
Arm Architecture v5TE
Architecture v5TE
- ARM 및 Thumb 명령어 세트의 완전한 v4T 버전
: ARM 및 Thumb 명령어 세트의 완전한 지원이 포함 - ARM/Thumb 상호 운용성 개선
: ARM/Thumb 상호 운용성을 향상시키는 기능이 추가
: ARM/Thumb 상호 운용성 모듈에서 다루어짐. - Leading(선행된) 0의 개수를 세는 명령어 추가
- 패킹(packing)된 half-word sign 곱셈 명령어
- 포화 수학 연산 지원
- PSR(프로그램 상태 레지스터)에 Q플래그 추가
- 더블 워드 로드/스토어 명령어 추가
- 브레이크 포인트 명령어
: ARM 및 Thumb 모드에서 전부 사용 가능 - 캐시 사전 로드 명령어
Counting Leading Zeros(CLZ)
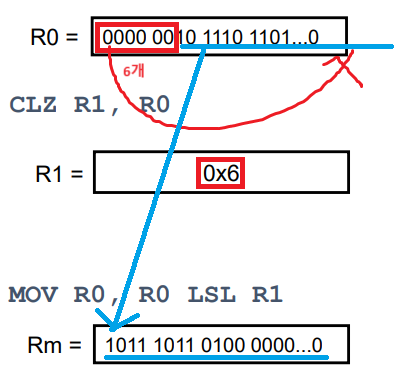
CLZ{cond} Rd, Rm
- 레지스터 값에서 첫 번째 1비트 앞의 0비트의 수를 반환
- 소스 레지스터는 상위비트에서 하위 비트로 스캔
- 1cycle 내에 실행
- 레지스터에 비트가 설정되지 않은 경우 결과는 32(00....0)
- 비트 31이 설정된 경우 결과는 0(10....0)
- 소프트웨어 나누기 및 부동 소수점 루틴에 사용
: Rm을 Rd만큼 왼쪽 시프트하면 Rm을 정규화 가능
: 부호가 있는 정규화는 1cycle을 더 필요로 함.
Counting Leading Zeros
EOR R1, R0, R0, LSL #1 ; R0의 값을 한 비트 왼쪽으로 시프트한 것과 R0의 값을 XOR하여 R1에 저장합니다. CLZ R1, R1 ; R1에서 선행 0의 수를 세어 R1에 저장합니다. MOV R0, R0, LSL R1 ; R0를 R1만큼 왼쪽으로 시프트한 값을 R0에 저장합니다.
- 주어진 레지스터 값의 선행 0 비트를 계산하여 그 값을 사용하여 원래 레지스터 값을 정규화하는 방법
- EOR R1, R0, R0, LSL #1: R0의 값을 한 비트 왼쪽으로 시프트한 것과 R0의 원래 값을 XOR하여 결과를 R1에 저장합니다.
- CLZ R1, R1: R1의 값에서 선행 0의 수를 세어 R1에 저장합니다.
- MOV R0, R0, LSL R1: R0의 값을 R1만큼 왼쪽으로 시프트한 결과를 R0에 저장합니다
Signed Multiply Operations(부호 있는 곱셈 명령어)
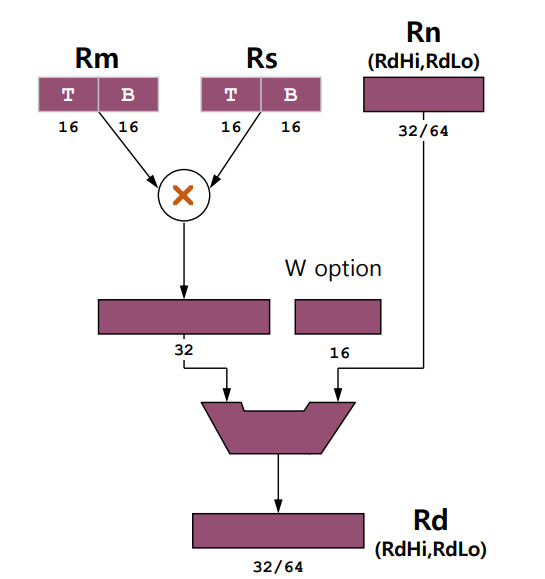
1. SMULxy{cond} Rd, Rm, Rs
- 두 레지스터의 하위 또는 상위 절반을 곱하여 결과를 Rd에 저장
- x와 y는 각각 레지스터의 상위 또는 하위 절반을 선택
SMULBB R0, R1, R2
; R1의 하위 절반과 R2의 하위 절반을 곱하여 R0에 저장
SMULTT R0, R1, R2
; R1의 상위 절반과 R2의 상위 절반을 곱하여 R0에 저장2. SMULWy{cond} Rd, Rm, Rs
- 48비트 곱셈의 상위 32비트를 선택하여 결과를 Rd에 저장
- y는 레지스터의 상위 또는 하위 절반을 선택
- W는 word를 의미
SMULWB R0, R1, R2
; R1 전체와 R2의 하위 절반을 곱한 48비트 결과의 상위 32비트를 R0에 저장실제 계산 과정:
R1 전체 = 0x12345678 (32비트)
R2 하위 절반 = 0xDEF0 (16비트)
- 여기서 16진수(4bit)로 적혀있음. 즉 4bit*8자리 = 32bit
- R1전체 * R2의 하위 절반 = 48비트
- 그 중 상위 32bit를 Rd에 저장
3. SMLAxy{cond} Rd, Rm, Rs, Rn
- 두 레지스터 Rm과 Rs의 하위 또는 상위 절반을 곱한 후, 레지스터 Rn의 값을 더하여 결과를 Rd에 저장
- Q 플래그(포화상태 플래그)는 이 명령어에 영향을 받지만 포화 상태에는 도달하지 않음.
SMLABB R0, R1, R2, R3
; R1의 하위 절반과 R2의 하위 절반을 곱하고 R3의 값을 더하여 R0에 저장4. SMLAWy{cond} Rd, Rm, Rs, Rn
- 48비트 곱셈의 상위 32비트를 선택하여 레지스터 Rn의 값을 더한 후 결과를 Rd에 저장
- y는 레지스터의 상위 또는 하위 절반을 선택
SMLAWT R0, R1, R2, R3
; R1의 전체값과 R2의 상위 절반을 곱한 48비트 결과의 상위 32비트를 선택하고 R3의 값을 더하여 R0에 저장5. SMLALxy{cond} RdLo, RdHi, Rm, Rs
- 두 레지스터 Rm과 Rs의 하위 또는 상위 절반을 곱한 결과를 64비트 레지스터 쌍 (RdLo, RdHi)에 저장
- x와 y는 각각 상위 또는 하위 절반을 선택
SMLALBB R0, R1, R2, R3
; R2의 하위 절반과 R3의 하위 절반을 곱한 64비트 결과를 R0와 R1에 저장추가 설명
- x와 y는 각각 B(Bottom) 또는 T(Top)를 의미
- ex.
SMULBB는 두 레지스터의 하위 절반을 곱함SMULWB는 첫 번째 레지스터 전체와 두 번째 레지스터의 하위 절반을 곱한 결과의 상위 32비트를 사용- NZCV 플래그를 변경하지 않으며, 이 명령어에 'S' 옵션을 사용할 수 없음
: Negative
: Zero
: Carry
: oVerflow
Saturated Maths Instructions(포화 연산 명령어)
포화 연산(Saturated Maths)
- 포화 연산은 결과가 정해진 범위를 벗어날 때 최대값 또는 최소값으로 설정되는 연산
- ex. 32bit에서 1을 더하면
0x7FFFFFFF에서0X80000000으로 전환
: 이 경우 포화 연산은 결과를 최대값인0X7FFFFFFF로 설정
포화 연산의 필요성
- 포화 연산은 통신 DSP 알고리즘에서 필요.
- 특히 G.723.1 및 AMR과 같은 VoIP 및 음성 인코딩 및 디코딩 알고리즘에서 사용
Q 플래그
- 포화 연산을 수행하는 명령어들은 포화가 발생했을 때
Q 플래그를 설정. - Q 플래그는 포화가 발생했음을 나타내는데 사용
포화 연산 명령어
QSUB{cond} Rd, Rm, Rn
- Rd = saturate(Rm - Rn)
- Rm에서 Rn을 뺀 결과를 계산
- 결과가 포화되면 최대값 또는 최소값으로 설정
- ex. Rm이 0x7FFFFFFF이고 Rn이 2라면, 결과는 0x7FFFFFFF에서 2를 뺀 값.
- 만약 결과가 32bit 범위를 벗어나면 최대값 또는 최소값으로 설정
QADD{cond} Rd, Rm, Rn
- Rd = saturate(Rm + Rn)
- 이 명령어는 Rm과 Rn을 더한 결과를 계산
- 결과가 포화되면 최대값 또는 최소값으로 설정
QDSUB{cond} Rd, Rm, Rn
- Rd = saturate(Rm - saturate(Rn * 2))
- 이 명령어는 Rm에서 saturate(Rn * 2)를 뺀 결과를 계산
- saturate(Rn * 2)는 Rn을 2배 한 후 포화가 발생하면 최대값 또는 최소값으로 설정
- 그 결과가 Rm에서 뺀 후에도 포화가 발생하면 최대값 또는 최소값으로 설정
QDADD{cond} Rd, Rm, Rn
- Rd = saturate(Rm + saturate(Rn * 2))
- 이 명령어는 Rm과 saturate(Rn * 2)를 더한 결과를 계산
- saturate(Rn * 2)는 Rn을 2배 한 후 포화가 발생하면 최대값 또는 최소값으로 설정
- 그 결과가 Rm과 더한 후에도 포화가 발생하면 최대값 또는 최소값으로 설정
Load/Store Double Registers
LDR/STR{<cond>}D <Rd>, <addressing_mode>
- 메모리에서 두 개의 인접한 워드(4바이트)를 전송하거나 레지스터 쌍에 저장
레지스터 쌍
- (r0,r1), (r2,r3), (r4,r5), (r6,r7), (r8,r9), (r10,r11), (r12,r13)
Rd
- 짝수 번째 레지스터를 지정
- Rd가 r0이면 인접한 홀수 번째 레지스터인 r1에도 전송이 수행
addressing_mode(주소 지정 모드)
- LDRH/STRH와 같은 주소 지정 모드가 사용
주소
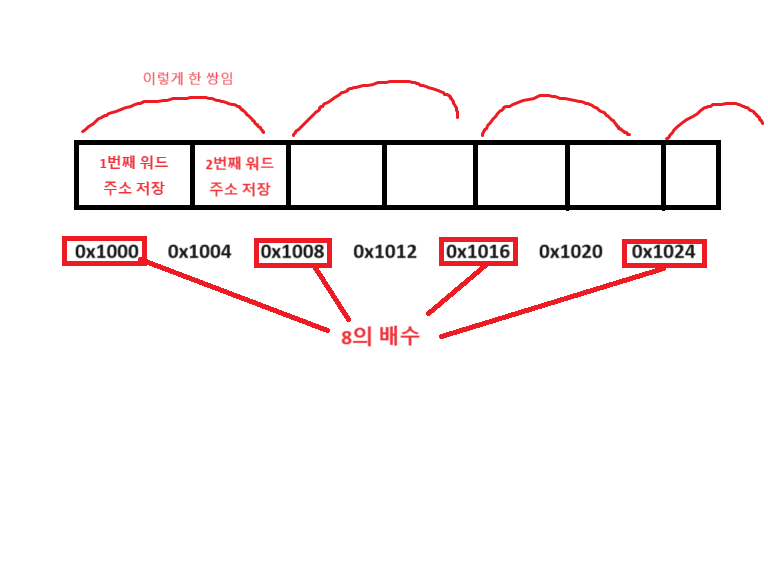
- LDRD 명령어가 로드하는 두 워드 중 낮은 주소를 지정
- 이 주소에 4를 더하여 두 번째 워드의 주소를 생성
- 첫 번째 워드의 주소가 0x1000이라면, 두 번째 워드의 주소는 0x1000 + 4 = 0x1004
주소 정렬
- 주소는 반드시 두 번째 워드의 8바이트 정렬(즉, 주소가 8의 배수여야 함)을 따라야 함.
- 메모리 주소는 8의 배수여야 함.
- 즉, 데이터가 메모리에서 저장되거나 로드될 때 주소는 항상 8바이트로 정렬되어야 함.
- 메모리에서 데이터를 빠르게 전송하는 데 사용
- 특히 데이터가 레지스터 쌍으로 저장되어 있는 경우에 유용함.
Breakpoint & Cache Preload
Breakpoint Instruction
BKPT <#imm16>
- 디버깅 중에 프로그램을 일시적으로 멈추고 디버그 에이전트에게 제어를 넘기기 위해 사용
- 보통 디버그 세션에서 디버그 포인트를 설정하는 데 사용
- 디버그 에이전트에 의해 시스템의 RAM에 설정
- 프로세서에서는 즉시 값을 무시
- 위 명령어를 실행하면 Prefetch abort를 발생시킬 수 있고, 프로세서를 디버그 상태로 전환시킬 수도 있음. 이는 코어의 설계 및 설정에 따라 달라짐
BKPT #0
; 디버그 포인트 설정Cache Preload Instruction
PLD[Rn, <offset>]
- 캐시에 데이터를 미리 로드하는 데 사용
- offset
: 부호 없는 12bit 즉시값(즉, 0에서 4095바이트)
: 레지스터, 선택적으로 즉시값으로 이동된 값 - 메모리 시스템에게 지정된 주소의 데이터에 대한 액세스가 곧 발생할 것임을 알려줌
- PLD는 힌트 명령어
: 이를 지원하지 않는 구현에서는 NOP(No Operation)으로 동작함.
PLD [R0, #16]
; R0가 가리키는 주소로부터 16바이트 떨어진 위치의 데이터를 캐시에 미리 로드합니다.Unified Assembler Language(UAL)
UAL은 ARM 어셈블러 코드를 더 유연하게 작성할 수 있도록 해주는 기술
- UAL은 모든 ARM 프로세서에 대해 어셈블러 코드를 작성할 수 있도록 함
: 이전에는 코드를 ARM 상태 또는 Thumb 상태에 대해서만 작성해야 했음
: UAL을 사용하면 어셈블리 시간에 실행 상태를 결정 - UAL은 효과적인 '의사' 명령어를 정의
: 이러한 명령어는 어셈블러에 의해 해석되며, 인라인 지시문(예: THUMB)이나 어셈블러 스위치(예: --arm)에 따라 어셈블러가 기계 코드를 생성
UAL의 일반 규칙
: POP, PUSH의 사용
: Rd와 Rs의 레지스터 정의의 융통성
: 자세한 내용은 어셈블러 가이드에서 확인할 수 있음
전통적인 ARM 어셈블리어 Vs. UAL 사용 어셈블리어
전통적(Traditional)
Asub
STMFD sp!, {r4, r5, lr}
ADDEQS r0, r0, r3
MOV r1,r2, LSL #4
BL Bsub
LDMFD sp!, {r4, r5, pc}
Bsub
STMIA r0, {r2, r3}
LDMIA r1, {r2, r3}
LDR r4, [pc,#0x0]
BX lr
Value DCD 0x8000Asub
: 서브루틴의 시작을 나타내는 레이블STMFD sp!, {r4, r5, lr}
: 스택에 레지스터 r4, r5, lr을 저장ADDEQS r0, r0, r3
: 조건 EQ(EQUAL)이 만족될 때 r0와 r3의 값을 더하고 결과를 r0에 저장MOV r1, r2, LSL #4
: r2 값을 4비트 왼쪽 시프트하여 r1에 저장BL Bsub
: 서브루틴 Bsub를 호출LDMFD sp!, {r4, r5, pc}
: 스택에서 레지스터 r4, r5, pc를 복원하고 서브루틴에서 반환Bsub
: 서브루틴의 레이블로 분기STMIA r0, {r2, r3}
: 메모리 주소 r0부터 r2와 r3을 저장LDMIA r1, {r2, r3}
: 메모리 주소 r1부터 r2와 r3을 로드LDR r4, [pc,#0x0]
: 프로그램 카운터(pc)의 현재 위치에서 상대 주소 0x0에 있는 값을 로드BX lr
: 서브루틴에서 반환
UAL
Asub
PUSH {r4, r5, lr}
ADDSEQ r0, r3
LSL r1, r2, #4
BL Bsub
POP {r4, r5, pc}
Bsub
STM r0, {r2, r3}
LDM r1, {r2, r3}
LDR r4, Value
BX lr
Value DCD 0x8000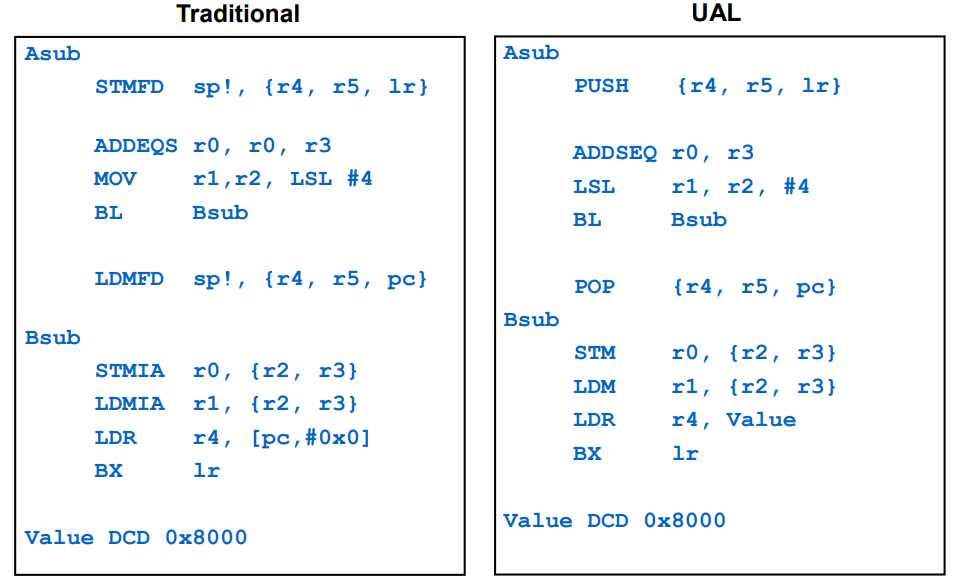
1. Asub
: 서브루틴의 시작을 나타내는 레이블
2. PUSH {r4, r5, lr}
: 스택에 레지스터 r4, r5, lr을 저장
3. ADDSEQ r0, r3
: 조건 SEQ(Sequential, 이전 명령어가 성공적으로 수행될 때)가 만족될 때 r0에 r3를 더함.
4. LSL r1, r2, #4
: r2 값을 4비트 왼쪽 시프트하여 r1에 저장.
5. BL Bsub
: 서브루틴 Bsub를 호출
6. POP {r4, r5, pc}
: 스택에서 레지스터 r4, r5, pc를 복원하고 서브루틴에서 반환
7. Bsub
: 서브루틴의 레이블로 분기
8. STM r0, {r2, r3}
: 메모리 주소 r0부터 r2와 r3을 저장
9. LDM r1, {r2, r3}
: 메모리 주소 r1부터 r2와 r3을 로드
10. LDR r4, Value
: Value 레이블이 가리키는 주소에 있는 값을 로드
11. BX lr
: 서브루틴에서 반환

행복한 하루 보내세요