데이터 파이프라인이란?
한마디로
언제든지 필요한 데이터를 가져와 꺼내 쓸 수 있도록 데이터를 계속 쌓아두는 파이프를 만드는 것이라고 보면된다.
데이터 파이프라인 사용 예시
파이프를 한 번 만들고 나면(배수관 파이프를 생각해보자, 여기서 데이터는 배수관 안으로 흐르는 물이라고 생각하면 된다) 큰 문제가 없는 한 데이터가 계속 들어와 쌓일 것이다.
어떻게 해야 적은 수고를 들이고 효율적으로 필요한 데이터를 모을 수 있을까?
데이터를 가져오는 과정에서 정제나 전처리가 쉽도록, 데이터 형태도 고쳐주고 필요없는 데이터는 제거하고 함께 보는게 좋은 데이터들은 합쳐서 저장하면 좋을 것 같다.
이러한 목적으로 만드는 것이 데이터 파이프라인이라고 보면 된다.
데이터 파이프라인이 하는 일
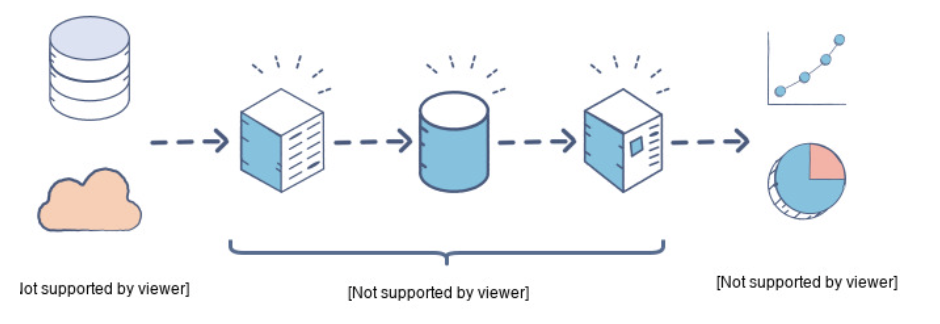
- Data extracting: 데이터 추출
- Data transforming: 데이터 변경
- Data combining: 데이터 결합
- Data validating: 데이터 검증
- Data loading: 데이터 적재
이 중 데이터 추출, 변환, 적재를 묶어 ETL이라고 한다.
ETL은 데이터 파이프라인 하위 개념으로, 하나의 시스템에서 데이터를 추출해 변환하여 데이터 베이스 or 데이터 웨어하우스에 차곡차곡 쌓아둔다.
데이터 파이프라인 구축을 위해서 무엇이 필요한가?
1) 분산 처리 프레임워크
- Hadoop, Spark
- 대규모의 데이터 셋을 효율적으로 처리하기 위해 사용한다.
하나의 대형 컴퓨터를 사용해서 데이터를 처리&저장 하는 대신에,
분산 처리 프레임워크를 사용하면 상용 하드웨어를 함께 클러스터링하여 대량의 데이터 세트를 병렬로 분석할 수 있다.
2) 데이터 레이크
- S3, HDFS
- 모든 데이터를 그대로 저장하고, 나중에 필요한 것만 꺼내서 사용하는 스토리지
3) Workflow 관리시스템
- Airflow, Oozie, Dagster, Argo
- 여러가지 태스크들(데이터셋 생성, 모델 학습 등)을 일련의 그래프로 연결하고 스케줄링, 모니터링 등 파이프라인을 관리할 수 있다.
Airflow에서 사용하는 DAG이란?
Directed Acyclic Graph, 즉 방향이 있지만 순환하지는 않는 그래프이다.
라면 끓이는 work flow를 생각해보면
물끓이기 -> 스프 넣기 -> 면 넣기 -> 계란 넣기
task마다 방향은 있지만 다시 자기 자신으로는 돌아오지 않는다.
순환하지 않는 이러한 그래프를 코드로 나타낸다.
4) 데이터 웨어하우스
- BigQuery etc
- 대량의 데이터를 분석하기 좋게 체계적으로 보관해놓는 데이터 창고이다.
- 가공되지 않은 데이터를 모아 놓은 창고는 데이터 레이크이다.
데이터 웨어하우스의 주요 특징 4가지
- 주체 지향 : 업무 중심이 아니라 주제 중심으로 데이터를 조직화 한다.(고객 거래처, 상품, 활동 등)
- 통합 : 데이터를 활용하기 좋은 형태로 변환하기 위해 표준화 기준으로 설정, 적용함으로 데이터를 통합해야 한다.
- 시계열 : 시간 별로 데이터 버전들을 저장한다.(데이터를 시간에 따라 수시로 갱신하거나 변경x)
- 비휘발성 : 데이터 웨어하우스의 데이터로 수행할 수 있는 작업은 데이터 로딩, 데이터 엑세스 뿐이다.(데이터의 변경, 삭제는 이뤄지지 않는다)
데이터 파이프라인 실습
우선은 데이터 파이프라인을 한번 경험해보는 것이 좋을 것 같아서
정리된 실습 강의를 찾아왔다.
1) T academy "빅데이터 파이프라인 기술의 이해 및 적정도구의 선정"
- 빅데이터 파이프라인 기술을 이해하고, 여기에 사용되는 주요 클라우드 플랫폼 및 다양한 도구들의 장단점, 유스케이스에 맞는 도구를 선택하는 방법을 알아봅니다.
- 220분
- https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=116
2) T academy "소셜 데이터 분석을 위한 데이터 파이프라인 구성 실습"
- 트위터와 같은 소셜 빅데이터 분석을 위한 데이터 파이프라인 구성의 전체 flow를 간단하게 실습하여 경험할 수 있습니다.
- 200분
- https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=117
참고 링크

킹왕짱 Cloud Engineer 지니박박구리 블로그