[Paper Review] DISGAN: Wavelet-informed Discriminator Guides GAN to MRI Super-resolution with Noise Cleaning
Paper Review
우와 !! denoising과 SR을 동시에 해주는 모델이 있다..?
바로 리뷰 시작..
논문 링크
전통적으로 SR(Super Resolution)과 Denoising은 별도로 처리되어 왔으며, 각각 별도의 훈련 데이터가 필요했다.
그런데ㅔㅔㅔㅔ 이 논문에서는 단일 딥러닝 모델을 사용하여 두 작업을 동시에 처리할 수 있는 방법을 개발함 !!
---> Noisy / Clean 이미지 쌍을 훈련 데이터로 사용할 필요가 없음!
모델이 SR 작업용으로 훈련되긴 했지만 SR 이미지에서도 뛰어난 잡음 제거 능력을 보여주는데, 주파수 정보를 고려한 판별기를 사용하는 GAN(Generative Adversarial Network) 모델을 사용한다. 특히, 3D 이산 웨이블릿 변환(3D Discrete Wavelet Transform, DWT)을 GAN 프레임워크 내에서 주파수 제약으로 활용한다. (이건 뭔소린지 모르겠어서 논문 차차 읽어보자)
Contribution:
- Residual Connection Block을 기반으로 한 3D generator
- 3D DWT와 1×1 conv를 combine한 DWT+conv 유닛을 3D Unet Discriminator에 통합
- High-quality SR 생성과 동시에 내재된 잡음 제거 과정을 수행
사용된 데이터는 인간 커넥톰 프로젝트(Human Connectome Project)의 3D MRI 데이터.
필요하다 생각하는 사전 지식은...
- GAN
- Discrete Wavelet Transform(DWT)
- 3D U-Net
- Super Resolution(SR)
🍞 1. Introduction
High-resolution MR 영상은 downstream MRI 분석에 필수적이지만, 아티팩트가 발생하기 쉽고 다양한 noise가 유입되어 공간 해상도 저하, 해부학적 세부 정보 손실 등의 문제가 있다.
따라서, 딥러닝을 통해 Single-Image Super Resolution(SISR)을 적용하려는 연구들이 계속되고 있다.
Conventional SR은 LR 이미지로부터 HR 이미지를 복원하려는 작업, Denoising 작업은 Gaussian noise, motion artifact 등 흔한 noise들을 제거하는 작업이다. ---> 각 작업별로 별도의 train, dataset을 필요로 한다.
SISR, Denoising은 inverse problem이며, 의료 영상에서는 특히 차원의 저주 문제로 더 어려운 작업이다. 2D 이미지 데이터셋들은 많지만, 3D MRI 데이터에 대한 접근은 어렵기도 하고 데이터셋도 적지만 3D는 중요한 해부학적 정보들을 포함하고 있기 때문에 이 논문은 3D 데이터 + DISGAN을 사용한다.
설명:
이 논문의 서론 부분에서는 고해상도 MRI 이미지의 중요성과 그것을 얻기 위한 과정에서 발생하는 어려움을 설명합니다. 노동 집약적인 스캔 과정과 하드웨어의 한계로 인해 발생하는 잡음과 아티팩트는 이미지의 품질을 저하시키며, 이를 개선하기 위해 딥러닝 기술이 필요함을 강조합니다. 특히, 3D MRI 데이터의 한정된 접근성과 큰 데이터 차원은 문제를 더 복잡하게 만들며, 이에 대한 해결책으로 DISGAN이 제안됩니다. DISGAN은 잡음 제거와 초고해상도를 동시에 달성하면서도 기존의 데이터 세트에 대한 의존도를 줄이는 새로운 접근 방식을 사용합니다.
Contribution은 다음과 같다.
-
GAN 프레임워크 제안: 기존 방법보다 더 상세한 구조를 복원하는 데 탁월한 성능을 보여주는 새로운 GAN 프레임워크를 제안한다.
-
모델의 robustness 입증: 주파수 정보를 기반으로 하는 판별기(frequency-informed discriminator)의 지도 하에 수행되는데, Discriminator는 잡음이 포함된 이미지와 깨끗한 이미지를 구분하는 능력을 향상시켜, SR 과정 중 이미지의 품질을 유지하도록 돕는다. 시뮬레이션된 잡음이 있는 이미지에서도 robustness를 입증했다.
-
noise 제거 효과 입증: 실제 임상 데이터에서의 잡음 제거 효과를 보여주는데, 이는 간질 또는 뇌종양 환자의 이미지와 같은 실제 임상 데이터의 품질을 향상시키는 데 중요하다.
🍞 2. Related works
🌿 Wavelet transforms
주파수 편향을 모델에 명시적으로 도입하는 데 널리 사용되며, SR, Denoising, domain transfer와 같은 작업에서 생성 모델(주로 GAN)에 사용되어 이미지 생성의 질을 향상시킵니다. 대부분의 연구에서는 생성기(generator)에 직접적으로 이산 웨이블릿 변환(Discrete Wavelet Transform, DWT)을 구현하지만, 본 논문에서 제안하는 모델은 판별기(discriminator) 내에서 DWT 기능을 포함하여, 생성된 분포와 실제 분포 사이의 주파수 공간에서의 차이를 측정하는 역할을 한다.
(무슨소린지모르겠따!! methods에 나오겠지뭐 걍 예전엔 제너레이터엿는데여기선디스크리미네이터랜다 )
🌿 Super resolution in medical imaging
Medical imaging에서의 SISR는 2D 및 3D 이미지 모두에 대해 광범위하게 연구되었는데, 이 태스크에서는 CNN의 엄~청난 능력을 사용하여 LR 이미지에서 HR 이미지로의 non-linear mapping을 학습한다. 2D 도메인에서 SRCNN은 LR에서 HR로의 이미지 매핑을 위한 최초의 end-to-end CNN 아키텍처를 도입하였으며, 전통적인 SISR 방법보다 훨씬 우수한 성능을 보였고, 이후 SRGAN, VDSR, RCAN, ESRGAN 등의 아키텍처가 GAN 프레임워크, perceptual loss, deeper architecures, attention mechanism을 도입하여 성능을 개선했다. 더 최근에는 트랜스포머 및 확산 모델이 2D SISR 작업에서 최고의 품질을 달성하였지만, 이런 방법들은 전형적으로 많은 양의 훈련 데이터가 요구된다.
Medical imaging에서 2D MR 영상에 대한 연구는 squeeze-excitation attention network나 트랜스포머 아키텍처와 같은 뛰어난 결과를 냈지만, 일반적으로 downstream 분석을 위해 3D MR 볼륨이 필요해서 3D 모델이 더 선호된다. 결과적으로 3D 모델은 MR 영상의 SISR 작업에서 2D 모델보다 우수했다. 이 논문은 오직 3D MR 영상 훈련에만 초점을 맞추고 있으며, 고차원성과 제한된 데이터로 인해 아직 3D MRI 영역에 새로운 아키텍처가 완전히 적용되지는 않았다.
---> 효율성과 높은 성능으로 인해 GAN 기반 방법이 3D MRI 훈련의 주류.
이전 연구들은 GAN training, densely connected residual blocks, implicit neural representation, image gradient를 이용하여 impressive한 3D MR 영상 SR 결과를 달성했다. 그러나 이러한 연구들은 종종 same modality거나 이미지 시퀀스를 훈련 데이터 세트로 사용하는 한계가 있어 일부 경우에는 reconstruction의 품질이 제한될 수 있다.
🍞 3. Methods
🌿 3.1 Network structure

DISGAN은 생성기(generator), 판별기(discriminator), 특징 추출기(feature extractor)로 구성된다.
생성기는 세 개의 Volumetric RRDB(VRRDB) 블록으로 구성되어 있으며, 업샘플링을 위해 pixel shuffling을 사용한다.
특징 추출기는 MLP 앞에서 convolution / activation 레이어를 사용한다. -> GAN 모델과 동시에 훈련됨.
3D MRI의 LR/HR 패치 쌍을 입력으로 받아 SR 영상을 출력하는 모델이다.
생성 과정에서 LR volume은 생성기의 입력으로 사용되며, SR 영상을 생성하여 출력한다.
이후 특징 추출기는 HR과 SR 쌍을 사용하여 feature-wise Euclidean distance를 측정한다.
판별기는 HR/SR 쌍을 입력으로 받고, discrimination score를 출력한다.
Train을 안정화하기 위해 linear하게 감소하는 Gaussian noise를 추가하고, adversarial training을 위한 target으로는 relativistic GAN Loss를 사용한다.
🌿 3.2 Wavelet informed discriminator
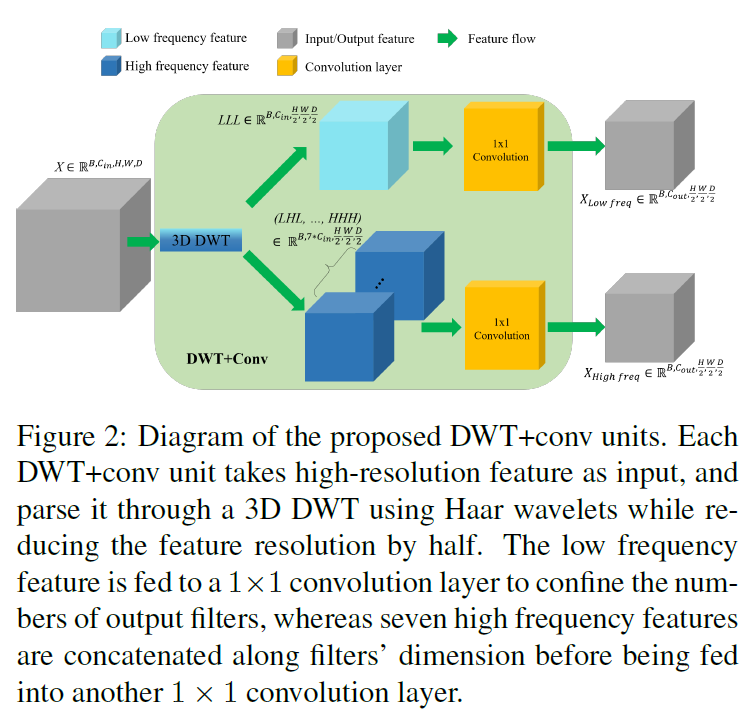
판별기에서 주파수별 특징을 추출하기 위해 이산 웨이블릿 변환 + convolution units(DWT+conv units)을 제안한다.
기본 연산으로, 3D Haar wavelet transform을 사용하여 sub-band frequency feature를 측정하고, 이 feature들은 여러 sub-band(하나의 low frequency band(LLL), 7개의 high frequency bands(LHL, LLH, LHH, HLL, HHL, HLH, HHH))로 분류된다.
Low frequency sub-band feature는 출력 필터 수를 제한하기 위해 1x1 conv를 통과하고,
high frequency sub-band feature는 필터 dimension을 따라 concatenate 된 후 같은 목적으로 another 1x1 conv를 통과한다.
🌿 3.3 Objective function
높은 지각 품질과 균형 잡힌 훈련 성능을 갖춘 이미지를 생성하기 위해, 이미지 도메인의 L1 손실, 지각 손실, 상대적 GAN 손실을 조합하여 생성기 네트워크의 전체 목적 함수를 구성합니다. 생성기의 파라미터는 특징별(Lperc) 및 이미지별(Lpixel) 실제값 표현을 학습하도록 제한되며, 이 목적 함수는 최소화하려고 합니다.
높은 perceptual quality와 균형 잡힌 훈련 성능을 갖춘 이미지 생성을 위해서, 이미지 도메인의 L1 loss, perceptual loss, relativistic GAN loss를 조합하여 생성기 네트워크의 전체 objective function을 구성했다.
생성기의 parameters는 Ground truth의 feature-wise(L^perc, 피처별), image-wise(L^pixel, 이미지별) representation을 학습하도록 제한되며, objective function을 최소화하려 한다.
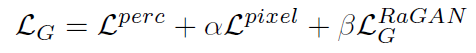
alpha = 0.01, beta = 0.005는 image space L1 loss와 relativistic averaged GAN loss를 weighting 하는 empirical paramters이다.
판별기와 특징 추출 네트워크는 각각 L^RaGAN_G, L^perc에 대해 업데이트된다.
🍞 4. Experimental settings
🌿 4.1 Evaluation metrics
SR 결과의 정확성을 평가하기 위해 제안된 다양한 지표들은 다음과 같다.
- PSNR(Peak Signal-to-Noise Ratio)
- NRMSE(Normalized Root Mean Square ERror)
- SSIM(Structural Similarity Index)
단순히 픽셀간의 유사성을 극대화하는 것뿐만 아니라 해부학적 구조를 정확하게 보존하는 것이 목표이기 때문에, SSIM을 사용하는데, SSIM은 이미지의 밝기, 대비, 구조 등 여러 측면에서의 유사성을 종합적으로 고려하여 정밀한 평가를 가능하게 한다.
🌿 4.2 Datasets
세 데이터셋은 HCM(Human Connectome Project)에서, 나머지는 다른 출처(Creation of fully sampled MR data repository for compressed sensing of the knee. In In Proceedings of Society for MR Radiographers & Technologists (SMRT) 22nd Annual Meeting, Salt Lake City, UT, USA, 2013.)에서 얻었고, 전처리는 모든 이미지가 평균이 0이고 표준편차가 1이 되도록 standardize 했다.
✨ "Insample"
HCP의 Lifespan Pilot Project에서 다운로드, 8~75세에 이르는 27명의 건강한 개인(남12 여15)의 T1-weighted MR 이미지를 포함하고 있다. Siemens 3T scanner로 촬영되었으며, 20명은 훈련용, 7명은 테스트용이다.
Ground truth의 해상도는 0.8mm isotropic이며, matrix size는 208x300x320이다.
✨ "Epilepsy"
OpenNeruo에서 다운로드, 간질 환자의 brain MRI 영상을 T1w contrast로 포함하고 있고, 85명 중 한명의 환자이미지를 사용하여 Denoising SR의 성능을 평가한다. 해상도는 0.8mm, matrix size는 208x320x320.
✨ "Tumor"
BraTS 챌린지의 validation dataset. 병리학적으로 확인된 여러 MRI scan을 포함하고 있으며, 그 중 뇌종양 MRI(T1w) 하나를 사용한다. matrix size는 240x240x155, 해상도는 1mm, 두개골 제거 처리.
---------> 다양한 데이터셋 사용으로 모델의 다양한 의료 영상에 대한 적용 가능성과 효과를 폭넓게 검증
🍞 5. Results
🌿 5.1. Implementation details
DISGAN의 구현을 위해 generator network, critic network, feature extractor network를 훈련시킴.
Gernerator network는 batch norm layer 없이 densely connect된 3개의 residual-in-residual dense block으로 구성되어 있다.
Critic network는 비선형 활성화 레이어 없이 discriminator와 동일하다.
Feature extractor는 ResNet10의 conv 레이어 뒤에 linear 레이어를 사용한다.
- Kaiming initialisation, Adam optimizer, lr = 0.0001, epoch = 60000(?!)
🌿 5.2. High fidelity super-resolution on brain MRI
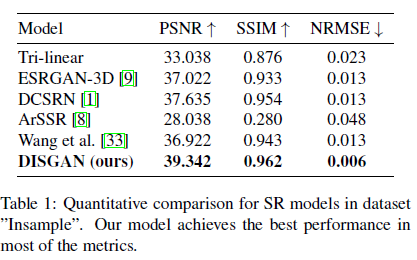
- Insample Dataset 사용하여 DISGAN / ESRGAN-3D(기존 2D conv를 3D로 대체) / DCSRN / Wang et al 모델
표로 보면 알 수 있듯이 quantitative result가 DISGAN이 제일 좋다고 한다ㅏㅏㅏ

위 그림에서도 DISGAN의 DWT-informed discriminator가 generator가 high fidelity한 이미지를 생성했다.
Image-space / Frequency-space 에서도 결과가 제일 좋음!
🌿 5.3. Removal of simulated noise
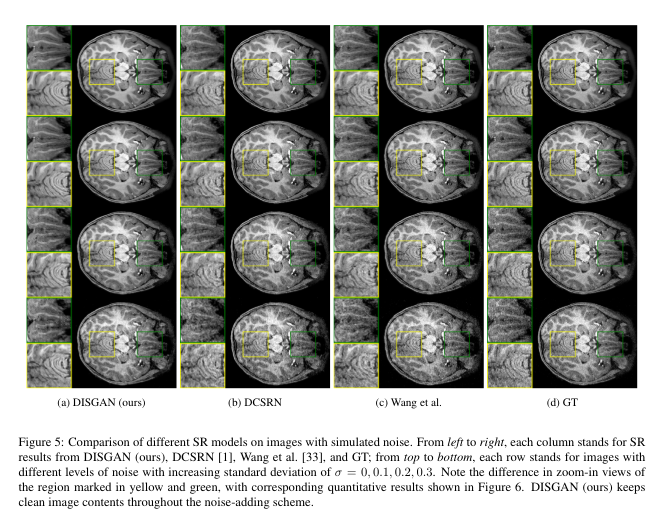
LR input = HR image + Gaussian noise + downsampled(2)
모든 모델에는 denoising 훈련 없이 SR에만 사용됨.
-> 사진이 잘 안보이긴 하는데, 4단계로 노이즈가 계속 증가하는 이미지들이다.
4단계 노이즈의 경우 모든 모델의 성능이 저하되었지만 DISGAN은 낮은 NRMSE 값을 유지했다.
🌿 5.4. Noise removal in real world patients
Tumor / Epilepsy 데이터셋 사용
-Epilepsy: random noise, ringing artifact 최소화, 복원 잘함
-Tumor: denoising 잘함, 병변 잘보이고 뭐 대비 개선 등등
🍞 6. Ablation studies
Ablation study는 모델의 개별 구성 요소나 구성의 영향을 분석하기 위해 설계된 연구로, DISGAN의 경우에는 생성기와 판별기 구성 요소에 초점을 맞춰 그들의 역할과 효과를 평가한다.
🌿6.1. Building blocks in the generator
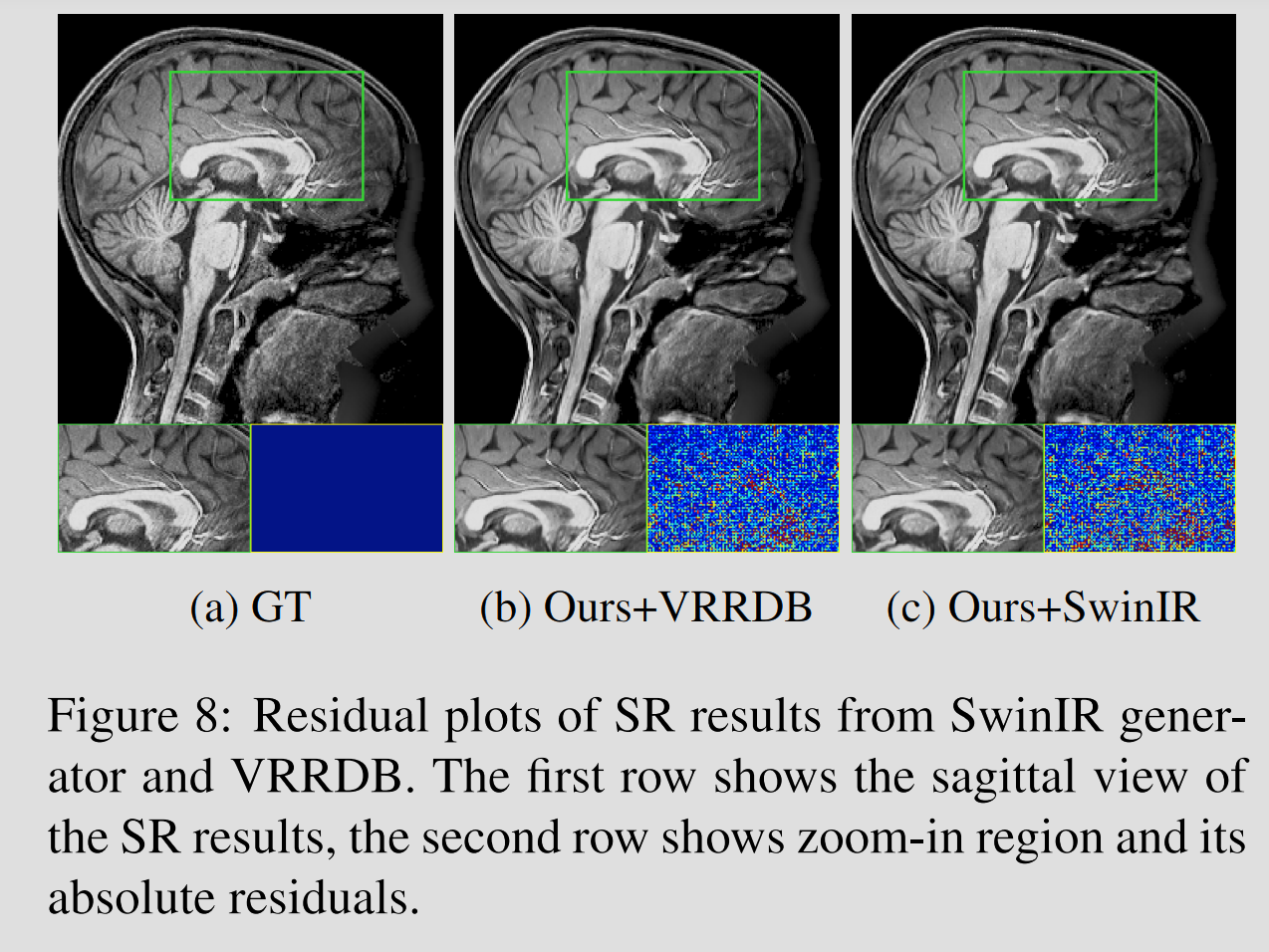
DISGAN's Generator = SwinIR의 Generator 변형 버전
- 2D SR SOTA 모델인 SwinIR의 SwinTransformer standard 2D conv를 3D conv로 대체하여 3D MRI 데이터 처리가 가능하도록 조정한다.
- Insample 데이터셋으로 훈련
Results: VRRDB Generator가 SwinIR보다 혈관의 tail과 같은 detail 등 복잡한 세부 사항을 포착하는데 효과적이다.
🌿6.2. DWT Unet as denoising discriminator
SR 과정에서 각 discriminator의 효과를 검토하는 실험.
각 비교된 discriminator들은 다음과 같다.
- Simple Conv network
- Unet-shaped conv network
- Unet-shaped conv network with DWT+conv units
Results: DWT discriminator로 생성된 이미지가 더 clean / detail한 recover를 보여준다.
🍞 7. Discussion
본 논문은 SISR + Denoising 아키텍처인 DISGAN을 제안했다.
특히, discriminator의 기본 단위로 3D DWT+conv 블록을 제안하여 generator가 high frequency fidelity & minimising noise하도록 간접적으로 guide함.
-> 일반화 여부가 향후 연구 과제
하도 이미징만 하니까 NLP 하고싶어져서 다음 논문은 NLP 해야게따
