[Paper Review] Dual-Octave Convolution for Accelerated Parallel MR Image Reconstruction
Paper Review
2021년에 나온 MR acceleratoin recon 과정을 개선하는 Dual-Octave Convolution 접근 방식을 소개하는 논문. AAAI 저널에 투고된 논문이라고 한다ㅏㅏ
후속 논문이 하나 더 있는데 일단 이거 읽어보고 괜찮으면 추가로 포스팅 해야겠다.
이 논문은 real / imag 파트 모두에서 multi-scale spatial frequency features를 학습할 수 있는 새로운 방식인 Dual-OctConv를 제안하는데, 복잡한 연산을 Octave convolution으로 재구성함을 통해 MR 이미지의 richer representation을 capture하며, spatial redundancy를 크게 줄인다.
본격적으로 내용을 보기 전 조금만 구체적으로 적으면,
input 피처맵과 conv 커널은 real / imag 부분으로 나뉜 후, 그들의 spatial frequency에 따라 4개의 그룹으로 나누어진다.
이후 Dual-OctConv는 그룹 내 정보 업데이트/교환을 수행하여 다양한 그룹 간의 contextual information을 집계하는데, 두 가지 장점이 있다.
- 다양한 spatial frequency에서 real / imag 부분 간의 상호작용을 촉진하여 더 richer representation을 달성
- real / imag 부분의 multiple spatial-frequency features를 학습함으로 receptive field를 확대한다.
🍞 1. Introduction
: MR의 중요성과 한계를 설명하는 섹션MR은 non-radiative(방사선 X)하면서도높은 spatial-resolution을 제공하는 장점이 있지만, 다른 영상 기법에 비해 훨씬 더 긴 acquisition time이 필요한 한계가 있다. 이를 위해 undersample된 데이터로부터 image를 recon하는 여러 노력들이 기울여지고 있다.
Parallel MR imaging은 accelerated MR image에서 가장 중요한 성과로 여겨지는데, SENSE, GRAPPA, SPIRiT 등 spatial sensitivity와 gradient coding을 활용하여 recon에 필요한 데이터의 양을 줄이고 imaging time을 단축하는 다양한 연구가 있다. GRAPPA 리뷰 포스트
또한 Compressed Sensing(CS)는 fast MR image recon을 위한 중요한 기술로, Nyquist rate 이하로 샘플링된 k-space 데이터에서 원하는 signal을 복구한다. CS 기반 접근법은 sparsity prior, low-rank sparse sampling, manifold learning을 recon에 사용한다.
최근에는(논문 시점 2021) DNN의 부활로 특히 CNN을 사용한 딥러닝 기술이 Parallel MR imaging에 널리 사용되고 있다.
(그동안의 연구 소개 생략)
하지만, 대부분의 접근법은 MR image rcon에서 k-space 데이터를 위해 standard CNN에서 사용되는 vanilla convolution을 사용하지만, 이는 real 값의 natural image를 위해 설계되어 imag 입력을 처리하는 데에는 적합하지 않다. 초기 연구에서는 imag 부분을 버리거나, real / imag 부분을 독립적으로 처리했다.
정보손실을 피하고 real / imag 값 간의 information exchange를 촉진하기 위해 complex convolution이 2018년에 제안되었는데, 이 complex convolution 연산은 MR 이미지의 intrinsic multi-frequency property를 무시하고, 최종 representation에서 single-scale contextual information이 제한되고 high spatial redundancy가 높은 한계가 있다.
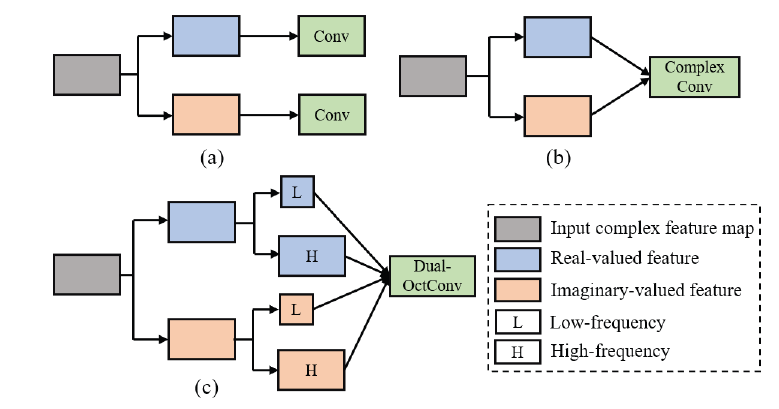
이러한 한계를 해결하기 위해 본 논문에서는 Dual-Octave Convolution을 제안하는데, 이는 multi-coil MR image의multi-frequency represnentation 학습을 가능하게 한다.
Complex convolution과 다르게, Dual-OctCOnv는 MR 이미지 feature의 real / imag 부분을 high - low frequency 구성 요소로 분해하여 처리한다. low-frequency components는 이웃 위치 간의 정보를 공유하여 low-resolution에서 효율적으로 처리할 수 있기 때문에 receptive field를 확장하고 spatial redundancy를 줄일 수 있다.
recon을 위해 마지막에는 real / imag 부분의 feature들을 결합하는데, Dual-OctConv를 통해모델은 다양한 크기 or 모양의 연조직(혈관, 근육 등)을 더 잘 포착할 수 있는 강력한 multi-scale representation learning 능력을 갖게 된다.
이 연구의 주요 contribution은 세 가지로 요약할 수 있는데,
- accelerated parallel MR image recon을 위한 multi-frequency feature representation을 제안하고, multi-scale contextual information을 포착할 수 있는 능력을 보여준다.
- multi-frequency representation space에서 imag 입력을 처리하고 다양한 주파수 도메인 간의 정보 교환을 촉진하기 위한 Dual-Conv를 고안했다. (larger receptive field, higher flexibility, computationally more efficient)
- vivo knee dataset에서 sota 알고리즘 보다 더 성능 개선
🍞 2. Related Work
: 딥러닝 / multi-scale representation learning, 두 주요 영역의 이전 연구 소개 섹션🌿 Deep Learning in MR image Reconstruction
기존 연구 소개니까 간단히만 적겠다.
U-Net, VN-Net 등이 있고, real / imag 처리하는 모델의 경우 함께 처리하는 연구가 많았지만 이와 대조적으로 본 논문은 복소수 입력 특징을 multi-frequency space에서 표현한다.
Dual-OctConv는 더 풍부한 contextual knowledge를 포착할 수 있고 이는 성능 향상으로 이어진다.
🌿 Multi-Scale Representation Learning
이미지 분류를 위해 다양한 scale에서 정보를 전파하고 통합하기 위한 multi-grid network를 제안하는 연구가 있었다.
multi-scale information은 이미지 세부 정보를 복원하는데도 효과적임이 입증되었고, Object Detection / semantic segmentation 에서 multi-scale representation을 학습하기 위한 다양한 기술이 제안되었다.
최근에는 Octave conv를 제안하여 spatial frequency model에 기반한 multi-scale features를 학습하여 성능을 향상시킨 연구도 있다.
Dual-OctConv는 다양한 크기, 모양의 혈관 또는조직의 세부 사항을 더 잘 포착할 수 있게 한다.
🍞 3. Methodology
🌿 Problem Formulation
MR Scanner는 receiver coil을 통해 k-space 데이터를 획득하고, inverse multidimensional Fourier transform을 통해 최종 MR 이미지를 얻는다.
Parallel imaging에서는 여러 receiver coil을 사용하여 k-space 데이터를 동시에 획득한다.
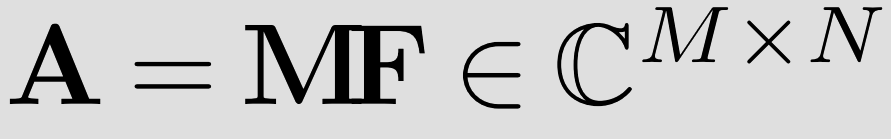
A는 undersample된 Fourier encoding matrix, F는 multidimensional Fourier Transform, M은 undersampled mask operator를 의미한다.
Parallel Imaging에서 모든 코일의 마스크는 동일하다.
각 코일의 Undersample된 k-space 데이터는
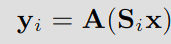 로 나타내는데,
로 나타내는데,
추가적으로, 얻어지는 이미지는 inverse FT가 undersampled k-space data에 직접적으로 적용되었다면 aliasing artifact를 포함한다.
암튼 수식이 정말 많은데... 많진 않고 약간 있는데 그냥 MR recon 관한 method 문제 정의 부분으로 보면 된다.
🌿 Dual-Octave Convolution
Dual-Octave Convolution은 real / imag 데이터를 low-freq / high-freq 구성 요소로 분리하여, 다양한 spatial frequency parts에서 풍부한 multi-scale context information을 얻는다.
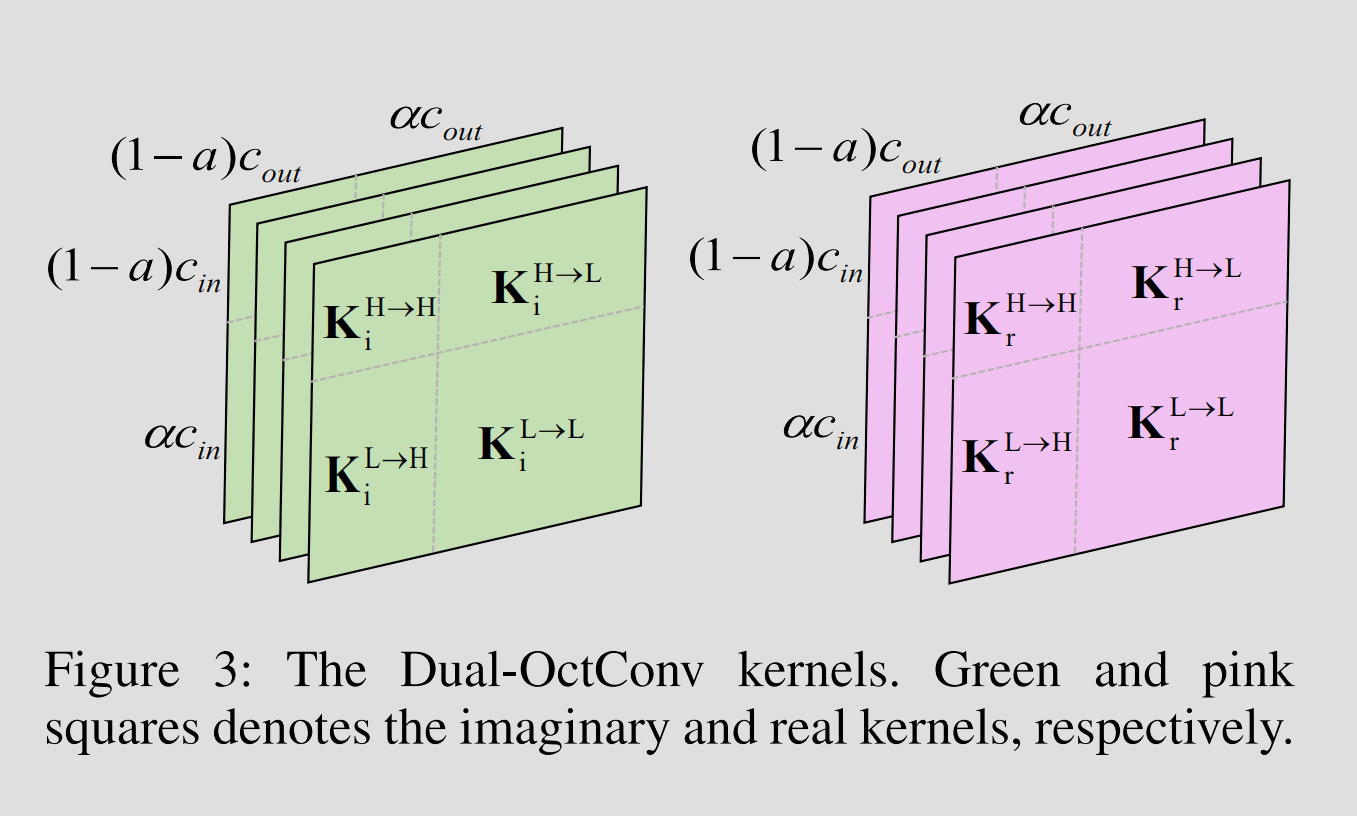
왜 배경이 회색으로 나오냐
그림처럼 imag/real kernel을 통해 low-freq / high-freq feature map을 생성하고, 이를 결합하여 최종 출력 피처맵을 생성하는 방식이다.
수식은 귀찮아서 생략
🌿 Detailed Network Architecture
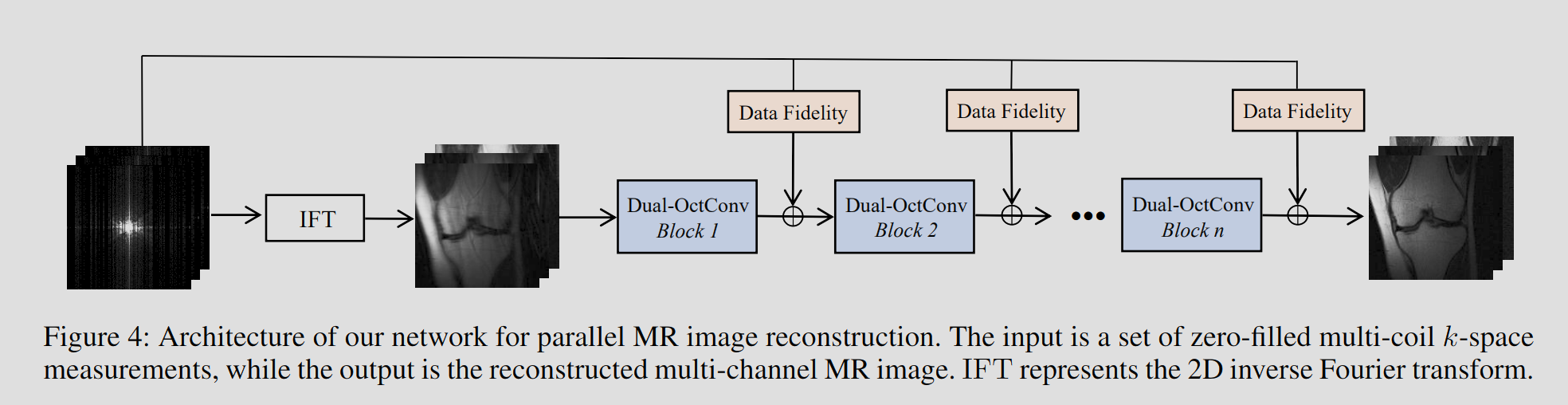
네트워크는 10개의 Dual-OctConv block으로 구성되며, 각 블록은 residual 형태로 구성된 5개의 Dual-OctConv layer를 포함한다.
input: undersampled multi-coil k-space measurement
output: reconstructed MR image
original k-space 정보 보존을 위해 연속된 블록 사이에 dat fidelity unit을 추가하고, activation function은 ReLU를 사용한다.
🍞 4. Experiments
🌿 Datasets
- 3T Simens Magnetom Skyra scanner 사용, multicoil fully-sampled MR knee dataset
🌿 Implementation Details
- Tensorflow 1.14, NVIDIA 1080Ti GPU 사용
- complex parameters의 magnitude, phase initialize 위해 Rayleigh / uniform distribution 사용
- Adam optimizer, lr = 0.001, weight_decay = 0.95, batch_size = 4, conv_kernel_size = 3 x 3
🌿 Quantitiative Evaluation, Qualitative Evaluation
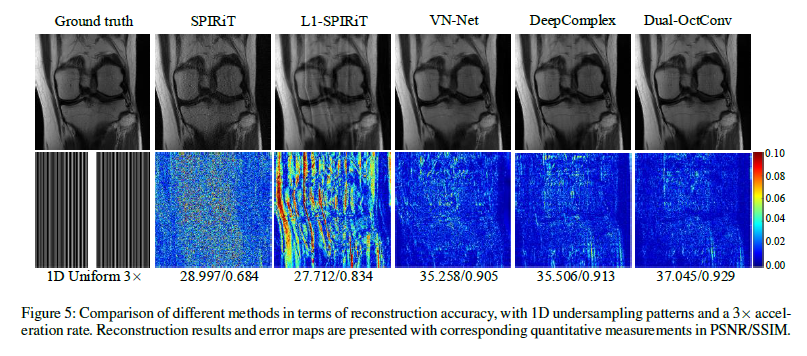
- PSNR, SSIM 사용 -> Dual-OctConv가 기존 방법론 능가
- 3x acceleration에서 가장 좋은 성능
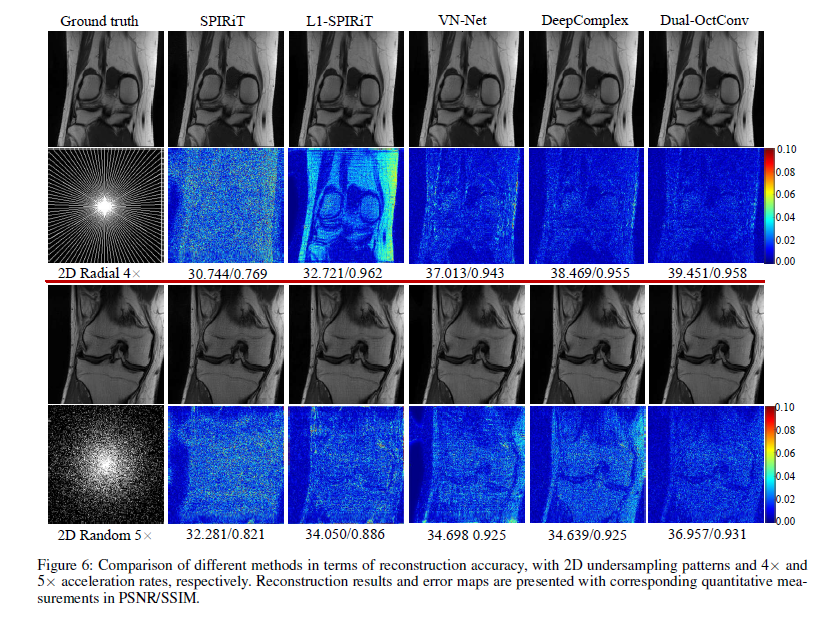
- 4x, 5x acceleration에서도 해봤는데 뭐 좋은 결과였다 ~
🌿 Ablation Studies
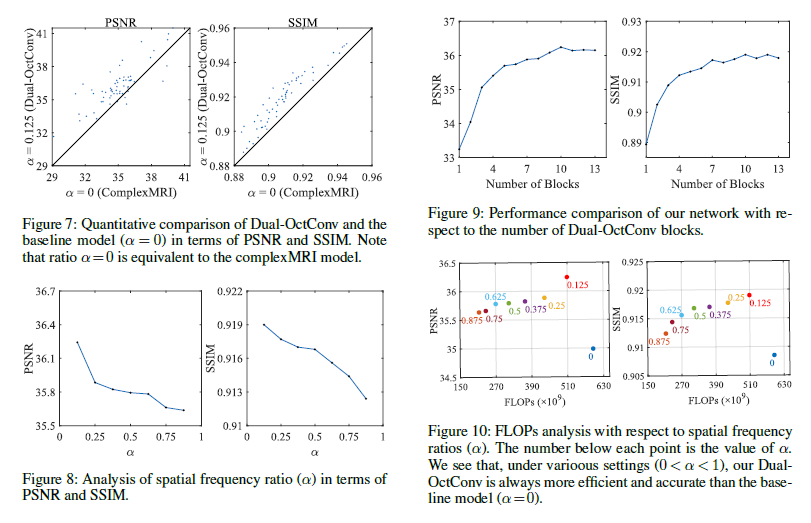
- alpha(spatial frequency) = 0으로 설정하여 Dual-OctConv를 standard complex convolution으로 변환한 기본 모델과 비교했을 때, SSIM 측면에서 크게 우수한 성능
- alpha = 0.125에서 최적의 PSNR / SSIM, alpha가 커질수록 성능 저하
- 블록 수가4일 때 MR recon 성공적, 10일 때 가장 높은 정확도
- 낮은 alpha 값은 높은 FLOPs로 성능 향상
🍞 5. Conclusions
- real/imag를 다양한 spatial frequency에서 처리할 수 있는 새로운 Dual-OctConv를 제안함.
- 다른 spatial resolution에서 real/imag feature map convolution을 통해 더 높은 quality의 이미지 recon 및 artifact 감소
계산 복잡성에 관한 말은 없어서 한번 써봐야 알 것 같다.
그리고 특정 하이퍼파라미터에 의존적일 수도 있다는 생각이 들어서, 깃허브에서 코드 응용을 해봐야할듯..?

취미로 논문을 뜯는 당신 참개발자.