Face Verification Vs. Face Recognition
얼굴 인증(verification): 상대적으로 더 쉬운 1 : 1 매칭 문제
얼굴 인식(recognition): 더 어려운 1 : K 매칭 문제
Pre-training (사전훈련)
: 이미 학습이 완료되어 output 도출이 가능한 모델
ex. 개와 고양이를 구분하는 모델
Transfer Learning (=domain adaptation)
: pretrained model을 새로운 데이터셋 (x,y)로 다시 학습시킴
ex. 위의 개-고양이 구분 모델을 표혐-호랑이 구분 모델로 새로 학습
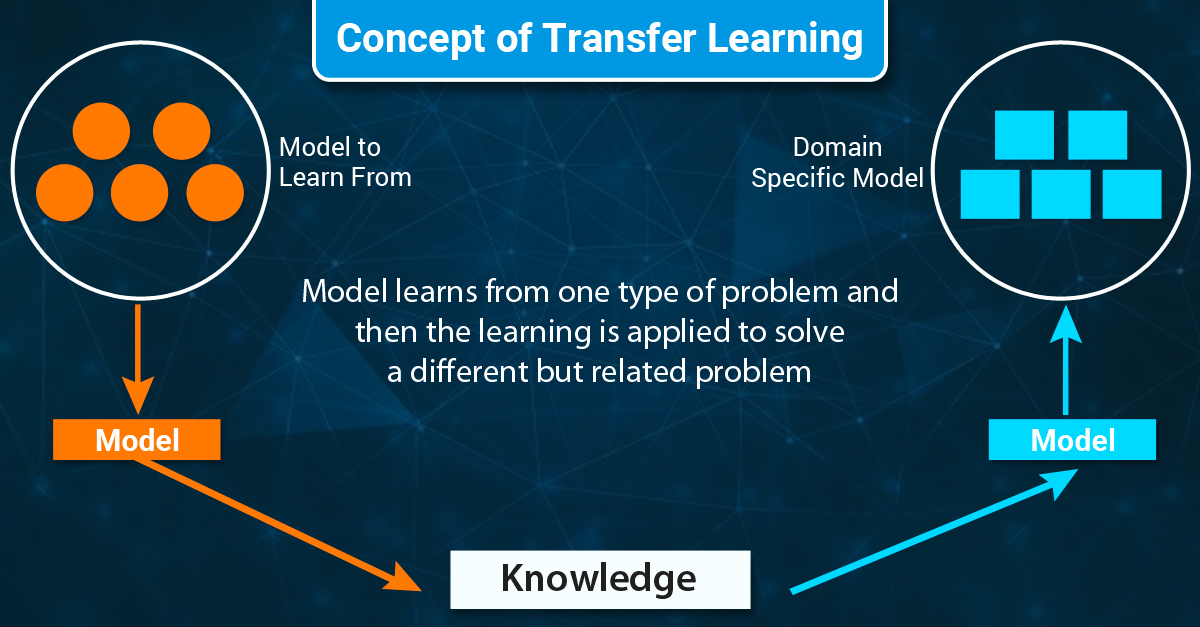
Fine-Tuning (미세 조정)
: 마지막 output layer를 삭제하고 다른 layer(들)를 붙여서 다시 훈련시킨다.
ex. 표범-호랑이가 아니라 모든 포유류를 분류하고 싶을 때.
PILLOW
- PIL: Python Image Library의 약자
- 이미지 처리, 그래픽 기능 제공하는 라이브러리
- 다양한 이미지 파일 형식 지원 (PPM, PNG, JPEG, GIF, TIFF, BMP 등; 지원하지 않는 형식은 라이브러리 확장을 통해 새로운 디코더 만들 수 있음)
- 파이썬 3.x 버전은 PIL의 후속인 Pillow가 지원
- jpynb에서 이미지를 바로 확인 가능
Image Augmentation (이미지 증강)
CNN 모델의 성능을 높이고 overfitting을 극복하려면, 다양한 유형의 학습 이미지 데이터셋을 늘려야 한다. 하지만 이미지 데이터의 경우 학습 데이터 양을 늘리기 쉽지 않다. 이 때 Augmentation을 통해, 학습 시 원본 이미지에 다양한 변형을 가해 데이터를 늘리는 효과를 발휘한다.
(원본 이미지의 수를 늘린다? -(X) / 학습마다 개별 이미지를 변형한다? - (O)
Augmentation의 유형
| 공간 레벨 변형 (Spatial) | 픽셀 레벨 변형 (Pixel) |
|---|---|
| Flip(대칭): vertical, horizontal Crop: Center, Random Affine: Rotate, Translate(이동), Shear(밀림), Scale(크기) | Bright, Saturation, Hue, GrayScale, ColorJitter 등 |
ex. center crop: 중앙을 기준으로 확대
Albumentation: image augmentation 전용 패키지

출처: Albumentations
End-to-End 모델
: 수동 피처 엔지니어링 (manual feature engineering)이나 중간 처리 단계 없이 입력 데이터에서 출력 데이터로 직접 작업을 수행하는 방법을 학습하는 일종의 머신러닝 모델.
- 입력부터 출력까지 파이프라인 네트워크 없이 신경망으로 한 번에 처리
- 수작업으로 만든 특징이나 전처리 단계에 의존하지 않고 원시 데이터를 입력으로 받아 원하는 출력을 직접 생성
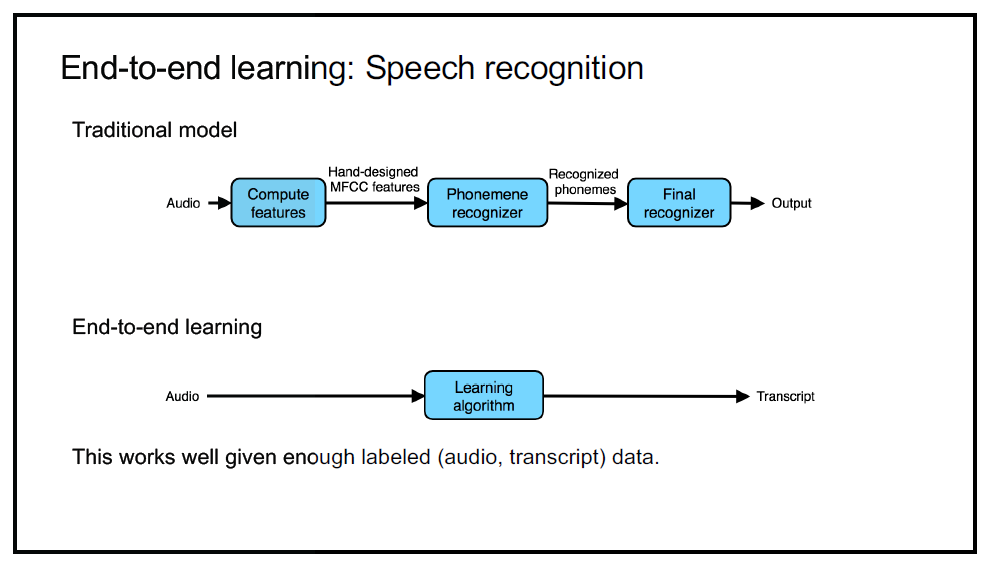
ex. MFCC로 음성 파일 특징 추출, 음소 추출 등을 거치지 않고 E2E 모델을 통해 음성 파일에서 바로 출력을 구함.
MTCNN이란?
논문: https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html
- Face Detection(얼굴 검출), Face Alignment(눈/코/입 좌표 추출), Bounding Box Regression(얼굴을 나타내는 박스 위치를 조절) 세 가지 태스크를 동시 학습시키는 joing learning 방식으로 빠른 속도와 높은 정확도 달성
- P-net, R-net, O-net의 세 CNN을 차례로 통과하는 Cascade 모델
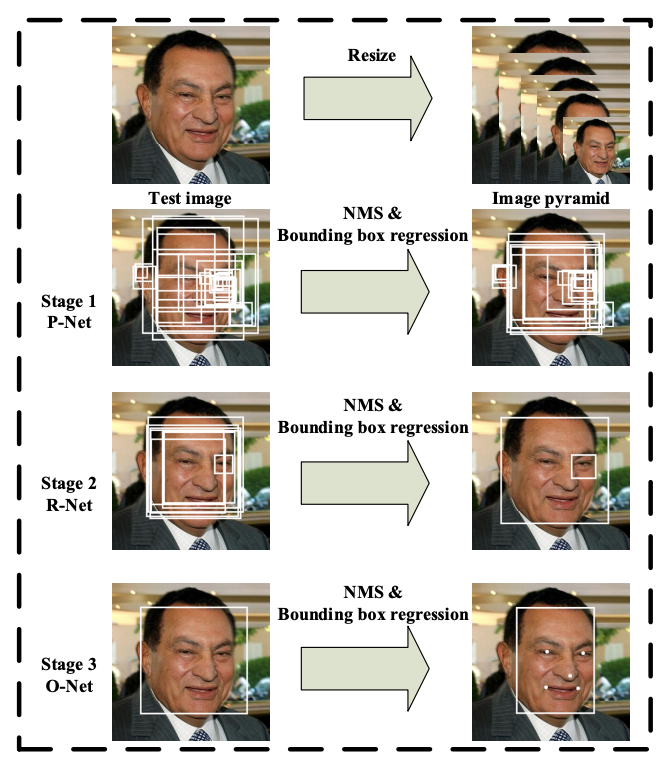
- 참고 토이 프로젝트: https://hayunjong83.tistory.com/50
MTCNN을 Face Detection 모델로 사용 -> FaceNet을 통해 얼굴 영역을 임베딩 벡터로 변환 -> 선형 SVM 모델로 임베딩 벡터 분류 -> flask API로 새로운 데이터에 대한 예측
SVM (Support Vector Machine, SVC)
-
분류에 사용되는 지도학습 머신러닝 모델
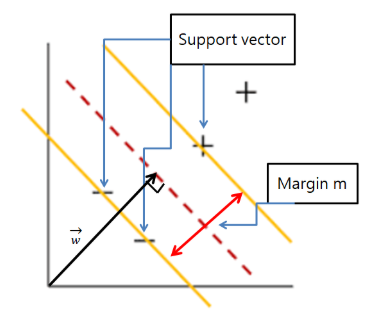
-
서포트 벡터: 클래스 사이 경계에 가깝게 위치한 데이터 포인트. 이 최외각의 벡터들을 기준으로 Margin을 구한다.
ex. 두 카테고리에 각각 해당되는 Data set들 (-가 모인 곳/+가 모인 곳)의 최외각 샘플들 -
Margin: 서포트 벡터를 통해 구한 두 카테고리 간의 거리
목표: **가중치 벡터 w와 직교**하면서, **margin이 최대**가 되는 선형 찾기
- 서포트 벡터(support vectors)를 사용해서 결정 경계(Decision Boundary)를 정의하고, 분류되지 않은 점을 해당 결정 경계와 비교해서 분류
- 퍼셉트론 기반의 모형에 가장 안정적인 결정 경계를 찾기 위해 제한 조건을 추가한 모형
- scikit-learn의 SVC 클래스를 사용하여 선형 SVM을 훈련 데이터에 적합시키고, 얼굴 데이터들을 분류
FaceNet의 Method
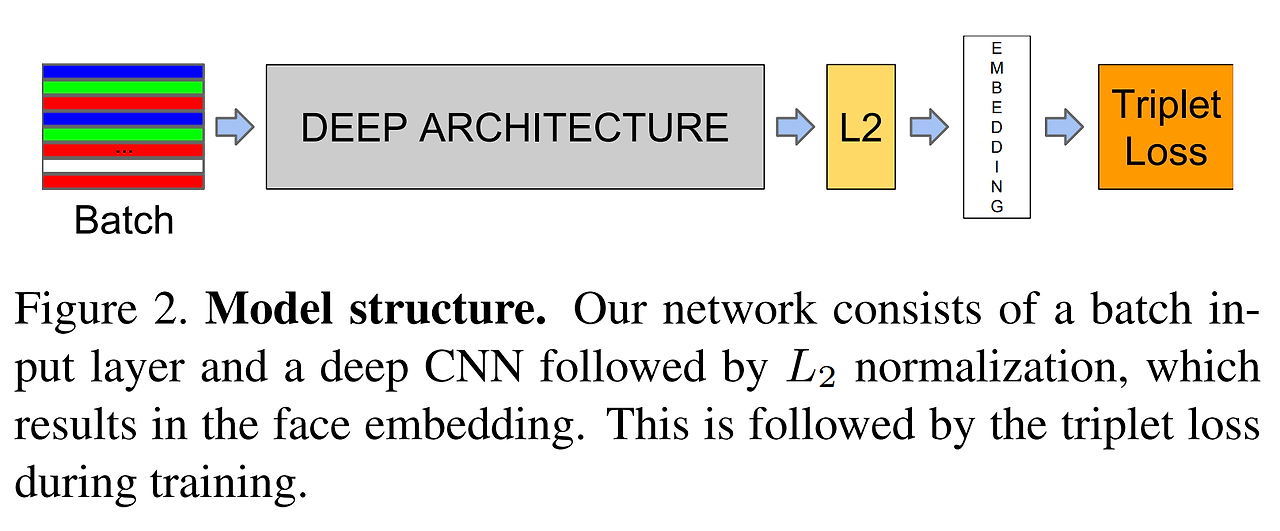
batch size:
1. Triplet loss function(삼중 항 손실)
-
얼굴 이미지의 인코딩을 학습하기 위해 신경망을 훈련시키는 데 효과적인 손실 함수
-
end-to-end 학습을 위하여 사용 (classifier를 학습시키는 것이 아니라, 최종 output인 128차원의 임베딩 벡터를 직접 학습시킴)
-
한 쌍: anchor(기준), positive(동일 인물 사진), negative(다른 인물 사진)
-
anchor - positive 거리는 가깝게, anchor - negative 거리는 멀게 학습
2. Triplet Selection
- 만들어질 수 있는 '모든' triplet 쌍을 학습데이터로 활용한다면, 쉬운 문제들로 인해 어려운 문제들을 잘 학습하지 못하게 되어 모델의 수렴 속도가 느려짐
- 맞추기 어려운 (hard positive)와 (hard negative)를 골라야 함
- 전체 데이터셋에 대해 찾기 힘들기 때문에, mini-batch 마다 triplet을 구성함
3. Deep Convolutional Network
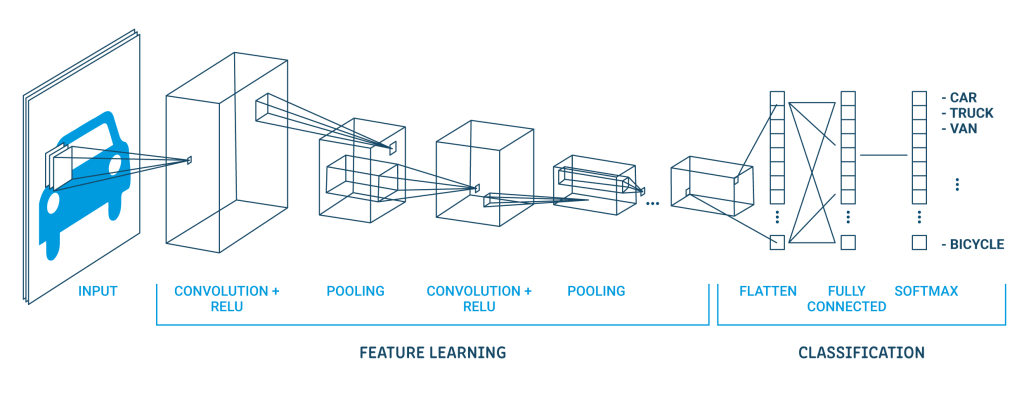
- 이미지 특징 추출 영역
: Convolution Layer(입력 데이터에 필터 적용 → 활성화 함수 반영, 필수) + Pooling Layer (Convolution 다음, 선택) - 클래스 분류 영역: Fully Connected Layer
- Flatten Layer: 특징 추출 & 분류 사이에 이미지 데이터를 배열 형태로 만들어 fully connected layer로 만듦
- Softmax Layer: classification 수행
3-1. Zeiler & Fergus architecture 기반 네트워크
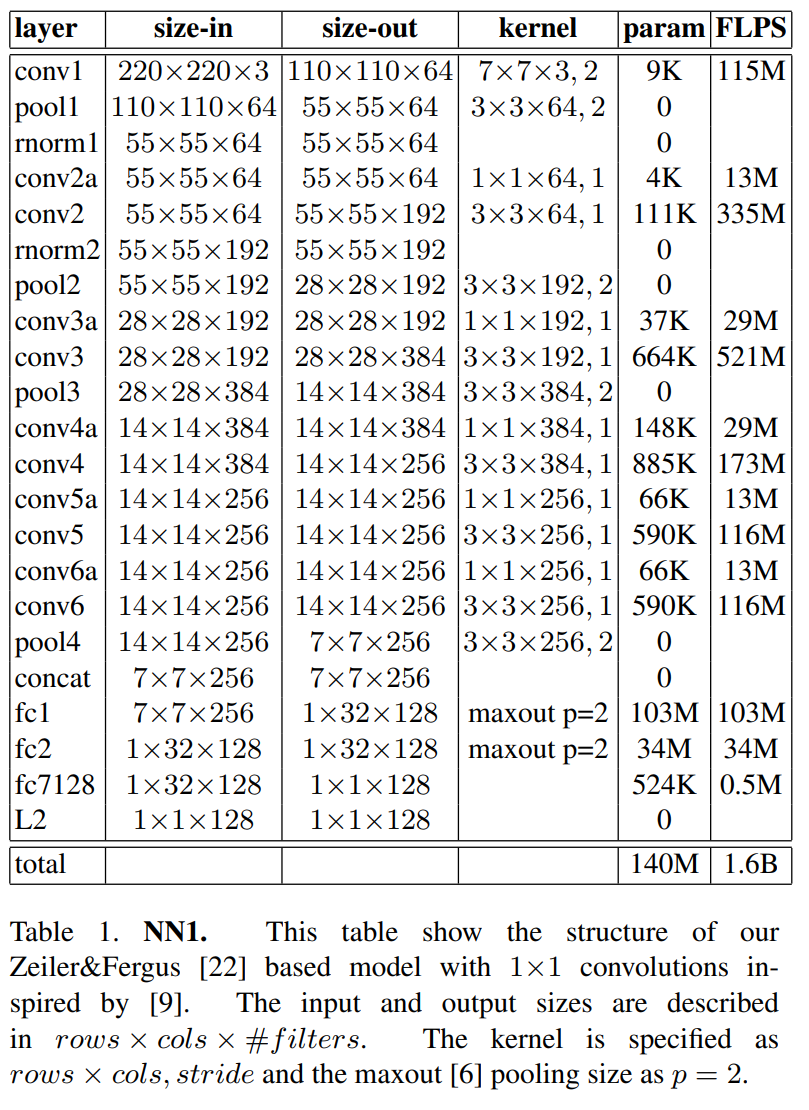
3-2. GoogLeNet 기반 네트워크
- zeiler & Fergus 기반에 비해 20배 적은 파라미터, 5배 적은 FLOPS (빠른 속도)
FaceNet: Triplet Loss 학습을 통해 이미지(input)로부터 임베딩 벡터(output)을 직접적으로 생성해내는 End-to-End 모델
