
개요
https://dataflow.spring.io/docs/feature-guides/streams/monitoring/
SCDF 공식문서에서 Prometheus와 Grafana를 활용하여 모니터링을 하도록 가이드 하고 있다.
그래서 Prometheus와 Grafana를 처음 사용해볼 겸 모니터링 시스템을 구축해보기로 하였다.
docker, docker-desktop, docker-compose
brew install docker --cask
brew install docker-compose우선 docker-compose를 활용하여 Prometheus와 Grafana를 설치해준다.
필자는 SCDF 공식문서에서 제공해주는 경로로 설치하였지만 각각 docker 이미지 경로 prom/prometheus, grafana/grafana를 통해서 설치 및 실행 할 수도 있다.
Prometheus, Grafana
wget -O docker-compose-prometheus.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/main/src/docker-compose/docker-compose-prometheus.yml
# 실행명령어
export DATAFLOW_VERSION=2.11.5
export SKIPPER_VERSION=2.11.5
docker-compose -f docker-compose.yml -f docker-compose-rabbitmq.yml -f docker-compose-postgres.yml -f ./docker-compose-prometheus.yml up -dDataflow, Skipper Server, Rabbitmq, postgresql, prometheus(grafana포함) docker-compose를 실행해준다.
https://dgjinsu.tistory.com/33
이후 Prometheus에 user-service를 target으로 등록하고 Grafana dashboard를 생성하는 과정은 위 링크를 참조하였다.
Prometheus 설정 중 문제 해결
Get "http://localhost:9000/actuator/prometheus": dial tcp [::1]:9000: connect: connection refused처음에 localhost:9000으로 target을 등록했으나 connection refused 에러가 발생했다.
이는 Prometheus는 docker 컨테이너에서 실행되고 있고 user-service는 jar파일을 실행시키고 있었기 때문이다. 이로 인해 localhost로 요청을 보내면 컨테이너 내부를 참조하게 되어 실패했던 것이다.
static_configs:
- targets: ['host.docker.internal:9000']localhost가 아닌 위 경로로 변경해주었다.
추후 user-service도 docker 컨테이너로 배포하여 다시 수정해주도록 하자.
metric name http_client_requests_seconds_count does not support exemplars위 에러는 사라졌지만 또 다른 에러가 발생했다.
docker 컨테이너 내에서 실행되는 프로세스를 확인해 보니 --enable-feature=exemplar-storage 옵션이 자동으로 추가되어 실행되고 있었다.
해당 옵션을 추가해준 적이 없었기에 원인을 찾아보았고, zipkin을 활용하기 위해 추가했던 micrometer-tracing 관련 의존성에서 해당 설정이 활성화된다는 것을 알게되었다.
micrometer-tracing은 요청 추적을 위해 traceId와 spanID를 생성하며 이를 통해 zipkin에서 요청을 추적할 수가 있는데 prometheus에서 제공되는 기본 metric 중 하나인 http_client_requests_seconds_count는 지원하지 않아 발생한 에러였다.
implementation 'io.micrometer:micrometer-tracing-bridge-brave'
implementation 'io.zipkin.reporter2:zipkin-reporter-brave'위 의존성을 아래와 같이 변경해주니 정상적으로 실행할 수 있었다.
implementation 'io.micrometer:micrometer-tracing-bridge-otel'
implementation 'io.opentelemetry:opentelemetry-exporter-zipkin'brave는 zipkin 전용이므로 다른 백엔드(Prometheus 등)로 보내려면 다양한 서비스로 전송이 가능한 otel을 사용하는 것이 권장된다.
아래와 같이 Status > Targets 탭에서 State가 up으로 보이면 정상적으로 실행 중인 것이다.
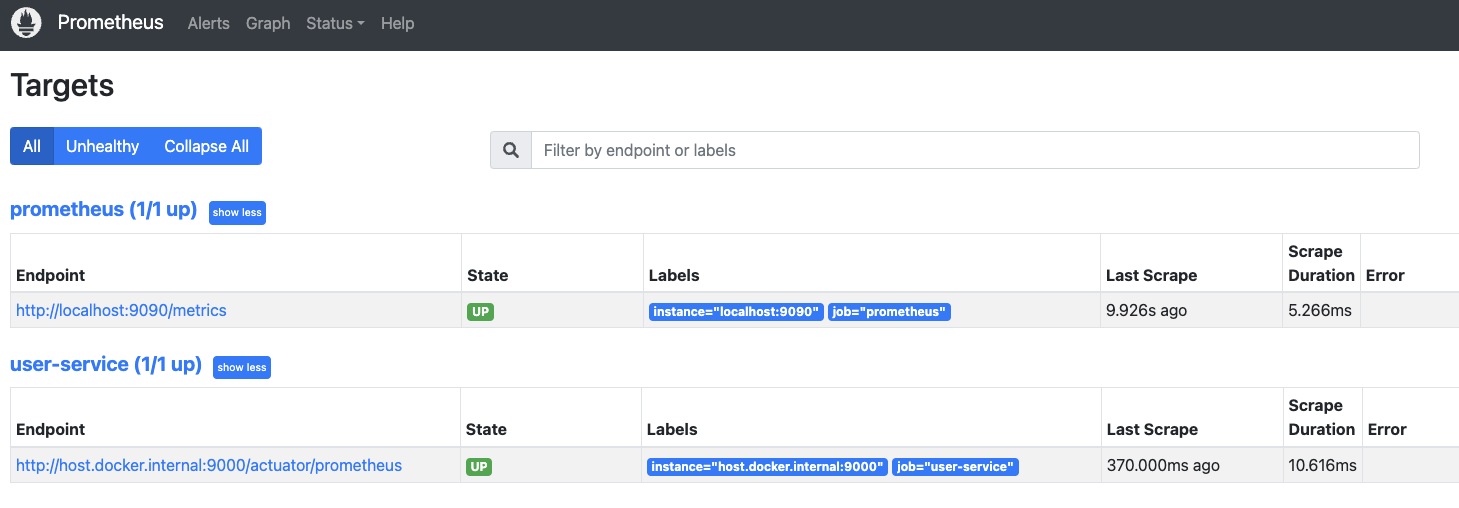
Grafana
이제 Grafana에 접속하여 datasource를 추가한 뒤 dashboard를 생성하면 된다.
https://ttl-blog.tistory.com/1366#hELLO
사실 처음 목표는 SCDF Stream, Task 관련 모니터링 설정까지 하는 것이었는데 우선 기본적인 CPU, Disk 사용량 모니터링 대쉬보드만 위 링크를 참조하여 만들었다.
(참고로 docker-compose로 prometheus를 띄웠다면 datasource를 localhost:9090이 아닌 prometheus:9090으로 연결해야한다.

알람 기능을 추가하면 추후 운영 상황에서 cpu 사용량 임계치 도달 등 상황을 파악할 수 있겠다.
직접 생성하는 방법 외에도 시중에 만들어져있는 템플릿이 많이 있다. 서비스에 필요한 템플릿을 잘 활용해보는 것도 좋을 것 같다.
마치며
아직 metric을 직접 만들어볼 정도로 actuator, prometheus, grafana에 대한 이해도가 높지 않은 것 같다. 그래서 이정도 실습까지도 굉장히 힘들게 진행했었다.
위 링크를 보니 모니터링 매트릭에 대해서만 공부해도 꽤 긴 시간을 투자해야할 것 같다는 생각이 든다.
정말 공부는 하면 할 수록 공부할 게 보인다. '지식이 증가할 수록 무지가 증가한다'는 말이 생각이 드는 시간이었고 나는 어디까지 알기를 원하는지 고민해보기도 하고 동기부여가 되기도 한 시간이었다.
지금까지는 로컬 환경에서 jar나 docker 정도를 활용하여 프로젝트를 실행시키며 진행해왔다.
그러다보니 많은 모듈을 관리하기가 어려워졌다. 하나로 통합할 필요성을 느끼게 되었다.
그래서 쿠버네티스에 대해 기초부터 학습을 해보며 현재까지의 프로젝트를 올려보려고 한다.
가능하다면 CI/CD까지 작업을 하는 것이 목표이다.
