IAM
유저를 관리하고 접근 레벨 및 권한에 대한 관리
- 접근키, 비밀키
- 매우 세밀한 접근 권한 부여 기능
- 비밀번호를 수시로 변경 가능하게 해줌
- 다중 인증 기능
EC2
-
Elastic Compute Cloud (EC2)
유연한 서버 관리 목적
-
지불 방법
- On-demand : 시간 단위로 가격이 고정
- 단기간에 마무리 되는 프로젝트
- 개발 일정이 정확하지 않을 때
- Reserved : 한정된 EC2 용량 사용 가능, 1 - 3 년동안 시간별로 할인 적용
- 개발 일정 파악이 가능할 때
- 선불로 인한 컴퓨팅 비용 감소
- Spot : 입찰 가격 적용 (경매 개념)
- On-demand : 시간 단위로 가격이 고정
EBS
-
EC2 인스턴스에 부착되는 가상 하드 디스크
-
Elastic Block Storage
- 저장 공간이 생성되어지며 EC2 인스턴스에 부착
- 디스크 불륨 위에 File System이 생성
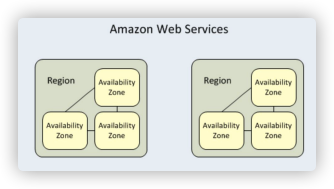
- EBS는 특정 Availabilty Zone에 생성
-
볼륨 타입
- General Purpose SSD (GP2) : 최대 10K IOPS를 지원하며 1GB당
3IOPS 속도가 나옴 - Provisioned IOPS SSD (IO1) : 극도의 I/O률을 요구하는(예시 :
매우 큰 DB관리) 환경에서 주로 사용됨. 10K 이상의 IOPS를 지원함 - Throughput Optimized HDD (ST1) : 빅데이터 Datawarehouse,
Log
프로세싱시 주로 사용 (boot volume으로 사용 가능 X) - CDD HDD (SC1) : 파일 서버와 같이 드문 volume 접근시 주로
사용, 역시 boot volume으로 사용 불가능하나 비용은 매우 저렴함 - Magnetic (Sandard) : 디스크 1GB당 가장 싼 비용을 자랑함. Boot
volume으로 유일하게 가능함
- General Purpose SSD (GP2) : 최대 10K IOPS를 지원하며 1GB당
ELB
-
Elastic Load Balancers
- 수많은 서버의 흐름을 균형있게 흘려보내는데 중추적인 역할
- 하나의 서버로 트래픽이 몰리는 병목현상 방지
- 트래픽의 흐름을 Unhealthy instance → healthy instance
-
종류
- Application Load Balancer
- HTTP, HTTPS와 같은 traffic의 load balancing에 가장 적합함
- 고급 request 라우팅 설정을 통하여 특정 서버로 request를
보낼 수 있음
- Network Load Balancer : OSI Layer4에서 작동됨, 매우 빠른
속도를 자랑하며 Production환경에서 종종 쓰임
- 극도의 performance가 요구되는 TCP traffic에서 적합함
- 초당 수백만개의 request를 아주 미세한 delay로 처리 가능 - Classic Load Balancer : 현재 Legacy로 간주됨, 따라서 거의
쓰이지 않음
- Layer7의 HTTP/HTTPS 라우팅 기능 지원
- Layer4의 TCP traffic 라우팅 기능도 지원
- Application Load Balancer
-
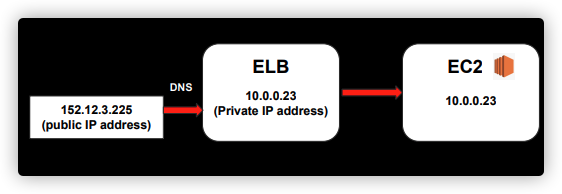
ERROR → 504 ERROR
-
X-Forwarded-For 헤더
EC2의 IP로 퍼블릭 아이피를 확인 할 수 있음
Route 53
- AWS에서 제공하는 DNS 서비스
- EC2 instance
- S3 Bucket
- Load Balancer
RDS
-
Relational DB Service (관계형 데이터베이스)
-
DB 종류
- Microsoft SQL
- Oracle
- MySql
- Postgre
- Aurora
- Maria DB
-
Data Warehousing
- 리포트 작성, 데이터 분석시 사용
- 매우 방대한 분량의 데이터 로드시 사용
-
OLTP vs OLAP
- OLTP : Transactional, 규모가 작은 데이터 불러오거나 Insert
- OLAP : 매우 큰 데이터를 불러올때 사용, 덩치큰 SELECT
-
Automated Backups - 자동 백업
- Retention Period (1-35일) 안의 어떤 시간으로 돌아가게 할 수 있음
- RDS 셋팅 시 기본으로 설정
- AB동안 약간의 딜레이가 생길 수 있음
-
DB Snapshots
- 원본 RDS 인스턴스를 삭제해도 보관이 유지됨
-
Multi AZ
- 원래 존재하는 RDS DB에 무언가 변화가 생길때 다른 Availability Zone에 똑같은 복제본이 만들어짐 (싱크)
- 원본 RDS DB에 문제가 생길 시 자동으로 다른 AZ의 복제본이 사용됨
-
Read Replica
- 성능을 극대화하기 위해 존재
- Production DB의 읽기 전용 복제본이 생성됨
- 복구 용도가 아님 (Disaster Recovery)
- 각각의 고유 엔드포인트 존재
-
ElasticCache
- RDS의 더효율적인 퍼포먼스를 도와줌
- 데이터베이스에서 데이터를 읽는 것이 아니라 캐시에서 빠른 속도로 데이터를 읽어옴
- Read-Heavy 어플리케이션에서 상당한 Latency 감소 효과 누림
- 테스트 용도로 사용하기에는 적합하지 않음 (요금)
- 종류
- Memcached
- Object 캐시 시스템
- EC2 Auto Scaling처럼 크기가 유동적으로 변경 가능함
- Memcached의 프로토콜을 디폴트로 따름
- 오픈소스
- 언제 사용할까요
- 가장 당순한 캐싱 모델
- Object caching 목적
- 캐시 크기를 자유롭게
- Redis
- key-value, set, List와 같은 형태의 데이터를 In-Memory에 저장 가능
- 오픈소스
- Multi-AZ 지원 (재해복구 대응 가능)
- 언제 사용할까요
- List, Set 과 같은 데이터셋 사용
- 리더보드처럼 데이터셋의 랭킹을 정렬하는 용도
- Multi-AZ
- Memcached
대표적인 예시로 실시간 TOP10의 데이터를 가져오는 경우
S3
- Simple Storage Service
- 안전하고 가변적인 Object 저장공간을 제공
- 저장공간 무제한
- Bucket이라는 이름을 사용 (디렉토리와 유사)
- Bucket 이름은 namespace
- S3 Object 구성요소
- key
- value
- version ID
- metadata
- cors
- S3 DATA Consistency Model
- Read after Write Concistency (PUT)
- Eventual Consistency (UPDATE, DELETE)
CloudWatch
- AWS 리소스 사용의 실시간 모니터링 기능 지원
- 다양한 이벤트들을 수집하여 로그파일로 저장
- 이벤트&알람 설정을 통해 SNS, AWS Lambda로 전송 가능
- 사용 가능 서비스 : EC2, RDS, S3, ELB 등
- 모니터링 종류
- Basic Monitoring
- 무료
- 5분 간격 제공
- Detail Montoring
- 유료
- 1분 간격 제공
- Basic Monitoring
- 사용 용례
- Use Case : 매일 얼마나 많은 사용자들이 모바일 앱을 사용하는지 알고 싶음
- Potential Issue : 똑같은 비용을 내며 AWS 리소스들을 사용하지만 낮과 밤의 필요한 서버의 성능은 달라질 수 있기 때문에 금전적 손실이 생길 수 있음
- Solution : 알람 설정을 통하여 특정 threshold에 대해 발생 시 개발자에게 알람 제공
- Alarm
- 임의로 정해놓은 값에 도달할 시 Alerm을 울림
- 특정이벤트들을 작동 시킬 수 있음
Lambda
- Serverless의 주축을 담당
- Events를 통하여 Lambda를 실행
- NodeJS, Python, Java, Go 등 다양한 언어 지원
- Lambda function
- 최대 300초 런타임 시간 허용
- 최대 50MB deployment package 허용
- s3 버켓 사용을 하면 예외적으로 가능
- 사용 용례
- S3 → Lambda → DB
CloudFront
- 분산 네트워크
- 정적, 동적 콘텐츠에 대한 정보를 빠르게
- CDN
- 용어 정리
- Edge Location (엣지 지역) : 컨텐츠들이 캐시에 보관되어지는 장소
- Origin : 원래 콘텐츠들이 들어있는 곳, 웹서버 호스팅이 되어지는 곳. S3 또는 EC2 인스턴스
- Distribution (분산)
DynamoDB
- NoSQL (Not Only SQL) 데이터 베이스
- 매우 빠른 쿼리 속도
- Auto-Scaling 기능 탑재
- 데이터의 크기에 상관없이 유동적으로 변경이 가능
- Key-Value 데이터 모델 지원
- 테이블 생성시 스키마 생성 필요 없음
- 모바일, 웹, IoT데이터 사용시 추천됨
- SSD 스토리지 사용
- 구성
- 테이블 (Table)
- 아이템 (Items) - 행(row)과 개념이 비슷함
- 특징 (Attributes) - 열(column)과 개념이 비슷함
- Key-Value
- JSON, XML
- Primary Keys (PK)
- PK를 사용하여 데이터 쿼리
- 두가지 PK 유형
- 파티션키 (Partition Key)
- 고유 특징
- 실제 데이터가 들어가는 위치를 결정해줌
- 파티션키 사용시 동일한 두개의 데이터가 같은 위치에 저장될 수 없음
- 복합키 (Composite Key)
- 파티션키 + 정렬키 (Sort Key)
- 예시) 똑같은 고객이 다른 날짜에 다른 물건을 구매
- 파티션키 : 고객아이디, 정렬키 : 날짜
- 같은 파팃녀키의 데이터들은 같은 장소에 보관, 그다음 정렬키에 의해 데이터가 정렬됨
- 파티션키 (Partition Key)
- 데이터 접근 관리
- AWS IAM으로 관리 가능
- 테이블 생성과 접근 권한 부여
- 특정 테이블, 데이터 접근 가능한 IAM 역할 존재
- AWS IAM으로 관리 가능
- Index
- 특정 컬럼만을 사용하여 쿼리
- 테이블 전체가 아닌 기준점을 사용해 쿼리가 이루어짐
- 매우 큰 쿼리 성능 효과
- 두가지 유형 존재
- Local Secondary Index (LSI)
- 테이블 생성시에만 정의해줄 수 있음
- 따라서 테이블 생성 후 변경, 삭제가 불가능
- 똑같은 파티션키 사용, 그러나 다른 정렬키 사용
- Global Secondary Index (GSI)
- 테이블 생성후에도 추가, 변경, 삭제 가능
- 다른 파티션키, 정렬키 사용
- Local Secondary Index (LSI)
- Query VS Scan
- Query
- PK를 사용하여 데이터 검색
- Query 사용시 모든 데이터 (컬럼) 반환
- ProjectionExpression 파라미터 → 보고싶은 컬럼만 설정 가능 (필터링 역할 담당)
- Scan
- 모든 데이터를 불러옴 (PK 사용 X)
- ProjectionExpression 파라미터
- Look-up 테이블에서 사용하기 좋음 (PK없는)
- 비교
- Query가 Scan보다 훨씬 효율적임
- 따라서 Query 사용 추천
- Query
- DAX
- DynamoDB Accelerator
- 클러스터 In-Memory 캐시
- 10배 이상의 속도 향상
- 읽기 요청만 해당
- 수많은 읽기 요청이 있는 쇼핑 웹사이트 운영
- 원리
- DAX 캐싱 시스템 → 테이블에 데이터 삽입 & 업데이트시 DAX에도 반영
- 읽기 요청에 맞는 데이터가 DAX에 들어있을시 DAX에서 데이터 즉시 반환
- 단점
- 쓰기 요청이 많은 어플리케이션에서는 부적절함
- 읽기 요청이 많지 않은 어플리케이션에서 부적절함
- 아직 모든 지역에서 제공하지 않음
- DynamoDB Stream
- 삽입, 수정, 삭제 등 일어날 시 시간적 순서에 맞게 Steams에 기록
- Log는 즉각 암호화가 일어나며 24시간 동안 보관
- 주로 이벤트를 기록하고 이벤트 발생을 외부로 알리는 용도
- 이벤트 전&후에 대한 상황 보관
API Gateway
- 뛰어난 확장성 제공 및 API를 만들고 운영하고 모니터링 기능
- Back-end 서비스에 들어있는 데이터 접근 허용
CI/CD
- CI : Continuous Integration (지속적인 통합)
- CD : Continuous Deployment (지속적인 배포)
장점
- 자동화 시스템 - 테스트
- Incremental Change
Code Commit
- 파일들을 보관하는 저장 장소 (Repository) - Github와 유사
- 동시에 많은 사람들이 저장 장소 접근 및 업데이트 가능
- 버전 컨트롤 기능 제공
Code Deploy
- 자동 배포 (Automated Deployment)
장점
- 새로운 기능들의 빠른 배포
- 소프트웨어 & 서버 다운타임 X
종류
- Rolling 배포
- Blue/Green 배포 (현재/신규)
Code Pipeline
CI/CD의 끝판왕
- 빌드, 테스트, 배포 과정을 관리
- 코드 변경 시 Code Pipeline은 감지 할 수 있음
- 소프트웨어 및 어플리케이션 출시 자동화 가능
- 빠르고 쉬운 디버깅을 가능하게 해줌

server developer