Multi-Node Setting 과 Deepspeed Guide
팀 내에서 자체 3D 생성 모델의 training 에 관련된 일을 주로 맡고 있는데,
비디오나 이미지만큼은 아니어도 3D 생성 모델도 1B 이상의 꽤 큰 Transformer 모델 (DiT) 을 학습시켜야 하는 일이라 multi-node 학습이 필수적이다.
오늘은 사내 클러스터와 AWS 환경에서 multi-node 학습 환경을 세팅하고, DeepSpeed 를 활용하여 모델을 분산 학습시킨 경험을 정리해보고자 한다.
1. Infrastructures:
- A100 80G infiniband x 4 (사내 GPU팜)
- A100 80G efa x 8 (aws)
우선 multi-node training 의 가장 중요한 점은 단순히 GPU node 가 여럿 필요한 것이 아니라, 고속 Network Interface 로 internode 간 연결 된 장비가 필수적이라는 점이다.
큰 모델을 나누어서 학습할 때는 모델 parameter 뿐만 아니라 gradient 를 나누고, 이를 합쳐서 업데이트 한 후 다시 각 노드로 분배하는 엄청난 network communication 이 필요하다. 따라서 통신 병목이 없어야만 큰 모델을 무리없이 학습할 수 있다. (nccl 이 일반 ethernet 규격도 지원하긴 하지만, 엄청난 통신 병목 때문에 학습 속도가 절망적이다 ㅎㅎ ㅠ)
참고로 같은 node 안에서는 NVLink 로 GPU 간 통신에 최대한 병목이 없도록 설계되어 있다.
(이는 nvidia-smi topo -m 을 통해 확인할 수 있음)

반면, 노드 간 통신에는 주로 NVIDIA 자체 규격인 Infiniband 가 사용되며, AWS 의 경우 자체 고속 네트워크 규격인 EFA(Elastic Fabric Adapter) 를 통해 internode network interface 가 설정되어 있다.
시스템에 InfiniBand 나 EFA 가 올바르게 설정되었는지는 다음 명령어를 통해 확인할 수 있다.
# InfiniBand
ls -al /dev/infiniband/
ibv_devinfo
# EFA
fi_info -p efa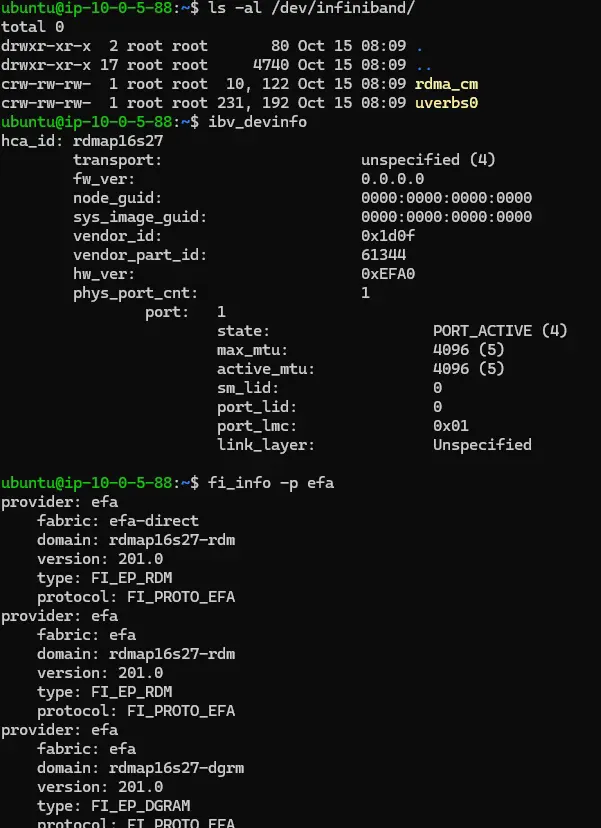
이러한 고속 네트워크 인터페이스는 nccl 이 자동으로 감지하고 사용하기 때문에, 아래처럼 환경 변수만 설정해주면 deepspeed 나 FSDP 등 distributed training framework 에서 복잡한 설정 없이 환경 변수 설정만으로 손쉽게 활용할 수 있다.
# EFA 사용을 위한 env path 설정 (Dockerfile 에 명시)
export FI_PROVIDER=efa
export FI_EFA_USE_DEVICE_RDMA=1
export NCCL_PROTO=simple2. Settings
2.1. Docker
모든 노드가 같은 docker 환경을 공유해야하므로, 필요한 라이브러리와 설정을 담은 Dockerfile 을 만들어두고 이를 기반으로 image 를 빌드하여 사용하였다.
- 사내 환경: 빌드한 이미지를 사내 docker harbor 에 업로드한 뒤, 각 노드에서 해당 이미지를 pull 해 dev container 환경을 구축하였다.
- AWS: 사내 네트워크 정책상 (inbound/outbound 모두 막혀있음) 외부에서 harbor 접근이 불가능했기 때문에, aws 의 container repository 서비스인
ecr을 활용하였다. 에 사내에서 build 한 image 를 push 한 후, 각 ec2 instance 에서 pull 하여 container 를 구동하는 방법을 사용하였다.

aws ecr get-login-password --region ap-northeast-2 | \
docker login --username AWS --password-stdin <account-id>.dkr.ecr.ap-northeast-2.amazonaws.com2.2. Docker Run
EFA
고속 네트워크 인터페이스를 컨테이너 내부에서 사용하기 위해서는 몇 가지 추가적인 설정이 필요하다.
docker run --gpus all \
--network host \
--cap-add=IPC_LOCK \
--device=/dev/infiniband/uverbs0 \
--device=/dev/infiniband/rdma_cm \
-v /opt/amazon/efa:/opt/amazon/efa:ro \
-v /fsx:/fsx \
--ulimit memlock=-1:-1 \
--shm-size=512g \
<image> bash--network host: container 가 호스트의 network namespace 를 공유하여 EFA 인터페이스에 직접 접근할 수 있도록 설정--device&-v: RDMA 및 EFA driver/library 를 container 에 마운트하여 docker 내부에서nccl이 efa network 에 접근할 수 있도록 허용--cap-add=IPC_LOCK,--ulimit memlock=-1:-1: RDMA가 사용하는 메모리를 물리 메모리에 고정할 수 있도록 허용하고 메모리 잠금 제한을 해제하여 성능을 최적화--shm-size=512g: 공유메모리 크기를 충분히 설정하여 데이터 전송 효율을 높였다.
cf. data I/O bound 를 최소화하기 위하여 FSx for lustre 에 데이터셋을 올려두고, 각 노드에서 이를 마운트하여 데이터 로딩에 사용했다.
Infiniband
InfiniBand 환경에서도 위와 거의 동일한 설정을 사용한다.
한 가지 팁으로, 네트워크 인터페이스를 명시적으로 지정하는 NCCL_SOCKET_IFNAME 설정의 경우 ibstat 이나 ip link 명령어로 정확한 인터페이스 이름을 찾아 설정할 수도 있지만, 그렇지 않고 불필요한 인터페이스를 제외하는 방식으로 설정해도 대부분 문제없이 동작한다.
ENV NCCL_SOCKET_IFNAME="^docker0,lo"ex) NCCL_SOCKET_IFNAME 명시적 설정 예시
# infiniband 관련 속성을 볼 수 있음
ibstat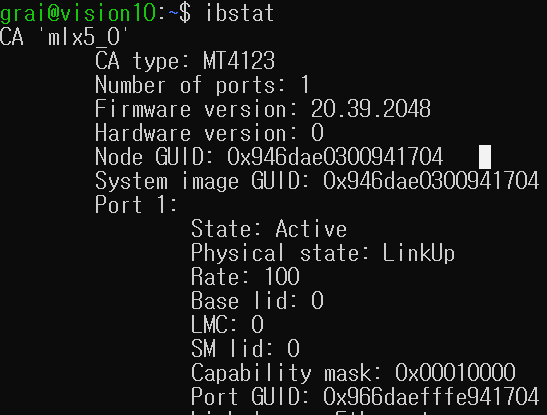
ip link로 나오는 네트워크 interface 목록 중 ibstat 의 Node GUID 와 같은 MAC 을 갖는 인터페이스를 찾아서 설정하면 된다.
즉, 위 경우엔 ip link 에서 link/infiniband 타입의 94:6d:ae:94:17:04 MAC 의 IP address 가 MASTER_NODE_IP 로, 이 인터페이스 이름은 NCCL_SOCKET_IFNAME 으로 설정.
2.3. Toy Experiment
모든 설정이 완료되면, 간단한 코드를 실행하여 멀티노드 학습의 핵심 연산인 all_reduce 와 all_gather 가 정상적으로 동작하는지 확인하는 것이 중요하다.
아래는 torch.distributed 를 사용하여 분산 환경을 설정하고, 간단한 모델 학습과 all_reduce 연산을 테스트하는 예제 코드이다.
# /app/dist_test.py
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, Dataset, DistributedSampler
import os
import time
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.linear = nn.Linear(10, 1)
def forward(self, x):
return self.linear(x)
class ToyDataset(Dataset):
def __init__(self, size=128):
self.size = size
self.data = torch.randn(size, 10)
self.labels = torch.randn(size, 1)
def __len__(self):
return self.size
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
def setup_distributed():
if not dist.is_available():
print("torch.distributed is not available!")
exit(1)
dist.init_process_group(backend='nccl', init_method='env://')
local_rank = int(os.environ['LOCAL_RANK'])
torch.cuda.set_device(local_rank)
node_rank = os.environ.get('NODE_RANK', 'N/A')
print(f"[Node {node_rank}, LocalRank {local_rank}, GlobalRank {dist.get_rank()}] Initialized. Using GPU: {torch.cuda.current_device()} ({torch.cuda.get_device_name(torch.cuda.current_device())})")
def cleanup_distributed():
node_rank = os.environ.get('NODE_RANK', 'N/A')
local_rank = os.environ.get('LOCAL_RANK', 'N/A')
global_rank_val = "N/A"
if dist.is_initialized():
global_rank_val = dist.get_rank()
print(f"[Node {node_rank}, LocalRank {local_rank}, GlobalRank {global_rank_val}] Cleaning up.")
dist.destroy_process_group()
def main():
setup_distributed()
local_rank = int(os.environ['LOCAL_RANK'])
global_rank = dist.get_rank()
world_size = dist.get_world_size()
node_rank_env = os.environ.get('NODE_RANK', 'N/A')
gpus_per_node_env = os.environ.get('GPUS_PER_NODE', 'N/A')
print(f"--- [Node {node_rank_env}, GlobalRank {global_rank}] Starting main worker. World size: {world_size}, GPUS_PER_NODE: {gpus_per_node_env} ---")
# DDP
model = ToyModel().to(local_rank)
ddp_model = DDP(model, device_ids=[local_rank], output_device=local_rank)
# set data_size % world_size = 0 or drop_last=True
dataset_size = 64
batch_size_per_gpu = 4
if dataset_size % world_size != 0:
print(f"[GlobalRank {global_rank}] Warning: Dataset size {dataset_size} is not divisible by world_size {world_size}. Some data might be dropped or repeated depending on sampler.")
dataset = ToyDataset(size=dataset_size)
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=global_rank, shuffle=True)
# DataLoader는 각 GPU당 batch_size를 의미
dataloader = DataLoader(dataset, batch_size=batch_size_per_gpu, sampler=sampler, pin_memory=True, num_workers=2)
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
criterion = nn.MSELoss()
num_epochs = 2
print(f"[GlobalRank {global_rank}] Starting dummy training for {num_epochs} epochs...")
for epoch in range(num_epochs):
sampler.set_epoch(epoch) # DistributedSampler
epoch_loss = 0.0
for batch_idx, (inputs, labels) in enumerate(dataloader):
inputs = inputs.to(local_rank)
labels = labels.to(local_rank)
optimizer.zero_grad()
outputs = ddp_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
if batch_idx % 5 == 0 :
print(f"[Node {node_rank_env}, GlobalRank {global_rank}, Epoch {epoch+1}, Batch {batch_idx}] Loss: {loss.item():.4f}")
avg_epoch_loss = epoch_loss / len(dataloader)
print(f"[Node {node_rank_env}, GlobalRank {global_rank}, Epoch {epoch+1}] Average Epoch Loss: {avg_epoch_loss:.4f}")
# all_reduce test
print(f"\n[Node {node_rank_env}, GlobalRank {global_rank}] Starting all_reduce test...")
tensor_to_reduce = torch.ones(1, device=local_rank) * (global_rank + 1)
print(f"[Node {node_rank_env}, GlobalRank {global_rank}] Tensor before all_reduce: {tensor_to_reduce.item()}")
dist.all_reduce(tensor_to_reduce, op=dist.ReduceOp.SUM)
print(f"[Node {node_rank_env}, GlobalRank {global_rank}] Tensor after all_reduce (SUM): {tensor_to_reduce.item()}")
# Rank 0에서 결과 검증
if global_rank == 0:
expected_sum = sum(range(1, world_size + 1))
if abs(tensor_to_reduce.item() - expected_sum) < 1e-5:
print(f"[Node {node_rank_env}, GlobalRank 0] AllReduce test PASSED. Got {tensor_to_reduce.item()}, expected {expected_sum}")
else:
print(f"[Node {node_rank_env}, GlobalRank 0] AllReduce test FAILED. Got {tensor_to_reduce.item()}, expected {expected_sum}")
# barrier 테스트
print(f"\n[Node {node_rank_env}, GlobalRank {global_rank}] Reaching barrier...")
time.sleep(global_rank * 0.2)
dist.barrier()
print(f"[Node {node_rank_env}, GlobalRank {global_rank}] Passed barrier. All processes synchronized.")
cleanup_distributed()
print(f"--- [Node {node_rank_env}, GlobalRank {global_rank}] Worker finished. ---")
if __name__ == "__main__":
required_env_vars = ['MASTER_ADDR', 'MASTER_PORT', 'RANK', 'WORLD_SIZE', 'LOCAL_RANK']
missing_vars = [var for var in required_env_vars if var not in os.environ]
if missing_vars:
print(f"Error: Missing required environment variables set by torchrun: {missing_vars}")
print("This script is intended to be launched using 'python -m torch.distributed.run ...'")
exit(1)
node_rank_user = os.environ.get('NODE_RANK', 'UNKNOWN_NODE')
total_nodes_user = os.environ.get('TOTAL_NODES', 'UNKNOWN_TOTAL_NODES')
gpus_per_node_user = os.environ.get('GPUS_PER_NODE', 'UNKNOWN_GPUS_PER_NODE')
print(f"Starting PyTorch Distributed Test on Node {node_rank_user}/{total_nodes_user} with {gpus_per_node_user} GPUs per node.")
print(f"Master: {os.environ['MASTER_ADDR']}:{os.environ['MASTER_PORT']}, WorldSize: {os.environ['WORLD_SIZE']}, GlobalRank: {os.environ['RANK']}, LocalRank: {os.environ['LOCAL_RANK']}")3. Distributed Training
멀티 노드 학습을 위한 세팅이 끝났다면, 학습할 모델의 학습 코드 또한 multi-node training 용으로 wrapping 해줄 필요가 있다.
대표적인 분산학습 방법은 PyTorch native 인 DistributedDataParallel(DDP) 이다. 하지만 DDP는 각 GPU가 모델 전체의 복사본을 보유해야 하므로, 모델의 크기가 GPU 메모리 용량을 초과하면 사용할 수 없다는 근본적인 한계를 가진다.
3.1. Limitations of DDP
DDP 에서 각 GPU 는 모델 전체의 복사본과 optimizer state 를 독립적으로 소유한다.
학습 단계에서는 각 GPU 가 데이터의 일부(mini-batch)를 처리하여 local gradient 를 계산하고, all_reduce 연산을 통해 모든 GPU 의 gradient 를 동기화하여 평균을 낸 뒤, 동일한 parameter update 를 수행한다.
- Pros: 구현이 간단하고, communication overhead 가 gradient 동기화에만 집중되어 상대적으로 적다.
- Cons: Memory Redundancy.
N개의 GPU를 사용하면, model parameter 와 optimizer state 가N번 중복되어 저장된다. 이 때문에 모델 크기가 단일 GPU 의 메모리를 초과하면 학습이 불가능한 근본적인 한계가 있다.
3.2. DeepSpeed & FSDP
이러한 메모리 한계를 극복하기 위해 등장한 개념이 바로 Sharding 이다. 모델을 구성하는 거대한 tensor (parameter, gradient, optimizer state) 를 잘게 조각내어 여러 GPU 에 분산 저장하는 기술이다.
대표적으로 Microsoft의 DeepSpeed 는 ZeRO (Zero Redundancy Optimizer) 라는 이름으로 이 개념을 구현하여 큰 성공을 거두었다.
- ZeRO-1: Optimizer States 분산 저장
- ZeRO-2: Optimizer States & Gradients 분산 저장
- ZeRO-3: Optimizer States & Gradients & Parameters 까지 모두 분산 저장
FSDP 라는 PyTorch native sharding solution 또한 존재하며, 개념적으로 DeepSpeed의 ZeRO-3 와 매우 유사하다. FSDP는 모델의 모든 구성 요소를 WORLD_SIZE(전체 GPU 수)만큼 분할하여 각 GPU가 1/N의 책임만 지도록 한다.
대략적으로 다음과 같은 과정을 통해 ZeRO-3 의 sharding strategy 가 이루어져 있다.

- Forward Pass: 각 layer 를 실행하기 직전, 필요한 parameter 조각들을
all_gather연산을 통해 모든 GPU 로부터 수집하여 layer 를 재구성하고 연산을 수행한다. 연산이 끝나면 즉시 수집했던 parameter 를 해제하여 메모리를 확보한다. - Backward Pass: Forward와 유사하게, gradient 계산에 필요한 parameter 를
all_gather로 수집한다. gradient 계산이 끝나면, 각 GPU 는 자신이 담당하는 parameter 조각에 해당하는 gradient 만 남기고reduce_scatter연산을 통해 합산한다. 이후 불필요한 gradient 는 메모리에서 해제된다.
4. Deepspeed Guide
여기서부턴 실제로 3D 생성 모델 학습 때 사용했던 deepspeed configs 와 train 코드 snippet 을 통해 deepspeed 에 대한 guide 를 작성한다.
설치 등은 공식 repo 를 참조하기 바란다.
4.1. ds_config.json
deepspeed 는 설치 후 deepspeed 관련 configures 만 세팅해주고, deepspeed 에 맞게 model wrapping 만 완료하면 기존 PyTorch 코드에서 수정이 거의 없이 바로 multi-node training 으로 사용 가능하다.
주로 다음과 같은 구조로 이루어져 있으며, 상세하게 각 configs 요소에 대해서 설명하도록 하겠다.
{
"train_batch_size": 128,
"train_micro_batch_size_per_gpu": 1,
"gradient_accumulation_steps": 2,
"steps_per_print": 2000,
"zero_optimization": { ... },
"fp16": { ... },
"optimizer": { ... },
"ema": { ... },
"scheduler": { ... },
"gradient_clipping": 1.0,
"wall_clock_breakdown": false
}a. batch size
{
"train_batch_size": 128,
"train_micro_batch_size_per_gpu": 1,
"gradient_accumulation_steps": 2
}train_batch_size: 전체 배치 크기 (모든 GPU 총합)train_micro_batch_size_per_gpu: GPU 당 실제 처리하는 micro batch 크기gradient_accumulation_steps: gradient accumulation 횟수
해당 세팅은 간단한 다음의 공식을 기억하고 있으면 쉽다.
이는 다음과 같은 이유로 설정한 것이며, 모델이나 데이터에 따라 유동적으로 설정하면 된다.
- 메모리 제약: GPU당 1 개의 샘플만 처리하여 OOM 방지
- 효과적인 배치 크기: Gradient Accumulation 으로 큰 배치 효과
- 통신 오버헤드 감소: 2스텝마다 한 번만 All-Reduce 수행
b. ZeRO Optimization
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"contiguous_gradients": true,
"overlap_comm": true,
"allgather_bucket_size": 5e7,
"reduce_bucket_size": 5e7,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_prefetch_bucket_size": 1e7,
"stage3_param_persistence_threshold": 1e6
}
}-
Stage
각 Stage 별 특징과 장단점은 다음과 같이 간략하게 정리할 수 있는데,
Stage 분산 대상 메모리 절감 통신 오버헤드 적합한 경우 1 Optimizer States 4배 낮음 작은 모델 2 Optimizer + Gradients 8배 중간 대부분의 경우 3 Optimizer + Gradients + Params 64배+ 높음 거대 모델 우리 프로젝트의 경우 모델의 크기가 (llm 에 비해 상대적으로는) 크지 않아 Stage 3 의 communication overhead 대비 메모리 이득이 크지 않았기 때문에 Stage 2 를 선택하였다.
또한 model 크기 때문에 oom 이 되는 상황이 아니라면 parameter 는 자주 접근되므로 GPU 에 유지하는 것이 효율적이다.
-
CPU Offloading
CPU offloading 이란 모델 학습에 필요한 일부 정보를 (e.g., optimizer states 의 momentum, variance) CPU RAM 에 저장하여 사용하는 기술이다. CPU-GPU 데이터 전송 오버헤드가 발생하여 training 속도와의 trade-off 가 있지만, 1.5B size 정도의 model 학습 땐 12GB 정도의 vram 절감 효과가 있어서 trade-off 를 일부 감소하고 offloading 을 활용하였다.{ "offload_optimizer": { "device": "cpu", "pin_memory": true } } -
Communication Parameters
{ "contiguous_gradients": true, "overlap_comm": true, "allgather_bucket_size": 5e7, "reduce_bucket_size": 5e7 }- contiguous_gradients: 그래디언트를 연속된 메모리에 저장 (통신 효율 향상)
- overlap_comm: 계산과 통신 중첩
- bucket_size: 작은 텐서들을 버킷으로 묶어 한 번에 전송 (통신 횟수 감소)
등의 옵션으로 통신 효율을 극대화했다.
버킷 크기 설정 가이드:
| small bucket | medium bucket | large bucket |
|---|---|---|
| 1e7 | 5e7 | 1e8 |
| 적은 메모리, 빈번한 통신 | 균형잡힌 설정 | 많은 메모리, 적은 통신 |
그밖에 mixed precision, gradient clipping 등의 설정을 통해 학습 안정성을 더 높게 확보하였다.
5. Deepspeed training code migration
5.1. DeepSpeed 초기화
a. Distributed settings
dist_utils.init_distributed()
world_size = dist_utils.get_world_size()
rank = dist_utils.get_rank()
local_rank = int(os.environ.get('LOCAL_RANK', args.local_rank))
if local_rank < 0:
local_rank = 0
device = torch.device("cuda", local_rank)중요 개념:
- world_size: 전체 프로세스 수 (총 GPU 수)
- rank: 전역 프로세스 ID (0부터 world_size-1)
- local_rank: 노드 내 GPU ID (0부터 노드당 GPU 수 -1)
예시 (2 노드 × 4 GPU):
Node 0: rank=0,1,2,3 local_rank=0,1,2,3
Node 1: rank=4,5,6,7 local_rank=0,1,2,3b. DataLoader와 DistributedSampler
# train.py:186
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank, shuffle=True)
dataloader = DataLoader(
dataset,
batch_size=cfg['data']['batch_size'],
sampler=sampler,
collate_fn=sparse_collate_fn,
pin_memory=True,
persistent_workers=True
)DistributedSampler 는 전체 데이터셋을 world_size 로 나누어 각 GPU (rank) 가 중복 없이 데이터의 일부만 처리하도록 자동으로 할당해준다.
중요 설정:
pin_memory=True: CPU → GPU 전송 속도 향상persistent_workers=True: Worker 재사용 → 메모리 누수 방지
5.2. DeepSpeed Model Initialization
deepspeed 로 model 을 traning 하기 위해서는, nn.module object 인 모델과 옵티마이저 등을 deepspeed 의 initialize 함수로 wrapping 해주기만 하면 된다.
model_engine, optimizer, _, _ = deepspeed.initialize(
args=args,
model=trainer,
model_parameters=[p for p in trainer.parameters() if p.requires_grad],
config=cfg['deepspeed']['config_path'] # 'ds_config.json'
)이때, return 된 객체들은 각 다음과 같다.
model_engine: DeepSpeed로 래핑된 모델 (원본은model_engine.module로 접근)optimizer: DeepSpeed가 생성한 optimizer- 나머지: scheduler 등 (config에서 정의 시 반환)
이제 train 의 남은 코드 부분은 model 대신 model_engine 으로만 대체하여 사용하면 된다.
(backward 나 optimizer step 등의 모든 연산)
5.3 Checkpoint save & load
deepspeed 로 학습된 모델은 다음과 같은 코드 스니펫으로 저장할 수 있으며,
model_engine.save_checkpoint(
cfg['logging']['log_dir'], # './logs'
tag="step_0", # checkpoint tage
client_state={'global_step': 0} # custom state (step, epoch...)
)이 때 저장되는 파일 구조는 다음과 같다.
아래 예시는 Stage2 의 저장된 파일 구조인데,
optimizer 를 sharding 하므로 각 rank 에 분산된 optimizer state 가 각기 다른 파일로 저장된 것을 볼 수 있다.
logs/
└── step_0/
├── mp_rank_00_model_states.pt # model param
├── zero_pp_rank_0_mp_rank_00_optim_states.pt # Optimizer states (ZeRO)
├── zero_pp_rank_1_mp_rank_00_optim_states.pt
└── latest # latestes tag일반적인 pytorch model training 처럼 deepspeed 또한 checkpoint 를 로드하여 resume train 이 가능하다.
load_path, client_state = model_engine.load_checkpoint(
args.load_dir, # './logs'
tag=args.load_tag # 'step_5000' or None (latest)
)
if load_path is not None:
global_step = client_state.get('global_step', 0)
print(f"Resumed from step {global_step}")inference 시에는 저장된 pt 파일을 그대로 사용해도 되고, deepspeed library 에서 제공하는 zero_to_fp32.py 파일을 사용하여 pytorch_model.bin 파일로 변환하여 사용해도 된다.
python zero_to_fp32.py {deepspeeed/step/path} {output/ckpt/path}5.4. train loop
학습 루프는 기존 PyTorch 코드와 거의 동일하다. model을 model_engine으로 바꾸고, loss.backward()와 optimizer.step()을 model_engine.backward(loss)와 model_engine.step()으로 대체하기만 하면 된다.
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
# 1. Data processing
batch = {k: v.to(device, non_blocking=True) for k, v in batch.items()}
# 2. Forward pass
loss_terms, loss_status = model_engine(batch)
loss = loss_terms['loss']
# 3. Backward pass
model_engine.backward(loss)
# 4. Optimizer step
model_engine.step() # Gradient accumulation 는 자동 처리
# 5. Logging
if global_step % log_interval == 0:
writer.add_scalar('Loss/total', loss.item(), global_step)
# 6. Checkpoint saving
if global_step % save_interval == 0:
model_engine.save_checkpoint(...)
global_step += 1다음 사안들에 대해서는 Deepspeed 가 자동으로 처리하기 때문에, deepspeed 사용하지 않을 때처럼 수동으로 구현할 필요가 없다.
- Gradient accumulation
- FP16 mixed precision
- Gradient clipping
- Learning rate scheduling
- Loss scaling (FP16)
5.5. Multi-node Distributed Training
deepspeed 에서의 multi-node training 을 위해서는, master node 에서 worker node 의 정보들이 담긴 hostfile 을 작성해둔 뒤,
id@node1_ip slots=8
id@node2_ip slots=8
id@node3_ip slots=8
id@node4_ip slots=8이 hostfile 을 이용하여 deepspeed command 를 통해 학습을 시작할 수 있다.
deepspeed --hostfile=hostfile \
--master_addr=node1_ip \
--master_port=29500 \
train.py \
--config config.yaml \
--deepspeed_config ds_config.json이를 통해 deepspeed 가 자동으로 hostfile 의 정보를 이용해 multi-node training 을 시작하게 된다.
사내 GPU 팜을 사용할 때는 사내 GPU monitoring web app 이 있어서 해당 앱을 사용했지만, aws 사용할 때는 (claude-code 가 만들어준) custom web app 을 통하여 각 node 에 이상은 없는지 모니터링 하였다.
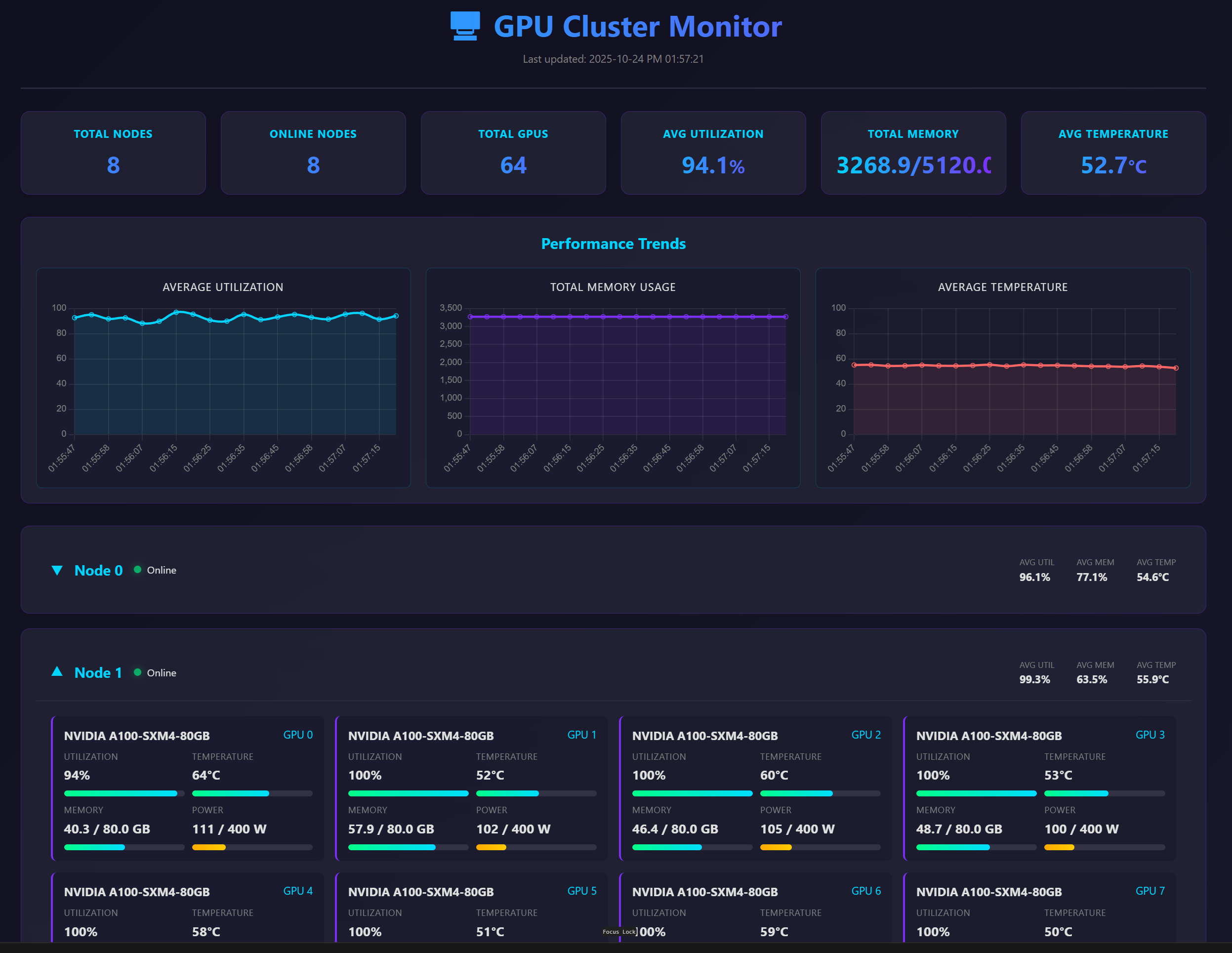
- claude 야 고마워... on/offline 상태, 각 GPU 별 util, vram 과 avg state 등을 모니터링 할 수 있도록 바이브 코딩!
6. 마무리
지금까지 multi-node 환경에서 3D 생성 모델을 학습하기 위한 infrastructure 세팅부터 deepspeed 를 활용한 분산 학습 구현까지 정리해보았다.
처음 multi-node training 을 세팅할 때는 InfiniBand/EFA 같은 고속 네트워크 설정부터 docker container 환경 구축, NCCL 설정까지 신경써야 할 부분이 많아서 시행착오가 있었다. 특히 사내 환경과 AWS 환경의 차이점 (harbor vs ECR, InfiniBand vs EFA) 을 파악하고 각각에 맞게 세팅하는 과정이 꽤나 번거로웠다.
하지만 한 번 제대로 세팅해두면, 이후에는 deepspeed config 파일과 hostfile 만 수정하여 손쉽게 scale-out 이 가능하다는 점이 큰 장점이다. 실제로 우리 팀의 경우 Stage 2 + CPU offloading 조합으로 메모리 효율성과 학습 속도 간의 적절한 균형점을 찾을 수 있었고, 이를 통해 1B 이상의 모델도 안정적으로 학습할 수 있게 되었다.
그동안은 주로 연구실, 사내 gpu 만 사용하다가 이번에 클라우드 서비스를 처음 이용해 보았는데, 한 가지 분명히 느낀 점은 AI 를 학습하는 것이 정말 굉장히 cost consuming 한 일이라는 것이다.
현재 사용 중인 스펙의 월 aws 이용료가 대략 1억에 달하는데, 사내 GPU 쓸 때보다 확실히 다른 성과에 대한 압박감이 있다.
이 압박감이 기분 좋은 얽매임이 되어 좋은 결과로 이루어지기를 바라며 글을 마친다.
Stay Tuned!
