
“사용자는 느리다는데, 클러스터는 멀쩡해 보이고, Pod는 자꾸 생겼다가 사라지고… 도대체 어디서부터 봐야 하지?”
Kubernetes 환경에서 서비스 운영을 하다 보면 금방 이런 상황을 맞이하게 됩니다.
예전처럼 서버 몇 대에 SSH로 접속해 로그를 tail 치고, top 명령으로 상태를 보는 방식만으로는 더 이상 원인을 찾기 어렵습니다.
Pod는 언제든지 사라지고, 트래픽은 여러 서비스로 분산되고, 네트워크 hop도 많아졌기 때문입니다.
그래서 Monitoring이라는 개념이 Observability로 확장되었습니다.
단순히 “살아 있냐/죽었냐(Up/Down)”를 넘어서, 지금 시스템이 어떤 상태인지, 이상 징후가 어디에서 시작됐는지, 한 요청이 여러 마이크로서비스를 거치며 어디에서 느려졌는지까지 끝까지 추적할 수 있어야 합니다.
1. 세 가지 축: Metrics / Logs / Traces
Kubernetes 모니터링/Observability는 보통 세 가지 축으로 이야기합니다.
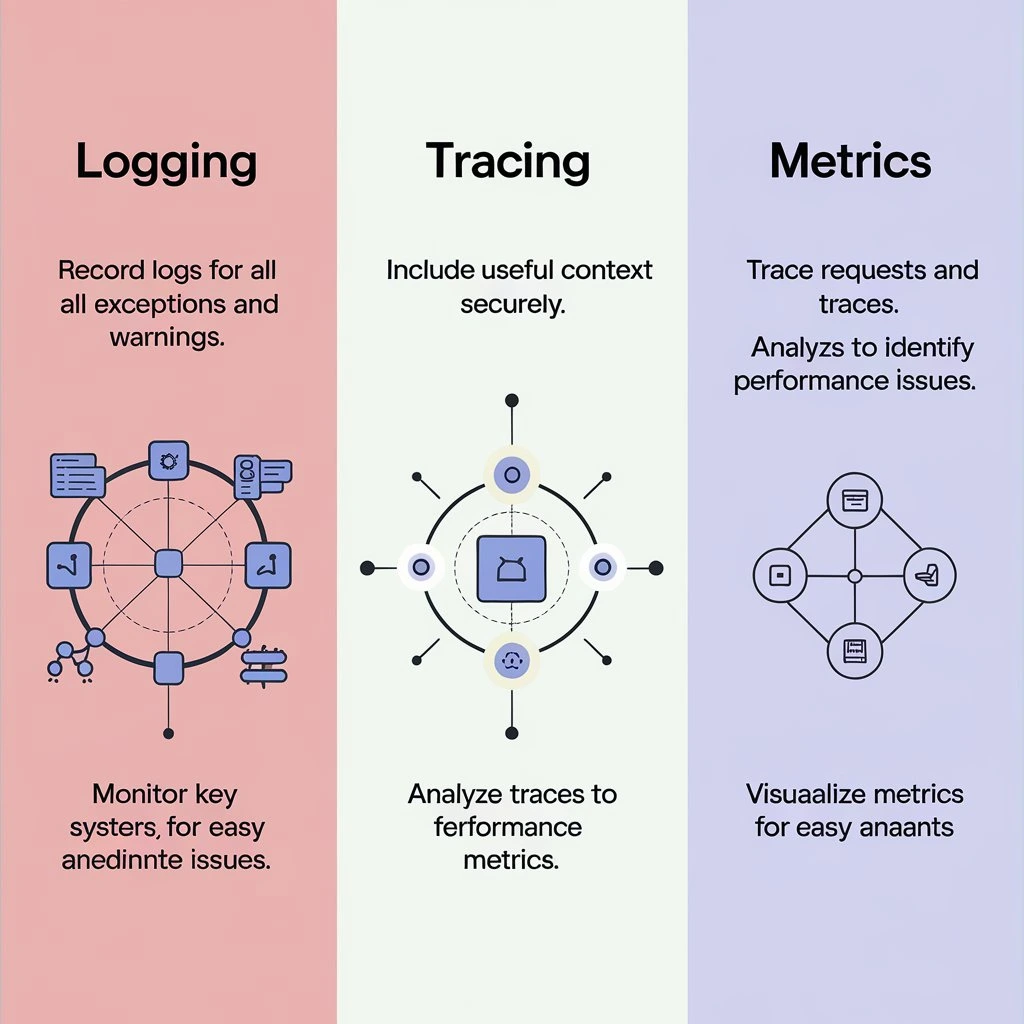
| 축 | 답하려는 질문 | 데이터 형태 | 주요 사용처 |
|---|---|---|---|
| Metrics | “정상인가?” “얼마나?” | 숫자 시계열 | 대시보드, 알람, 용량/성능 트렌드 |
| Logs | “무슨 일이 있었나?” | 텍스트 이벤트 | 에러 분석, 디버깅, 감사 로그 |
| Traces | “요청이 어디로 흘러갔나?” “어디가 느린가?” | Span/Trace 구조 | 분산 호출 병목 파악, 아키텍처 이해 |
- Metrics
- CPU, 메모리, RPS, Error Rate, p95/p99 Latency 같은 숫자 지표
- “지금 이상한지/정상인지, 어느 정도인지”를 빠르게 판단하기 좋음
- Logs
- 에러 메시지, 비즈니스 이벤트 등 상황 설명 텍스트
- “무슨 일이 있었는지”, “에러 스택이 무엇인지”를 확인
- Traces
- 한 요청이
Gateway → Service A → Service B → DB를 지나갈 때의 전체 여정 - 어느 구간에서 지연이 발생했는지, 어느 서비스가 병목인지 확인
- 한 요청이
이 세 가지는 서로의 대체재가 아니라,
- Metrics: 탐지(Detection) – “문제가 있다”
- Traces: 위치 추적(Localization) – “어디가 느린가”
- Logs: 원인 분석(Diagnosis) – “왜 그런가”
이렇게 서로 다른 질문에 답하는 역할을 합니다.
실제 장애 상황에서는 보통 이렇게 흐릅니다.
Metrics로 “어? 이상하다”를 감지
→ Traces로 “어디가 느린지” 위치를 좁히고
→ Logs로 “그래서 정확히 왜 그런지”를 파고듦
이 관점을 머리에 두고, 이를 받치는 Observability 아키텍처를 봅니다.
2. Observability 아키텍처: 4단계 데이터 흐름
Kubernetes Observability 스택은 보통 아래 4단계 파이프라인으로 정리할 수 있습니다.
- 수집 (Collect)
- 앱 코드, Sidecar, Node DaemonSet, Agent 등이 데이터 수집
- 예시
/metrics노출 (Prometheus용)- Promtail/Fluent Bit이 컨테이너 로그 읽기
- OpenTelemetry SDK/Auto-instrumentation이 Trace 생성
- 처리/집계 (Process / Aggregate)
- 수집된 데이터를 파이프라인에서 가공, 필터링, 샘플링
- 예시
- Prometheus 서버의 스크랩/집계
- OpenTelemetry Collector 파이프라인
- Fluentd/Fluent Bit 필터링
- 저장 (Store)
- 장·단기 보관, 조회 가능한 형태로 저장
- 예시
- Prometheus TSDB, Thanos/VictoriaMetrics
- Loki, Elasticsearch
- Jaeger/Tempo, ClickHouse 등
- 시각화/탐색 (Visualize / Explore)
- 대시보드, 검색, 트레이스 뷰어
- 예시
- Grafana, Kibana
- Jaeger UI, Tempo UI
- Kiali (서비스 메쉬 트래픽 뷰)
간단한 그림으로 표현하면

Metrics / Logs / Traces vs 4단계
- Collect:
/metrics, stdout/stderr 로그, OTel SDK/Auto-instrumentation- Process: Prometheus/OTel Collector/Fluent Bit가 정제·샘플링
- Store: Prometheus/Thanos, Loki/Elastic, Jaeger/Tempo
- Visualize: Grafana/Kibana/Jaeger UI/Kiali에서 통합 탐색
뒤에서 나올 도구들을 4단계/3축에 매핑하면 대략 이렇게 볼 수 있습니다.
| 단계 \ 축 | Metrics | Logs | Traces |
|---|---|---|---|
| Collect | kube-state-metrics, node-exporter, OTel SDK | Promtail, Fluent Bit, Filebeat | OTel SDK/Auto-instrumentation, Envoy/Istio |
| Process | Prometheus, OTel Collector | Fluent Bit/Fluentd, OTel Collector | OTel Collector, (Istio Telemetry) |
| Store | Prometheus, Thanos/VictoriaMetrics | Loki, Elasticsearch | Jaeger, Tempo, ClickHouse |
| Visualize | Grafana | Grafana, Kibana | Jaeger UI, Grafana, Kiali |
3. Metrics: Prometheus + Grafana + Thanos (또는 VictoriaMetrics)
3.1 왜 이 조합이 필요한가?
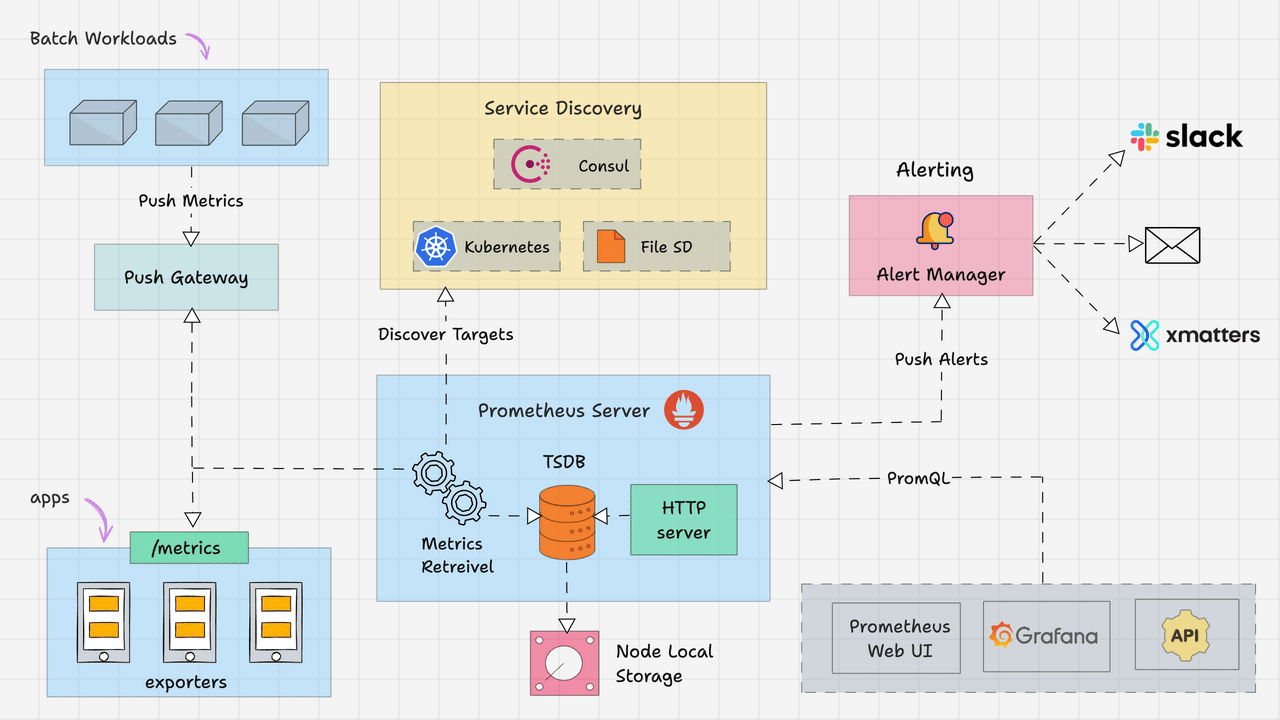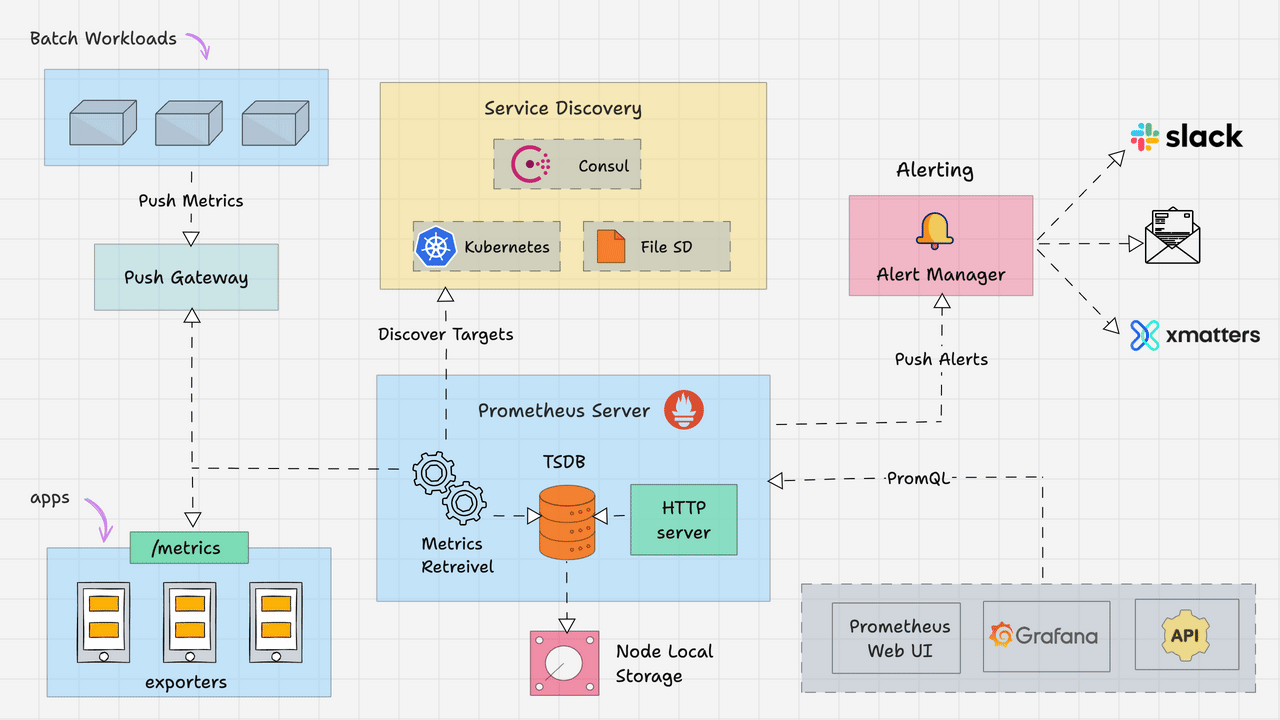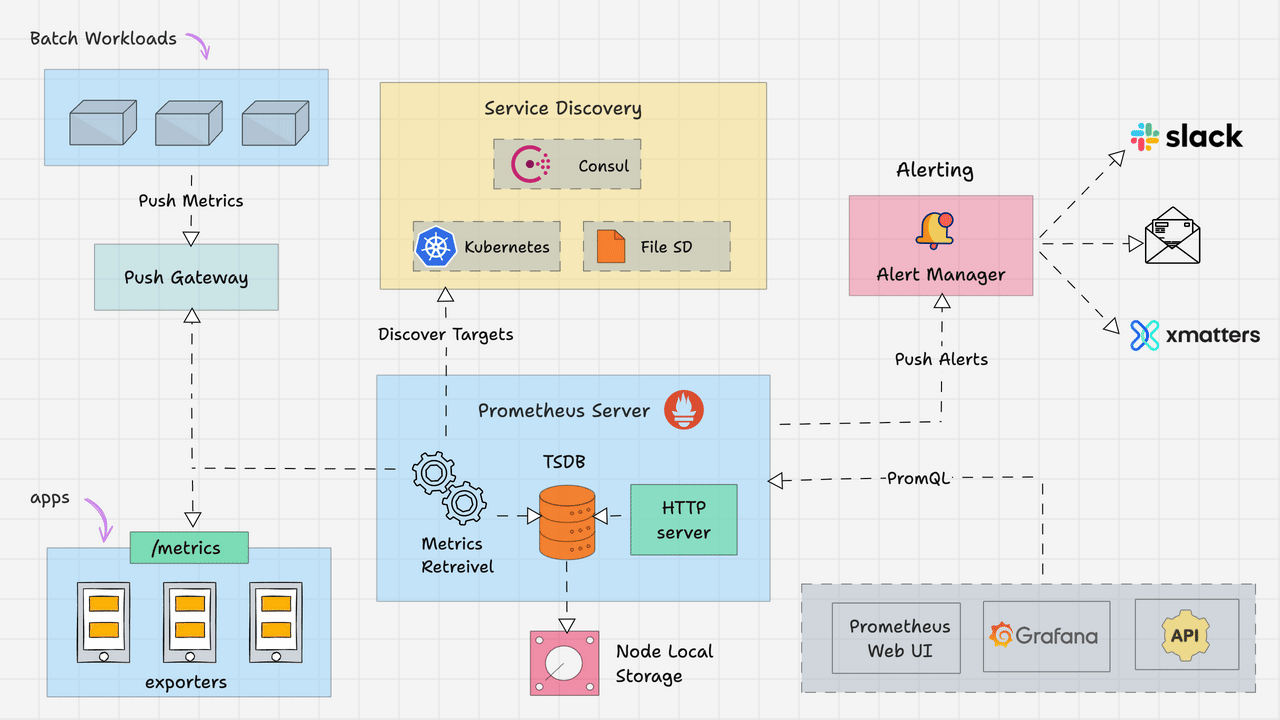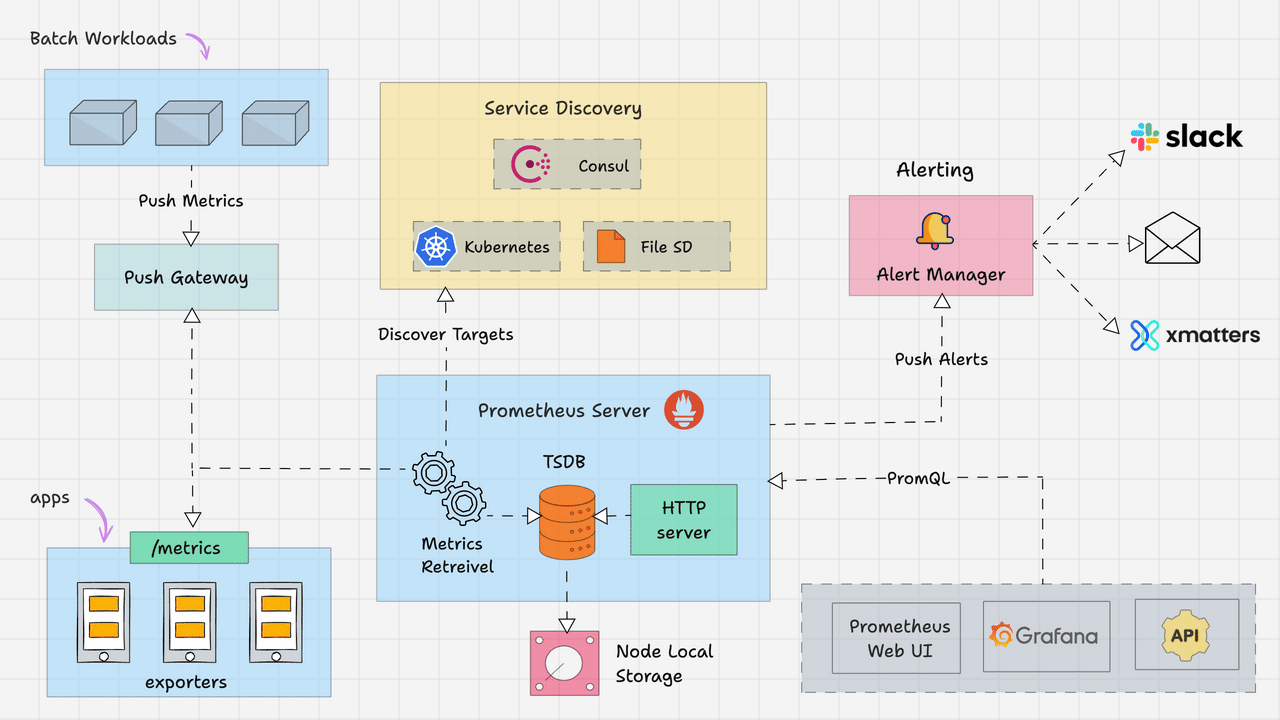
Prometheus 스택은 “Kubernetes에서 지금 정상인가?”를 숫자로 대답해주는 기본 틀입니다.
인프라/클러스터/애플리케이션 상태를 한 번에 수집하고,
대시보드·알람의 기반이 되기 때문에 사실상 표준으로 자리 잡았습니다.
3.2 Prometheus: Kubernetes Metrics의 사실상 표준
/metrics엔드포인트를 Pull 방식으로 스크랩- 자체 TSDB(Time Series DB)에 시계열 데이터 저장
- Alertmanager와 연동해 알람 발송
- Kubernetes Service Discovery로 Pod/Service 자동 감지 + 라벨 부여
즉, Kubernetes 환경에서는
- 새로 뜬 Pod도 자동으로 스크랩 대상에 포함
namespace,pod,container,service라벨을 기반으로 쿼리 작성 가능
3.3 Exporters: node-exporter, kube-state-metrics
- node-exporter
- Node CPU/메모리/디스크/네트워크 등 OS 레벨 메트릭
- kube-state-metrics
- Deployment, Pod, HPA 등 Kubernetes 오브젝트 상태를 메트릭으로 노출
이 조합으로,
- 인프라 상태(node-exporter)
- Kubernetes 오브젝트 상태(kube-state-metrics)
- 애플리케이션 커스텀 메트릭(/metrics) 를 한 번에 모을 수 있습니다.
3.3.1 라벨 설계 & PromQL 예시
실전에서 Prometheus를 쓸 때는 라벨 설계가 핵심입니다.
- 공통적으로 자주 쓰는 라벨
namespace,app,instance,env,pod,service정도는모든 메트릭에 공통으로 들어가게 설계해두면 쿼리가 훨씬 단순해집니다.
간단한 PromQL 예시를 보면 감이 더 옵니다.
# 네임스페이스별 p95 레이턴시
histogram_quantile(
0.95,
sum(rate(http_server_request_duration_seconds_bucket[5m]))
by (le, namespace)
)
# 서비스별 에러율 (5xx / 전체)
sum(rate(http_requests_total{status=~"5.."}[5m])) by (service)
/
sum(rate(http_requests_total[5m])) by (service)
3.4 Grafana: Metrics 시각화/알람 허브
- Prometheus를 데이터소스로 붙여 대시보드 구성
- 서비스/네임스페이스/인프라 레벨별 패널 구성이 용이
- Alerting도 Grafana에 통합하는 패턴이 많음
Grafana는 “여러 데이터소스를 묶는 관제실 모니터” 역할입니다.
Prometheus, Loki, Tempo, Elastic, ClickHouse 등 다양한 데이터소스를 한 화면에서 볼 수 있어
“Metrics 패널에서 → Logs/Traces로 점프”하는 흐름을 만들기 좋습니다.
3.5 장기 Metrics 보관: Thanos / VictoriaMetrics
왜 필요한가?
Prometheus는 로컬 디스크 기반이라 보관 기간을 너무 길게 가져가면 디스크 터지고,
여러 클러스터/Prometheus 인스턴스를 한 번에 조회하기도 어렵습니다.
운영에서 필요해지는 것은
- “최근 1년간 CPU 사용률 추이”
- “여러 리전/클러스터를 묶어서 전체 트래픽 패턴 보기”
그래서 Thanos / VictoriaMetrics 같은 솔루션이 Prometheus 앞뒤에 붙어
- 여러 Prometheus 인스턴스를 논리적으로 하나처럼 조회
- 메트릭 데이터를 Object Storage(S3, MinIO, GCS 등)에 업로드해 장기 보관
- 수평 확장 + 고가용성 쿼리 지원
- 오래된 데이터는 Downsampling(예: 1m → 5m → 1h) 해서 롤업 저장
현실적인 운영 예시
- Prometheus: 최근 7~15일 (상세 데이터)
- Thanos/VictoriaMetrics: 그 이후 기간 전체를 조회 (롤업된 장기 데이터)
3.6 Metrics 운영 시 자주 나오는 안티 패턴
- 라벨 고카디널리티
user_id,request_id,session_id같은 값은 라벨로 넣지 않는 것이 원칙- 이런 값은 로그/트레이스 영역에서 다루고, Metrics에서는 집계된 수준으로만 사용
- 무분별한 커스텀 메트릭
- 서비스별로 제각각 이름/라벨 구조를 쓰면, 조직 전체 대시보드가 지옥이 됨
- 공통 규칙 예
- 메트릭 이름:
appname_subsystem_metricname_unit - 공통 라벨:
env,namespace,app,instance
- 메트릭 이름:
- 무거운 쿼리를 실시간 대시보드에 남발
- 긴 기간 + 복잡한
histogram_quantile은 recording rule로 미리 계산해두는 패턴이 좋음
- 긴 기간 + 복잡한
4. Logs: Loki + Promtail (또는 ELK와의 비교 관점)
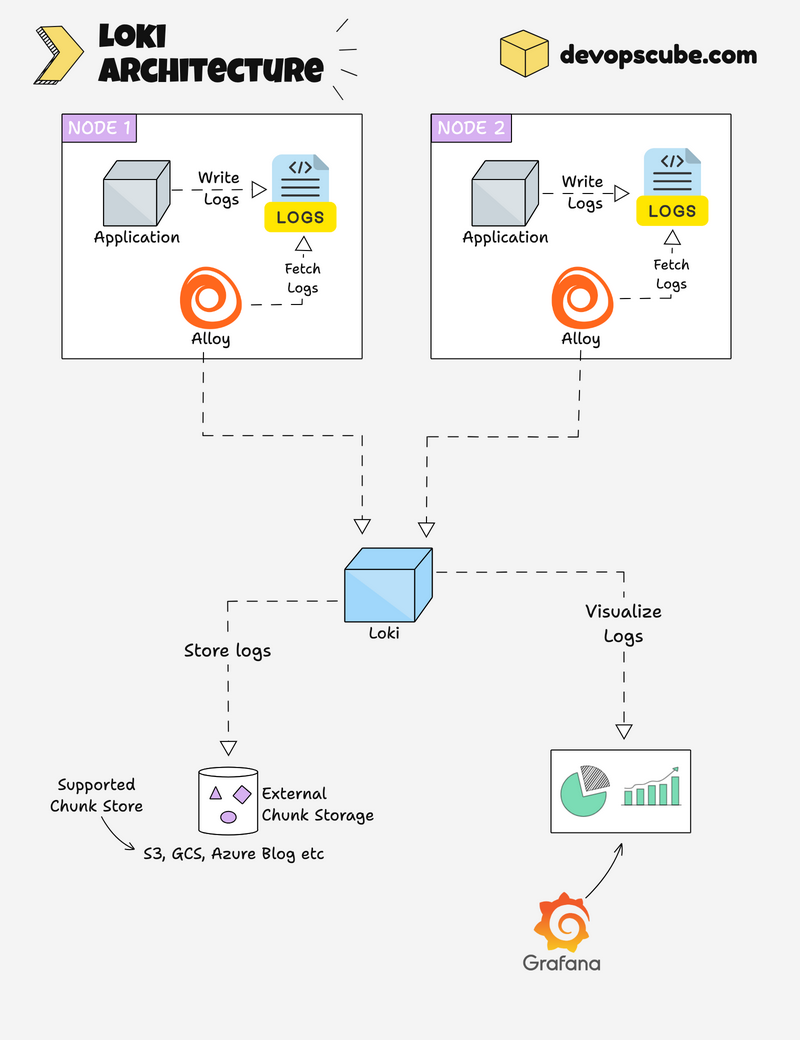
4.1 왜 별도의 로그 스택이 필요한가?
- Metrics만으로는 “왜?”라는 질문에 충분히 답하기 어렵습니다.
- 에러 메시지, 비즈니스 컨텍스트, 디버깅 정보 등은 텍스트 로그에 들어 있습니다.
- Kubernetes에서는 Pod가 자주 재시작/삭제되므로 Pod에 붙어서 로그를 보는 방식(
kubectl logs)만으로는 과거 기록 유지/검색이 힘듭니다.
그래서 “클러스터 전체 로그를 한 곳에 모으고, 라벨로 검색할 수 있는 중앙 로그 스택”이 필요합니다.
4.2 Promtail: Node 단에서 로그 수집
- 각 Node에 DaemonSet으로 배포
/var/log/containers,/var/log/pods등에서 컨테이너 로그를 읽음- Pod/Namespace/Container 라벨을 붙여 Loki로 전송
→ “어떤 Pod/서비스/네임스페이스에서 나온 로그인지” 메타데이터가 함께 전달됩니다.
4.3 Loki: 메트릭 친화적인 로그 스토어
- Elasticsearch처럼 복잡한 인덱스를 만들지 않고,
- Prometheus 스타일의 라벨(Label) 중심으로 로그를 관리/검색
장점
- Prometheus 메트릭의 라벨 구조와 잘 맞음
- Grafana에서 “메트릭 패널 → 관련 로그”로 점프하기 쉽고 자연스러움
즉, Loki는 “Prometheus의 로그 버전” 느낌에 가깝습니다.
라벨을 잘 설계하면, 서비스/네임스페이스/Pod 기준으로 쉽게 Drilling Down 할 수 있습니다.
4.3.1 대표 LogQL 예시
# prod 네임스페이스의 checkout 서비스 error 로그
{namespace="prod", app="checkout", level="error"}
# payment 서비스의 timeout 관련 로그 검색
{app="payment-service"} |= "timeout"
# 특정 trace_id에 해당하는 모든 로그 조회
{trace_id="abcd-1234-efgh-5678"}이런 식으로 라벨 필터 + 텍스트 필터를 조합해 사용하는 게 일반적입니다.
4.3.2 추천 라벨 스키마
최소한 이 정도 라벨은 공통으로 가져가면 운영이 편합니다.
namespace,app,pod,container,envlevel(info/warn/error)trace_id,span_id(Tracing과 연계하는 경우)
이 라벨들이 잘 붙어 있으면,
- “prod 네임스페이스에서 error만 보고 싶다”
- “특정 trace_id로 전체 call chain 로그 보고 싶다”
같은 요청을 금방 처리할 수 있습니다.
4.4 로그 장기 보관 전략
- 로그는 데이터량이 매우 많기 때문에, 장기 보관 전략이 중요합니다.
일반적인 패턴
- 단기 (7~30일)
- Loki(또는 Elasticsearch)의 빠른 스토리지(SSD 등)에 보관
- 장기
- 일정 기간 이후 로그 chunk/index를 Object Storage(예: S3, MinIO)로 이동
- 오래된 로그는 조회는 느려도 괜찮다는 전제 하에 저렴한 스토리지에 저장
비즈니스/보안 요구에 따라
- 일반 애플리케이션 로그: 보통 7~30일
- 보안/감사 로그: 수개월~수년까지 별도 보관
4.5 로그 품질/보안 관점에서의 고려사항
로그 스택을 구축할 때는 “얼마나 모을지”뿐 아니라 “무엇을 어떻게 모을지”가 중요합니다.
- 로그 레벨/샘플링
DEBUG/INFO로그를 무한정 찍으면 스토리지가 금방 터짐.- 고트래픽 엔드포인트는
DEBUG를 끄거나, 샘플링(예: 100건 중 1건) 도입.
- PII/민감정보 마스킹
- 이메일/전화번호/주민번호/토큰 같은 정보는 수집 전에 마스킹.
- Fluent Bit / Promtail / Loki pipeline에서 정규식으로 마스킹 필터를 넣는 패턴이 많음.
- TraceID와의 연계
- 로그에
trace_id/span_id를 남겨두면
“Trace 화면에서 해당 로그로 이동”하거나,
“LogQL로 특정 trace_id 전체 로그 조회” 같은 흐름을 만들기 쉽습니다.
- 로그에
5. Traces: Jaeger + Kiali (+ Tempo)
5.1 왜 Tracing이 필요한가?
- Metrics로 “느리다”는 것을 알 수는 있지만,
- 어느 서비스가 느린지
- 어느 DB 쿼리가 병목인지
- 어느 마이크로서비스 간 hop에서 지연이 발생하는지
까지는 알기 어렵습니다.
- 마이크로서비스/Service Mesh 환경에서는 한 요청이 여러 Hop을 거치므로,
- 전체 호출 체인을 한 눈에 볼 수 있는 도구가 필요합니다.
Tracing은 “한 요청 단위의 스토리”를 보여주는 도구입니다.
“어디서부터 느려졌는지, 어느 hop에서 에러가 났는지”를 직관적으로 보여줍니다.
5.2 Jaeger: 대표적인 분산 트레이싱 백엔드
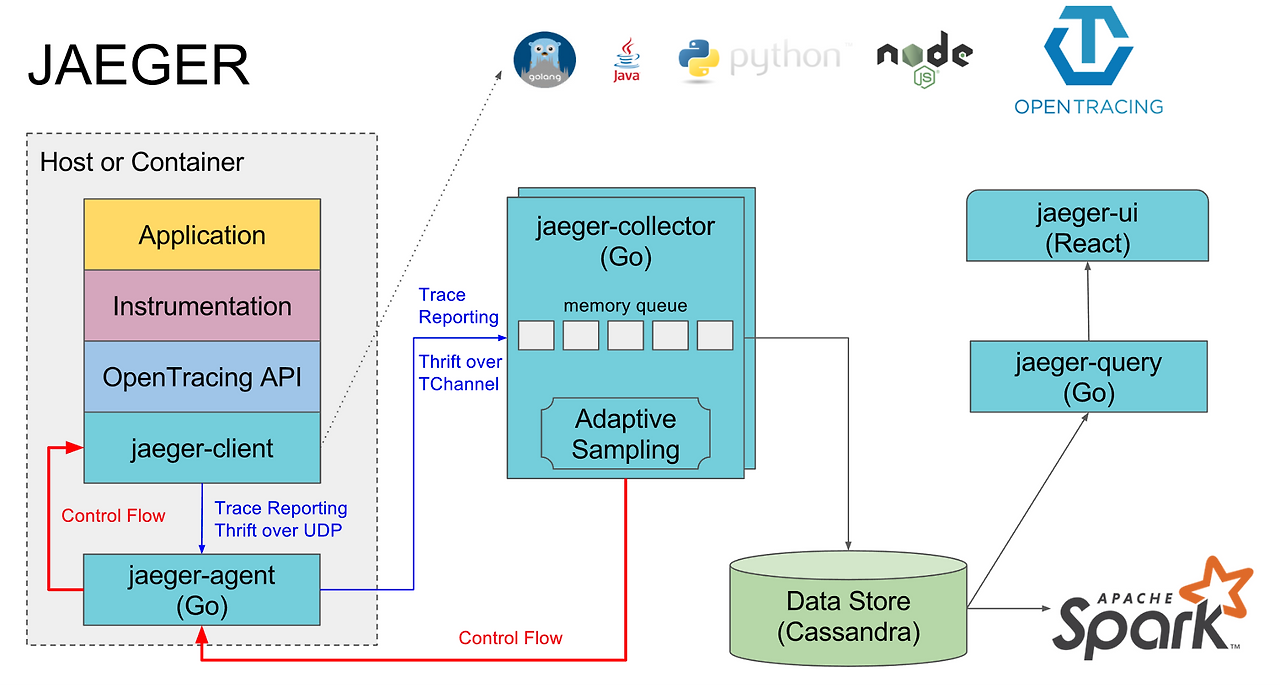
- Span/Trace 수집 및 저장
- 워터폴 뷰로 “요청이 어떤 서비스/DB를 어떤 순서로 거쳤는지” 시각화
- 다양한 스토어(Elasticsearch, Cassandra, Tempo 등) 지원
특징
- Trace 용량이 크기 때문에 보통 샘플링(Sampling)이 필수
- 비율 기반 샘플링 (예: 1%)
- 에러/슬로우 요청만 스페셜 샘플링
- 특정 엔드포인트만 Full 샘플링 등
5.3 Kiali: Istio Service Mesh 관점의 관찰
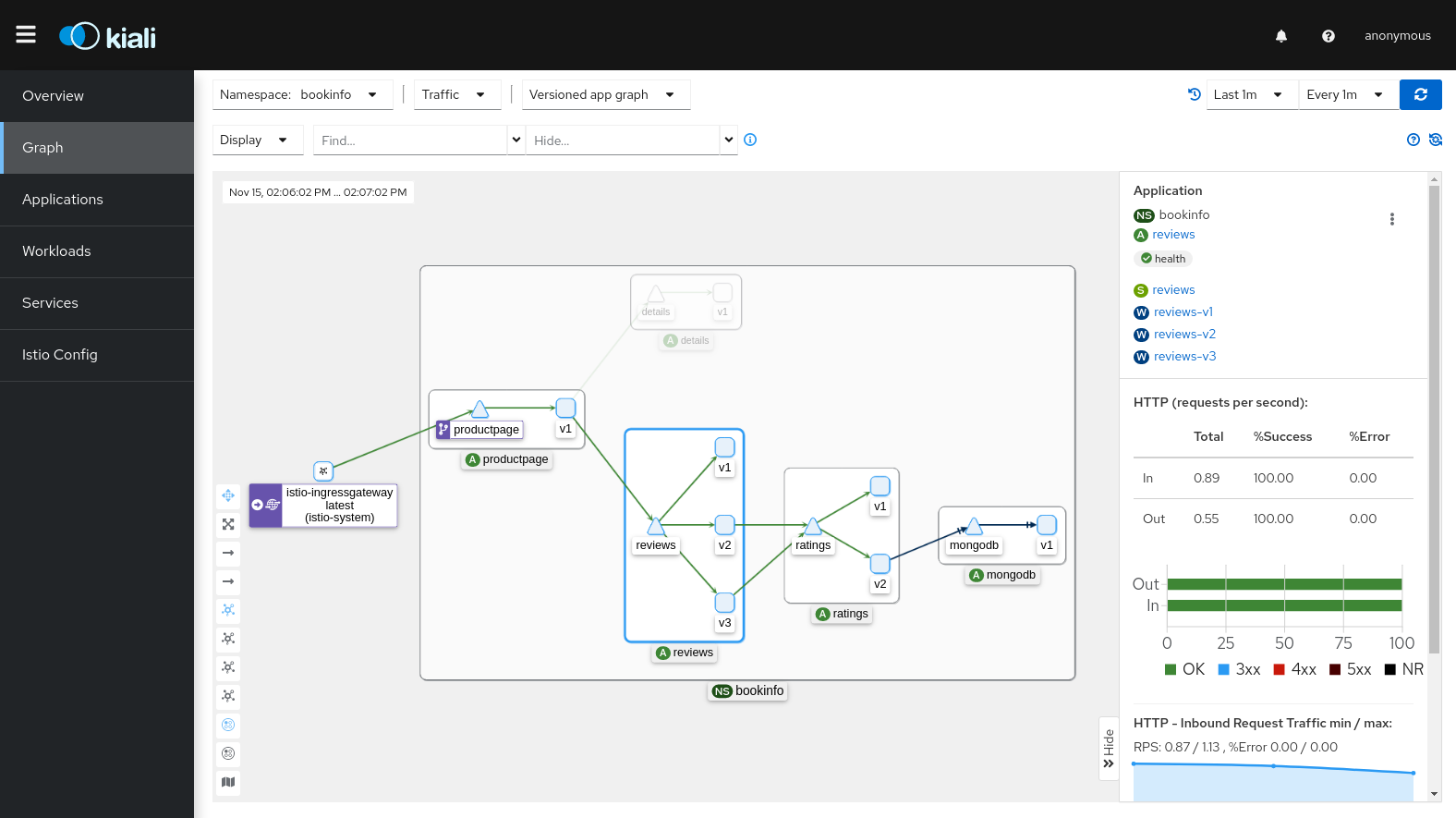
- Istio 환경에서 서비스 간 트래픽 흐름 그래프 제공
- 각 엣지에 요청 수, 오류율, 레이턴시 표시
- Jaeger/Tempo와 연동 시
- 특정 서비스/엣지 클릭 → 해당 트레이스로 이동 가능
Kiali는 “서비스 간 트래픽 지도를 그려주는 시각화 툴”입니다.
서비스 메쉬 관점에서 “어느 서비스가 병목인지” 빠르게 보기에 좋습니다.
5.4 Tempo(옵션): 객체 스토리지 기반 Trace 백엔드
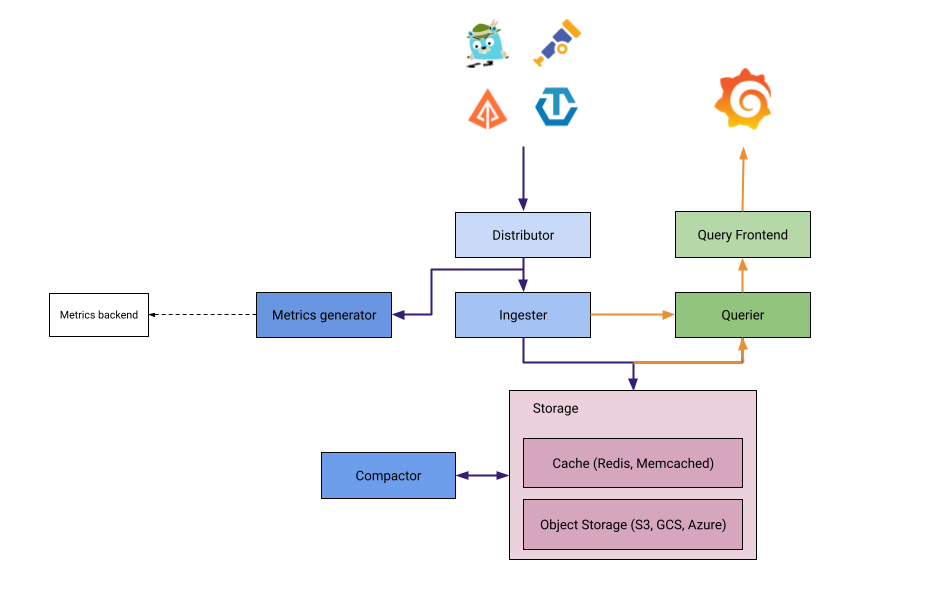
- Grafana Tempo는 Trace를 Object Storage에 저장하는 분산 트레이스 백엔드
- Prometheus/Loki와 비슷한 철학
- Object Storage + 대용량 Trace 저장
- 비용/확장성에 유리
Grafana와 연동 시, Metrics/Logs/Traces 간 점프가 매우 자연스러워
“한 화면에서 모든 Observability 데이터”를 보는 구성을 만들기 쉽습니다.
6. OpenTelemetry 중심 Observability: 수집/전송 표준화
6.1 왜 OpenTelemetry가 필요한가?
기존 구조
- 코드에 Prometheus SDK, Jaeger SDK, 특정 APM 벤더 SDK 등을 각각 심어야 함
- 백엔드를 바꾸거나 추가하면 코드도 함께 수정해야 하는 경우가 많음
OpenTelemetry는 이런 문제를 해결하기 위해 등장한, 벤더 중립 Observability 표준입니다.
6.2 OpenTelemetry 구성 요소
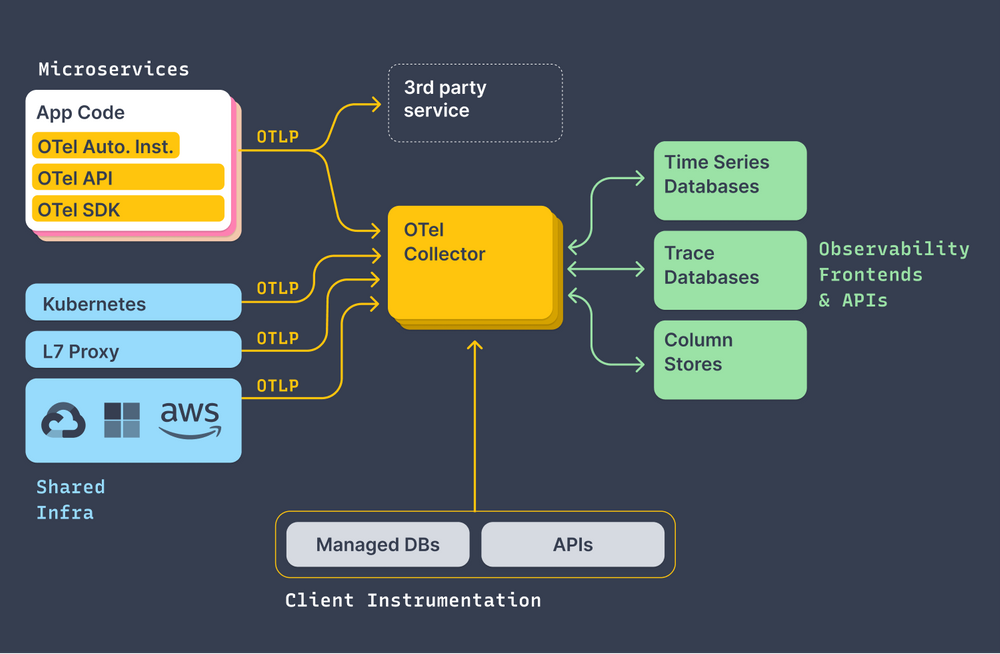
- SDK
- 애플리케이션 코드에서 Metrics/Logs/Traces를 OTLP 포맷으로 생성
- Collector
- 여러 입력(OTLP, Jaeger, Prometheus 등)을 받아
- 가공/필터링/샘플링 후 여러 백엔드로 내보내는 파이프라인 역할
6.3 OTel 기반 아키텍처의 장점
- 애플리케이션 코드에서는 OTel SDK + OTLP만 사용
- OTel Collector가 데이터를 받아서
- Metrics → Prometheus/Thanos/Mimir/SaaS APM
- Logs → Loki/Elastic/Cloud Logging
- Traces → Jaeger/Tempo/SigNoz/상용 APM
즉, 수집/전송 계층을 OpenTelemetry로 표준화하고,
백엔드는 필요에 따라 유연하게 교체/추가할 수 있습니다.
6.4 예시: OTel + OSS 백엔드 Observability
한 가지 예시 아키텍처
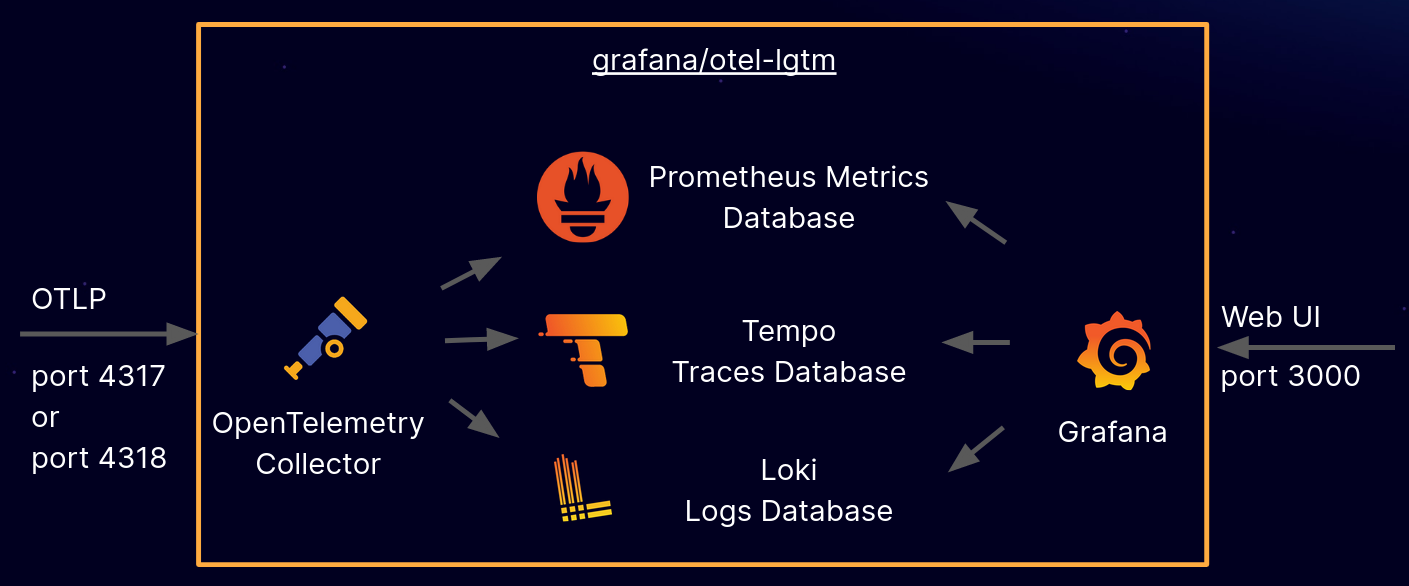
- Grafana에서는 Prometheus/Loki/Tempo를 모두 붙여 M/L/T를 통합 시각화
6.5 OpenTelemetry 도입 전략 (현실적인 3단계)
OpenTelemetry를 도입할 때, “전 서비스 한 번에 전환”은 현실적으로 어렵습니다.
보통은 아래처럼 단계적 도입을 많이 합니다.
- Collector부터 세운다 (프록시 모드)
- 기존 Prometheus/Jaeger/Elastic 앞에 OTel Collector를 세우고,
- 수집/전송 경로를 Collector를 거쳐 가도록만 바꾼다.
- 이 단계에서는 애플리케이션 코드는 거의 손대지 않음.
- 신규 서비스부터 OTel SDK/Auto-instrumentation
- 새로 만드는 서비스는 처음부터 OTel SDK + OTLP로 설계.
- Traces/Logs/Metrics를 Collector로 보내고, Collector → 기존 백엔드로 내보내는 구조.
- 기존 서비스 점진 이관
- 장애/성능 이슈가 잦은 서비스부터 OTel 적용.
- 점점 “Prometheus SDK, Jaeger SDK → OTel SDK”로 바꿔가며,
최종적으로는 코드에서 벤더 의존 코드를 제거.
이렇게 가면 리스크를 낮추면서 표준화를 할 수 있고, 도중에 백엔드를 바꿔야 해도 Collector 설정만 손보면 되기 때문에 유연합니다.
7. 다른 스택과의 비교: ELK Stack, SigNoz
7.1 ELK(Elastic) Stack
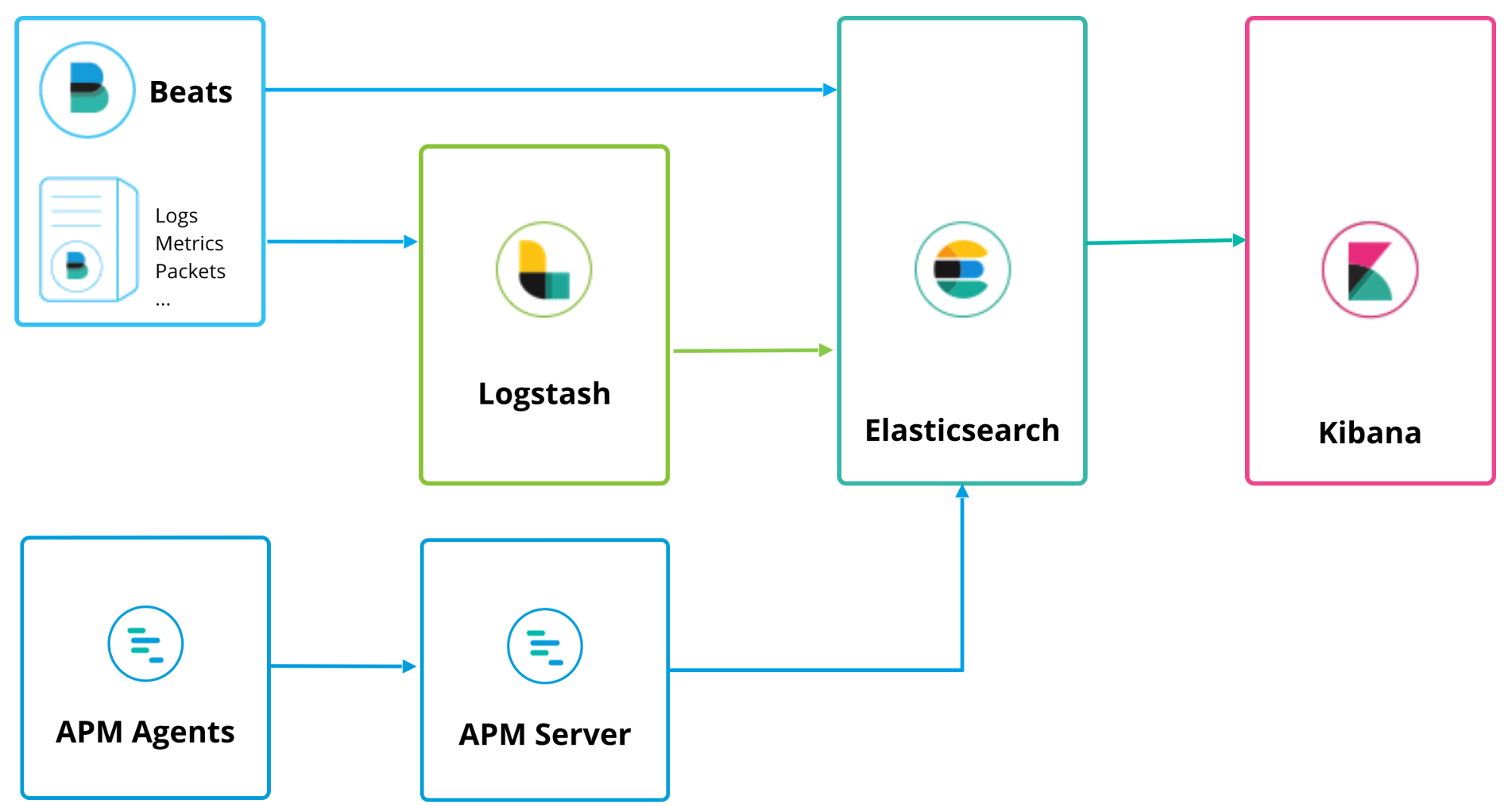
왜 여전히 많이 쓰이는가?
- Elasticsearch + Logstash + Kibana (+ Beats) 조합
- 주로 로그 수집/검색/분석에 매우 강력
- 대량 로그를 중앙에서 텍스트 검색/집계하기에 최적화
장점
- 텍스트 기반 로그 검색, 분석, 집계에 강력
- 성숙한 에코시스템과 풍부한 문서
단점
- 클러스터 운영이 무겁고 리소스 소모가 큼
- Metrics/Traces까지 완전 통합하려면 추가 구성이 필요
요즘 K8s Observability에서는
“전체 스택”이라기보다, “로그 특화 스토어”로 사용하는 경우가 많습니다.
Metrics 확장: Metricbeat / Beats 계열
ELK를 “로그만”이 아니라 메트릭까지 포함한 관제로 쓰고 싶다면 보통
- Metricbeat
- 시스템/서비스 메트릭 수집용 Beat
- Node CPU/메모리/디스크/네트워크, Docker/Kubernetes, Nginx, Redis 등 다양한 모듈 제공
- 구조
- Metricbeat → Elasticsearch → Kibana Metrics/대시보드
- 그 외 Beats
Filebeat(로그),Heartbeat(가용성 체크) 등과 함께 조합해서 “Beat → Elasticsearch → Kibana” 파이프라인을 구성
즉, ELK 진영에서 Metrics까지 보려면
- Prometheus 대신 Metricbeat + Elasticsearch 조합을 쓰거나,
- OpenTelemetry/Prometheus를 쓰되, 일부 메트릭만 Elasticsearch에 적재해서 로그와 코릴레이션 용도로 활용하는 패턴이 많습니다.
Traces 확장: Elastic APM
분산 트레이싱/성능 분석까지 ELK 안에서 해결하려면 Elastic APM을 붙입니다.
- Elastic APM Agent
- Java, Node.js, Python, Go 등 언어별 APM 에이전트
- 애플리케이션 코드/프레임워크에 붙어서 Trace/Span, 에러, 성능 데이터를 수집
- APM Server
- 에이전트에서 보낸 데이터를 받아 Elasticsearch에 저장
- Kibana APM UI
- 서비스 맵, 트랜잭션 레이턴시, Error Rate, Trace 워터폴 뷰 제공
구조를 정리하면
Logs -> Filebeat/Logstash -> Elasticsearch -> Kibana(Logs)
Metrics -> Metricbeat -> Elasticsearch -> Kibana(Metrics)
Traces -> Elastic APM Agent -> APM Server -> Elasticsearch -> Kibana(APM)즉, ELK를 “진짜 Observability 스택”으로 쓰려면
Filebeat + Metricbeat + Elastic APM까지 포함한 구성이 되고,
그만큼 클러스터/스토리지 운영 복잡도와 비용도 함께 올라가는 구조입니다.
7.2 SigNoz
포지션
- OpenTelemetry-native All-in-one Observability 도구
- Metrics, Logs, Traces를 하나의 UI에서 제공
- 내부적으로 OTel Collector + ClickHouse 등 사용
- Datadog / New Relic 같은 상용 APM의 오픈소스 대체재 포지션
구조
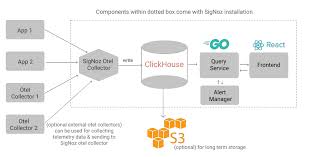
장점
- OTel-native
- 수집/전송 계층이 OpenTelemetry라, 나중에 다른 백엔드로 전환하기 쉬움.
- All-in-one UI
- 한 화면에서 서비스 맵, 메트릭 대시보드, 로그, 트레이스를 같이 볼 수 있음.
- ClickHouse 기반
- 대용량 시계열/로그/트레이스 쿼리에 강함.
단점/고려사항
- 자체 클러스터 운영 필요 (ClickHouse + Collector + UI)
- Grafana + Prometheus + Loki처럼 모듈형으로 다 쪼개 쓰는 것에 비해
세밀한 커스터마이징은 상대적으로 제한될 수 있음. - 이미 “Grafana 스택”을 깊게 쓰고 있는 조직이라면중복 투자 이슈가 생길 수 있음.
“전체 Observability를 하나의 제품/화면에서 보고 싶고,
OpenTelemetry 기반으로 가고 싶다”면 충분히 고려할 수 있는 옵션입니다.
7.3 스택 비교 요약 표
Prometheus+Loki+Tempo 조합, ELK, SigNoz를 간단히 비교하면
| 스택 | 강점 | 약점 | 적합한 케이스 |
|---|---|---|---|
| Prom+Loki+Tempo | K8s 친화, 모듈형, Grafana 연동, 확장성 | 설계/운영 난이도, 처음 셋업 손이 많이 감 | 인프라/플랫폼 팀이 있고 커스터마이징 중시 |
| ELK(+APM) | 텍스트 검색/로그 분석 최강, 에코시스템 풍부 | 리소스/운영 비용 높음, K8s 친화성은 상대적으로 약함 | 로그/검색 위주, 이미 ELK 도입된 조직 |
| SigNoz | OTel-native, All-in-one UI, ClickHouse | 자체 운영 필요, 모듈형 대비 유연성 제한 | 소규모 팀, All-in-one 선호, OTel 도입 초기 |
8. Metrics / Logs / Traces 장기 보관 전략
지금까지 내용을 표로 정리하면
| 축 | 단기 보관 (운영/장애 대응) | 장기 보관 (분석/컴플라이언스) | 대표 솔루션/패턴 |
|---|---|---|---|
| Metrics | Prometheus TSDB (7~15일) | Thanos / VictoriaMetrics + Object Storage | S3/MinIO, GCS 등 |
| Logs | Loki / Elasticsearch (7~30일) | Object Storage tier, ES ILM, Loki chunk 장기 보관 | S3/MinIO, Cold Storage |
| Traces | Jaeger/Tempo (샘플링된 단기 Trace) | Tempo + Object Storage, Jaeger + ES/Cassandra 등 | OTLP + OTel Collector 기반 |
현실적인 포인트
- Metrics
- 이미 집계된 숫자라 용량이 상대적으로 적어 장기 보관에 유리
- Logs
- 텍스트라 데이터량이 폭발 → 레벨 조정, 필터링, 압축, 마스킹 중요
- Traces
- 모든 요청을 다 저장하기엔 너무 크므로 샘플링 전략이 핵심
- 비율 기반, 에러 기반, 중요 트랜잭션 기반 등
- 모든 요청을 다 저장하기엔 너무 크므로 샘플링 전략이 핵심
9. 장애 시나리오로 보는 전체 흐름
간단한 예시
상황: /checkout API가 특정 시간대에 유난히 느려졌다는 제보
- Metrics (Prometheus + Grafana)
checkout-service의 p95 latency 그래프에서 특정 시간대 스파이크 확인- 같은 시점의 CPU, DB 쿼리 수, 다른 서비스 의존성도 함께 확인
- Traces (Jaeger/Tempo + Kiali/OTel UI)
- 해당 시간대 Trace를 조회
checkout → payment → DB호출 체인 중
DB 호출 구간에서 지연이 집중되어 있는 것을 확인- Logs (Loki/ELK)
- 같은 시점
payment-service로그를 조회- DB 인덱스 미사용 쿼리, 타임아웃, 설정 변경 등의 단서를 로그에서 발견
이런 식으로 Metrics → Traces → Logs 순으로 내려가며
- “문제가 있다”
- “어디가 느린가”
- “왜 그런가”
를 연결하는 것이 Observability의 핵심 흐름입니다.
OpenTelemetry를 도입하면
- 앱 코드 → OTel SDK/Auto-instrumentation
- OTel Collector → Prometheus/Loki/Jaeger/SigNoz 등으로 분배
형태로 위 시나리오를 표준화된 파이프라인으로 구현할 수 있습니다.
10. 우리 환경에서 어떤 조합을 쓸 것인가? (패턴 정리)
현실적인 선택지를 몇 가지 패턴으로 정리해보면
10.1 OSS 기본 조합 (Kubernetes 친화형)
“Kubernetes + OSS로 Observability 환경을 꾸리고 싶다”
- Metrics: Prometheus + Alertmanager + Grafana
- Logs: Loki + Promtail
- Traces: Jaeger 또는 Tempo
- 수집 표준화: OpenTelemetry Collector(선택)
10.2 로그 Heavy 환경 + 검색 위주
“로그 볼륨이 크고 텍스트 검색/분석이 중요하다”
- Metrics: Prometheus + Grafana
- Logs: ELK (Elastic + Logstash/Beats + Kibana) 또는 Loki+ELK 혼합
- Traces: Jaeger/Tempo, 필요하다면 OTel 기반 추가
10.3 All-in-one 성향
“한 제품/한 UI로 M/L/T를 보고 싶다 + OTel 기반”
- 수집/전송: OpenTelemetry SDK + OTel Collector
- 백엔드/뷰어: SigNoz 혹은 상용 APM (Datadog, New Relic 등)
- Kubernetes/비-Kubernetes 환경 통합에 유리
10.4 선택 기준 질문 몇 가지
어떤 패턴을 택할지는, 대략 이런 질문에 답해보면 윤곽이 잡힙니다.
- 우리 서비스의 로그 볼륨은? (월 수백 GB vs 수 TB 이상)
- 인프라/플랫폼 팀 인원은? (1~2명 vs 5명+)
- 이미 쓰고 있는 SaaS APM/로그 서비스가 있는가?
- 컴플라이언스(예: 금융, 공공) 요구로 온프레미스/자체 운영이 필수인가?
- 개발자들이 Grafana/Prometheus에 익숙한지, 아니면 한 제품형 UI를 선호하는지?
출처
