1. Problem - 수동 배포의 한계
1.1 MSA 환경에서 배포의 복잡성
마이크로서비스 아키텍처(MSA)에서는 수십~수백 개의 서비스가 서로 얽혀 있습니다.
수동으로 이를 관리할 경우 다음과 같은 문제가 발생합니다.
- 휴먼 에러: 스크립트 실행 순서 실수, 오타, 롤백 타이밍 지연.
- 가용성 저하: 서비스 업데이트 중 연결 끊김 현상(Downtime).
- 상태 불일치: 서버마다 실행 중인 버전이 다르거나 설정이 꼬이는 현상.
1.2 핵심 트레이드오프
모든 배포 전략은 비용(리소스), 위험(가용성), 속도 사이의 선택입니다.
| 전략 | 리소스 효율 | 전환 속도 | 롤백 속도 | 버전 혼재 | 한 줄 요약 |
|---|---|---|---|---|---|
| Blue-Green | 낮음 (2배 필요) | 즉시 | 즉시 | 없음 | 안전하지만 비쌈 |
| Canary | 보통 | 점진적 | 빠름 | 일부 | 위험 최소화, 검증 용이 |
| RollingUpdate | 높음 | 점진적 | 보통 | 있음 | 기본값, 균형 잡힌 선택 |
| Recreate | 최고 | 빠름 | 보통 | 없음 | 단순하지만 다운타임 발생 |
2. Solution - 선언적 배포
2.1 명령형 vs 선언형의 차이
| 구분 | 명령형 (Imperative) | 선언형 (Declarative) |
|---|---|---|
| 철학 | "어떻게(How) 도달할 것인가?" | "어떤 상태(What)여야 하는가?" |
| 도구 | kubectl run, kubectl expose | kubectl apply -f deployment.yaml |
| 상태 관리 | 운영자가 현재 상태를 기억해야 함 | 시스템이 스스로 상태를 유지 (Self-healing) |
| 멱등성 | 보장되지 않음 (중복 실행 시 에러 가능) | 보장됨 (여러 번 실행해도 결과는 동일) |
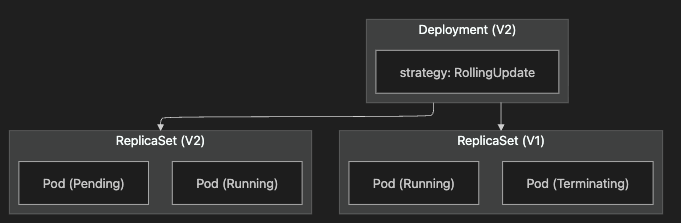
2.2 Deployment의 계층적 구조
Deployment는 직접 Pod를 관리하지 않고, ReplicaSet을 통해 Pod의 개수와 버전을 관리합니다.
3. RollingUpdate - 무중단 점진적 교체
3.1 동작 원리
기존 Pod를 하나씩 종료하면서 동시에 신규 Pod를 생성합니다. 서비스의 전체 가용성을 유지하며 버전을 교체하는 가장 표준적인 방식입니다.
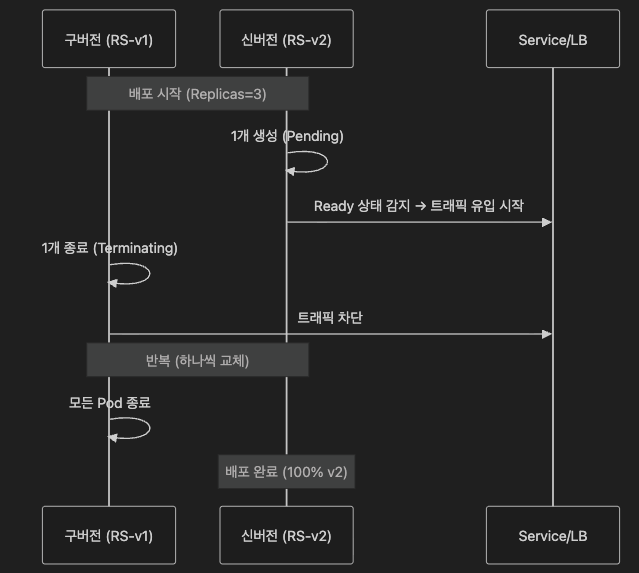
3.2 핵심 설정 파라미터
maxSurge: 목표치보다 얼마나 더 많은 Pod를 일시적으로 생성할 수 있는가? (기본값 25%)maxUnavailable: 배포 중 얼마나 많은 Pod가 비가용 상태가 되어도 되는가? (기본값 25%)minReadySeconds: 신규 Pod가 Ready 상태로 최소한 이 시간 동안 안정적이어야 다음 단계 진행 (기본값 0초).
운영 팁
maxUnavailable: 0으로 설정하면, 새로운 Pod가 완벽히 준비되기 전까지
기존 Pod를 절대 지우지 않으므로 Zero-Downtime이 보장됩니다.
다만 배포 속도는 느려집니다.
3.3 HPA / Cluster Autoscaler와의 상호작용
RollingUpdate 중에 HPA(Horizontal Pod Autoscaler) 또는 Cluster Autoscaler(CA)가 동시에 동작하면 예상치 못한 스파이크나 충돌이 발생할 수 있습니다.
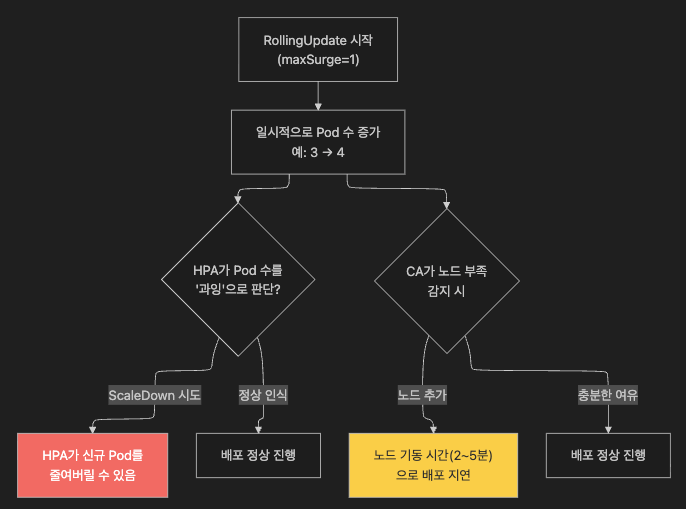
운영 권장 사항
| 상황 | 권장 조치 |
|---|---|
| HPA 적용 서비스 배포 전 | kubectl get hpa 로 현재 스케일 상태 확인 후 배포 |
| 배포 중 HPA ScaleDown 방지 | 배포 시작 전 HPA를 일시 비활성화(minReplicas 상향) 후 배포 완료 후 복원 |
| Cluster Autoscaler 환경 | 배포 전 여유 노드 확보 여부 점검, maxSurge 최소화 또는 배포 시간대를 트래픽 저점으로 조정 |
| PodDisruptionBudget 설정 시 | maxUnavailable과 PDB minAvailable의 합이 총 replicas를 초과하지 않는지 반드시 확인 (자세한 내용 → 8.4절) |
4. Recreate - 단순 전체 교체
4.1 동작 방식
모든 구버전 Pod를 먼저 종료한 뒤, 신버전 Pod를 생성합니다. 다운타임(Downtime)이 발생하지만, 두 버전이 동시에 존재할 수 없는 경우에 사용합니다.

Recreate가 적합한 상황
| 상황 | 이유 |
|---|---|
| DB 스키마가 구/신버전 비호환 | 두 버전이 동시에 DB를 접근하면 데이터 손상 위험 |
| 싱글톤 프로세스 (파일 락, 배타적 큐 컨슈머) | 중복 실행 불가 |
| 개발/스테이징 환경 | 다운타임 허용, 단순함 선호 |
4.2 DB 마이그레이션: Expand/Contract 패턴
Recreate 없이도 RollingUpdate 중 DB 스키마를 안전하게 변경하는 방법입니다. 구/신버전이 동시에 같은 DB를 사용하는 상황에서 반드시 고려해야 합니다.
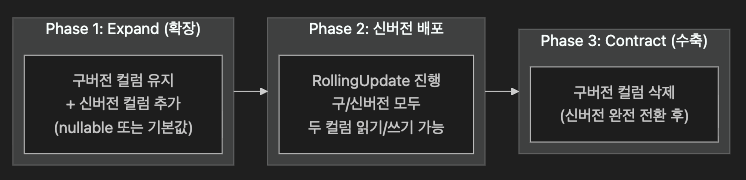
핵심 원칙
- 절대 금지: 구버전이 사용 중인 컬럼을 즉시 삭제하는 마이그레이션 (배포 중 구버전이 죽음)
- 권장: 신규 컬럼은 항상
nullable또는DEFAULT값으로 추가 → 구버전에 영향 없음 - 삭제는 신버전 배포가 완전히 완료되고 구버전 Pod가 모두 사라진 뒤 별도 배포로 수행
5. Blue-Green 배포
5.1 개념 및 구조
완전히 새로운 환경(Green)을 구축하여 검증을 마친 뒤, 로드밸런서의 설정을 변경하여 한꺼번에 트래픽을 전환합니다.
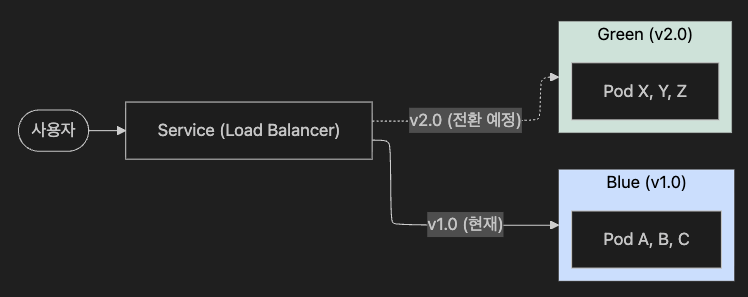
5.2 장단점
- 장점: 즉각적인 롤백이 가능하며(Service selector 변경만으로 < 1초), 버전 혼재로 인한 문제가 없습니다.
- 단점: 리소스가 일시적으로 2배 필요하여 비용이 상승합니다. Stateful 서비스나 DB 동기화 복잡도가 높습니다.
6. Canary 배포
6.1 개념
소수의 사용자에게만 먼저 신버전을 노출하여 에러율, 성능 지표 등을 모니터링한 후 점진적으로 확대합니다.
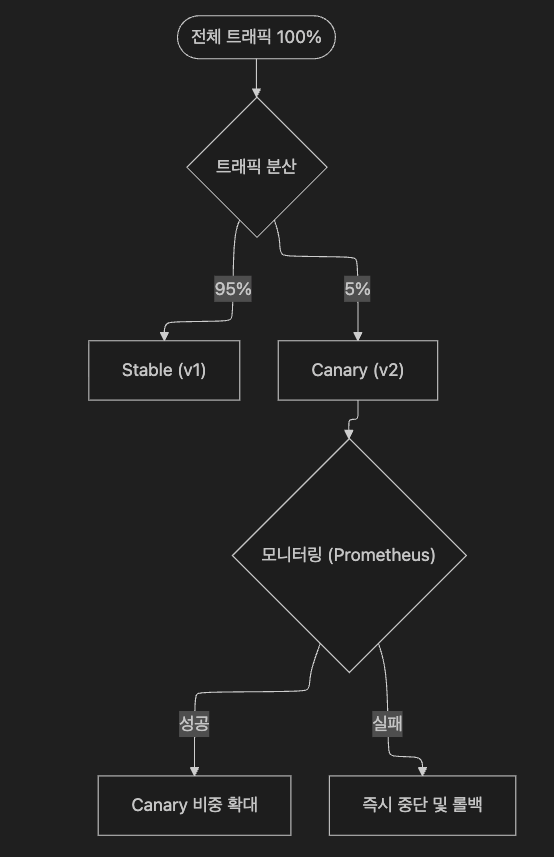
6.2 트래픽 분배의 현실: Replica 비율 ≠ 트래픽 비율
네이티브 Kubernetes(Service + 복수 Deployment)로 Canary를 구현할 때 Replica 수 비율이 트래픽 비율과 정확히 일치하지 않습니다. 이는 운영 환경에서 반드시 인지해야 할 중요한 함정입니다.
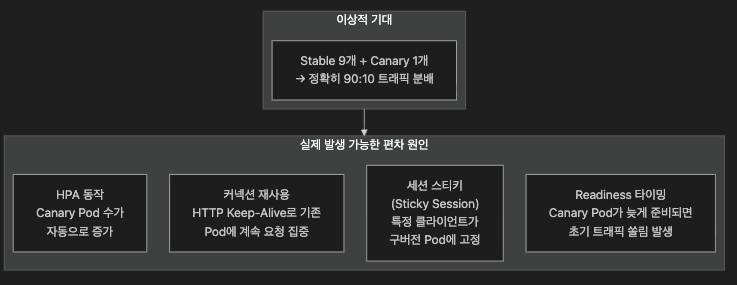
정확한 가중치 트래픽 분배가 필요하다면
| 방법 | 설명 | 예시 |
|---|---|---|
| Argo Rollouts + trafficRouting | Rollout CRD에서 trafficRouting 블록으로 NGINX/ALB/Istio 연동 | setWeight: 10 → 정확히 10% |
| Istio VirtualService | weight 필드로 퍼센트 단위 제어 | weight: 10 |
| NGINX Ingress (canary annotation) | nginx.ingress.kubernetes.io/canary-weight: "10" | 애노테이션 한 줄 |
| AWS ALB Ingress | alb.ingress.kubernetes.io/actions.* 에서 가중치 지정 | Weight: 10 |
운영 원칙: 정확한 트래픽 비율 제어가 중요한 프로덕션 Canary 배포에는 반드시 Ingress 또는 Service Mesh 기반 트래픽 라우팅을 사용하세요. Replica 비율 방식은 개발/스테이징 검증에만 적합합니다.
6.3 Feature Flag와의 연계
배포(Deploy)와 릴리스(Release)를 분리하는 것이 Canary 배포의 핵심 안전 장치 중 하나입니다.
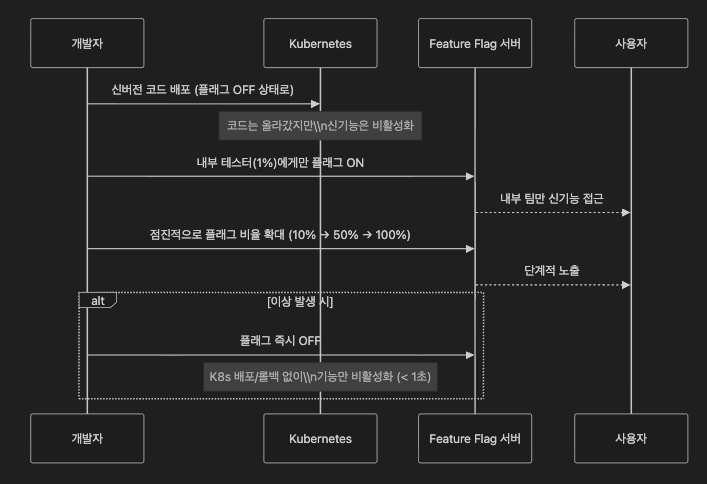
Feature Flag의 이점
- 코드 롤백 없이 기능만 즉시 비활성화 가능 (수 초 이내)
- 특정 사용자 세그먼트(내부 팀, 베타 유저, 특정 지역)에만 선별 노출
- A/B 테스트와 자연스럽게 연계
- 대표 도구: LaunchDarkly, Flagsmith, OpenFeature(CNCF 표준), Unleash
7. Argo Rollouts 실습
Argo Rollouts는 네이티브 Kubernetes Deployment의 한계를 넘어 Canary 및 Blue-Green 전략을 선언적으로 관리하게 해주는 Controller입니다.
7.0 사전 준비
# 네임스페이스 및 컨트롤러 설치
kubectl create ns argo-rollouts
kubectl apply -n argo-rollouts -f <https://github.com/argoproj/argo-rollouts/releases/latest/download/install.yaml>
# kubectl 플러그인 버전 확인
kubectl argo rollouts version
# 실습용 네임스페이스 생성
kubectl create ns rollouts-demo
kubectl create ns rollouts-blue-green-demo
kubectl create ns rollouts-canary-demo
# 대시보드 실행
kubectl argo rollouts dashboard -n rollouts-demo --port 3100
open <http://localhost:3100>
7.1 RollingUpdate 배포
rollout-nginx.yaml
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: nginx
namespace: rollouts-demo
labels:
app: nginx
spec:
replicas: 10
selector:
matchLabels:
app: nginx
strategy:
canary: {}
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.25-alpine
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
readinessProbe:
httpGet:
path: /
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: rollouts-demo
labels:
app: nginx
spec:
selector:
app: nginx
ports:
- name: http
port: 80
targetPort: 80kubectl apply -f rollout-nginx.yaml
kubectl argo rollouts get rollout nginx -n rollouts-demo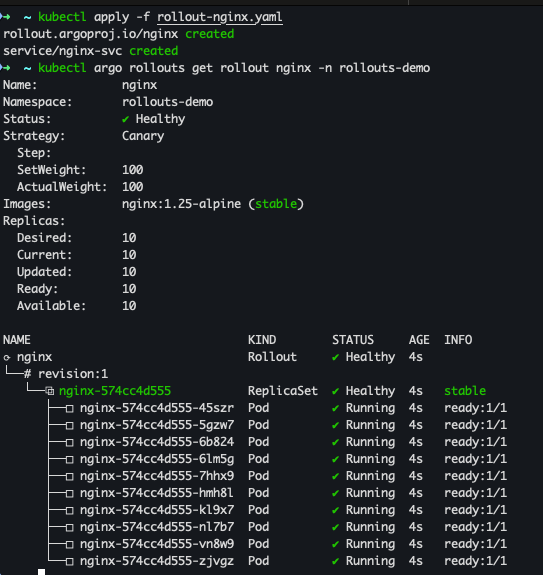
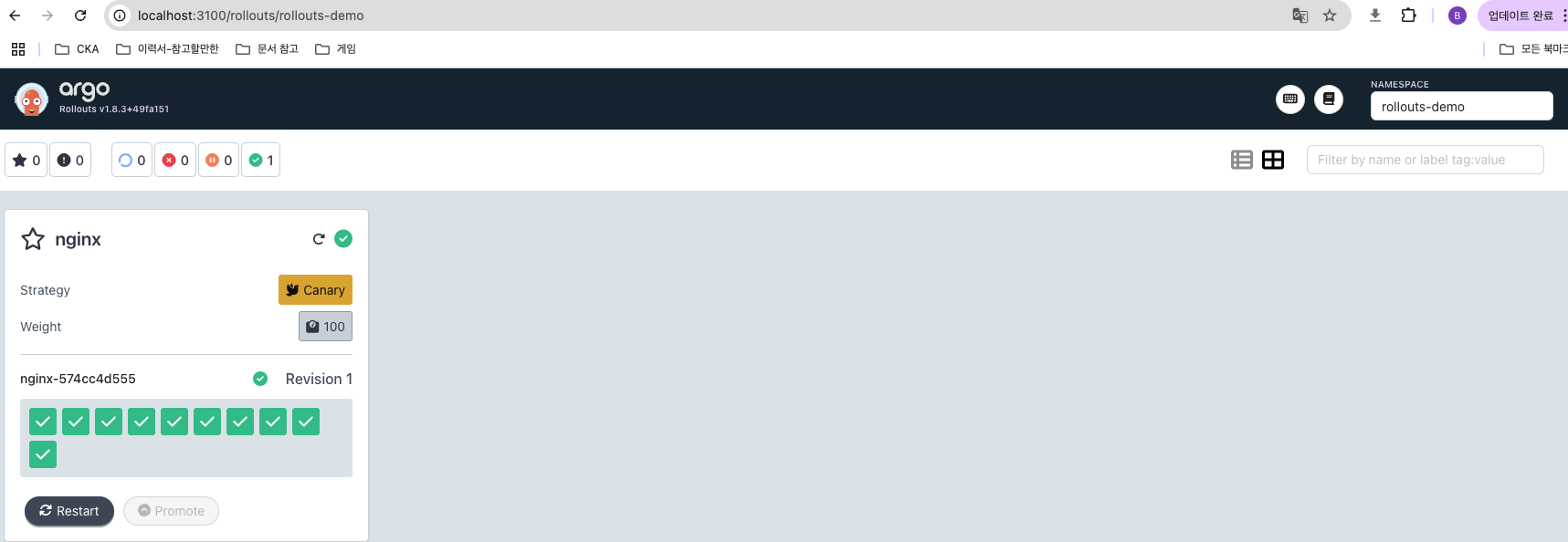
kubectl argo rollouts set image nginx nginx=nginx:1.27-alpine -n rollouts-demo
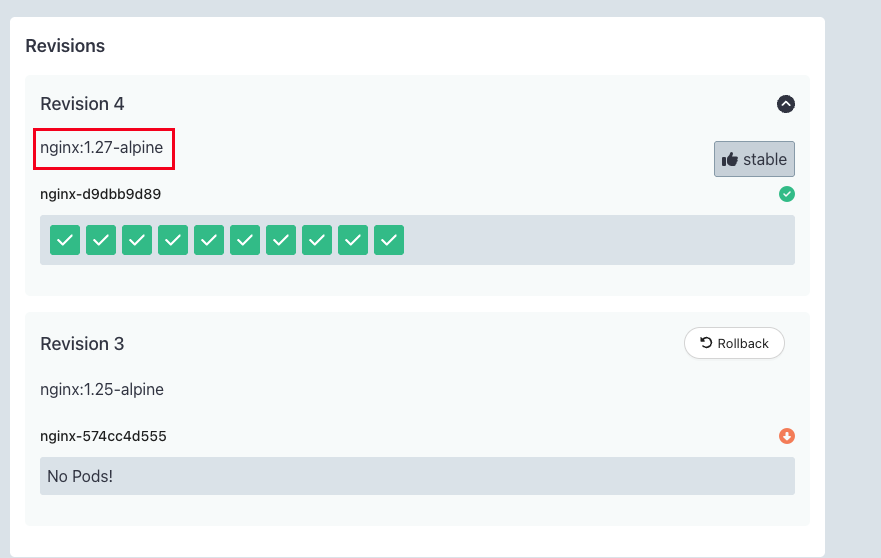
7.2 Blue-Green 배포
services-bluegreen-nginx.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-active
namespace: rollouts-blue-green-demo
labels:
app: nginx
spec:
selector:
app: nginx
ports:
- name: http
port: 80
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-preview
namespace: rollouts-blue-green-demo
labels:
app: nginx
spec:
selector:
app: nginx
ports:
- name: http
port: 80
targetPort: 80rollout-bluegreen-nginx.yaml
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: nginx
namespace: rollouts-blue-green-demo
labels:
app: nginx
spec:
replicas: 10
selector:
matchLabels:
app: nginx
strategy:
blueGreen:
activeService: nginx-active
previewService: nginx-preview
autoPromotionEnabled: false
scaleDownDelaySeconds: 30
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.27.0
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
readinessProbe:
httpGet:
path: /
port: 80kubectl apply -f services-bluegreen-nginx.yaml
kubectl apply -f rollout-bluegreen-nginx.yaml
kubectl argo rollouts get rollout nginx -n rollouts-blue-green-demo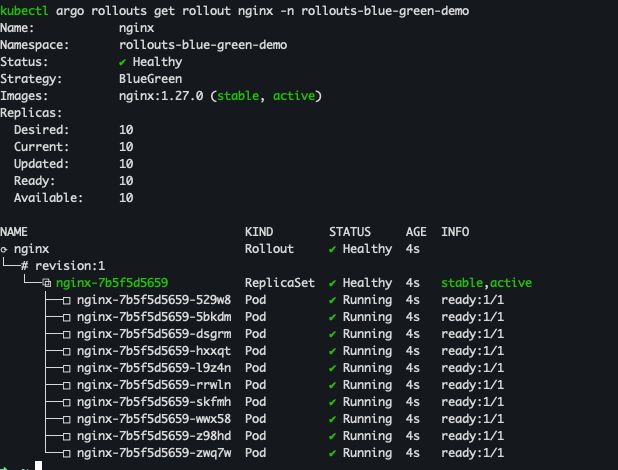

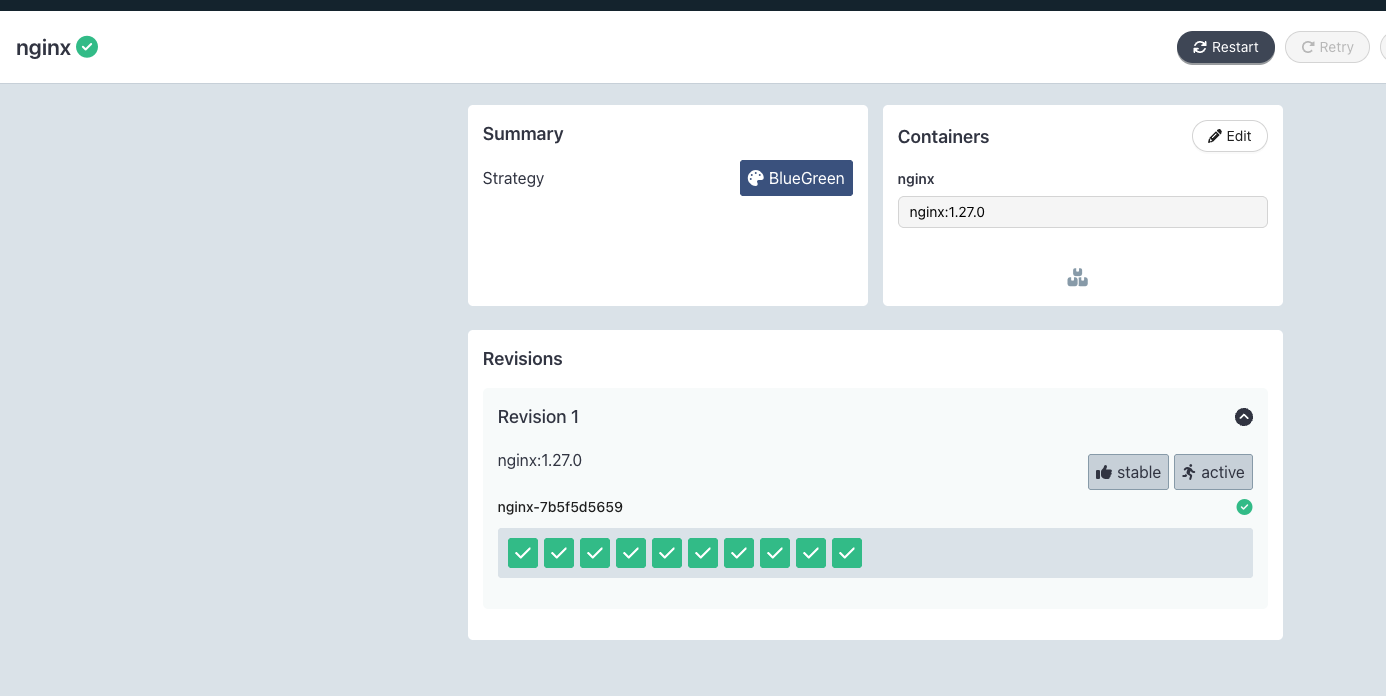
kubectl argo rollouts set image nginx nginx=nginx:1.27-alpine -n rollouts-blue-green-demo
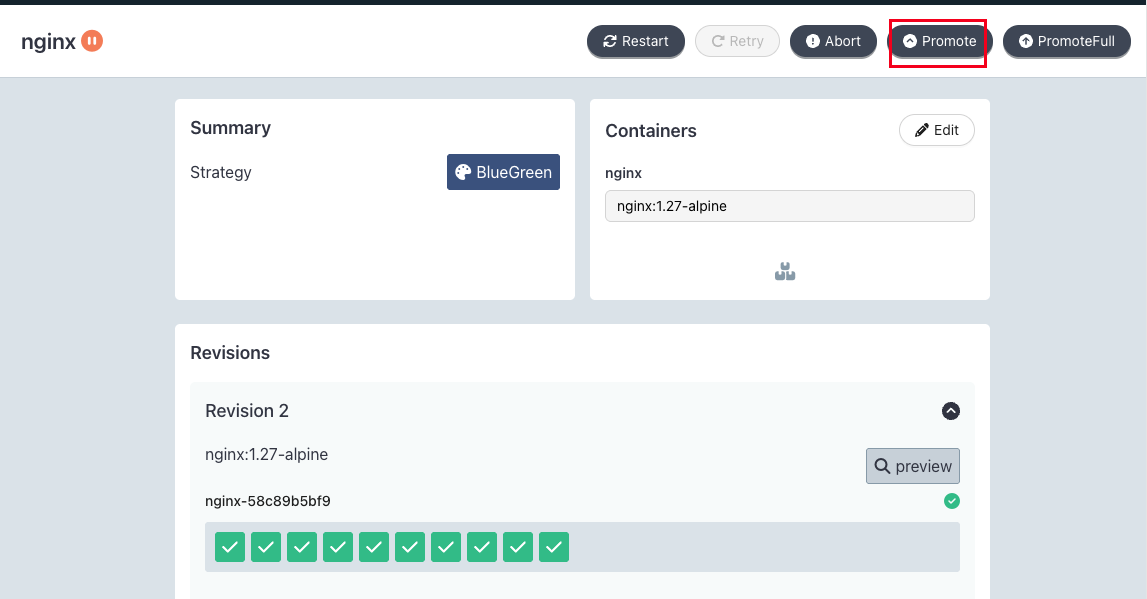
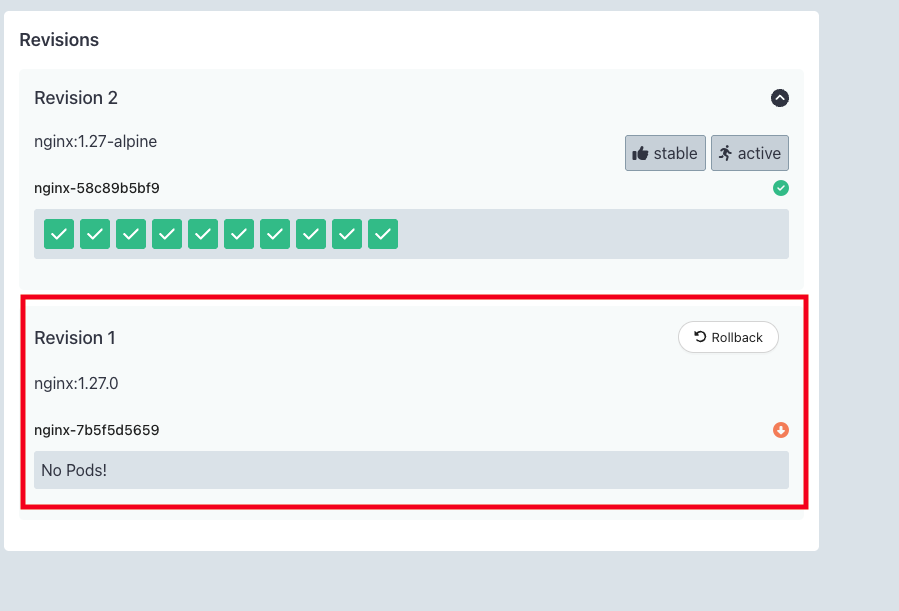
7.3 Canary 배포
rollout-canary-nginx.yaml
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: nginx
namespace: rollouts-canary-demo
labels:
app: nginx
spec:
replicas: 10
selector:
matchLabels:
app: nginx
strategy:
canary:
steps:
- setWeight: 10
- pause: {}
- setWeight: 30
- pause: {}
- setWeight: 50
- pause: {}
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.25.0
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
readinessProbe:
httpGet:
path: /
port: 80kubectl delete deploy nginx --ignore-not-found -n rollouts-canary-demo
kubectl apply -f rollout-canary-nginx.yaml -n rollouts-canary-demo
kubectl argo rollouts get rollout nginx -n rollouts-canary-demo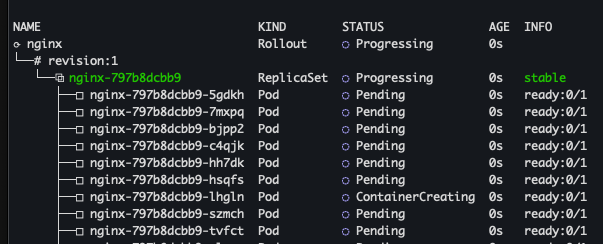
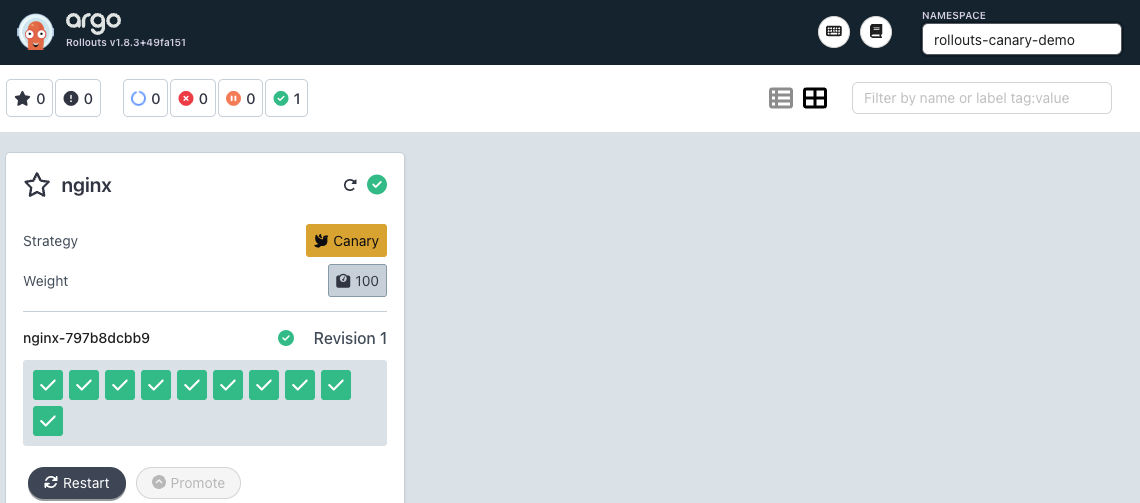
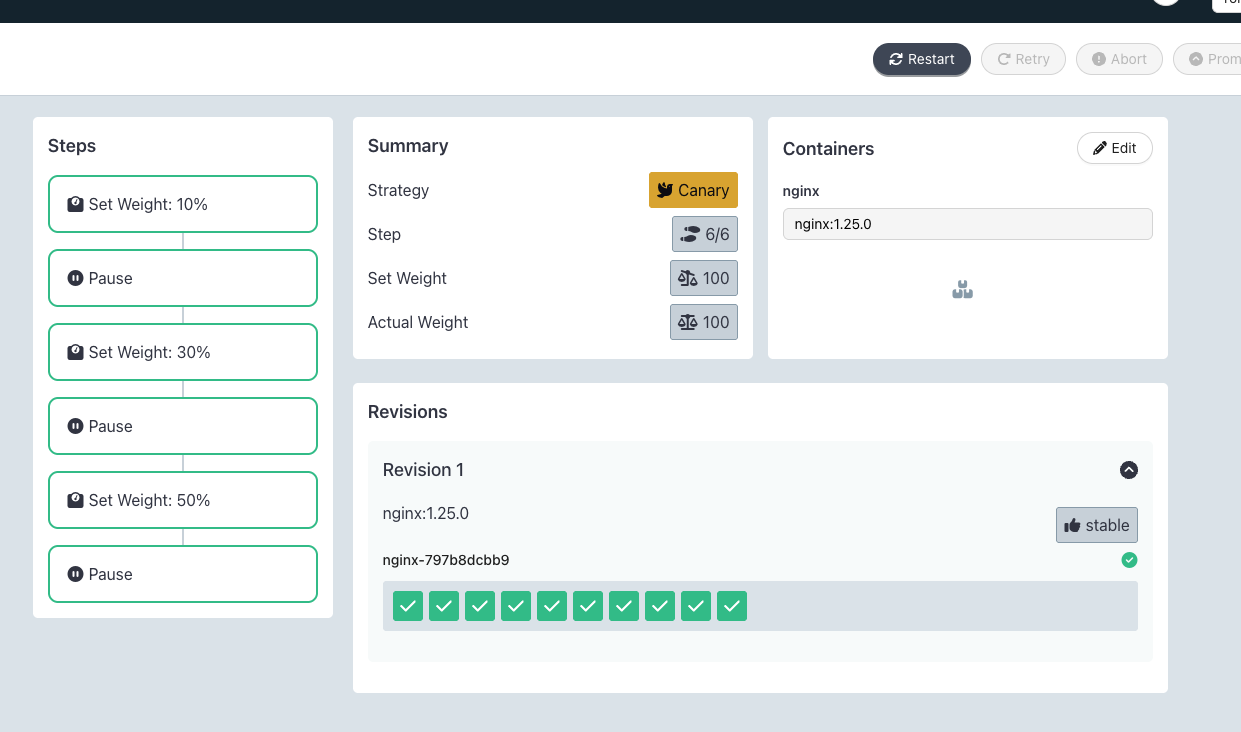
kubectl argo rollouts set image nginx nginx=nginx:1.27-alpine -n rollouts-canary-demo
7.4 실습 리소스 정리
kubectl delete all --all -n rollouts-demo
kubectl delete all --all -n rollouts-blue-green-demo
kubectl delete all --all -n rollouts-canary-demo
kubectl delete ns rollouts-demo
kubectl delete ns rollouts-blue-green-demo
kubectl delete ns rollouts-canary-demo8. 운영 관점 - 필수 고려 사항
8.1 Graceful Shutdown (SIGTERM 처리)
배포 중 기존 Pod가 종료될 때, 현재 처리 중인 요청을 안전하게 마무리해야 합니다.
- SIGTERM 수신: 앱은 새로운 요청 수락을 중단.
- preStop Hook: LB에서 Pod IP가 완전히 제거될 때까지 잠시 대기 (예:
sleep 10). - 진행 중 요청 완료: 타임아웃 전까지 비즈니스 로직 마무리.
spec:
terminationGracePeriodSeconds: 60 # 기본 30초, 긴 트랜잭션 서비스는 증가
containers:
- name: myapp
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 10"] # iptables 전파 대기주의
결제, 대용량 파일 업로드 등 긴 트랜잭션을 처리하는 서비스는
terminationGracePeriodSeconds를 충분히 늘리지 않으면 배포 중 데이터 손실이 발생합니다.
8.2 Health Probe의 역할
- Liveness: 컨테이너가 살아있는가? (실패 시 재시작)
- Readiness: 트래픽을 받을 준비가 되었는가? (실패 시 LB에서 제외)
- Startup: 앱이 기동 중인가? (기동 완료 전까지 Liveness/Readiness 체크 유예)
8.3 Sticky Session 이슈
RollingUpdate 진행 시, 세션 고정(Sticky Session)이 설정되어 있다면
클라이언트가 특정 Pod에 묶여 배포 중 연결이 끊기거나 구버전으로 계속 접속되는 문제가 발생할 수 있습니다.
- 해결책: Redis 등을 활용한 Session Clustering을 도입하거나,
connection: close헤더를 통해 재접속을 유도해야 합니다.
8.4 PDB와 maxUnavailable 충돌 주의
- PodDisruptionBudget(PDB)이 너무 보수적으로 설정되어 있으면, RollingUpdate 중 Rollout이 완전히 멈추는(Blocking) 상황이 발생합니다.
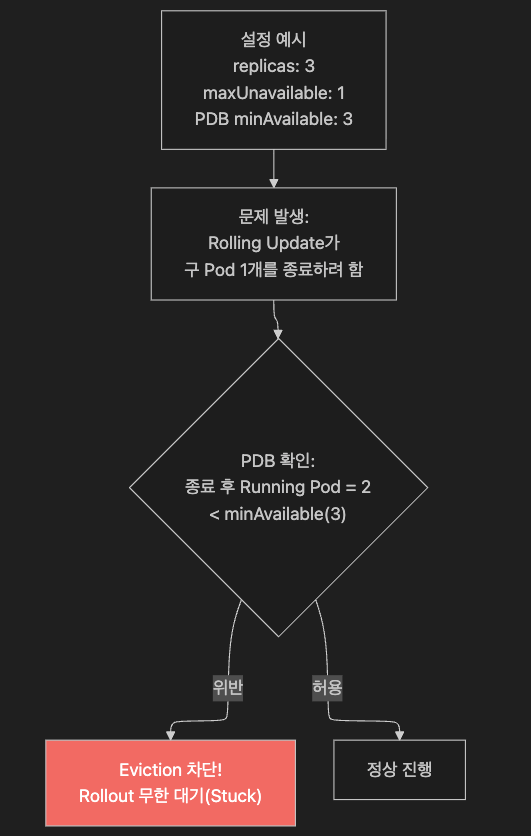
올바른 PDB 설정:
# replicas: 3 기준 올바른 조합 예시
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: myapp-pdb
spec:
# minAvailable: 2 ← replicas - maxUnavailable 이하로 설정해야 함
maxUnavailable: 1 # maxUnavailable 방식으로 설정 (Deployment maxUnavailable과 일치)
selector:
matchLabels:
app: myapp| 설정 | 결과 |
|---|---|
minAvailable: 3 + maxUnavailable: 1 (replicas=3) | Rollout Stuck — 종료 불가 |
minAvailable: 2 + maxUnavailable: 1 (replicas=3) | 정상 — 최소 2개 유지, 1개씩 교체 가능 |
maxUnavailable: 1 (PDB) + maxUnavailable: 1 (Deployment) | 일관성 있는 설정 |
[운영 팁]
PDB와 Deployment의maxUnavailable은 서로 모순되지 않도록 쌍으로 검토해야 합니다.
노드 드레인, 업그레이드 시에도 이 설정이 적용됩니다.
9. 고가용성 & 모니터링
9.1 Topology Spread Constraints
특정 노드나 존(Zone)에 Pod가 몰려 배포 시 한꺼번에 죽는 것을 방지합니다.
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: myapp9.2 주요 모니터링 메트릭
배포 성공 여부를 판단하기 위해 다음 메트릭을 관찰해야 합니다.
kube_deployment_status_replicas_available: 가용한 Pod 수.http_requests_total{code=~"5.."}: 배포 중 에러율 급증 여부.container_cpu_usage_seconds_total: 신버전의 자원 사용량 변화.
9.3 SLO / 에러 버짓 기반 배포 게이트
"지금 배포해도 되는가?" 를 직관이 아닌 데이터로 판단하는 운영 기준을 정의해야 합니다.
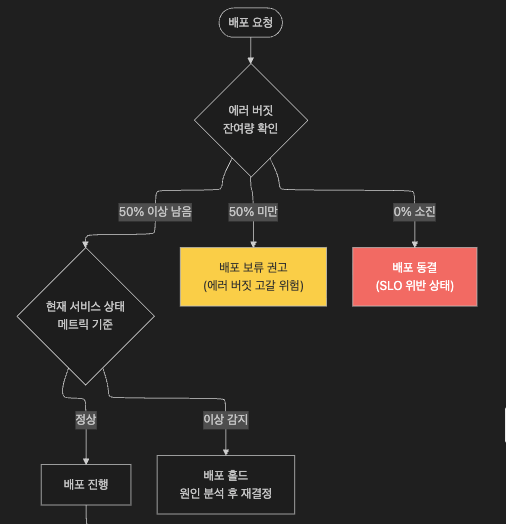
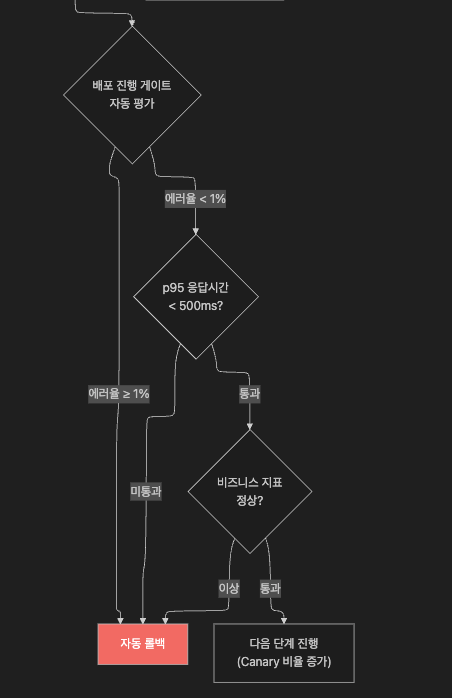
배포 게이트 기준 예시 (팀별로 SLA 기반 조정 필요)
| 지표 | 정상 기준 | 경고 임계치 | 자동 롤백 임계치 |
|---|---|---|---|
| HTTP 5xx 에러율 | < 0.1% | 0.1% ~ 1% | ≥ 1% |
| p95 응답 시간 | < 200ms | 200ms ~ 500ms | ≥ 500ms |
| p99 응답 시간 | < 500ms | 500ms ~ 1s | ≥ 1s |
| 주문/결제 성공률 | > 99.9% | 99% ~ 99.9% | < 99% |
| 에러 버짓 소진율 | < 30%/주 | 30% ~ 70%/주 | > 70%/주 |
에러 버짓 기반 배포 동결
SLO를 30일 기준으로 설정했을 때, 에러 버짓이 0%에 도달하면 추가 기능 배포는 동결하고
안정화 작업만 허용합니다.
Google SRE 방법론의 핵심 원칙 중 하나입니다.
10. Kubernetes v1.35 최신 기능
v1.35 (Timbernetes) 릴리즈에서는 배포 운영의 효율성을 높이는 중요한 기능들이 포함되었습니다.
[주의] 버전 정보
아래 GA/Beta/Alpha 분류는 v1.35 릴리즈 노트 기준입니다.
기능 상태는 마이너 버전마다 변경될 수 있으므로, 실제 적용 전 공식 릴리즈 노트 및
kubectl api-resources로 현재 클러스터의 지원 여부를 반드시 재확인하세요.
10.1 terminatingReplicas 필드 (Beta, 기본 활성화)
Deployment와 ReplicaSet의 .status 필드에 terminatingReplicas가 추가되어, 현재 종료 중인 Pod의 수를 API 수준에서 즉시 확인할 수 있습니다. (DeploymentReplicaSetTerminatingReplicas 피처 게이트 Beta 승격)
# v1.35에서 확인 가능한 상태값
kubectl get deployment myapp -o jsonpath='{.status.terminatingReplicas}'
# 배포 완전 완료(구 Pod 모두 사라짐) 대기 스크립트
until [[ "$(kubectl get deployment myapp \\
-o jsonpath='{.status.terminatingReplicas}')" == "0" || \\
-z "$(kubectl get deployment myapp \\
-o jsonpath='{.status.terminatingReplicas}')" ]]; do
echo "종료 중인 Pod 남아있음... 대기 중"
sleep 3
done
echo "배포 완전 완료"- 효과: 배포가 "완전히" 끝났는지 확인하기 위해 일일이 Pod 목록을 조회할 필요 없이, Operator나 CI/CD 파이프라인에서
.status.terminatingReplicas == 0조건으로 완료를 감지할 수 있습니다.
10.2 In-Place Pod Resource Resize (GA)
컨테이너를 재시작하지 않고 CPU/메모리 리소스를 변경할 수 있는 기능이 Stable(GA)이 되었습니다. (v1.27 Alpha → v1.33 Beta → v1.35 GA)
# 배포 없이 컨테이너 리소스 즉시 변경 (트래픽 급증 대응)
kubectl patch pod myapp-pod-xyz --subresource=resize \\
-p '{"spec":{"containers":[{"name":"myapp","resources":{"requests":{"cpu":"2"},"limits":{"cpu":"4"}}}]}}'- 배포 관점의 이점: 리소스 할당량만 늘리고 싶을 때, RollingUpdate 없이 즉시 적용 가능합니다.
- 제한 사항: 현재 CPU와 메모리만 지원하며, Windows 노드는 지원하지 않습니다.
10.3 Pod Replacement Policy (Alpha)
Deployment에서 신규 Pod 생성 시점을 제어하는 정책입니다. (피처 게이트 활성화 필요, Alpha 단계)
TerminationStarted: 종료 시작 시 즉시 교체 (기본 동작, 속도 우선).TerminationComplete: 완전히 종료된 후 교체 (리소스 제약 환경, 싱글톤 서비스).
# Alpha 피처 — 프로덕션 적용 전 충분한 검증 필요
spec:
strategy:
type: RollingUpdate
rollingUpdate:
podReplacementPolicy: TerminationComplete11. 참고 자료
- Kubernetes Deployments 공식 문서
- Kubernetes v1.35 릴리즈 노트 (Timbernetes)
- KEP-3973: terminatingReplicas for Deployments
- Kubernetes In-Place Pod Vertical Scaling (GA)
- PodDisruptionBudget 공식 문서
- Argo Rollouts 공식 문서
- Argo Rollouts - AnalysisTemplate 가이드
- OpenFeature — CNCF Feature Flag 표준
- Google SRE Book — Error Budget Policy
- Kubernetes Health Probe 공식 가이드
- Expand/Contract DB Migration Pattern — Prisma

4개의 댓글

Argo Rollouts 실습 올려주셔서 좋았습니다! 실무에서 Rollout 컨트롤러 선택할 때, Argo Rollout 외에 Flagger, Spinnaker 등도 있는 것으로 알고 있는데, 어떤 기준으로 선택하면 좋을까요?"
작성해주신 글 잘 봤습니다. 감사합니다 ㅎㅎ. 혹시 Argo Rollout 기능 중에서 트래픽을 복사해오는 기능이 있을까요? BlubeGreen 있는 것을 보니 궁금해서요. 물론 내부적으로 단순히 Service 업데이트 하는 것일 수도 있지만, 혹시나 다른 배포 전략을 고려해서 트래픽 복사해오는 기능까지 구현되어 있는지 혹시 아시는 부분이 있는지 궁금해서요.