목차
1. 프로젝트 개요
2. 시스템 구조
3. 개발 환경
4. 코드 설명
5. 결과
6. 마무리
1. 프로젝트 개요
때는 내가 회사에 가기 한 달 전..
학교에서 평화롭게? 준비를 하던 내 앞에 파이썬 크롤링 과제가 떨어졌다.
어렵진 않았지만 귀찮았던 나는 2주를 미뤄버렸고...
어떤 프로젝트를 하면 좋을지 고민하던중, 유튜브 영상에 달린 댓글들을 기반으로 AI 모델로 분석해 그 영상을 본 시청자들의 전체적인 분위기?를 알 수 있는 프로젝트를 하기로 했다.
주요 기술: Playwright, BeautifulSoup, 허깅페이스의 tabularisai/multilingual-sentiment-analysis모델
2. 시스템 구조
youtube_sentiment_project/ <- 프로젝트 루트 폴더
│
├─ youtube_scraper.py <- 유튜브 댓글 수집 및 가공
├─ sentiment_analysis.py <- AI 감정 분석
유튜브 → Playwright로 크롤링 → BeautifulSoup으로 파싱 → 댓글 추출 → AI 감정분석 → 결과 반환
실행 방법
>python youtube_scraper.py 원하는 영상 링크
3. 개발 환경
Python 3.10 이상
- youtube_scraper.py파일 - 유튜브 댓글 수집 및 가공용
Playwright
설치: pip install playwright
브라우저 드라이버 설치 필요: playwright install
사용 이유: 유튜브처럼 동적 로딩 페이지에서 스크롤하면서 댓글까지 가져오기 위함.
실행 환경: Windows (C:\Program Files\Google\Chrome\Application\chrome.exe 경로 사용)
BeautifulSoup
설치: pip install beautifulsoup4
사용 이유: Playwright로 가져온 HTML에서 댓글 텍스트만 추출하기 위함.
time, sys
Python 기본 내장 모듈
sentiment_analysis
sentiment_analysis.py 파일과 연동됨
- sentiment_analysis.py파일 – 댓글 감정 분석
Transformers
설치: pip install transformers
사용 이유: Hugging Face 모델을 이용해 감정 분석 수행
모델: tabularisai/multilingual-sentiment-analysis
긍정/부정/중립 분류
collections.Counter
Python 기본 내장 모듈
사용 이유: 분석 결과 집계
4. 코드 설명
youtube_scraper.py파일
from playwright.sync_api import sync_playwright
import sys
from bs4 import BeautifulSoup
import time
import sentiment_analysis
video_link = sys.argv[1] #실행하면서 유튜브 영상 링크 받기
check_string = "https://www.youtube.com/watch?"
def run_playwright(): #유튜브 페이지 열고 댓글 로딩해 가져오는 함수
if check_string in video_link: #올바른 링크인지 확인
with sync_playwright() as p:
browser = p.chromium.launch(
headless=False, #True로 하면 페이지 안뜸
executable_path="C:/Program Files/Google/Chrome/Application/chrome.exe"
) #오류로 PC에 설치된 크롬사용(senwifi 때문으로 추정)
page = browser.new_page()
page.goto(video_link)
page.wait_for_timeout(3000) #페이지 로딩
last_count = 0
retry = 0
# 페이지 끝까지 스크롤하며 댓글 로딩
while True:
page.evaluate("window.scrollBy(0, 1000)")
page.wait_for_timeout(1500)
comments = page.query_selector_all("ytd-comment-thread-renderer")
if len(comments) == last_count:
retry += 1
if retry > 3: # 연속 3번 변화 없으면 종료
break
else:
retry = 0
last_count = len(comments)
html = page.content() #BeautifulSoup하기 위해 HTML 가져옴
browser.close()
return html #HTML 반환
else:
print("올바른 유튜브 링크를 입력해주세요.")
sys.exit(0)
def run_BeautifulSoup(html): #가져온 html에서 댓글 추출하는 함수
soup = BeautifulSoup(html, "html.parser")
comment_elements = soup.select("ytd-comment-thread-renderer #content-text")
comments = [] #댓글 모음 배열
for i in comment_elements:
text = i.get_text(strip=True)
comments.append(text)
return comments
if __name__ == "__main__":
start = time.time() #걸린 시간 측정
html = run_playwright() #로딩된 HTML 반환
comments = run_BeautifulSoup(html) #HTML에서 comments만 반환
result = sentiment_analysis.analyze_sentiment(comments)# comments를 ai로 감정분석
end = time.time()
print(f"소요 시간: {end - start:.2f}초")
print(f"댓글 수: {len(comments)}개")
print(result)
sentiment_analysis.py파일
from transformers import pipeline
from collections import Counter
def analyze_sentiment(comments):
if not comments:
return "댓글이 없어서 감정 분석을 진행할 수 없습니다."
model = pipeline("text-classification", model="tabularisai/multilingual-sentiment-analysis")
results = []
for comment in comments:
try:
prediction = model(comment)
if prediction:
results.append(prediction[0]['label'])
except Exception as e:
continue
if not results:
return "분석 가능한 댓글이 없습니다."
simplified = []
for r in results:
if r in ['Very Positive', 'Positive']:
simplified.append('긍정적')
elif r in ['Very Negative', 'Negative']:
simplified.append('부정적')
else:
simplified.append('중립')
counts = Counter(simplified)
overall_emotion = counts.most_common(1)[0][0]
formatted_result = (
f"- 긍정적: {counts.get('긍정적',0)}\n"
f"- 부정적: {counts.get('부정적',0)}\n"
f"- 중립: {counts.get('중립',0)}\n"
f"전체적인 분위기: {overall_emotion}입니다"
)
return formatted_result
사실 이런 AI 모델은 처음써봐서, 이 부분은 AI(ChatGPT)의 도움을 많이 받았다.
5. 결과
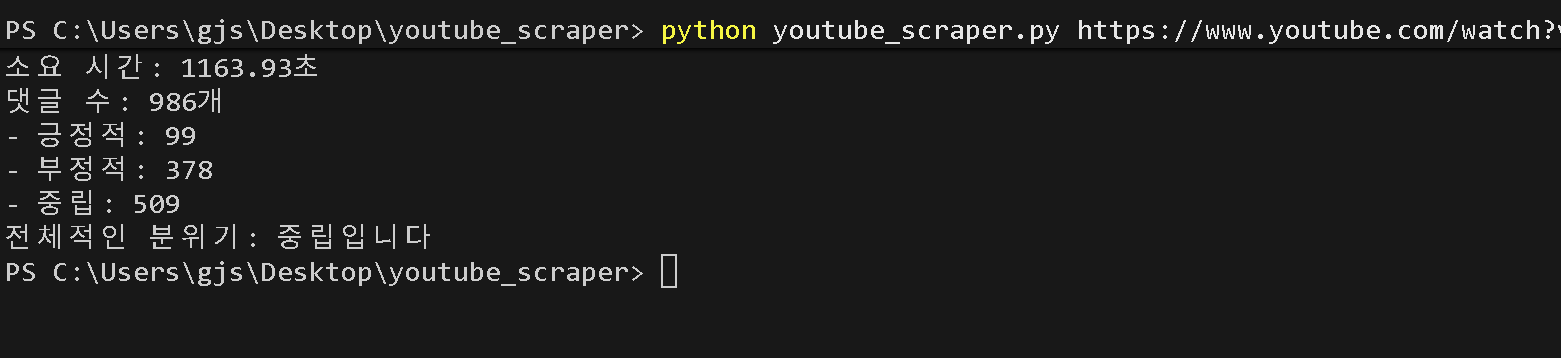
이렇게 그 영상이 시청자들에게 어떻게 받아들여졌는지 알 수 있다.
6. 마무리
원래는 뉴스 영상의 반응을 쉽게 알기 위해 생각한 프로젝트인 만큼, 각 영상마다 물타기, 봇, 정치 성향 등 다양한 변수가 있을 수 있으므로 결과를 신뢰하기에는 한계가 있고, 재미로 보는 것이 맞을 듯하다. 또한 AI 모델을 처음 써봐서 결과가 불안정할 수도 있을 것 같다.
또한 댓글이 많아질수록 시간이 많이 걸리는 것으로 보아, 댓글 수집 방식이 비효율적이라고 생각한다(다른 좋은 방법이 있을것이다).
원래는 플라스크로 만들까 싶었지만 귀찮아서 패스했다.
그래도 빠른 시간에 후딱 만든 프로젝트 치고는 나쁘지 않았고, 공부도 꽤 되어서 다행이다.
