고려대학교 산업공학과 정태수 교수님 강의 정리
Week1: 강화학습의 이해
1-1. 강화학습 개요
강화학습 정의
강화학습: 주어진 어떤 상황(State)에서 보상(Reward)을 최대화 할 수 있는 행동(Action)을 어떻게 할 것인지를 일련의 과정을 통해서 학습해 나가는 과정
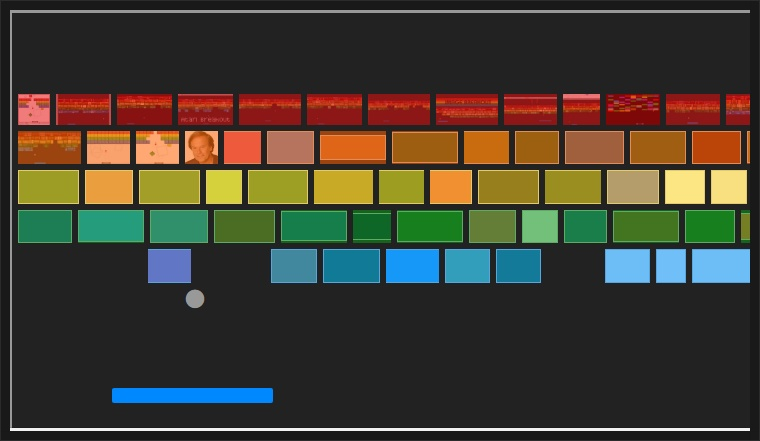
Example (벽돌깨기 게임)
- 목적: 벽돌을 많이 깨는 것
- 상황: 현재 벽돌 상태, 구슬 위치, 하단 바의 위치
- 행동: 상황 정보를 가지고 하단 바를 어떻게 움직일 것인지 결정
- 보상: 어떤 행동을 했을 때 벽돌이 깨지는 양
(목적을 얼마나 잘 따르는지 알 수 있음)
강화학습 특징
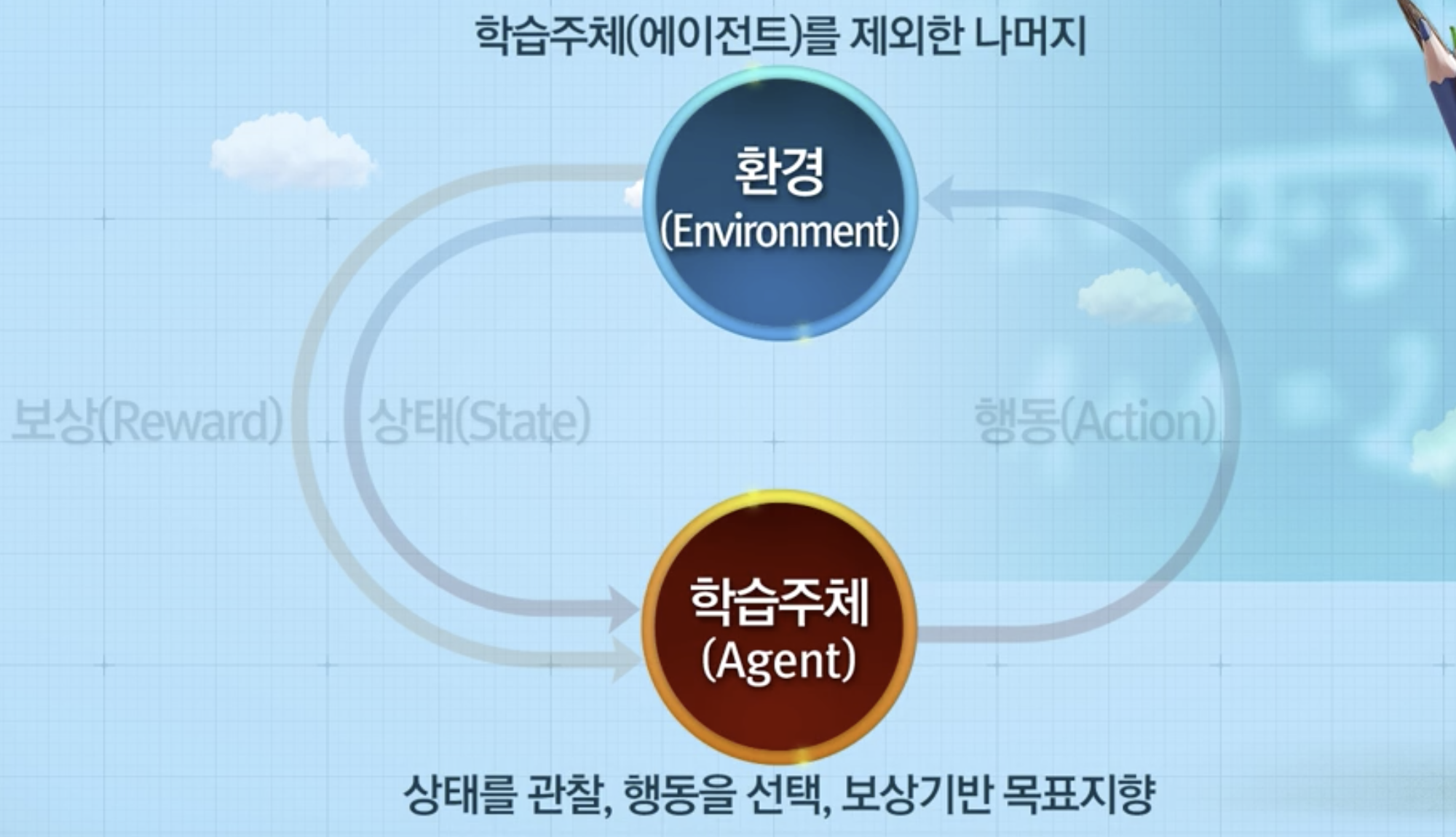
- 학습 주체는 환경에 대해 모르는 상태에서 학습
- agent가 환경에 주어져 있는 상태 정보를 관찰하고 어떤 action을 취함
- action을 했기 때문에 환경에 변화가 생김
- 환경으로 부터 행동에 따른 보상을 받음
- 적합한 행동 학습을 위한 시행착오(Trial & Error) 필요
- 현재 행동이 미래 순차적 보상에 영향 (Delayed reward)
지도학습, 비지도학습과의 차이점
- 지도학습
- 레이블(label)이라는 정답데이터가 존재
- 잘 정의된 데이터로부터 즉각적인 피드백을 받으며 학습
- 현재의 데이터들을 바탕으로 미래를 예측 or 정답이 있는 결과를 맞추는데 활용
- 비지도학습
- 레이블(label)이라는 정답데이터가 존재하지 않음
- 데이터 자체에 내재되어 있는 성질을 찾아내는데 활용
- 강화학습
- 레이블(label)이라는 정답데이터가 존재하지 않음
- 환경과의 상호작용을 통해 얻은 보상을 통해 학습
- 데이터는 환경과의 상호작용을 통해 얻음
1-2. Multi-armed bandit 문제
개요

- 행동(action)에 대한 즉각적인 보상(reward)
- action: 밴딧머신 선택
- 각 밴딧머신에 대한 상태(state) 정보 부재
- 목적: 주어져 있는 횟수에서 총 보상 최대화를 위한 슬롯머신 선택
어떻게 게임을 진행할까?
- 랜덤하게 시도하여 탐색 시작
- 시도를 통한 보상값을 통해 의사결정
Exploration, Exploitation
- Exploration: 아무것도 모르는 상태에서 탐색
- Exploitation: 누적 정보를 바탕으로 슬롯머신 선택
강화학습은 일반적으로Exploration, Exploitation의 trade-off를 가지고 학습을 하게됨
예시 (임상시험)
- 약의 좋고 나쁜점을 시행 착오를 통해 학습함
- 행동(action): 약 투여 (red, blue, green)
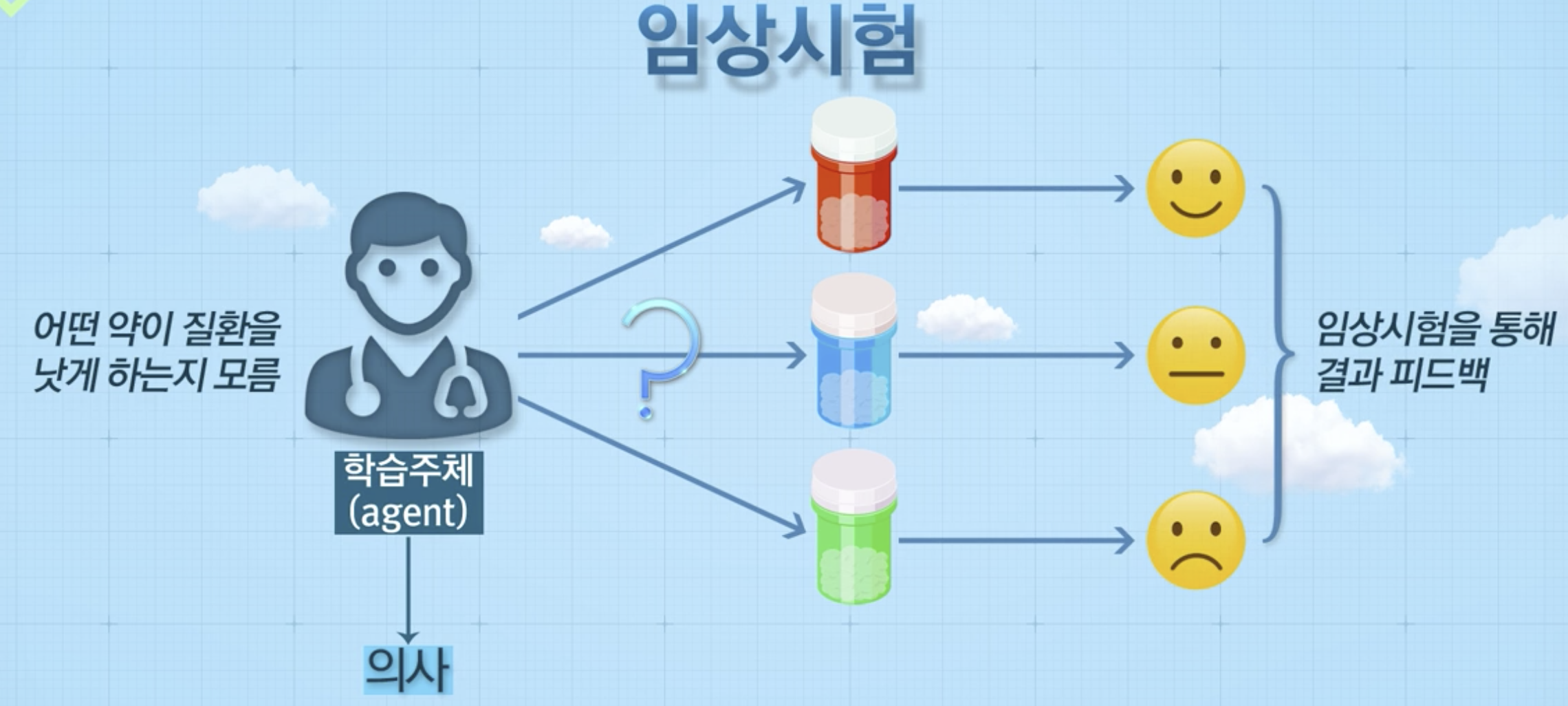
Multi-armed bandit 문제란?
- 학습주체(agent)가 k개의 행동(action) 중 하나를 선택하고,
- 선택한 행동에 따라 보상(reward)을 받는 일련의 과정을 통해
- 일정 기간동안 취득한 보상의 총합에 대한 기대값을 최대화하도록 어떠한 행동들을 취할지 결정하는 문제
행동 가치 (action values)
- 정의: 특정 시점에서 어떠한 행동을 취했을 때의 보상에 대한 기댓값
- 학습 주체가 하고자 하는, 의사결정을 하는데 지표가 됨
- 최적의 가장 좋은 행동가치에 대한 정보 부재
- 반복된 실험을 통해 얻은 정보를 기반으로 행동 가치 추정
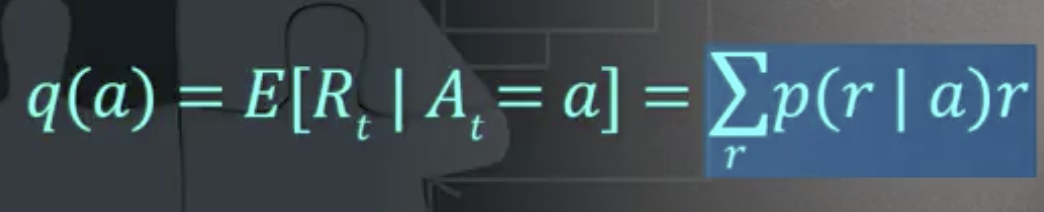
- 보상이 일어날 확률과 보상을 곱하면 기댓값을 계산 가능
- 문제: 학습주체가 각각의 보상에 대한 분포를 모름 (k-armed bandit)
- 분포를 이미 다 알고 있으면, 분포의 기댓값을 최대화하는 슬롯머신을 찾아 당기면 됨
- 행동 가치함수를 일련의 시행착오를 통해 추정을 할 수 있게 된다면, 가장 좋은 행동, 가장 좋은 슬롯머신을 선택할 수 있음
행동 가치를 추정하는 가장 단순한 방법
-
표본평균 방법 (Sample-mean method)

-
예시 (어떤 색의 약을 쓸 것인가)
- 파란색 약이 보상 가치가 가장 높기 때문에, 파란색 약을 사용할 것
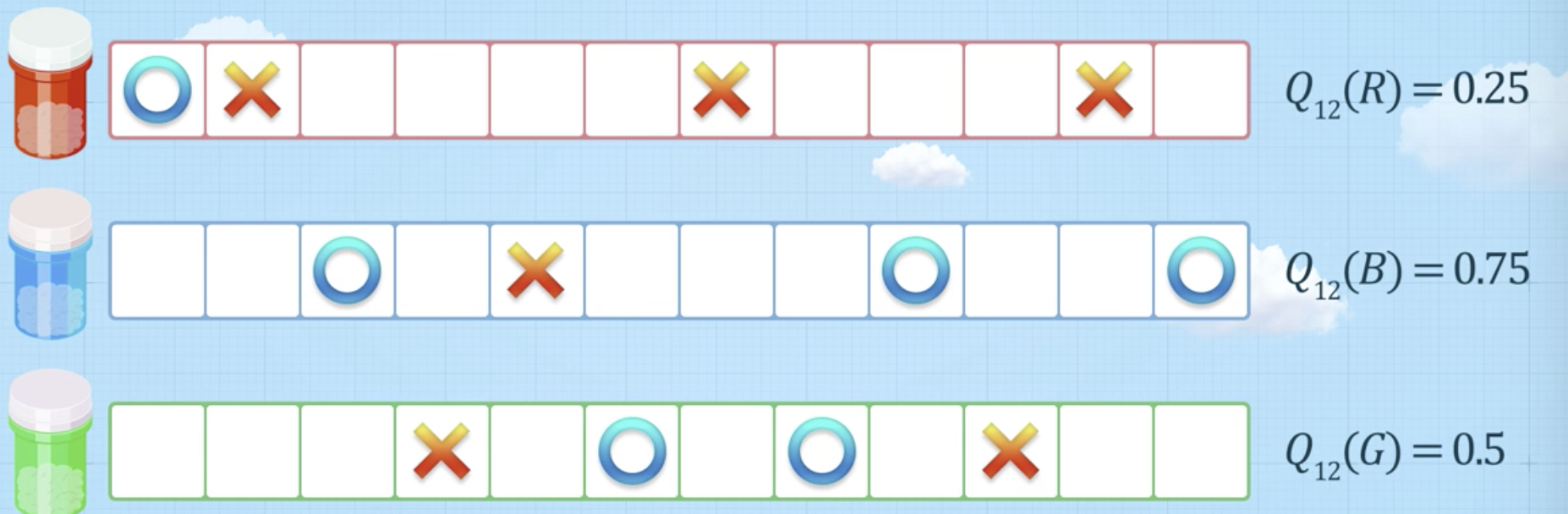
- 파란색 약이 보상 가치가 가장 높기 때문에, 파란색 약을 사용할 것
행동 가치 추정치 를 보다 효율적으로 계산할 수 있는 방법


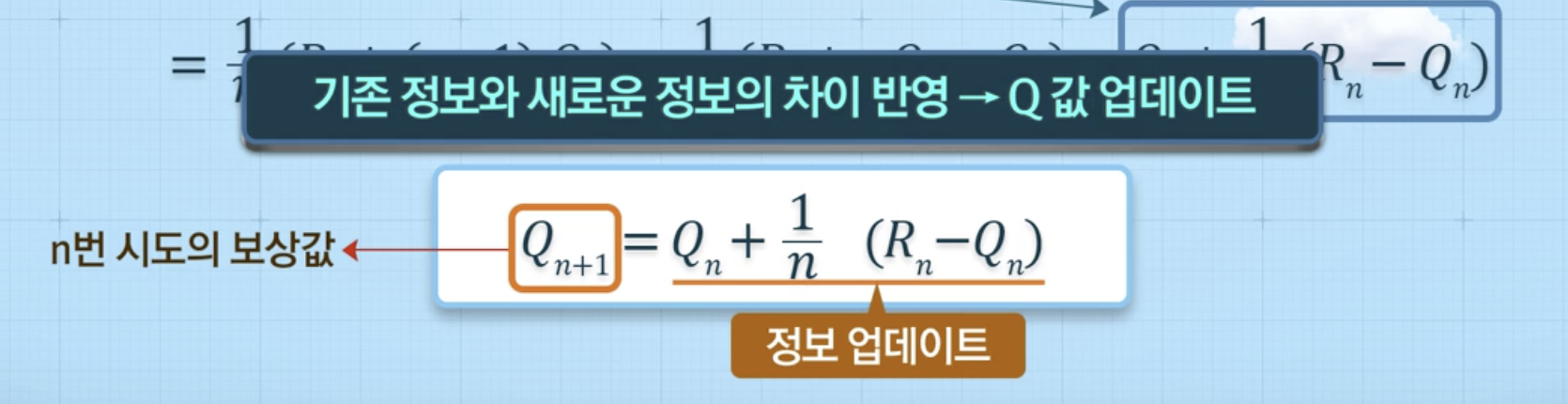
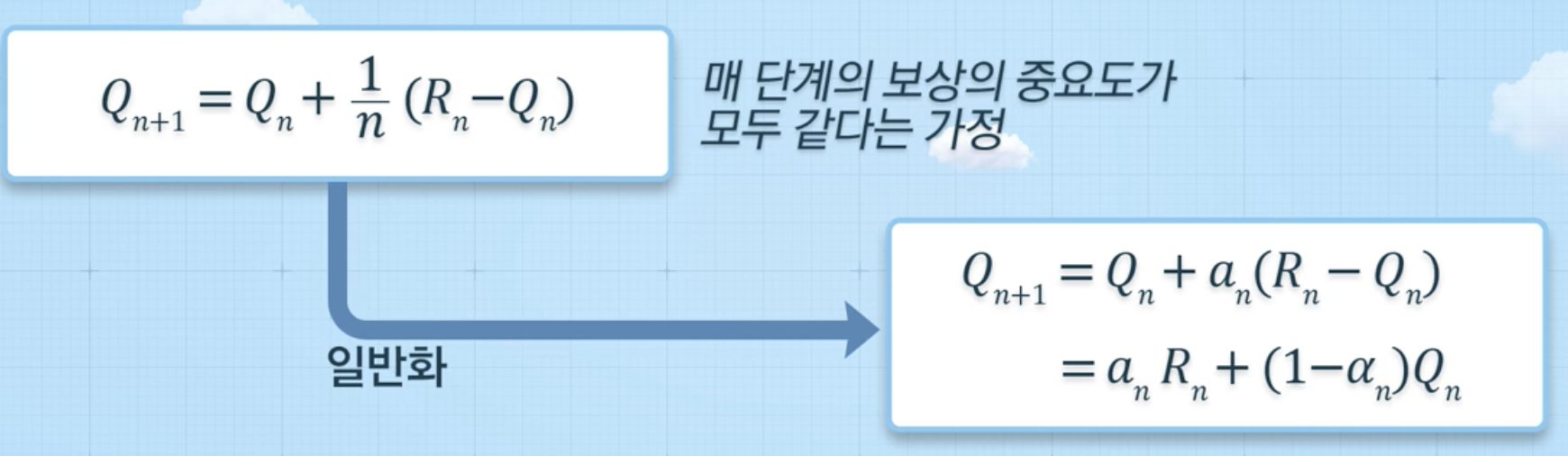
추정치 업데이트 방식
-
새로운 정보와 기존 정보의 차이만큼 반영

-
기존 정보와 새로운 정보의 가중 평균

1-3. 강화학습 맛보기
Q러닝에서 정보를 단계별로 업데이트 하는 방법

-
-> State 에서 Action 선택 시 얻을 수 있는 최대 누적 보상의 기대치
-
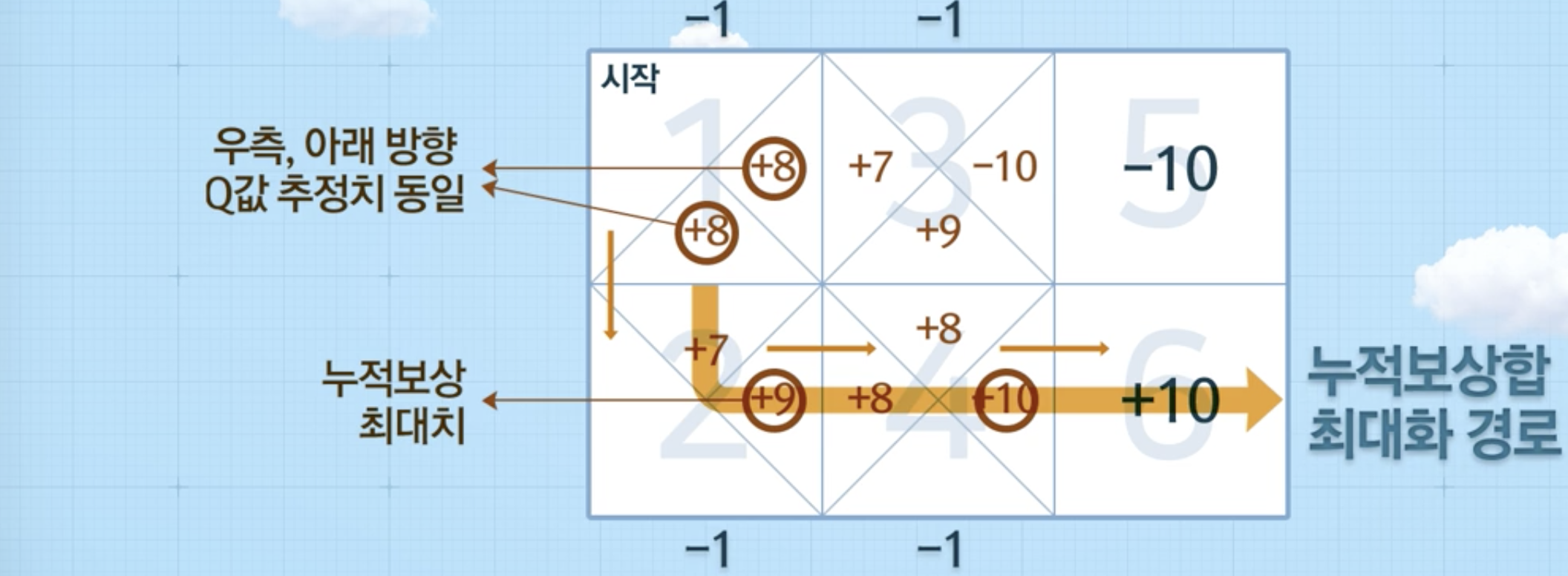
에피소드(Episode): 학습 과정
- ex. 1 >> 3 >> 5, 1 >> 2 >> 4>> 6
-
예시
- 1 > 3 > 5를 하는 경우
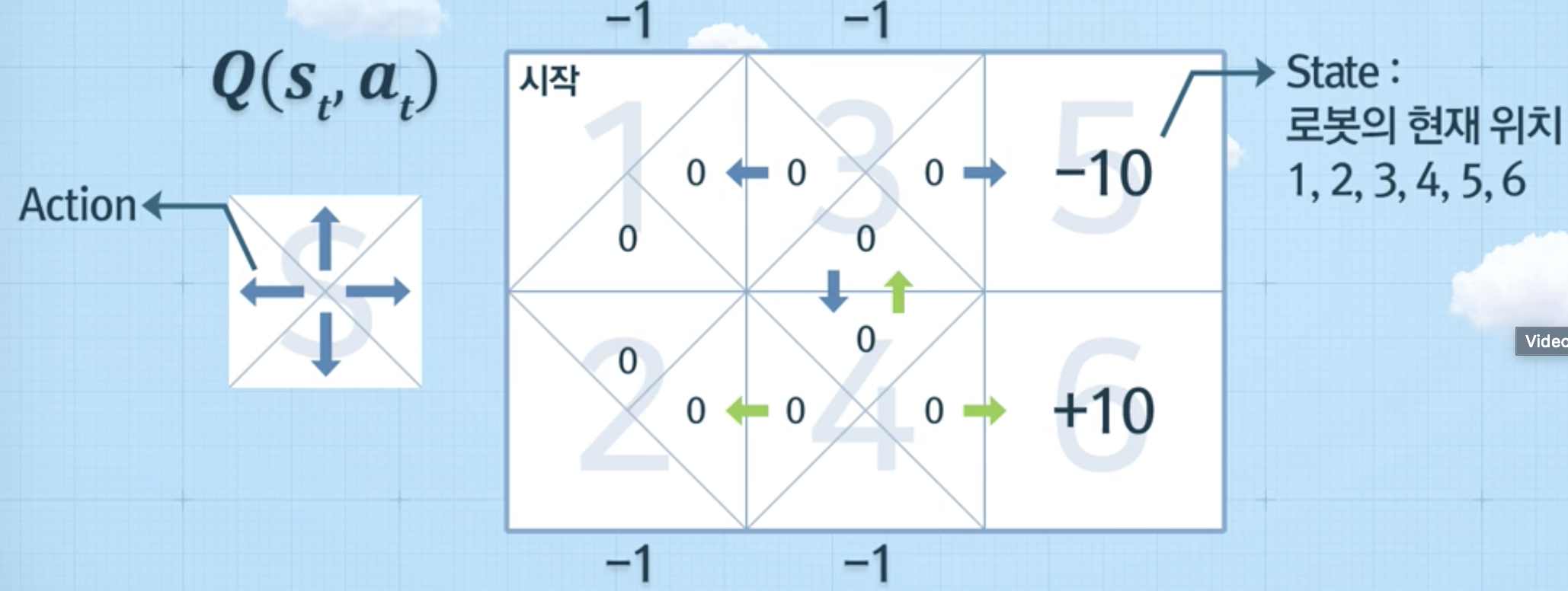
- 1 --> 3 (보상 -1) 보상 업데이트

- 3 --> 5 (보상 -10), 5에서는 더 이상 이동 X, 그 이후 추정치 X --> episode 종료
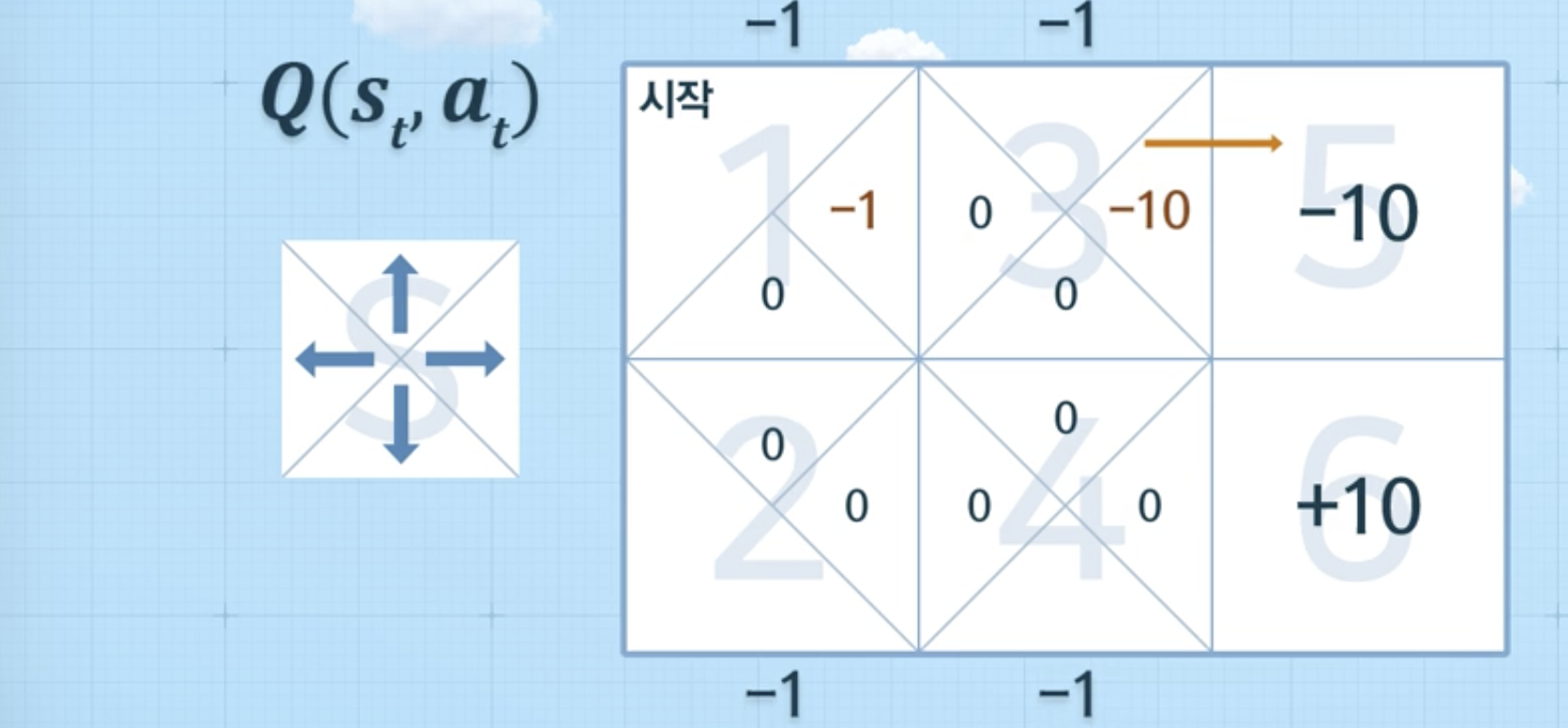
- 1 > 2 > 4 > 6 완료 시 (episode 종료),
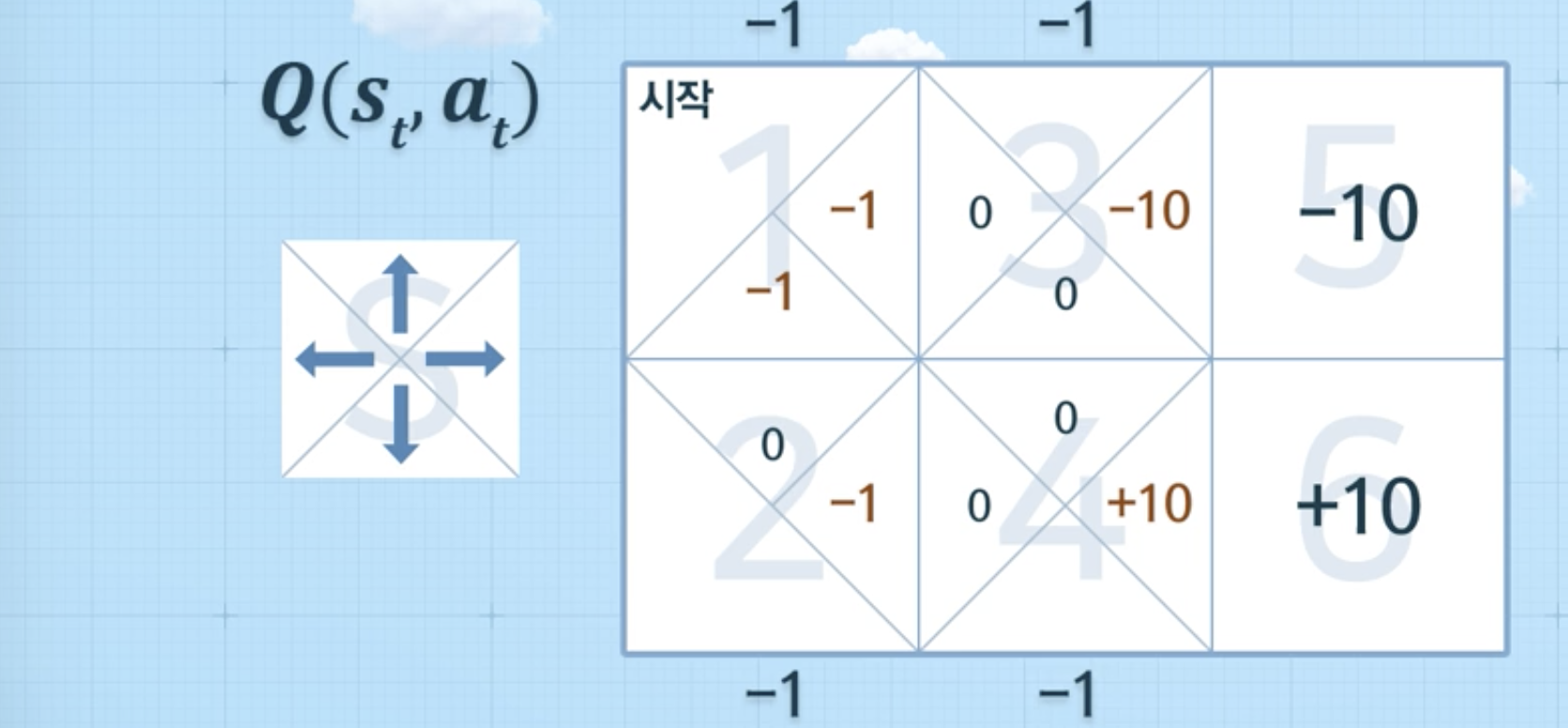
- 1 > 2 > 4 > 3 > 5 완료 시 (episode 종료),
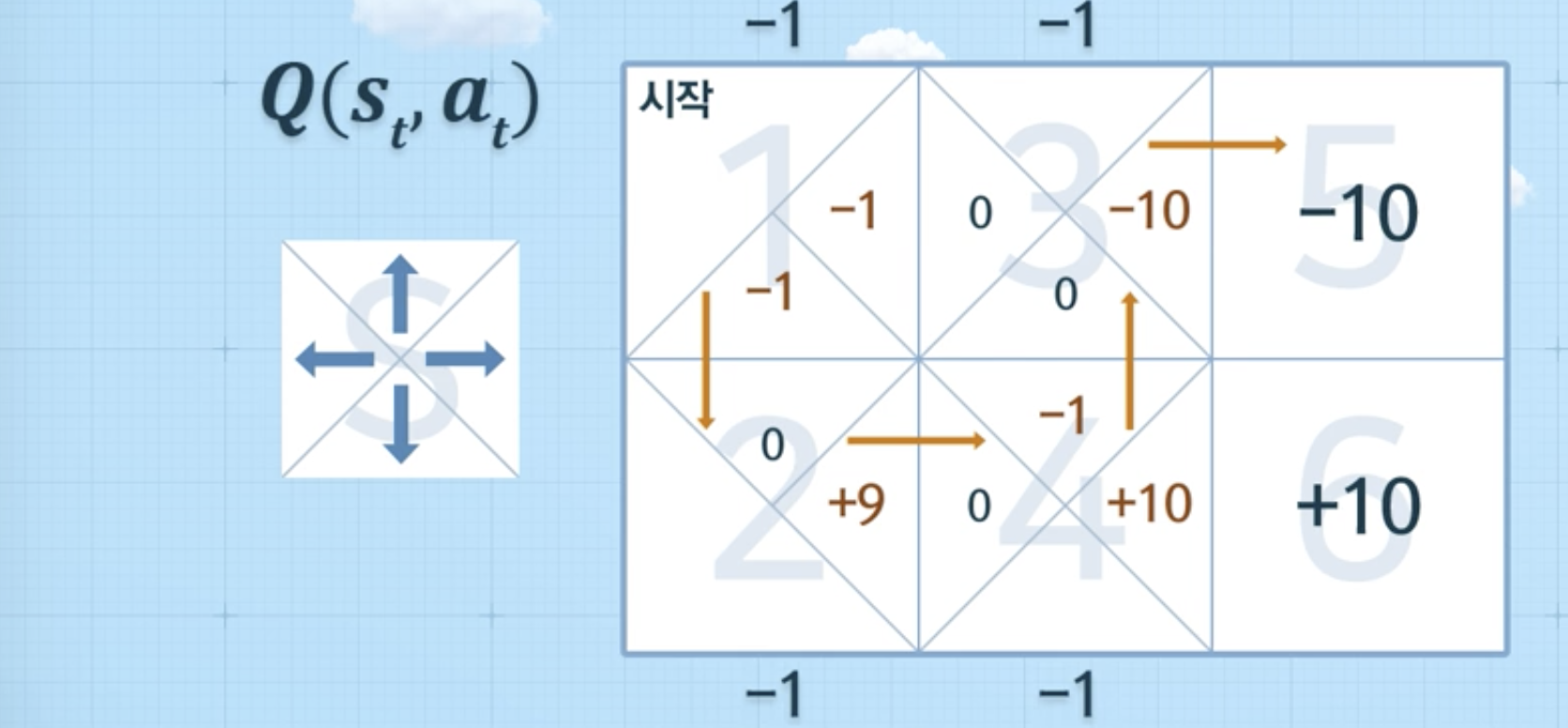
- 1 > 3 > 4 > 3 > 5 완료 시 (episode 종료),
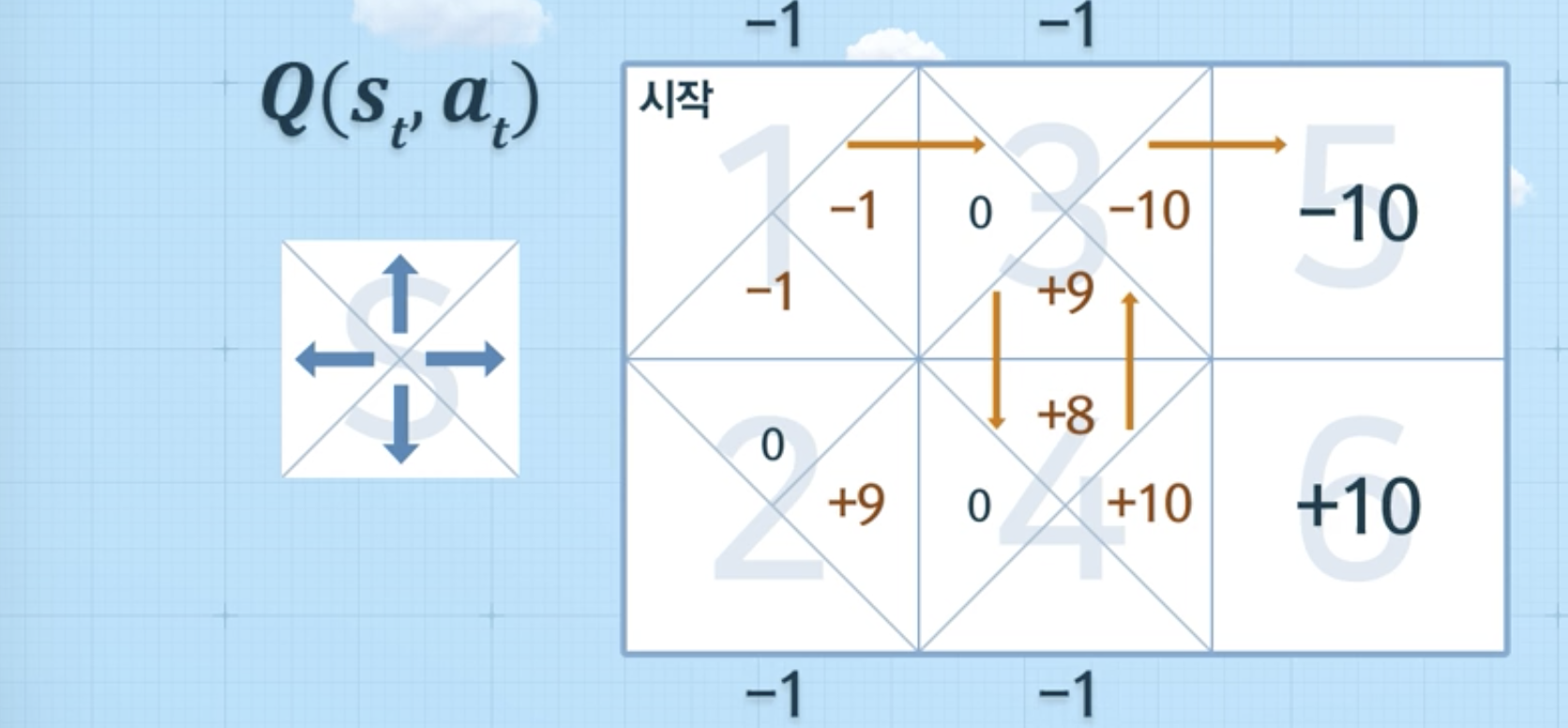
- 1 > 3 > 5를 하는 경우
-
위와 같은 방식으로 계속 반복을 하게 되었을 때, 아래와 같은 그림이 나왔다면, 의사결정을 할 수 있음 (에피소드를 통해 학습)

Data Scientist, Data Analyst