인프런 권철민님 강의 정리
Section9: 추천(Recommendation)
추천 시스템의 중요성
- 아마존과 같은 전자상거래 업체부터 넷플릭스, 유튜브 등 콘텐츠 포털까지 활용하고 있음
- 사용자의 취향을 이해하고 맞춤 상품과 콘텐츠를 제공해 조금이라도 오래동안 자기 사이트에 고객을 머무르게 하기 위해 전력을 기울이고 있음
- 정교한 추천시스템은 사용자에게 높은 신뢰도를 주고 사용자가 의존하게 만듦
추천 시스템 방식
- 콘텐츠 기반 필터링 (Content Based Filtering)
- 협업 필터링 (Collaborative Filtering)
- 하이브리드 (콘텐츠 기반 + 협업 필터링)
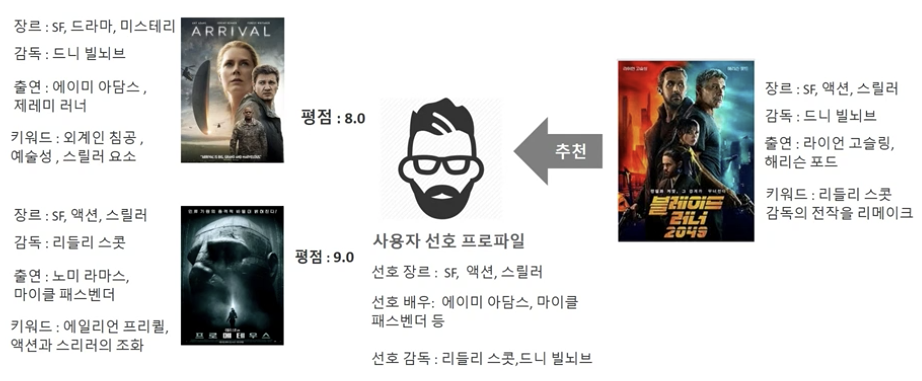
컨텐츠 기반 필터링
-
사용자가 특정한 아이템을 매우 선호하는 경우, 그 아이템과 비슷한 콘텐츠를 가진 다른 아이템을 추천하는 방식
-
일반적인 프로세스

-
컨텐츠 기반 필터링 구현 프로세스
- 컨텐츠에 대한 여러 텍스트 정보들을 피처 벡터화
- 코사인 유사도로 컨텐츠별 유사도 계산
- 컨텐츠 별로 가중 평점을 계산
- 유사도가 높은 컨텐츠 중에 평점이 좋은 컨텐츠 순으로 추천
협업 필터링
유형
- 최근접 이웃 기반 (Nearest Neighbor)
- 사용자 기반 (User-user CF)
- 아이템 기반 (Item-item CF)
- 잠재 요인 기반 (Latent Factor)
- 행렬 분해 기반 (Matrix Factorization)
특징
- User behavior에만 기반하여 추천 알고리즘들을 전반적으로 지칭함
- 상품, 영화 등 사용자가 아직 평가하지 않은 아이템에 대한 평가를 예측하는 것이 주요 역할
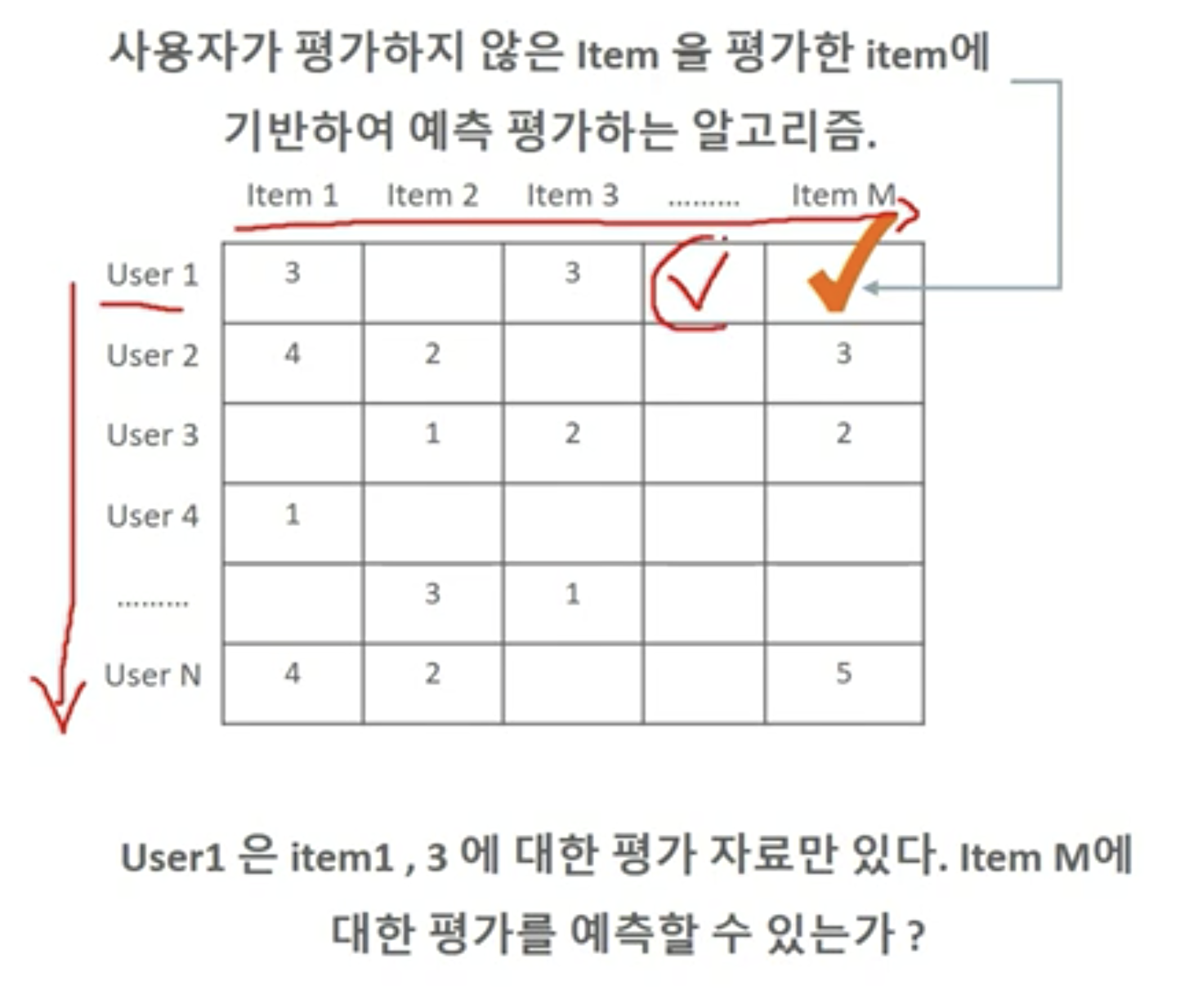
데이터 세트
사용자 기반, 아이템 기반 협업 필터링
-
사용자 기반
- 특정 사용자와 비슷한 고객들을 기반으로 선호하는 다른 상품을 추천
- 특정 사용자와 비슷한 상품을 구매해온 고객들은 비슷한 고객으로 간주
- 당신과 비슷한 고객들이 다음 상품도 구매했습니다.
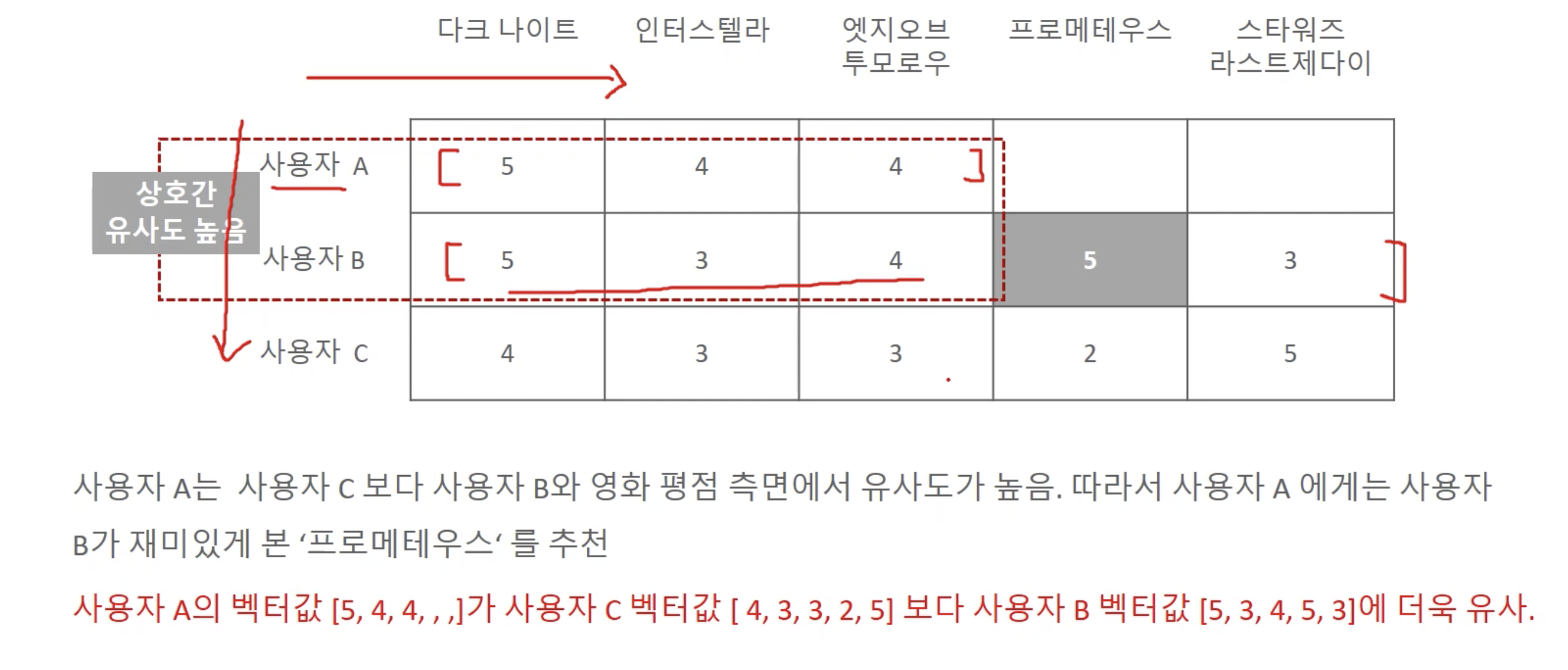
-
아이템 기반
- 특정 상품과 유사한 좋은 평가를 받은 다른 비슷한 상품을 추천
- 사용자들로부터 특정 상품과 비슷한 평가를 받은 상품들은 비슷한 상품으로 간주
- 이 상품을 선택한 다른 고객들은 다음 상품도 구매했습니다.
-
일반적으로 아이템 기반 방식이 더 선호됨
- 사람간의 특성은 상대적으로 다양한 요소들에 기반하고
- 단순히 동일한 상품을 구입했다고 유사한 사람이라고 판단하기 어렵기 때문
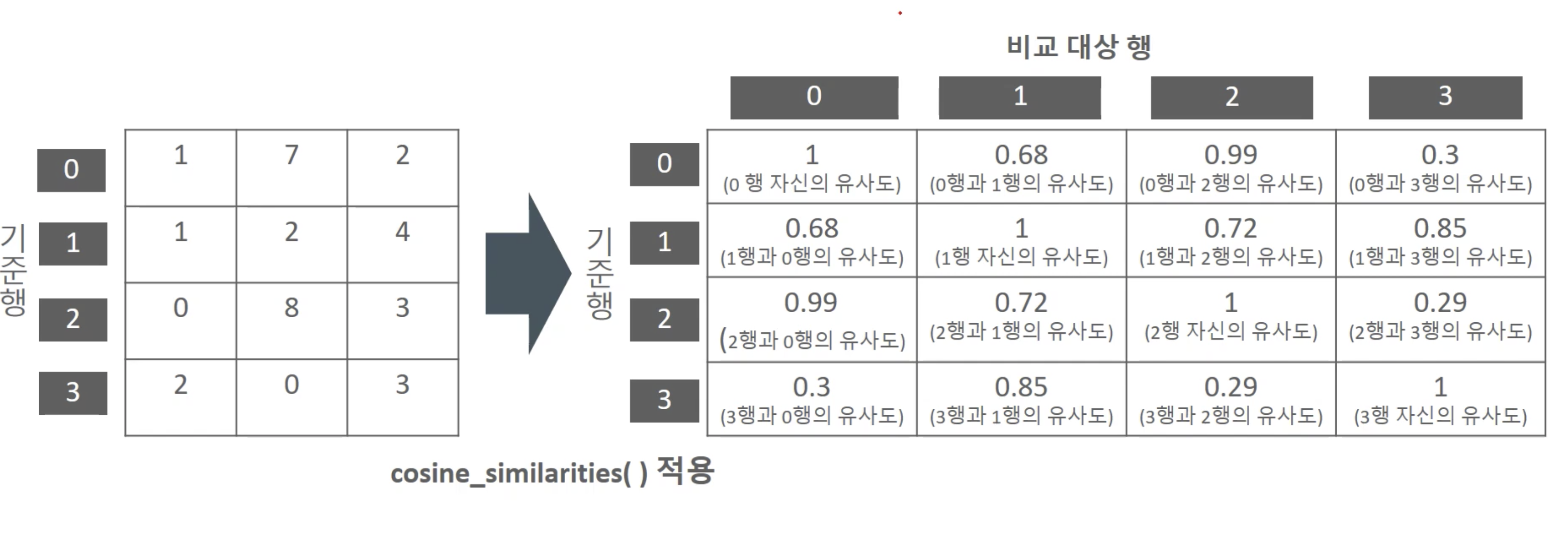
코사인 유사도
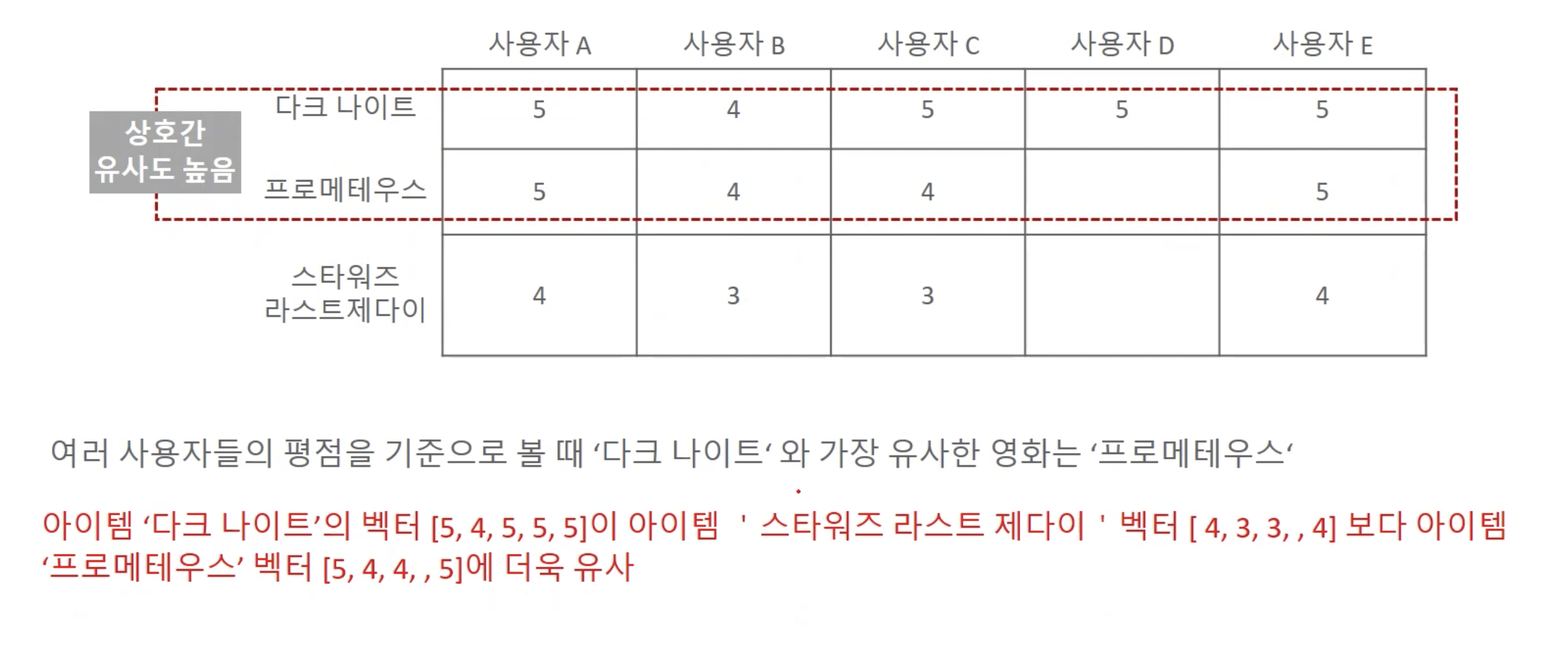
아이템 기반 협업필터링의 개인화된 영화 추천
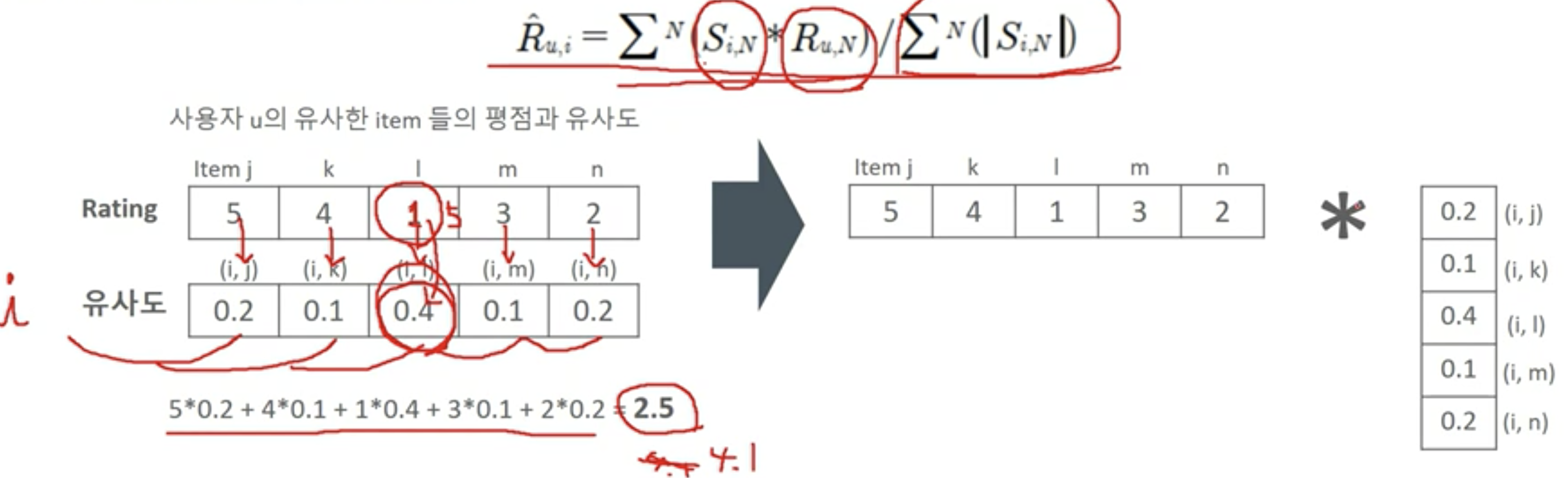
- 사용자 u의 아이템 i에 대한 평점 예측을 사용자 u가 아이엠 i와 유사한 다른 아이템들의 합으로 계산하되, 아이템 i와 다른 아이템드간의 유사도를 반영한 합으로 계산

아이템 기반 협업필터링 구현순서
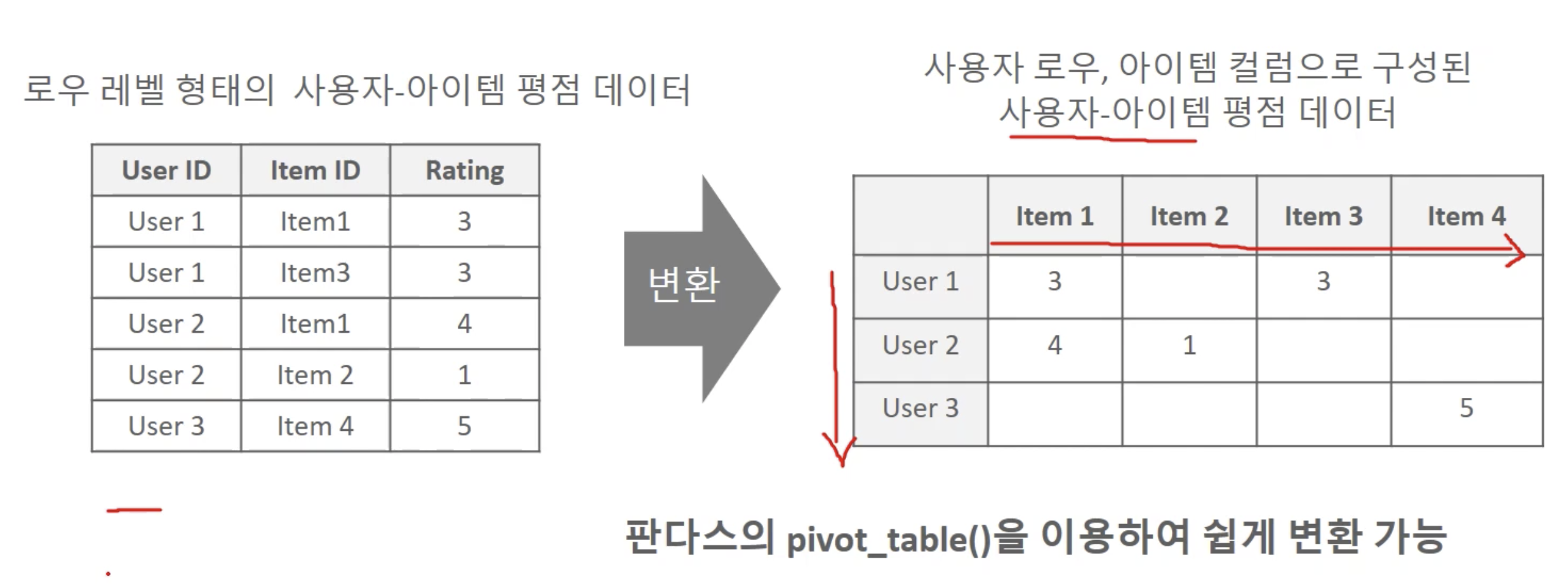
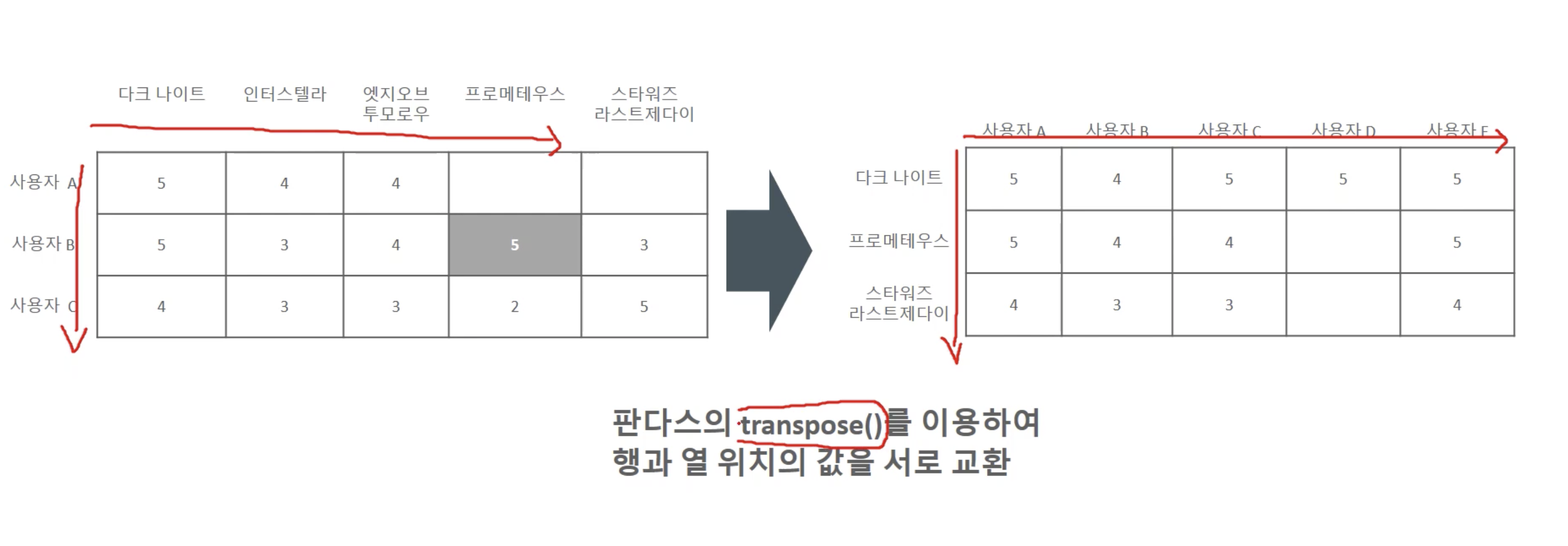
- 사용자-아이템 행렬 데이터를 아이템-사용자 행렬 데이터로 변환
- 아이템 간의 코사인 유사도로 아이템 유사도 산출
- 사용자가 관람하지 않은 아이템들 중에서 아이템간 유사도를 반영한 예측 점수 계산
- 예측 점수가 가장 높은 순으로 아이템 추천
잠재 요인 협업필터링
개요
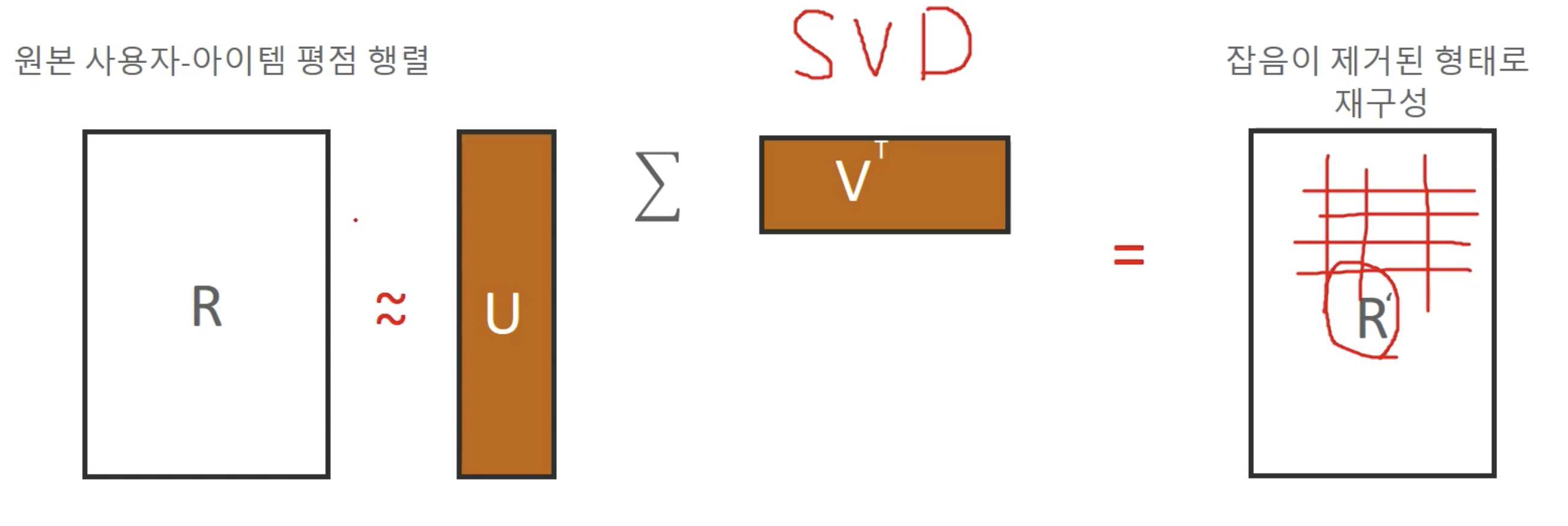
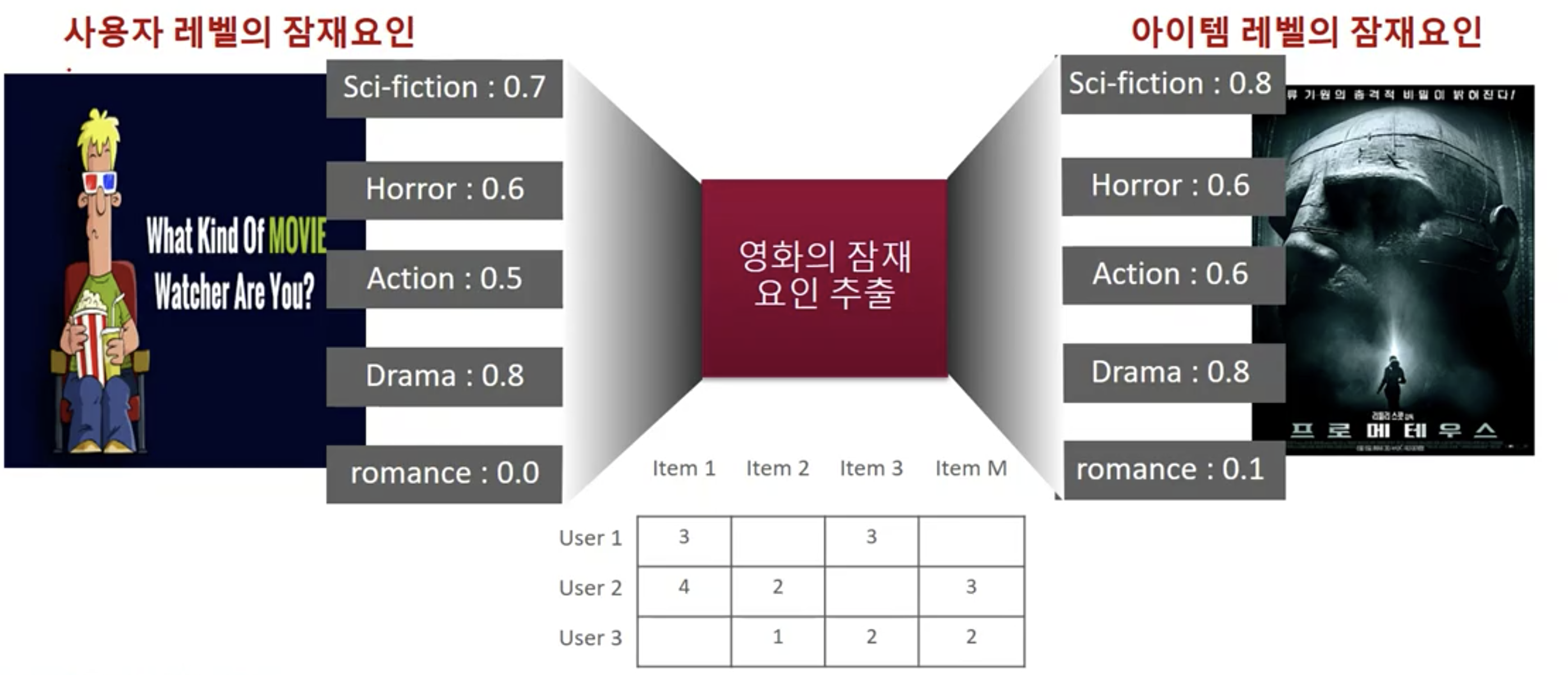
- 사용자 아이템 평점 행렬 속에 숨어 있는 잠재요인을 추출해 추천 예측을 할 수 있게 하는 기법
- 대규모 다차원 행렬을 SVD와 같은 행렬 분해 기법으로 분해하는 과정에서 잠재 요인을 추출
- 잠재 요인을 기반으로 사용자 아이템 평점 행렬을 재구성하면서 추천을 구현
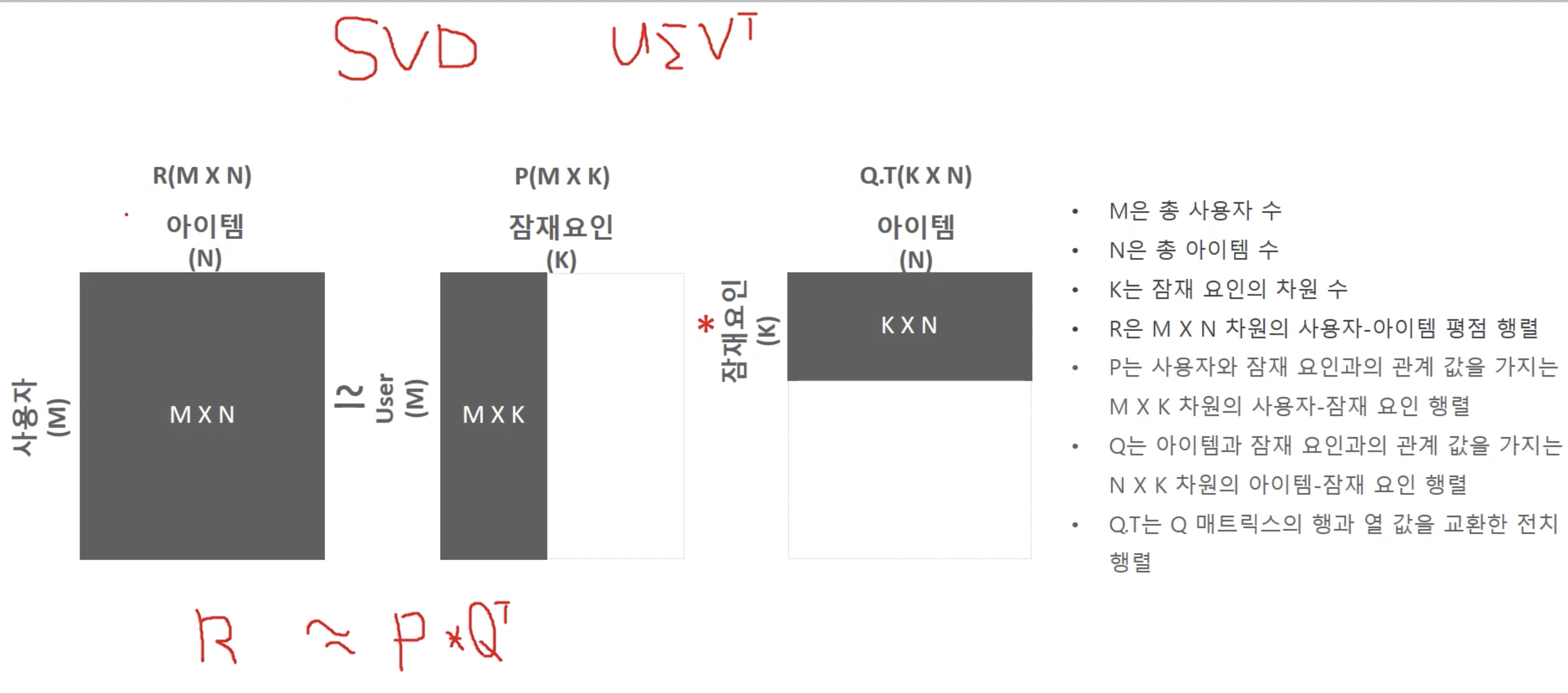
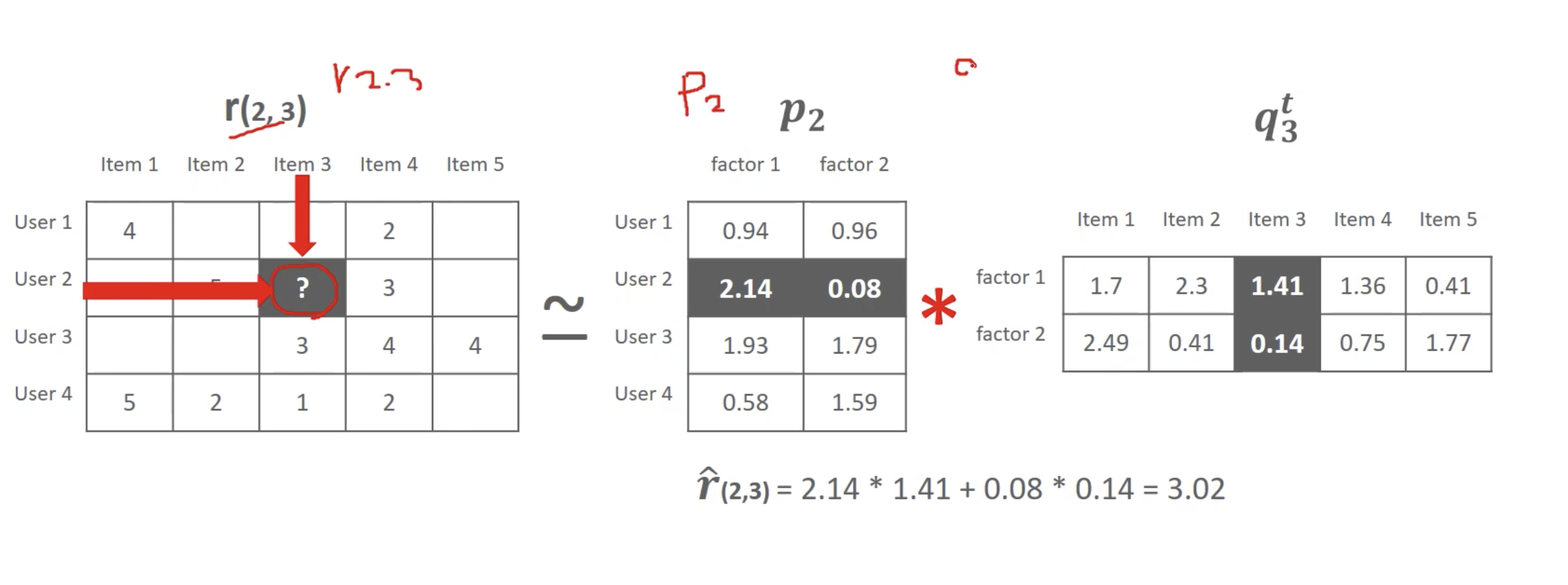
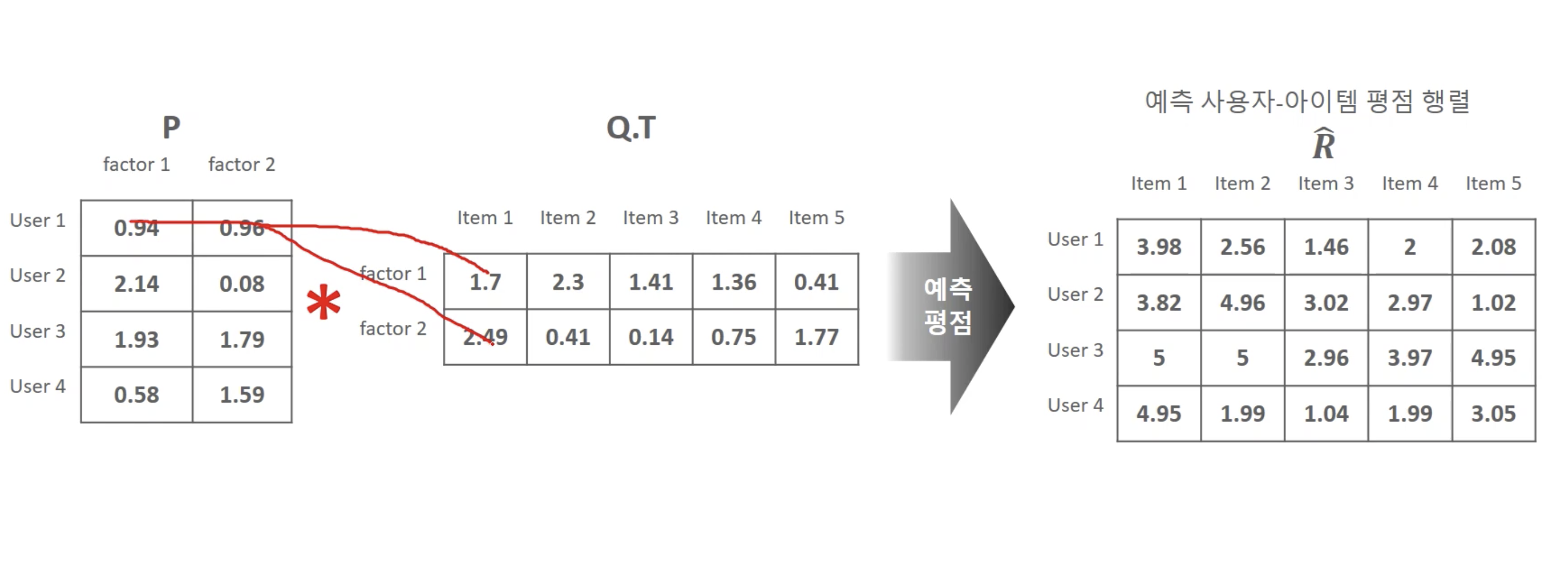
행렬 분해
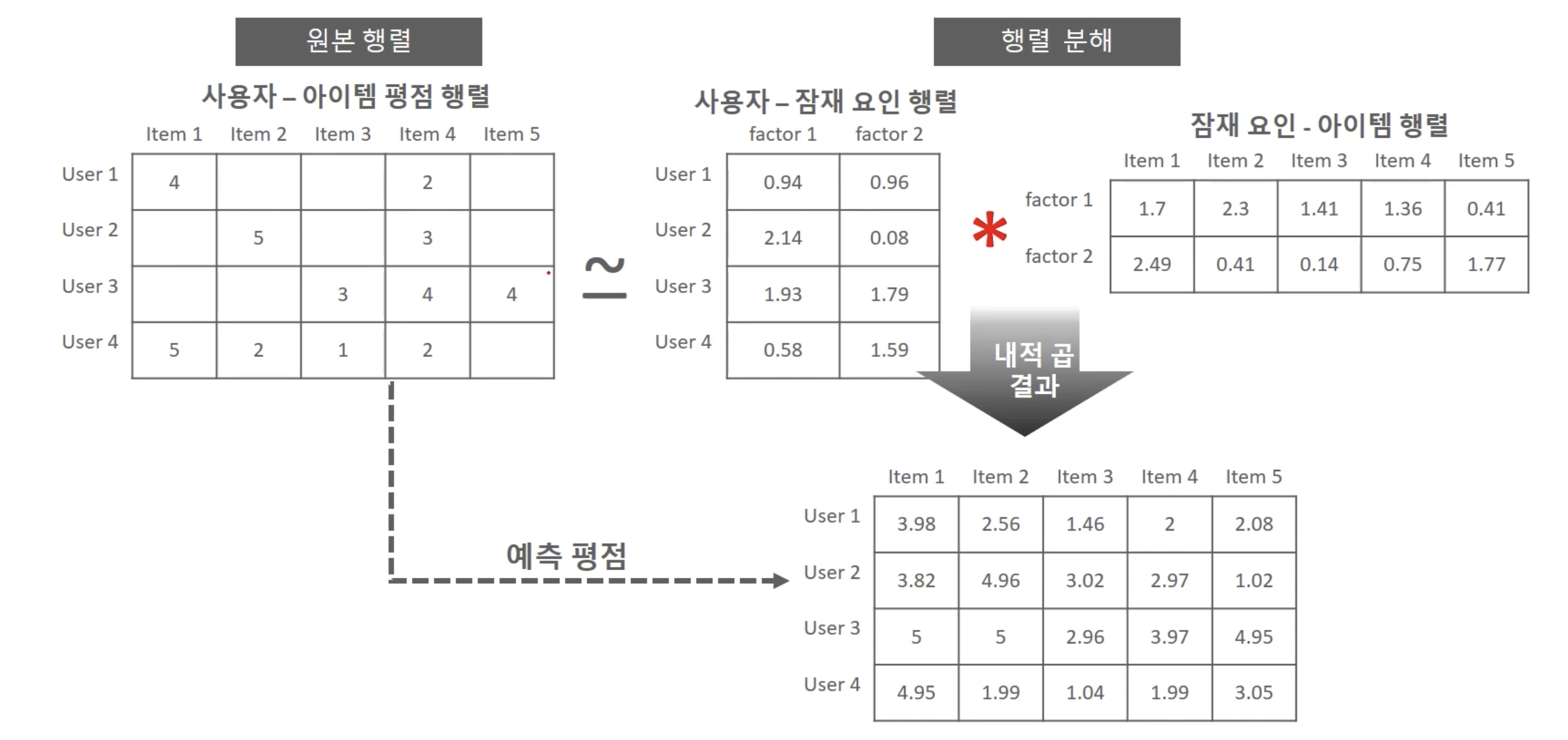
- 잠재 요인 협업 필터링의 행렬 분해 목표: 희소 행렬 형태의 사용자 아이템 평점행렬을 밀집 행렬 형태의 사용자 잠재요인 행렬과 잠재 요인 아이템 행렬로 분해한 뒤, 이를 재결합하여 밀집 행렬 형태의 사용자 아이템 평점 행렬을 생성하여 사용자에게 새로운 아이템을 추천하는 것

예시

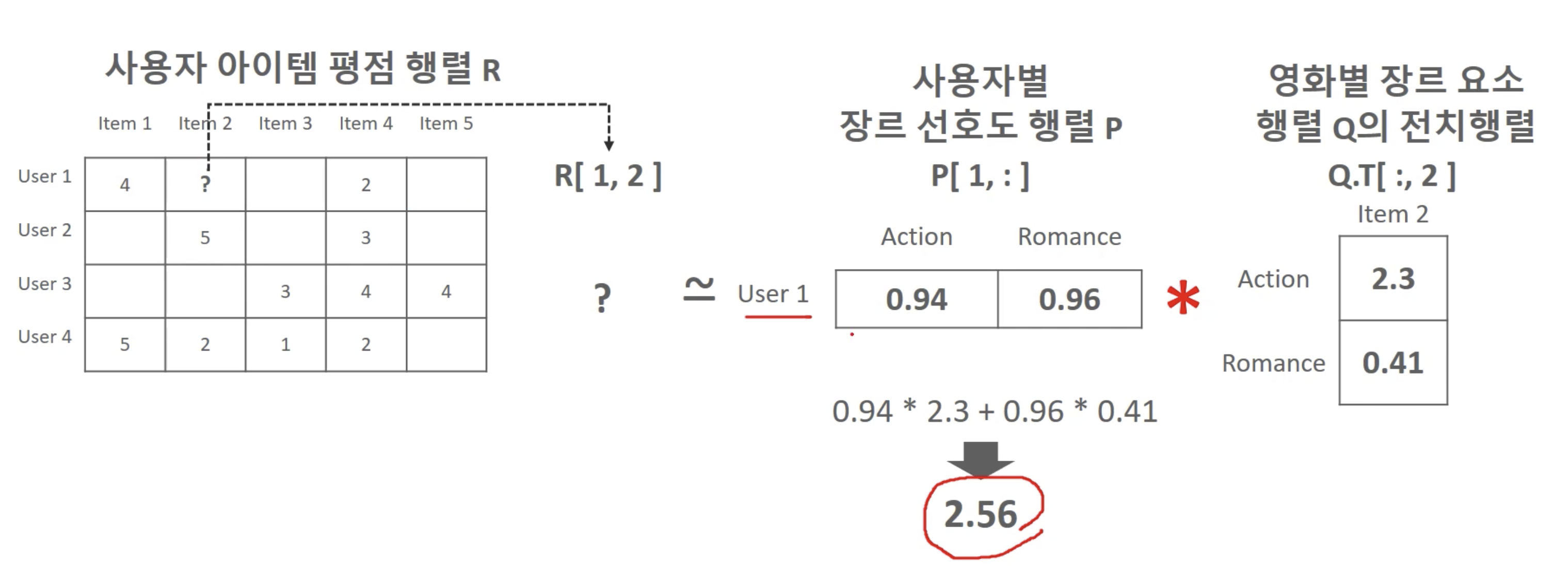
수식 이해
행렬 분해 이슈
- SVD는 Missing value가 없는 행렬에 적용 가능
- P와 Q 행렬을 일반적인 SVD 방식으로는 분해할 수 없음

경사하강법 기반의 행렬 분해
- P와 Q 행렬로 계산된 예측 R행렬 값이 실제 R행렬 값과 가장 최소의 오류를 가질 수 있도록 반복적인 비용 함수 최적화를 통해 P와 Q를 유추

비용함수 수식

업데이트 수식

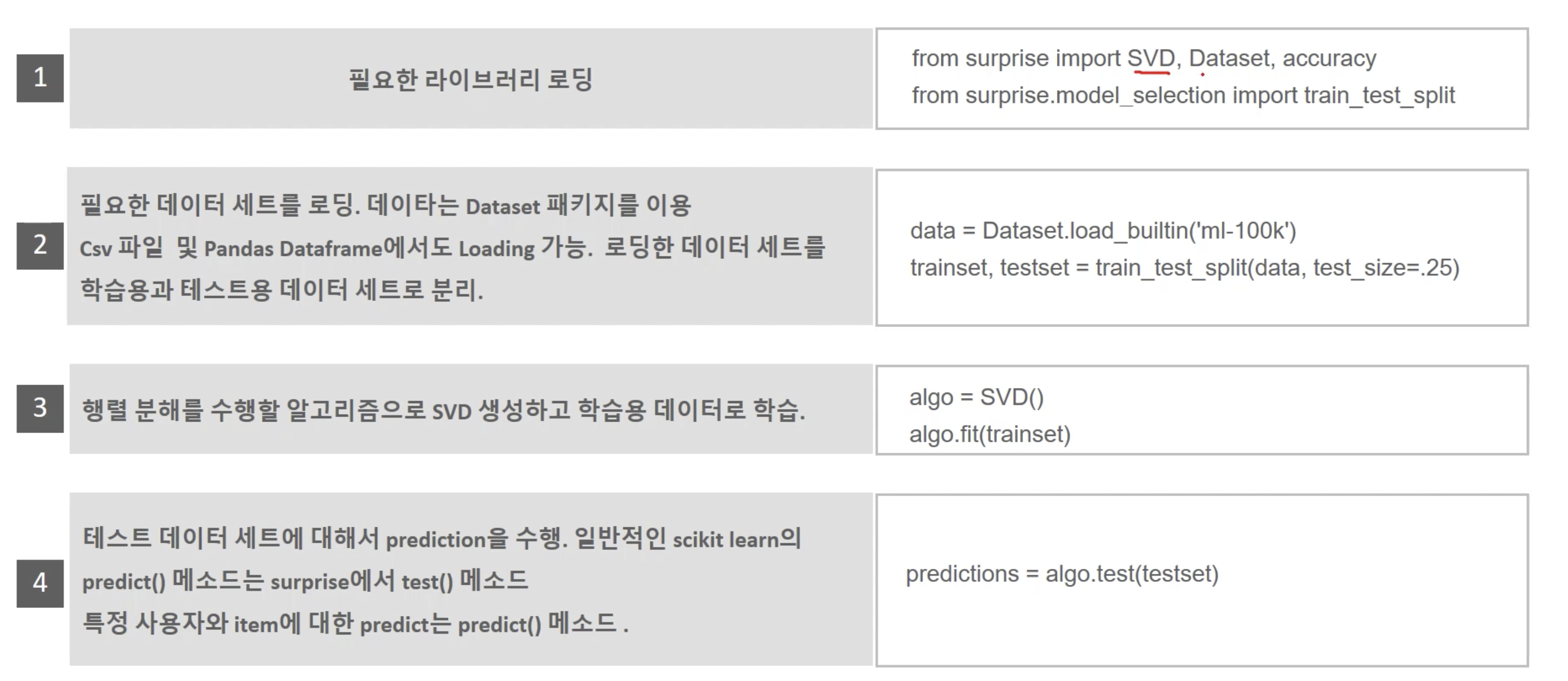
Suprise 패키지
- Python에서 recommendation을 쉽게 제공하는 대표적인 패키지
- Visual studio build tools가 미리 설치되어 있어야됨
추천 수행 프로세스
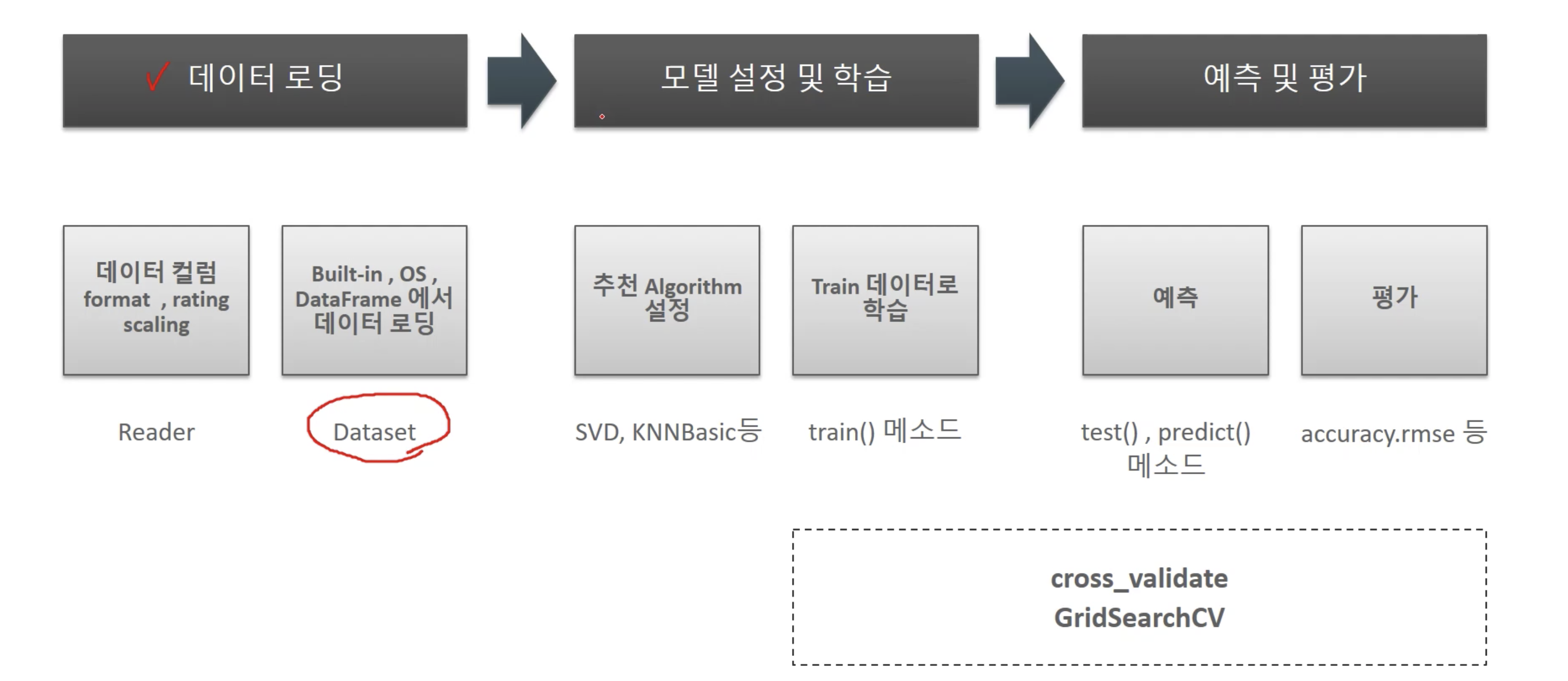
구현
Reader
- raw 데이터 소스에서 dataset로 로딩 규칙을 지정하기 위해 사용됨

추천 알고리즘 클래스

사용자 성향을 반영한 Baseline rating

Baseline rating을 반영한 행렬 분해의 비용 최소화 함수
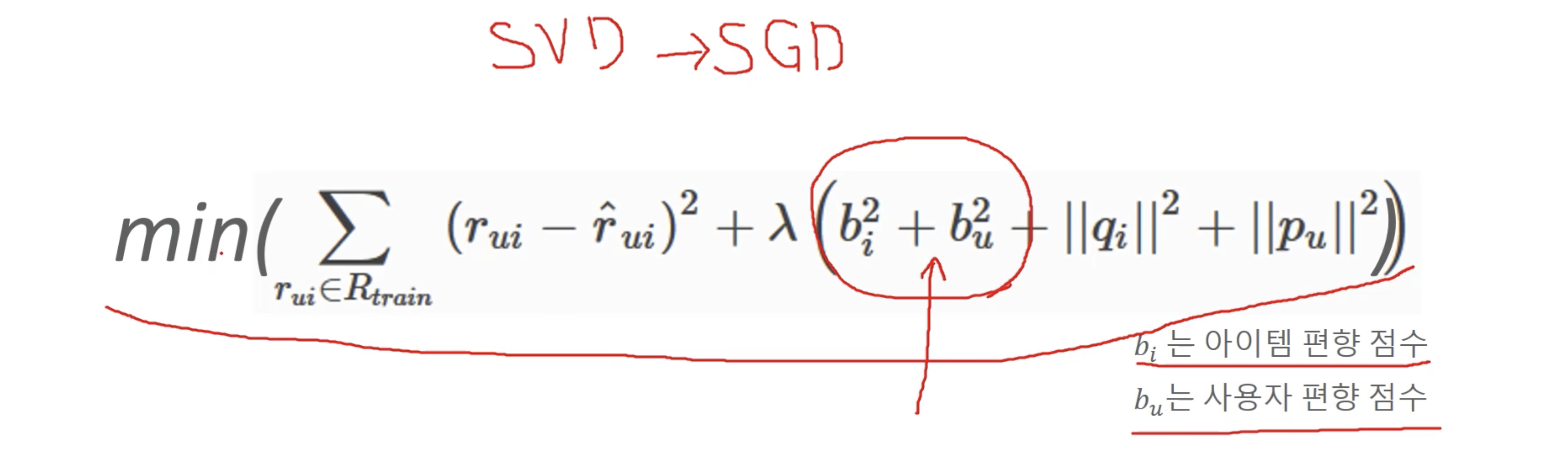
SVD 튜닝 파라미터

교차 검증, 하이터 파라미터 튜닝
- scikit learn과 동일하게 Gridsearch, cross_validate 함수를 제공함

Data Scientist, Data Analyst