
R의 caret을 이용하여 의사결정 트리 만들기 .
사용데이터 iris
데이터 분류
#아이리스 모델 분류
library(C50)
#데이터를 로드합니다.
iris <- read.csv('iris2.csv',stringsAsFactors = TRUE)
#데이터를 훈련(80%), 테스트(20%)로 나눕니다.
library(caret)
set.seed(1)
train_num <- createDataPartition(iris$Species, p = 0.8,list = F)
nrow(train_num) #120
train_data <- iris[train_num, ]
test_data <- iris[-train_num, ]
nrow(train_data) #120
nrow(test_data) #30
데이터 확인
-> 120행의 훈련데이터와 30행의 테스트 데이터 확인
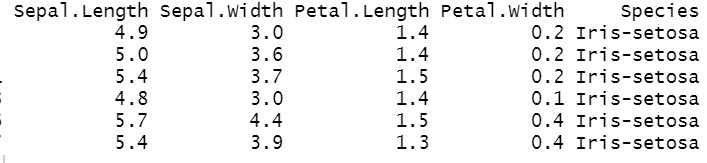
head(test_data)
head(train_data)
의사결정 모델 만들기
#훈련 데이터로 분류 모델을 만듭니다.
library(C50)
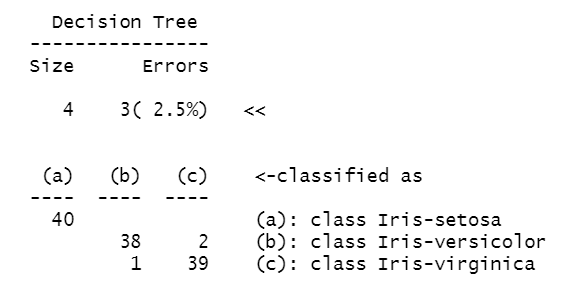
model <- C5.0(train_data[,-5],train_data[,5]) #3개 틀림
model
summary(model)
의사결정 트리 그래프
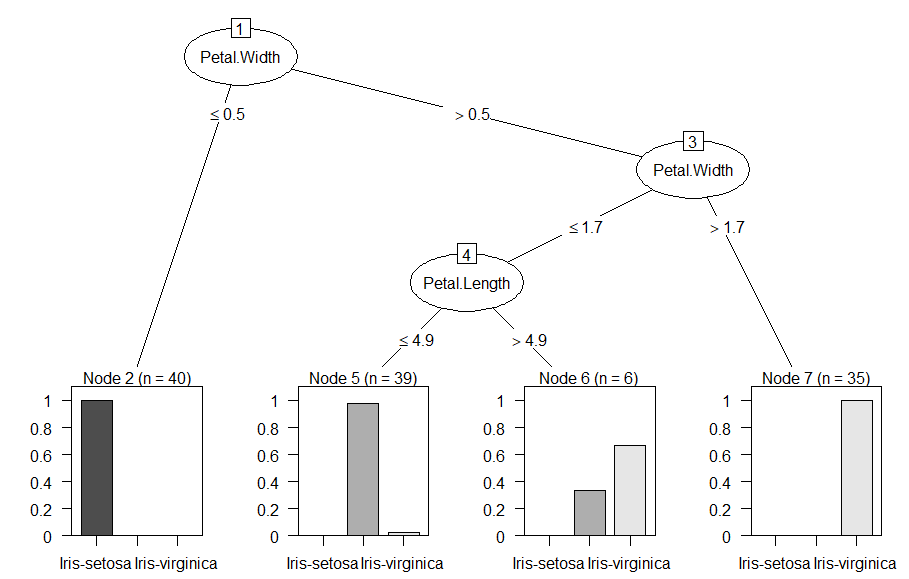
의사결정 트리를 기반으로 데이터 예측
#5. 훈련 한 모델로 테스트 데이터 10개를 예측합니다.
result <- predict(model, test_data[,-5])
sum(result == test_data[,5])/30 #2개 오류
정확도 높이기
1. trial 사용하기
약한 학습자 여러개를 실행한 후 다수결에 의해서 훈련데이터를 분류한다.
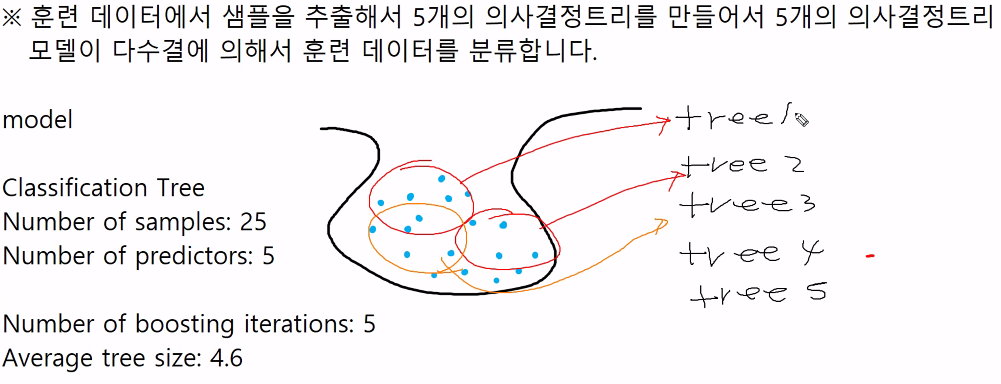
#1. trail 사용하기 10번
model2 <- C5.0(train_data[,-5],train_data[,5],trials = 10)
summary(model2) #훈련데이터 다 맞음 정확도 100
result2 <- predict(model2, test_data[,-5]) #예측하기
sum(result == test_data[,5])/30 #여전히 2개 오류, 93%trial을 사용했을때 훈련데이터는 정확도가 100%로 증가했지만 예측을 했을 때는 실패하였다.
이런 현상을 과대접합이라고 한다. (overfitting)
데이터를 과대 접합하면 해당 데이터에서는 높은 정확도가 나오지만 다른 데이터를 예측하거나 모델을 적용했을때 정확도가 떨어진다.
이럴 때는 pruning과정을 통해 가지치기를 해야한다.
2. pruning (가지치기)
###과대접합 한 데이터를 Pruning과정을 통해 가지치기를 해 준다.
install.packages('tree')
library(tree)
#훈련데이터의 의사결정 그래프를 그린다.
treemod<-tree(train_data[,5]~. , data=train_data[,-5])
#plot(treemod)
#text(treemod)
#의사결정 나무에서 각 가지에 대한 분산을 구한다.
cv.trees<-cv.tree(treemod, FUN=prune.misclass )
plot(cv.trees)
#3 이후로 값이 줄어드는 것을 확인 -> best = 4로 설정
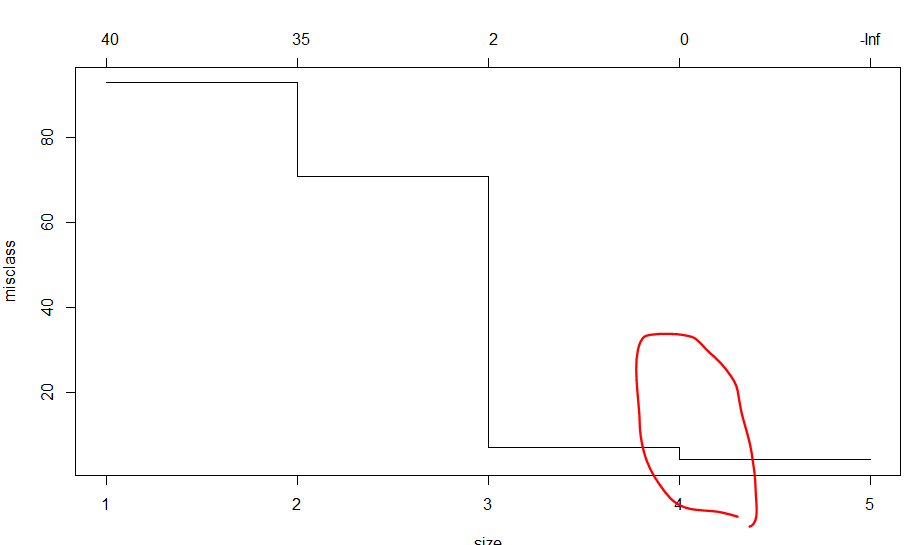
#의사결정 트리 만들기
prune.trees <- prune.misclass(treemod, best=4)
#새로운 의사결정 트리 그래프 확인
plot(prune.trees)
text(prune.trees, pretty=0)
#새로운 데이터를 사용해서 예측한 후 정확도 확인
install.packages("e1071")
library(e1071)
treepred <- predict(prune.trees, test_data[,-5], type='class')
## treepred 결과 -> 예측 값들이 나열 (30개)
#정확도 확인
confusionMatrix(treepred, test_data[,5])confusionMatrix(treepred, test_data[,5])
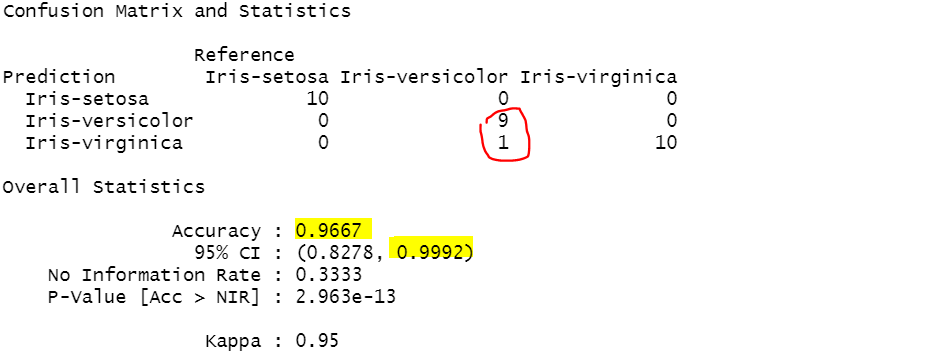
결과 -> 1개 오류, 96%의 정확성으로 늘어남.
