nGrinder
nGrinder는 네이버에서 만든 성능 테스트 툴입니다. 사용방법도 간단하고 무엇보다 테스트결과를 직관적인 Report형태로 보여주며 저장까지 자동으로 해주기 때문에 선택하였습니다.
설치 및 사용방법은 다음 포스팅에서 작성하겠습니다. (작성완료)
서버 구성은 [Compact] 1vCPU, 2GB Mem, 50GB Disk [g1] WAS 1대와 동일한 스팩의 MySQL, ElasticSearch, Redis 서버로 이루어져있습니다.
1. Space 검색 - 쿼리 vs ElasticSearch
제가 만든 서비스에서 가장 많이 사용될 공간검색api를 테스트해보겠습니다.
검색어로 원하는 공간을 검색하는 api이며, 오직 DB에 쿼리를 날려 조회하는 api와 ElasticSearch에 쿼리를 날린 후 해당결과를 기반으로 DB에 쿼리를 날려 검색하는 api로 나누어 구현하였습니다.
즉, ElasticSearch를 이용하여 검색의 범위를 좁히고 거기서 나머지 조건을 필터링한다고 보면됩니다. 이렇게 구현한 이유는 ElasticSearch는 Join이 불가능하기때문에 연관된 엔티티의 조건은 DB에 쿼리를 날려해결하였습니다.
- ElasticSearch로 검색어에 해당하는 SpaceId List얻어오기
- 해당 Space가 필터링 조건(사용인원, 예약예정일자, 예약예정시간)에 해당하는 지 DB에 쿼리를 날려 확인 후 반환
검색 쿼리 테스트
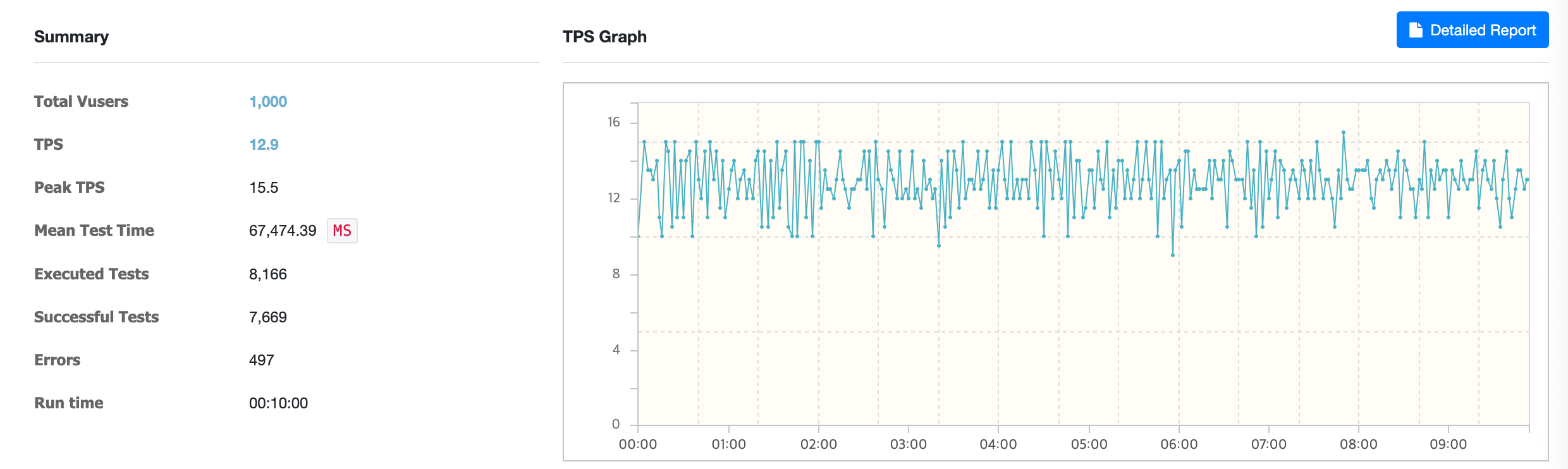
해당 테스트는 가상 사용자 1000명을 기준으로 10분간 진행하였습니다. 초당 처리할 수 있는 트랜잭션 수인 TPS는 12.9가 나왔고 테스트 1회 평균 시간인 MTT는 무려 67,474ms가 나왔습니다. 테스트 성공률 또한 93.9%로 만약 사용자가 존재한다면 간헐적으로 불편함을 느낄정도였습니다.
에러로그를 보니, DB Connection을 제대로 얻어오지 못한것으로 보였습니다.
java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30000ms.쿼리로 검색을 구현하면 Space 대부분의 필드에 like를 걸어야하기 때문에 느릴 것이란걸 예상하긴 했지만 정말 느렸습니다.
ElasticSearch + 쿼리 테스트
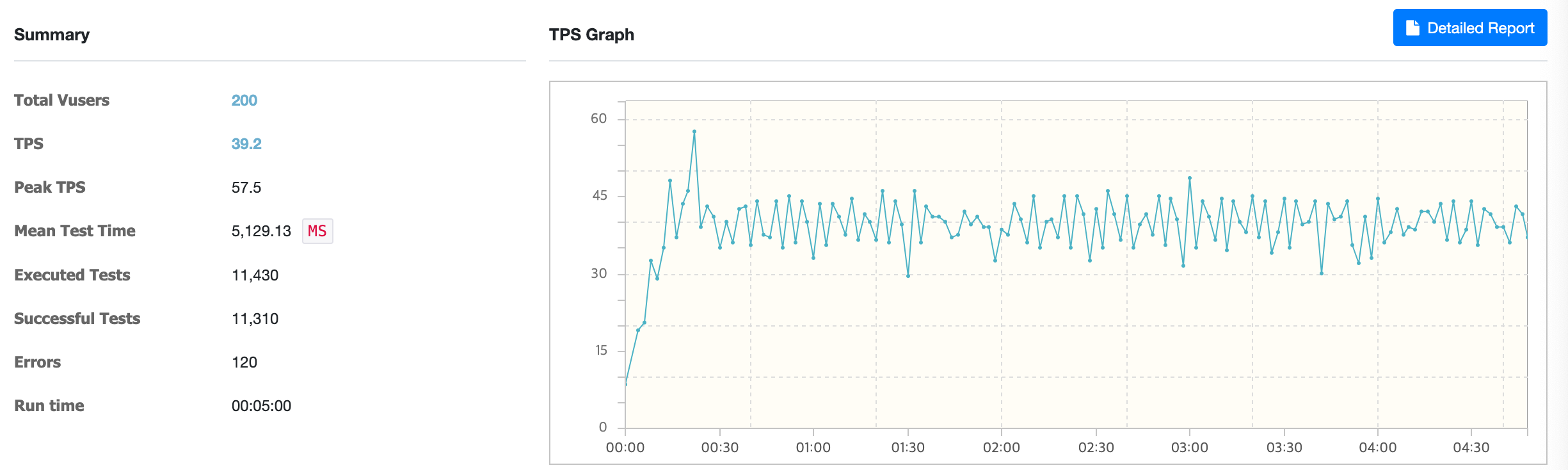
처음엔 가상 사용자 200명을 기준으로 5분간 진행하였고 ElasticSearch와 통신하려다 TimeOutException이 간헐적으로 발생하였습니다. 하지만 처리량이 쿼리만 사용하는 api비해 약 3배가량 높았기 때문에 이 부분을 개선하기로 결정하였고 Timeout시간과 Connection Pool을 늘렸습니다. (ElasticSearch TimeOutException 해결과정)
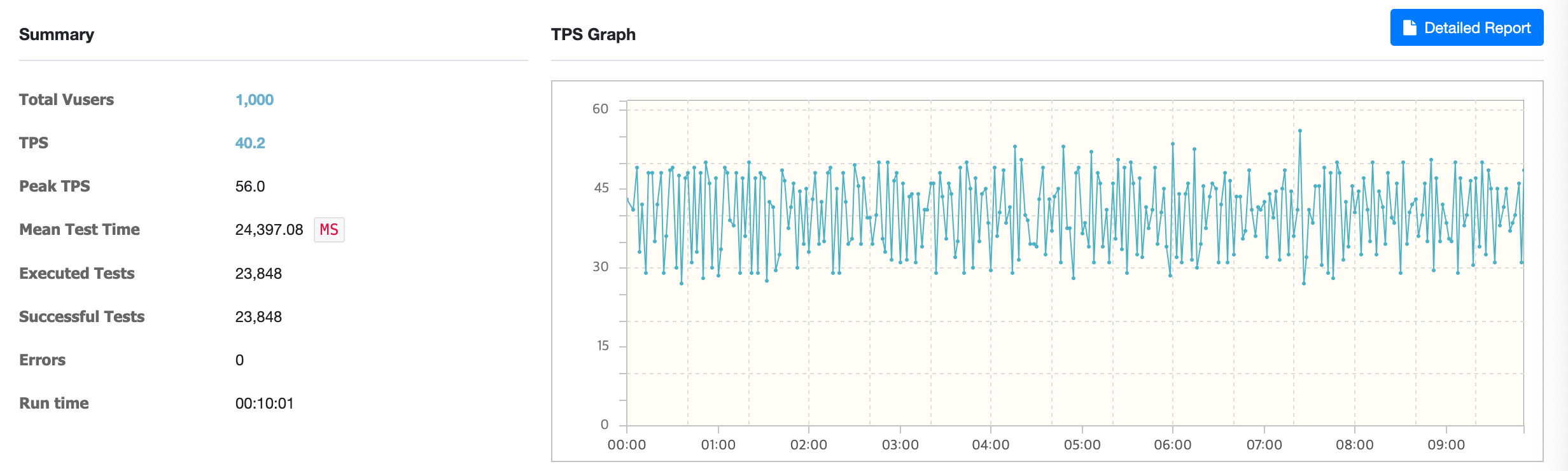
결과적으로 가상 사용자 1000명을 기준으로 10분간 진행하였을 때 TPS는 40.2, MTT는 24,397ms으로 약 3배정도의 향상된 성능을 보여줬습니다. 여기서 그치지않고 Redis를 이용하여 ElasticSearch의 쿼리 결과(SpaceId List)를 캐싱하여 동일한 검색어로 요청된다면 결과를 재사용할 수 있도록하였습니다.
2. 공간검색 - 캐싱
캐싱 적용
검색어를 key값으로 아래와 같이 캐싱을 설정해주었습니다.
@Cacheable(cacheNames = "findSpaceId", key = "#queryString")
public List<Long> findIdByQuery(String queryString) {
...
}그리고 Space의 변경(Create/Update/Delete)이 일어난다면 캐싱된 결과는 최신 데이터가 아니기 때문에 재사용할 수 없으므로 삭제하도록 하였습니다.
@Transactional
@CacheEvict(value = "findSpaceId")
public Long createSpace(Long categoryId, SpaceCreateUpdateRequest createRequest,
String loginEmail) {
...
}
@Transactional
@CacheEvict(value = "findSpaceId")
public void updateSpace(Long spaceId, SpaceCreateUpdateRequest updateRequest,
String loginEmail) {
...
}
@Transactional
@CacheEvict(value = "findSpaceId")
public void deleteSpace(Long spaceId, String loginEmail) {
...
}검색요청 시 통신 과정
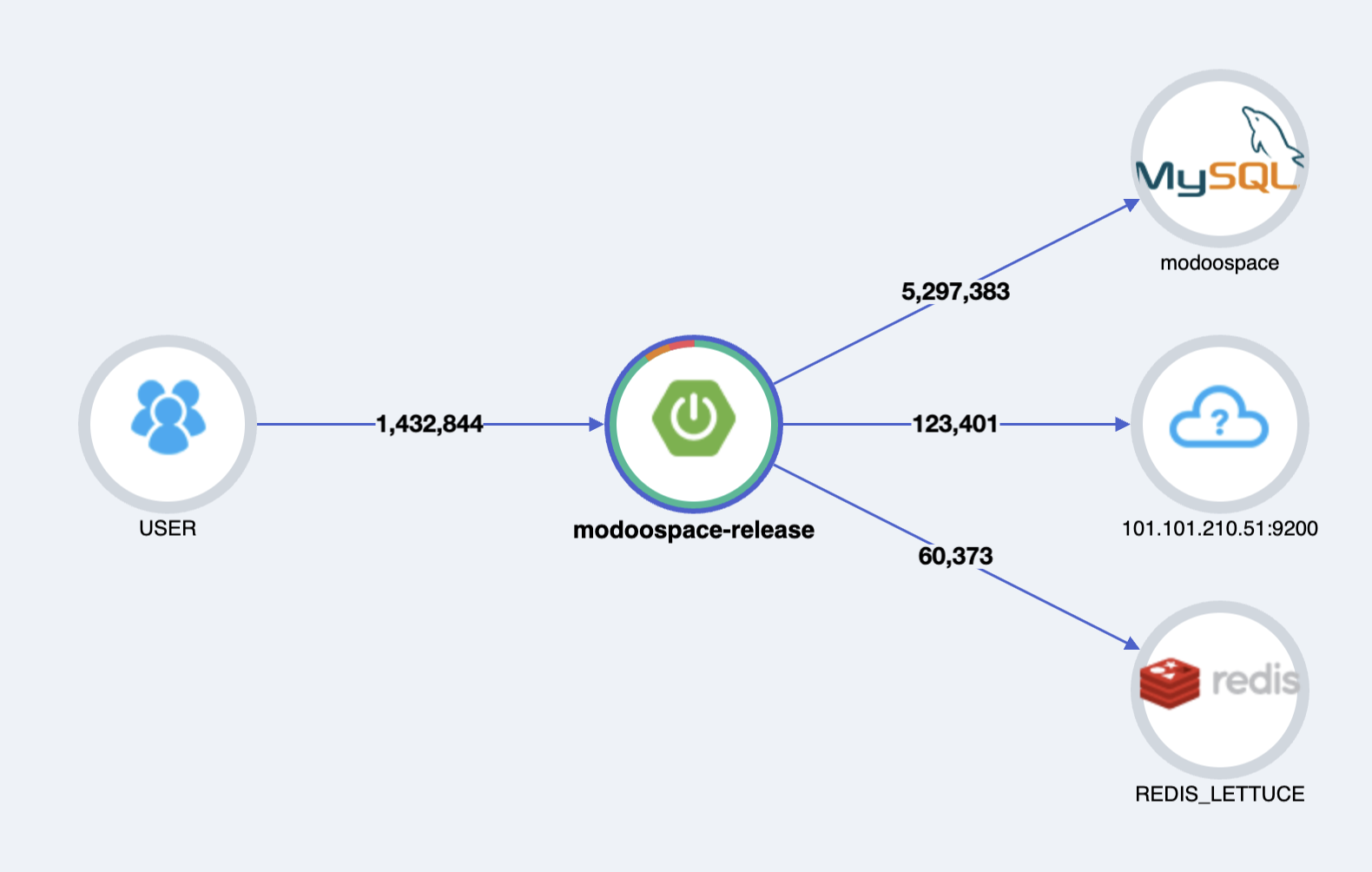
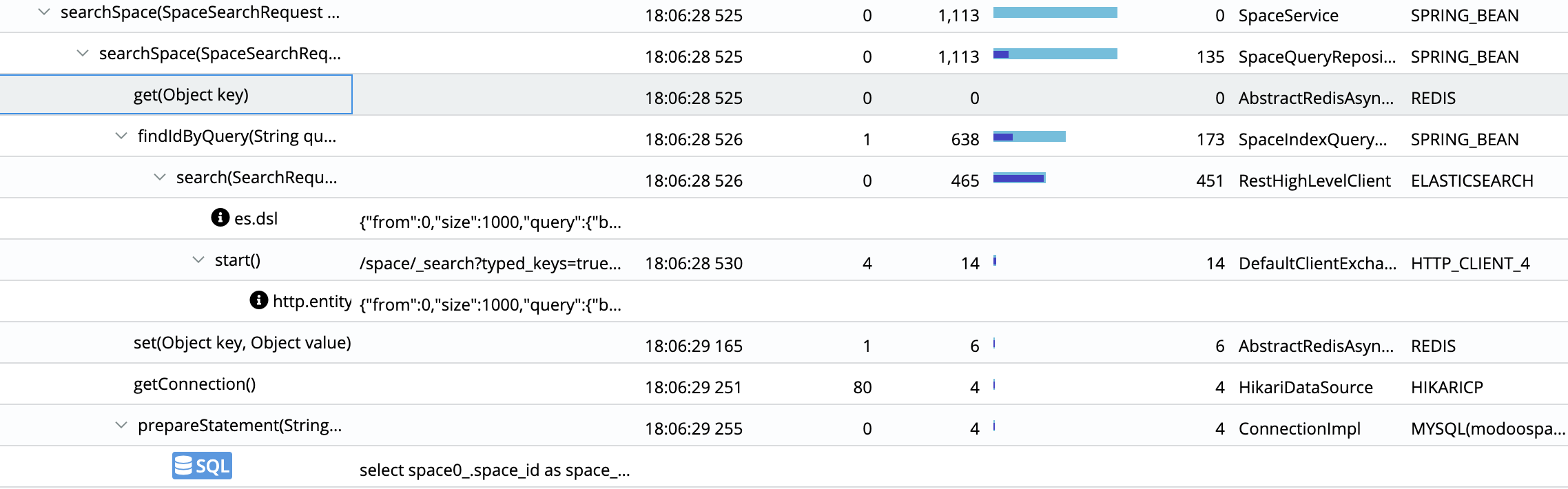
Pinpoint로 통신 과정을 보자면 아래와 같습니다.
- 검색요청이 들어오면 Redis와 통신하여 검색어(
key)로 캐싱된 결과가 있는지 확인합니다.get(key) - 결과가 없다면 ElasticSearch에 질의를 보내고 SpaceIdList를 받아옵니다.
2-1. 결과가 있다면 바로 DB에 쿼리를 날려 Space를 필터링합니다. - 검색어(
key)로 SpaceIdList(value)를 Redis에 캐싱합니다.set(key, value) - DB에 쿼리를 날려 해당 Space를 필터링합니다.
ElasticSearch + 캐싱 + 쿼리 테스트
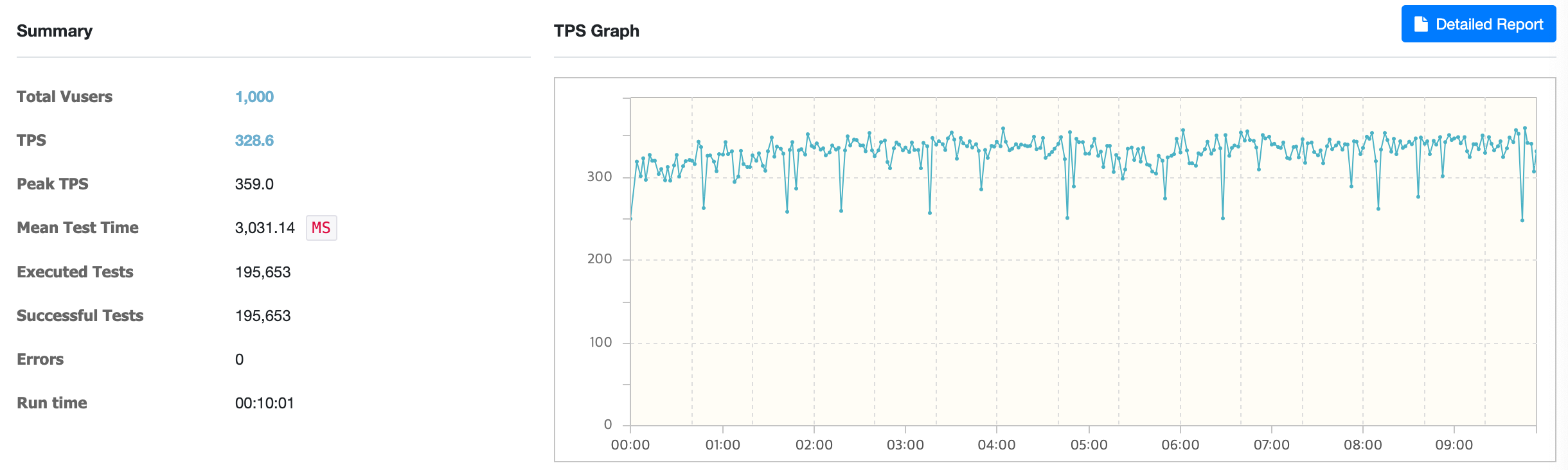
TPS는 328.2, MTT은 3,031ms으로 약 7배정도의 향상된 성능을 보여줍니다. 물론 새로운 Space가 저장된다거나 수정/삭제가 일어난다면 캐시 데이터는 삭제되므로 실제 운영환경에서는 더 낮은 성능을 보일 가능성이 있습니다.
하지만 비지니스로직상 사업자는 가게의 상호정보와 같은 Space보다는 판매물품과 같은 Facility를 수정할 일이 많기 때문에 성능은 비슷할 것으로 예상됩니다.
CPU 성능비교
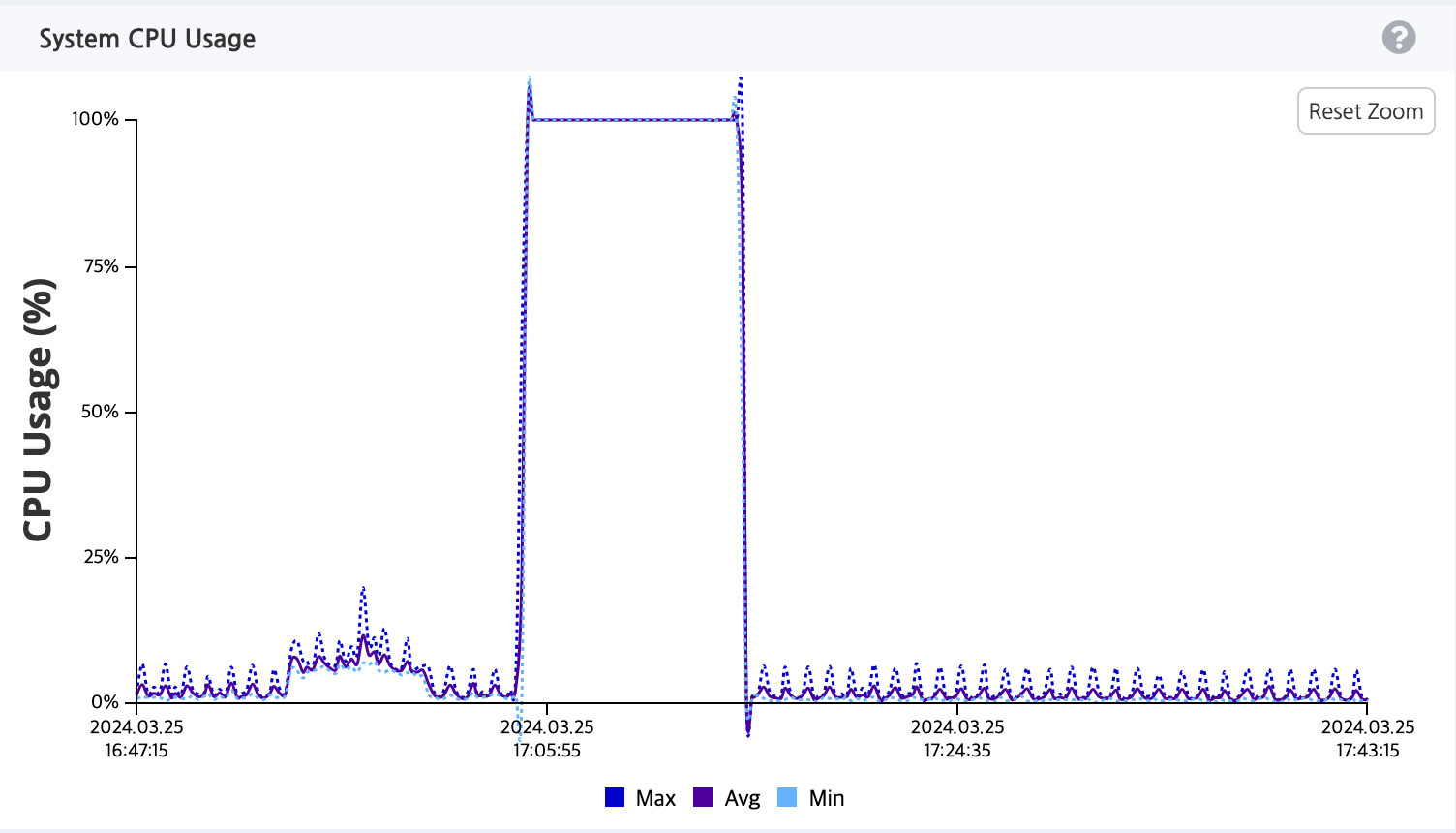
다만 처리량이 쿼리만 사용할때에 비해 약 25배가 늘었다보니, CPU 사용량도 15% ➡️ 100%까지 치솟았습니다. 이 부분은 WAS의 CPU스펙을 높이던지(Scale-Up) 또는 WAS를 여러개 두고 로드밸런싱을 통해 트래픽을 분산(Scale-Out)시켜야할 필요가 있음을 보여줍니다.
3. 시나리오 테스트
사용자가 서비스를 이용한다면 아래와 같은 행위가 이루어질것입니다.
- 공간 검색
- 공간 + 포함된 시설List 조회
- 특정 시설의 한달 스케줄 조회
- 해당일자의 예약가능시간 조회
2,3,4 api를 각각 동일한 환경에서 테스트해본 결과 평균 450~500TPS로 무리가 없다 생각하여 시나리오 테스트를 진행하였습니다.
결과
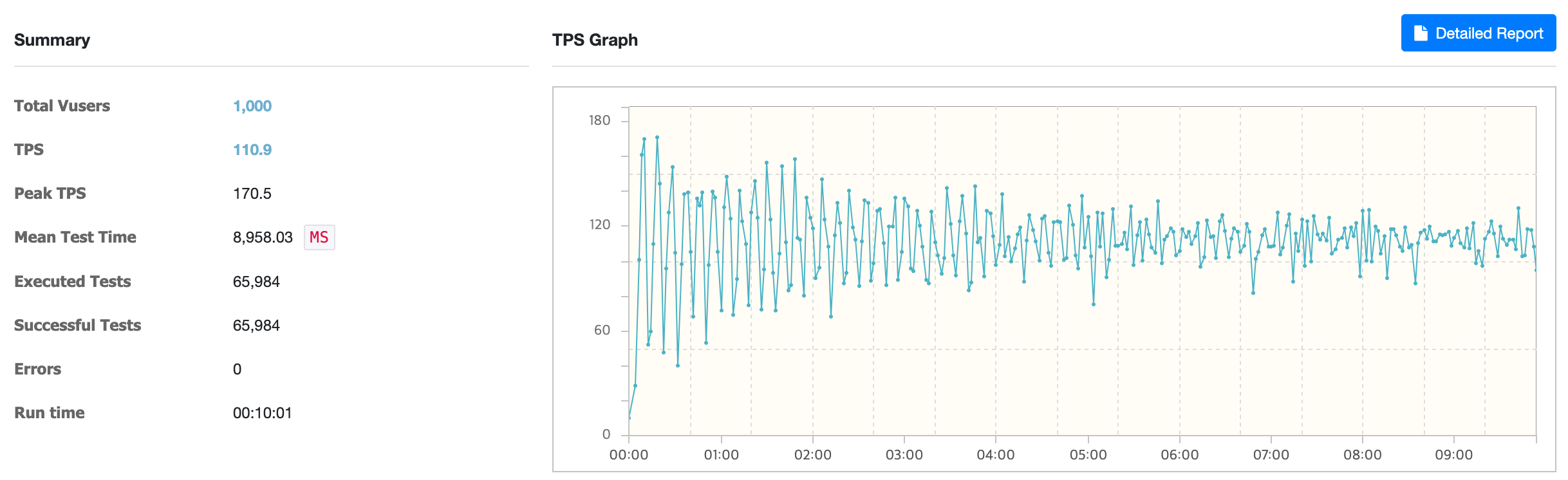
1000명의 가상 사용자로 10분간 진행해본 결과, 해당 시나리오를 처리하는데 평균 TPS 는 110.9, MTT은 8,958ms가 나왔습니다.
느낀점
처리량이 높아지면 높아질수록 CPU의 성능이 중요하다는 것을 깨달았습니다. 현재 더 많은 트래픽을 안정적으로 처리하기 위해서는 Scale-Up 또는 Scale-Out이 필요하다는 것을 몸소 느꼈으며 학습 후 도입하도록 해야겠습니다!