아 처음에 가볍게 풀어본다는 생각으로 시작해서 엣지케이스 때문에 개삽질했다;
일단 얻은 첫 번째 교훈은 문제를 꼼꼼히 읽어봐야한다는 것인데,
그림도 크고 글자도 많아서 대충 읽었다가.
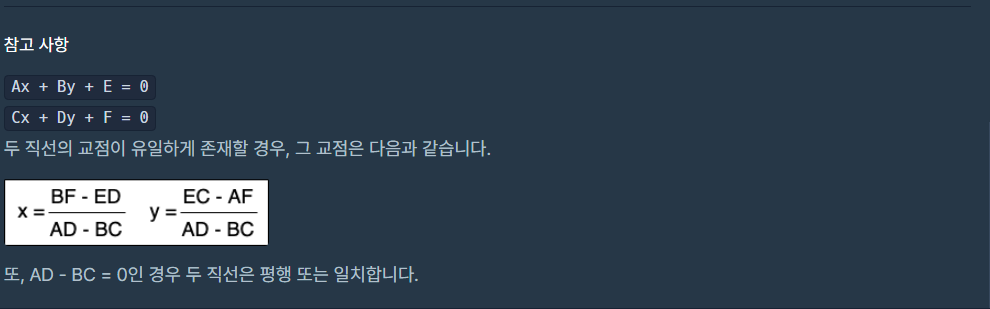
다음과 같이 참고사항이 있는 것을 못보고, 교점 구하는 방법을 되게 이상하고 힘들게 하고 있엇다;
수식을 종이에 조금만 적어봐도 금방 알 수 있는 방정식인데, 괜히 막 GCD 구하고...
흔적...
int GCD(int a, int b)
{
if(a % b == 0)
return b;
return GCD(b, a % b);
}
아무튼 저 식을 이용해서 풀다보면 평행하면 어떡하지? 라는 생각이 들 수 있는데,

다행히 친절하게 제한해준다.
그래서 그냥 간단하게 풀면 되는데, 여기서 하나 주의할 것은 A, B, C가 -100,000 이상 100,000 이하인 것이다.
100,000은 10의 5승정도인데, 10은 약 2의 3승정도, 즉 100,000은 2의 16승정도로 생각하면 된다.
그러면 A*B를 하면 어떻게 되겠는가. 당연히 Integer Overflow가 발생한다. (이 부분을 제대로 알지 못해서 좀 고생함;)
이 것을 주의해서 자료형을 int가 아니라 long long으로 형변환해서 사용해주면 된다...
파라미터로 주어지는 값도 int이기 때문에 그냥 모든 자료형을 long long으로 사용해주게 좋다.
#include <string>
#include <vector>
#include <algorithm>
#include <climits>
using namespace std;
class Pos
{
private:
long long x;
long long y;
public:
Pos(long long a, long long b):
x(a), y(b)
{}
virtual ~Pos() {}
long long getX() const {
return x;
}
long long getY() const {
return y;
}
bool operator==(const Pos &a) {
return (this->x == a.x) && (this->y == a.y);
}
};
vector<string> solution(vector<vector<int>> line) {
int size = line.size();
long long max_x = LLONG_MIN, max_y = LLONG_MIN;
long long min_x = LLONG_MAX, min_y = LLONG_MAX;
vector<Pos> result;
for(int i=0;i<size;i++) {
long long baseX = line[i][0];
long long baseY = line[i][1];
long long baseC = line[i][2];
for(int j=i+1; j<size;j++) {
long long targetX = line[j][0];
long long targetY = line[j][1];
long long targetC = line[j][2];
long long parent = (baseX*targetY*1LL - baseY*targetX*1LL);
long long Xchild = (baseY*targetC*1LL - baseC*targetY*1LL);
long long Ychild = (baseC*targetX*1LL - baseX*targetC*1LL);
if(parent == 0)
continue;
if((Xchild % parent) || (Ychild % parent))
continue;
long long result_x, result_y;
result_x = (long long)Xchild / parent;
result_y = (long long)Ychild / parent;
Pos entity = Pos(result_x, result_y);
if(find(result.begin(), result.end(), entity) == result.end()) {
result.push_back( {result_x, result_y} );
max_x = max(result_x, max_x);
max_y = max(result_y, max_y);
min_x = min(result_x, min_x);
min_y = min(result_y, min_y);
}
}
}
// 이 방식이 코드가 깔끔해보임
string tmp(max_x - min_x + 1, '.');
vector<string> answer(max_y - min_y + 1, tmp);
/*vector<string> answer;
for(long long i=min_y;i<=max_y;i++) {
string tmp = "";
for(long long j=min_x;j<=max_x;j++)
tmp += ".";
answer.push_back(tmp);
}*/
for(int i=0;i<result.size();i++) {
long long new_x, new_y;
new_x = abs(min_x - result[i].getX());
new_y = abs(max_y - result[i].getY());
answer[new_y][new_x] = '*';
}
return answer;
}이번엔 class를 사용해서 == 연산을 오버로딩했다.
그 이유는 result로 담는 곳에 교점이 다음과 같이 중복적으로 들어갈 수 있는데, ((0,0)만 3개가 들어간다.)
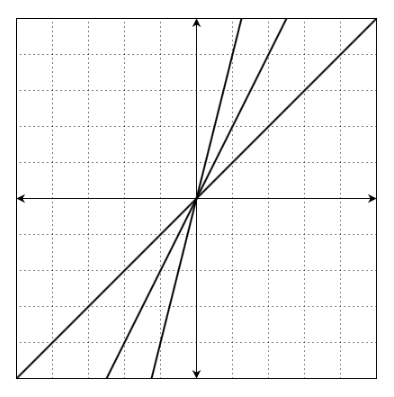
이를 방지하기 위해서 find 함수를 통해서 존재하지 않는 entity만 교점 집합에 포함시켜준다.
이를 위해 (x, y)를 멤버로 갖는 class를 선언하고 == 연산을 다음과 같이 오버로딩했다.
bool operator==(const Pos &a) {
return (this->x == a.x) && (this->y == a.y);
} 다른 코드를 보니 그냥 2차원 벡터를 쓰면 굳이 class를 선언해서 오버로딩안해도 primitive 자료형의 == operator가 알아서 특정 행 값을 비교해주는 것 같다..
그래도 명시적인 코드를 적은거에 의의를 두면 될 것 같다.
결과는 다음과 같다. 29번의 경우 integer overflow가 발생한 경우고, 이를 double로 해결하려하면 27, 28번에서 메모리초과가 발생한다고 한다.