주어진 배열에서 두 수를 뽑아서 더했을 때 나오는 숫자의 결과들을 벡터에 담아서 리턴해주면 된다.
일단 생각나는데로 먼저 작성한 코드는 다음과 같다.
배열이 총 3개읭 원소로 이루어졌다고 가정하면 다음과 같은 numbers 조합을 가지도록 하였다.
[0 1], [0 2], [1 0], [1 2], [2 0], [2 1]
그 후 Index 조합을 가지고 sum을 구한 뒤 answer 벡터에 넣어준다.
이 때 이미 그 값이 들어가져 있을 수 있기 때문에 중복을 방지하기 위한 hashMap을 관리한다.
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
int result[101];
int visit[101];
vector<int> answer;
int hashMap[10001];
void combination(const vector<int> numbers, int n, int r, int depth)
{
if(r == depth) {
int sum = 0;
for(int i=0;i<r;i++)
sum += numbers[result[i]];
if(hashMap[sum] == 0) {
hashMap[sum] = 1;
answer.push_back(sum);
}
return;
}
for(int i=0; i<n; i++) {
if(visit[i] == 0) {
visit[i] = 1;
result[depth] = i;
combination(numbers, n, r, depth + 1);
visit[i] = 0;
}
}
}
vector<int> solution(vector<int> numbers) {
int n = numbers.size();
combination(numbers, n, 2, 0);
sort(answer.begin(), answer.end());
return answer;
}다음으로는 위 코드의 단점인 중복적인 조합을 삭제한 코드이다.
[0 1], [0 2], [1 0], [1 2], [2 0], [2 1]
에서 볼 수 있듯 [0 1]과 [1 0]은 어차피 같은 합을 가지기 때문에 [1 0]을 따로 구할 필요가 없다.
버블소트의 성능을 높이기 위해서 2번째 for-loop의 시작을 i+1로 하는 것과 일맥상 같은 최적화이다.
int result[101];
int visit[101];
vector<int> answer;
int hashMap[10001];
void combination(const vector<int> numbers, int n, int r, int depth)
{
if(r == depth) {
int sum = 0;
for(int i=0;i<r;i++)
sum += numbers[result[i]];
if(hashMap[sum] == 0) {
hashMap[sum] = 1;
answer.push_back(sum);
}
return;
}
// 조합을 구해야 하는 start Index를 재설정
int start = depth == 0 ? 0 : result[depth - 1];
for(int i=start; i<n; i++) {
if(visit[i] == 0) {
visit[i] = 1;
result[depth] = i;
combination(numbers, n, r, depth + 1);
visit[i] = 0;
}
}
}
...마지막으로는 set을 사용한 코드이다.
vector<int> solution(vector<int> numbers) {
int n = numbers.size();
set<int> setMap;
for(int i=0;i<n;i++)
for(int j=i+1; j<n;j++)
setMap.insert(numbers[i] + numbers[j]);
answer.assign(setMap.begin(), setMap.end());
return answer;
}가장 간결하고, 메모리 사용량도 적다고 생각된다. (따로 hashMap을 관리 안해도 되니까)
set자체가 중복을 피하고하자는 자료구조이기 때문에 내부 구현은 아마 내가 위에서 구현한 것과 비슷하게 구현되어 있으리라 생각된다..
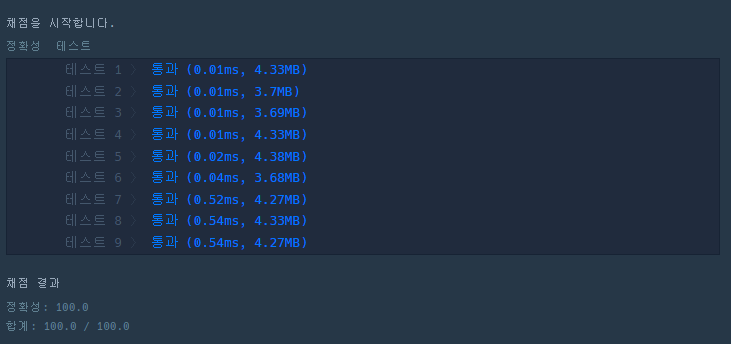
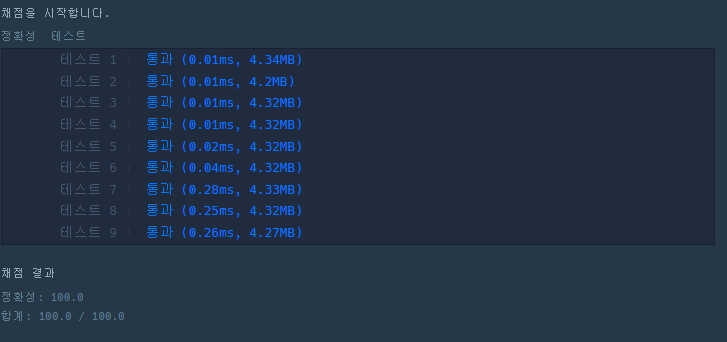
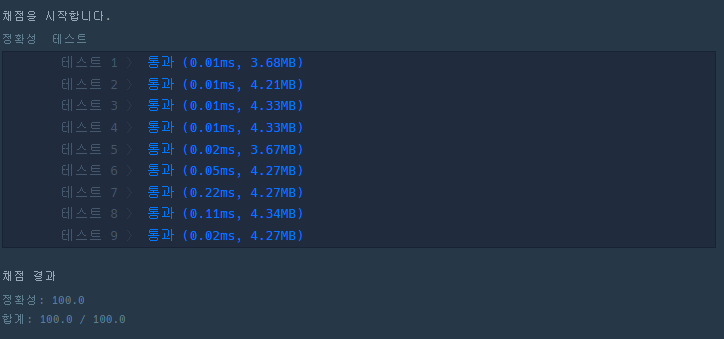
위 코드들에 대한 결과이다.
set을 썻을때가 가장 안정적으로 빠르다. 중복값 피할때는 set을 가져다 쓰는게 가장 좋을 것 같다.

내가 보려고 만든 블로그