
pycham과 python3.6버전을 추천합니다! 제가하는 패키지는 bs4이니 selenium패키지는 없습니다..ㅠㅠ
( 성격이 급하셔서 코드만 보고싶으시면 맨아래로 내리면 되세요! )
크롤링을 시작하기 전에 먼저 package를 다운받아야 합니다.
파이참을 실행한 후 환경설정의 Python Interpreter으로 들어갑니다.
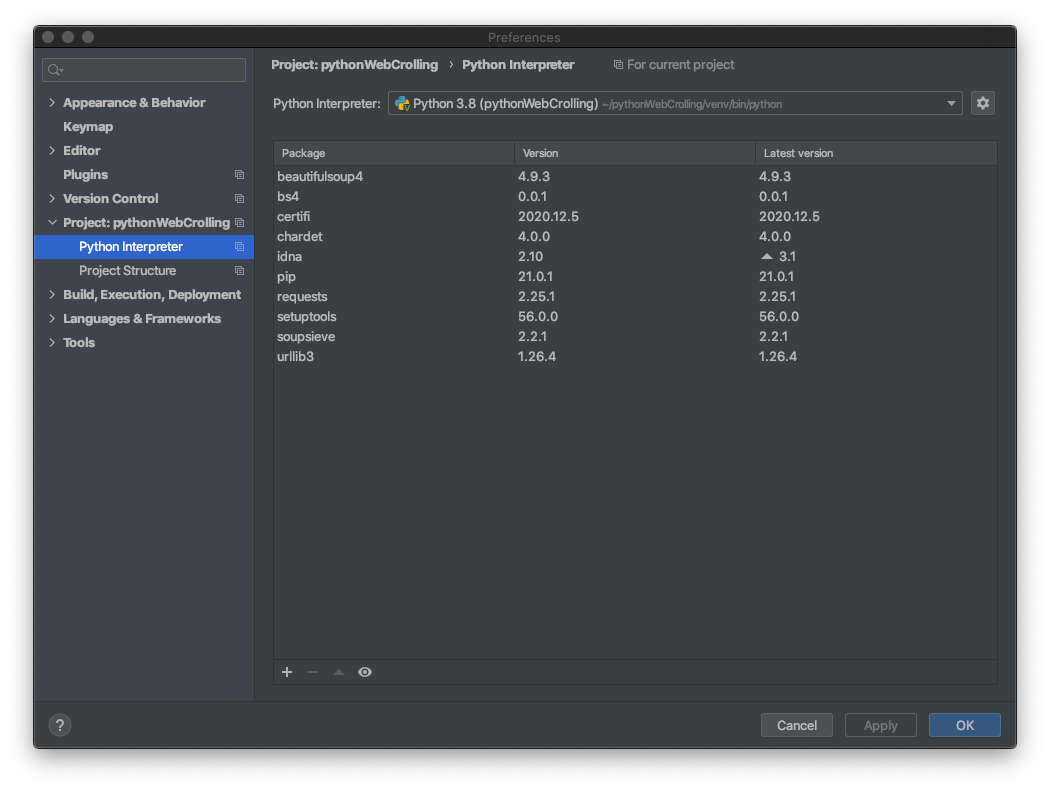
오른쪽 하단의 +클릭!

검색창의 bs4를 검색후
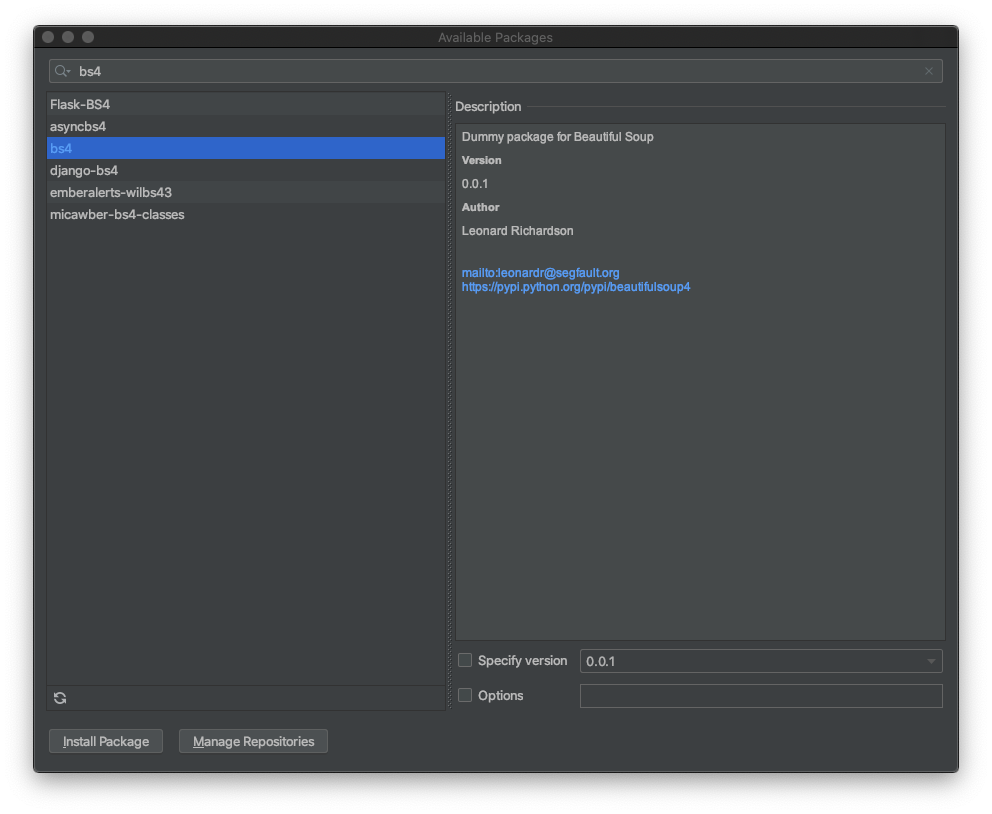
오른쪽 하단의 Install Package를 클릭!
package가 모두 다운로드되면 환경설정창을 모두 닫아주시고 파이참의 처음화면으로 돌아갑니다.
처음 화면으로 돌아와서 원하는 파일명으로 .py파일을 생성합니다.
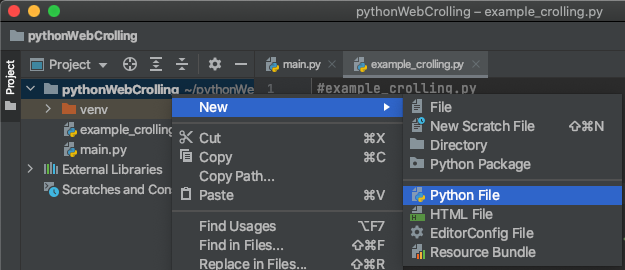
저는 example_crolling이라는 이름으로 생성해주겠습니다.
이제 부턴 코딩을 시작하겠습니다.
#example_crolling 파이썬의 주석 처리 방법입니다.
import urllib.request
url = "https://www.naver.com/"
html = urllib.request.urlopen(url)
print(html.read())
소스를 위와 같이 간단하게 적고 실행을 돌려본 결과입니다. ( run을 돌릴 때 기본값으로 main이 잡혀있다면 새로만든 파일을 우 클릭! Run을 클릭하면 됩니다!)
일단 네이버의 시작 페이지를 불러오겠습니다.
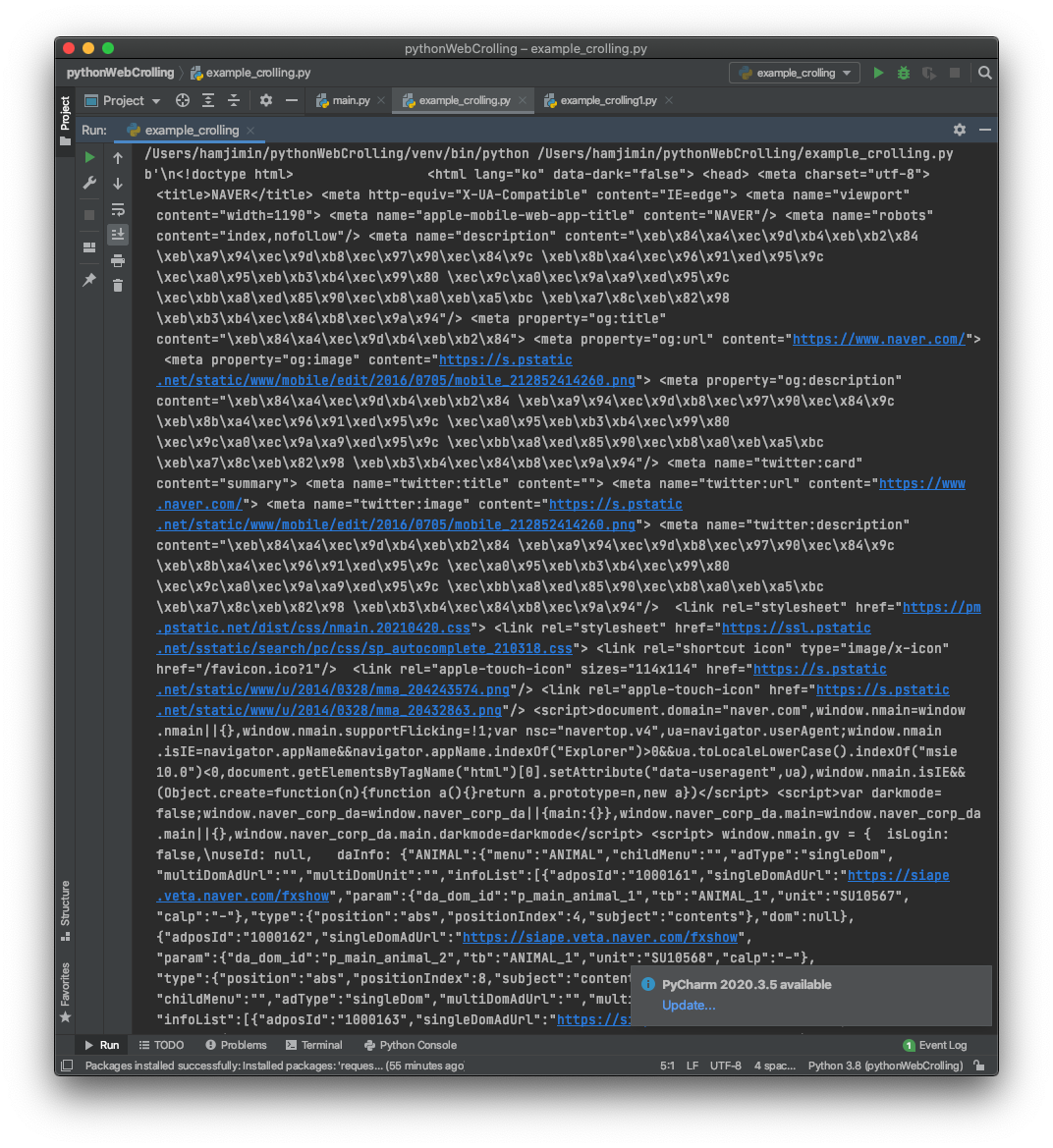
네이버의 부터 까지의 데이터를 불러왔습니다.
다음은 bs4에 데이터 넣기, 불러온 데이터를 Parsing하기 위해 데이터를 bs4에 데이터를 넣은 후 파이썬에서 가공할 수 있는 형태로 만들어 주어야한다.
#example_crolling 파이썬의 주석처리 입니다.
import urllib.request
import bs4
url = "https://www.naver.com/"
html = urllib.request.urlopen(url) # html이란 변수엔 웹에서 받은 text값
bs_obj = bs4.BeautifulSoup(html, "html.parser") # html.parser로 parsing하기
print(bs_obj)
여기까지 오류없이 되셨다면 다음은 naver.com에서 원하는 부분만 추출해볼까요?
그럴려면 naver.com에서 원하는 부분의 테그를 알아야합니다.
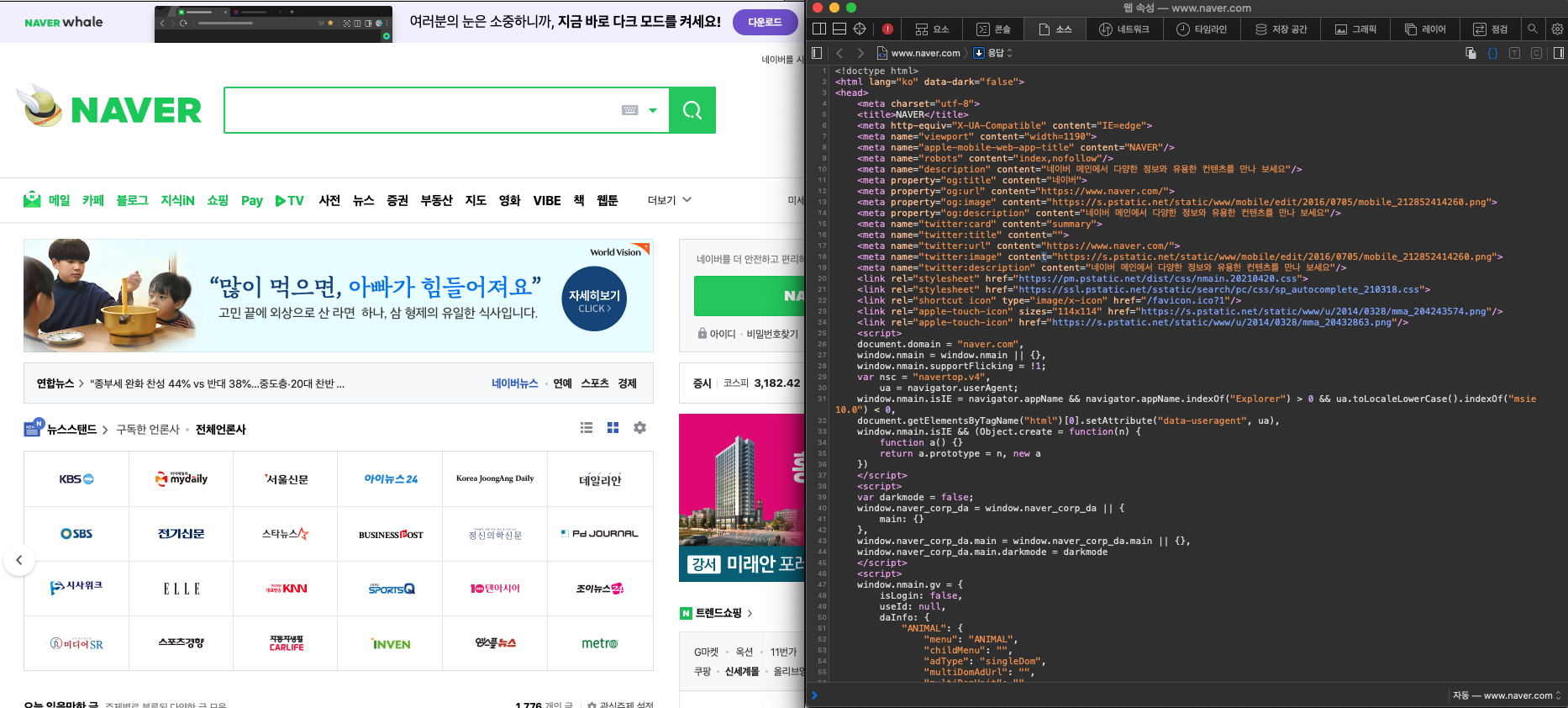
네이버로 들어가 개발자 모드를 켠 후 자신이 원하는 부분의 태그를 찾아보시면 됩니다. ( chrom을 이용하시면 마우스로 쉽게 찾아볼 수 있어요! )
저는 class="service_area"영역을 추출해 보겠습니다.
#example_crolling.py
import urllib.request
import bs4
url = "https://www.naver.com/"
html = urllib.request.urlopen(url)
bs_obj = bs4.BeautifulSoup(html, "html.parser")
top_right = bs_obj.find("div",{"class" : "service_area"})
first_a = top_right.find("a")
print(first_a.text)
새로운 변수에 bs4.find로 class="service_area"를 추가해주시고 Run을 시키면?!?!
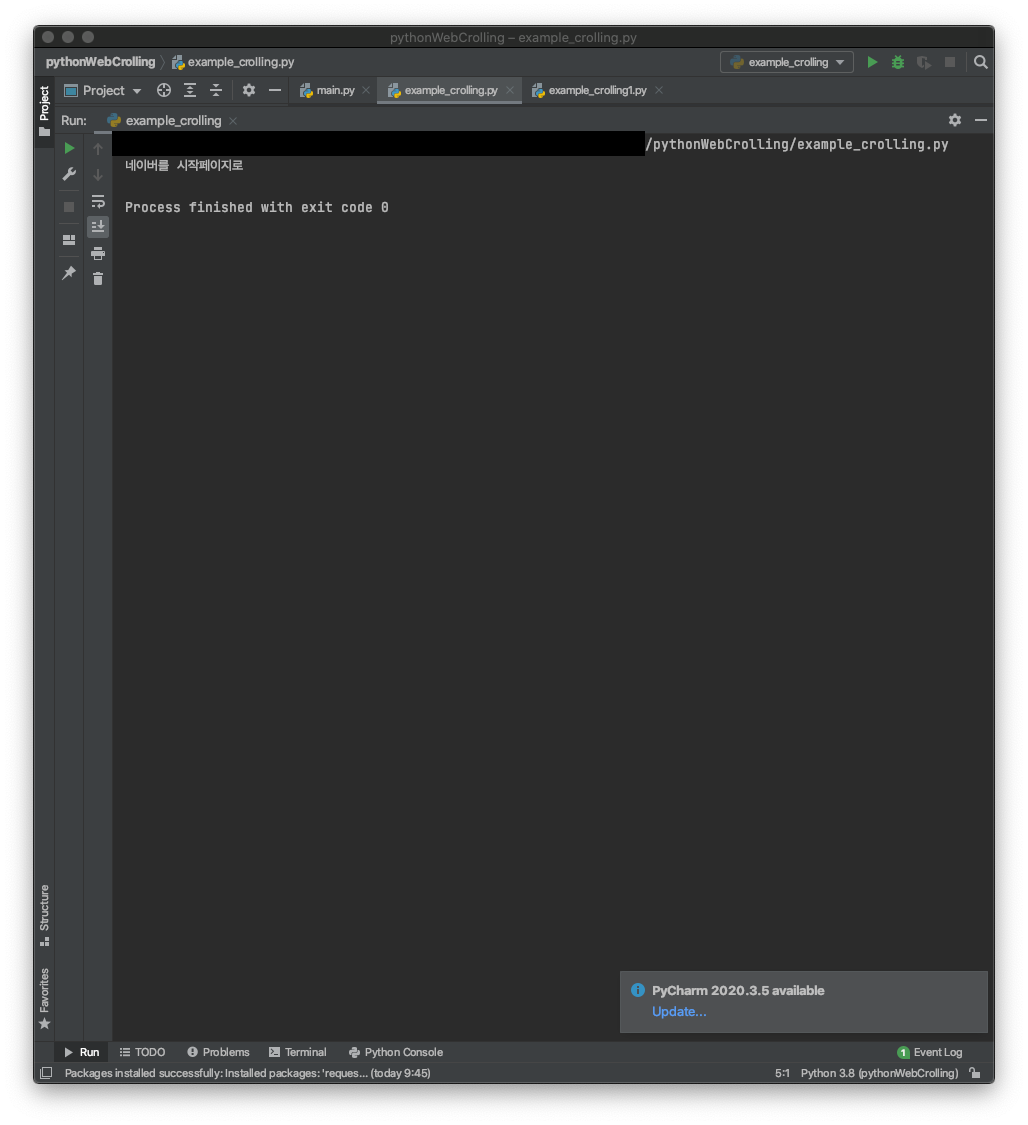
제가 원하는대로 뽑아오는걸 볼 수 있습니다.
java크롤링과 비교해보니 너무나 쉽네요ㅜㅜ package를 bs4가 아닌 selenium으로 많이들 한다고 합니다. 저는 아직 해보지 못해 bs4로 알려드렸어요 다음엔 selenium으로 다시 찾아뵐께요! 빠잉~
