
1. 참조 지역성 원리
캐시 메모리는 메모리의 일부를 복사하여 저장한다. 무엇을 저장할까?
→ CPU가 사용할 법한 대상을 예측하여 저장!
- 캐시 히트(cache hit)
: 자주 사용될 것으로 예측한 데이터가 실제로 들어맞아 캐시 메모리 내 데이터가 CPU에서 활용된 경우
- 캐시 미스
: 예측이 틀려 메모리에서 필요한 데이터를 직접 가져와야 하는 경우 (성능 저하)
→ 캐시적중률이 높으면 CPU의 메모리 접근 횟수를 줄일 수 있다.
HOW 예측?
1) CPU가 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다.
→ 시간 지역성
: 코드에서 변수를 사용할 때 보면 CPU는 최근에 접근했던 (변수가 저장된) 메모리 공간을 여러 번 다시 접근할 수 있다.
2) CPU는 접근한 메모리 공간 근처를 접근하려는 경향이 있다.
→ 공간 지역성
: 워드 프로세서 프로그램을 실행할 적에는 워드 프로세서 프로그램이 모여 있는 공간 근처를 집중적으로 접근할 것. 사용자가 입력을 할 적에는 입력 기능이 모여있는 공간 근처를 집중적으로 접근.
2. 캐시 실습
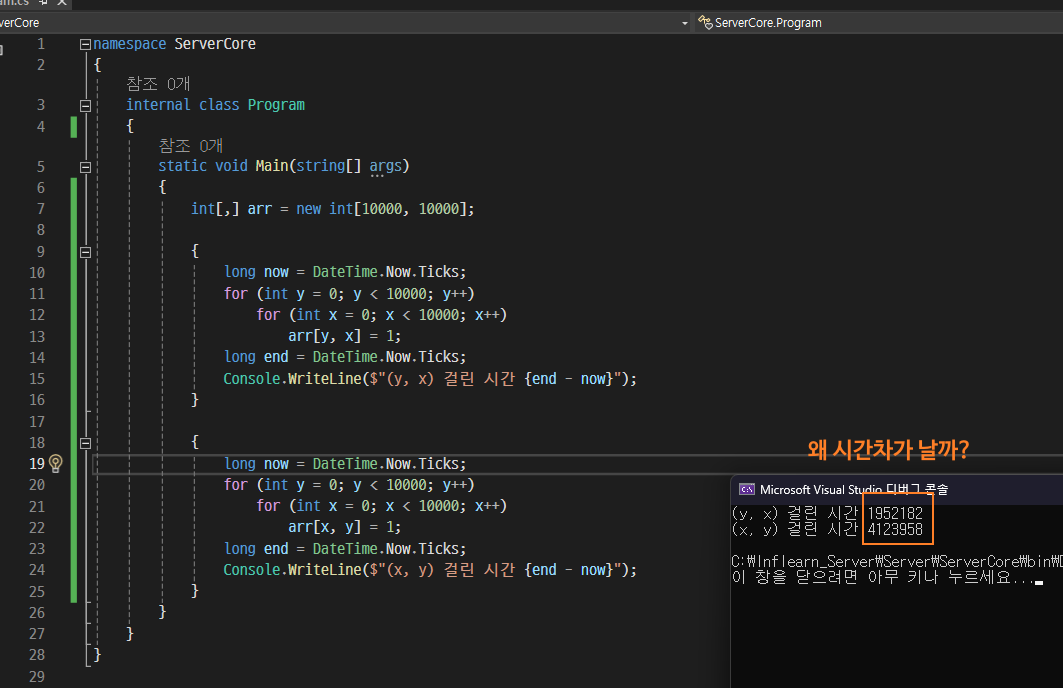 수학적으로 보았을 때는 두 방식의 걸린 시간이 동일해야하는데 약 2배나 차이가 난다.
수학적으로 보았을 때는 두 방식의 걸린 시간이 동일해야하는데 약 2배나 차이가 난다.
WHY?
-
배열의 저장 방식:
C#에서 다차원 배열 (예: int[,] arr)은 메모리에 연속적으로 저장된다. int[10000, 10000] 배열에서, 첫 번째 차원 (y 축)은 각 행을 나타내고, 두 번째 차원 (x 축)은 각 열을 나타낸다. 메모리에는 이 배열이 행별로 연속적으로 저장된다. 즉, (0, 0) 다음에 (0, 1)이 오고, 마지막으로 (0, 9999)가 온다. 그 다음에는 (1, 0)이 저장된다. -
CPU 캐시:
CPU가 데이터에 빠르게 접근하기 위해, 작은 양의 데이터를 일시적으로 저장하는 빠른 메모리다. CPU는 캐시에 데이터를 '라인(line)' 단위로 저장한다. 데이터에 처음 접근할 때, 해당 데이터와 인접한 메모리 위치의 데이터도 함께 캐시에 로드됩니다.(캐시 라인 채우기)
💡 시간 차이의 원인:
-
(y, x) 순서
: 이 경우, 배열은 행별로 연속적으로 접근된다. (arr[0, 0], arr[0, 1], ..., arr[0, 9999], arr[1, 0], ...). 이는 메모리에 저장된 순서와 일치한다. 따라서 캐시 효율성이 높아지며, CPU는 메모리에서 데이터를 더 빠르게 읽을 수 있다. -
(x, y) 순서
: 이 경우, 배열은 열별로 접근된다. (arr[0, 0], arr[1, 0], ..., arr[9999, 0], arr[0, 1], ...). 이는 메모리에 저장된 순서와 일치하지 않다. 각 접근은 메모리의 다른 위치로 이동함을 의미하고, 이로 인해 캐시 미스(cache miss)가 빈번하게 발생한다. 이는 상대적으로 느린 작업이므로, 전체적인 실행 시간이 늘어난다.
결론적으로, (y, x) 순서로 배열에 접근하는 것이 (x, y) 순서로 접근하는 것보다 메모리의 연속적인 구조와 캐시 메커니즘을 훨씬 효율적으로 활용하기 때문에 더 빠르다.
