https://redis.io/docs/management/scaling/을 보며 학습한 내용을 기록합니다.
redis cluster
- 여러 개의 노드에 데이터를 자동으로 분배 시킬 수 있음
- 일부 노드가 실패하거나 다른 노드와 상호작용하지 못하는 경우에도 여전히 운영되도록 할 수 있음
tcp ports
- ex. 6379 → serve clients
- ex. 16379 = data port + 10000 → cluster bus port
- cluster bus → binary protocol을 사용하여 노드 간 커뮤니케이션을 위해 사용된다.
- 노드들은 cluster bus를 failure detection, configuration updates, failover authorization 등등을 위해 사용한다.
- 그렇기 때문에 두 개의 포트에 대해 방화벽을 열어주어야 한다.
binary protocol → 작은 대역폭, 처리시간 덕분에 노드 사이 정보 교환에 적합한 프로토콜
redis cluster data sharding
- CRC16(key) mod 16384 → key에 대한 hash slot을 알아낸다.
- 예를 들어서 만약 3개의 노드로 클러스터가 구성되어 있다면 다음처럼 hash slot의 subset을 가지게 된다.
- Node A contains hash slots from 0 to 5500.
- Node B contains hash slots from 5501 to 11000.
- Node C contains hash slots from 11001 to 16383.
redis cluster master-replica model
- master 노드가 죽거나 다수의 노드들과 커뮤니케이션 할 수 없는 상황에서도 레디스를 동작 가능하게 하기 위해서 레디스 클러스터는 모든 hash slot이 1개 master, n개 replica 를 가지는 master-replica 모델을 사용한다.
- A,B,C (master) A1,B1,C1(replica)
- B가 죽었을 때 B1이 master로서 기능을 하게 된다.
- B, B1이 동시에 죽는다면 레디스 클러스터는 동작할 수 없게 된다.
redis cluster consistency guarantees
- 레디스 클러스터는 강력한 일관성을 보장하지 않는다.
- 그 이유는 레디스 클러스가 비동기적인 복제를 사용하기 때문
-
client → master b(write)
-
client ← master b(ok)
-
master b → replicas b1, b2, b3(propagates)
→ master b는 replicas b1, b2, b3으로부터 ack 응답을 받고 사용자에게 ok 응답을 보내지 않는다. (기다리지 않고 보낸다)
→ master b가 client에게 ack 응답을 보내고 replicas b1, b2, b3에게 데이터를 복제하기 전에
죽어서 replicas 중에 하나가 master가 된다면 이 쓰기 작업은 영구적으로 잃게 된다.
-
성능과 일관성 사이에는 트레이드 오프가 존재한다.
-
wait 명령어를 통해 동기적인 쓰기 작업을 지원한다.
→ 하지만 이렇게 한다고 하더라도 여러 실패 시나리오가 존재하기 때문에 강력한 일관성을 보장할 수는 없다.
-
- 그 이유는 레디스 클러스가 비동기적인 복제를 사용하기 때문
redis cluster configuration parameters
- cluster-enabled<yes/no>: yes로 설정하면 인스턴스가 레디스 클러스터로 구성되도록 한다.
- cluster-config-file: redis cluster에 의해 자동으로 관리되는 파일이며 이 파일에는 클러스터에 포함된 다른 노드들, 노드들의 상태 등등이 저장된다.
- cluster-node-timeout: redis cluster 노드가 동작 가능하다고 판단되는 최대 시간 만약 master 노드가 이 시간까지 동작하지 못한다면 이것의 replicas에 의해 failover 된다. node의 과반수가 down 상태로 체크할 경우 replica를 master로 승격하는 failover 처리를 시작한다. 만약 대부분의 master 노드가 이 시간까지 동작하지 못한다면 요청 처리를 멈춘다.
- cluster-slave-vaildity-factor: 0으로 설정하면, replica는 항상 자신이 유효한 것으로 간주하기 때문에 master와 replica 간의 maximum disconnection time 에 상관없이 master를 failover 하려고 시도한다. 만약 양수라면, maximum disconnection time은 node-timeout * factor로 설정된다. 만약 master와 replica 간의 disconnection time이 위에서 계산한 값보다 크다면 replica는 fail over를 시도할 수 없다.
- cluster-migration-barrier: 연결된 상태를 유지하는 최소 replica의 수
- cluster-require-full-converage<yes/no>: 기본적으로 설정된 yes의 경우 key space의 일정 퍼센테이지가 어떤 노드에 의해서도 cover 되지 못한다면 쓰기 작업을 허용하지 않는다. (=master, replica 모두 동작 x) 만약 no로 설정하면 keys의 일부 요청만 처리할 수 있는 경우에도 쓰기 작업을 멈추지 않는다.
requirements to create a redis cluster
- 먼저 레디스 클러스터를 구성하기 위해서 cluster mode로 동작하는 redis 인스턴스를 만들어야 한다.
- 6개(master 3, replica 3)의 노드 클러스터가 추천된다.
mkdir cluster
cd cluster
mkdir 7001 7002 7003 7004 7005 7006- 그 다음 redis.conf 파일을 아래처럼 수정한다.
port 7001 // 각 디렉토리에 맞게 port number 수정
cluster-enabled yes // cluster mode를 위해 yes로 설정
cluster-config-file nodes.conf // 절대 임의로 수정하면 안되는 파일
cluster-node-timeout 5000
appendonly yes // 다운되었던 노드 재시작시 appendonly 파일에 가장 최근까지 데이터가 있으므로 클러스터 운영시에는 yes로 설정하는것을 권장
dir /Users/junghayoung/cluster/7001 // working directory도 설정해주는것을 추천- 그다음 각 디렉토리(7000부터 7005까지) 안에 redis.conf 파일을 생성하고
각각의 터미널 탭에서 다음처럼 각각이 인스턴스를 시작한다.
redis-server ./redis.conf- 7001-7006까지 인스턴스 실행
- 실행한 후에 새로운 id가 각각 노드마다 할당된 것을 log를 통해 확인할 수 있다.
[82462] 26 Nov 11:56:55.329 * No cluster configuration found, I'm 97a3a64667477371c4479320d683e4c8db5858b1 - 모든 노드들은 id를 통해 다른 모든 노드들을 기억한다.
- ip 주소와 port는 변경될 수 있지만 id는 노드가 죽을 때까지 절대 변경되지 않는다.
그다음으로 생성한 인스턴스를 클러스터로 구성한다.
replicas를 0으로 지정하면 참여한 노드가 모두 마스터가 된다.
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 \
127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 \
--cluster-replicas 1 //모든 master마다 replica를 생성함정상적으로 실행되면 다음 메시지를 볼 수 있다.
[OK] All 16384 slots covered레디스 클러스 각각 인스턴스를 실행하고 구성하는 대신 더 간단한 방법이 있다.
레디스 폴더 > utils에 가면 create-cluster라는 스크립트가 있다.
6개의 노드로 클러스터를 구성하기 위해 다음의 명령어만 입력하면 된다.
create-cluster start
create-cluster create첫 번째 노드는 기본적으로 30001포트를 사용하고 클러스터를 멈출 때는 아래 명령어를 입력하면 된다.
create-cluster stopInteract with the cluster
redis-cli를 사용해서 redis cluster를 테스트할 수 있다.
$ redis-cli -c -p 7000 //-c는 클러스터 노드에 접속
redis 127.0.0.1:7000> set foo bar
-> Redirected to slot [12182] located at 127.0.0.1:7002
OK
redis 127.0.0.1:7002> set hello world
-> Redirected to slot [866] located at 127.0.0.1:7000
OK
redis 127.0.0.1:7000> get foo
-> Redirected to slot [12182] located at 127.0.0.1:7002
"bar"
redis 127.0.0.1:7002> get hello
-> Redirected to slot [866] located at 127.0.0.1:7000
"world"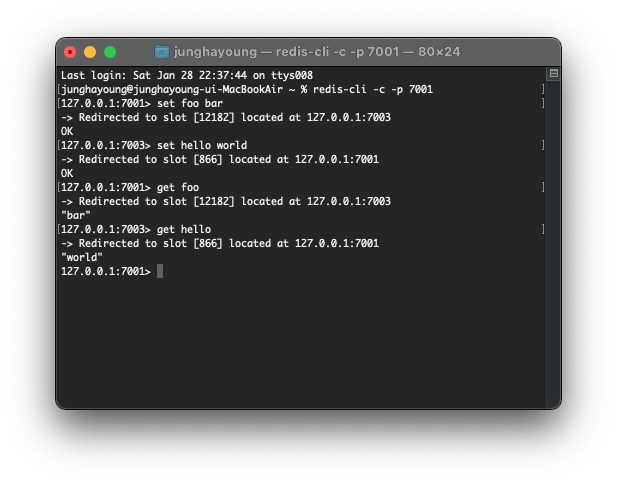
set foo bar를 입력하면 key의 slot은 12182이므로 7003번 노드에 할당되었고 redis-cli가 7003번에 접속해서 입력하는 것이다. 이것은 -c 모드로 접속했을 때 가능하다.
Reshard the cluster
resharding은 hash slots을 노드 세트에서 다른 노드 세트로 옮기는 것을 뜻한다.
클러스터 생성과 똑같이 redis-cli를 사용해서 할 수 있다.
redis-cli --cluster reshard 127.0.0.1:7001노드만 입력하면 자동으로 다른 노드들을 찾아준다.
How many slots do you want to move (from 1 to 16384)?얼만큼을 resharding을 할지 물어보는데 우리는 1000개의 hash slots을 resharding 할 것이다.
What is the receiving node ID?그다음 redis-cli는 resharding 타켓을 물어보는데 우리는 첫 번째 master 노드인 127.0.0.1:7001
로 할 것이기 때문에 이 노드의 node id를 입력한다.
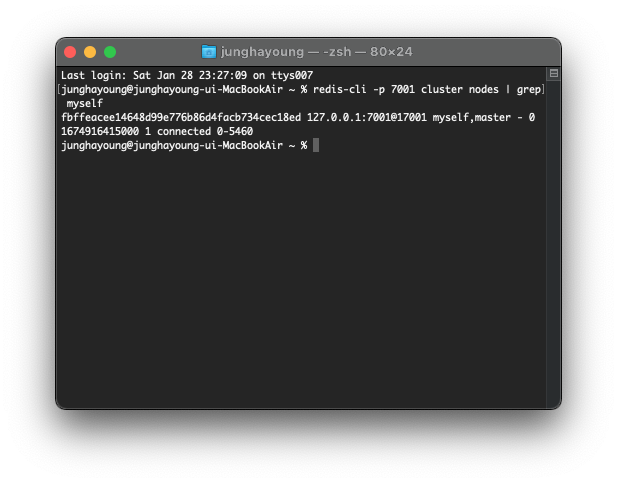
$ redis-cli -p 7001 cluster nodes | grep myself
97a3a64667477371c4479320d683e4c8db5858b1 :0 myself,master - 0 0 0 connected 0-5460이 명령어를 통해 첫번째 노드의 node id를 알 수 있다.
그다음 해당 키를 가져올 노드를 물어보는데 이때 모든 master 노드들에서 hash slots을 조금씩
가져오기 위해 all을 입력한다.
최종 확인이 끝나면 노드에서 다른 노드로 이동할 모든 슬롯에 대한 메시지가 표시된다.
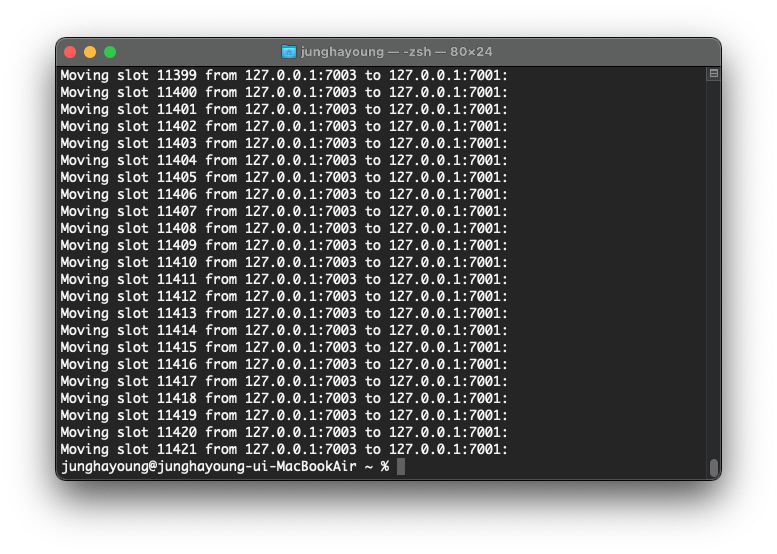
resharding이 진행되는 동안 돌아가던 프로그램은 영향을 받지 않는다.
모든 slots은 똑같이 커버되고 다만 127.0.0.1:7001 master는 약 6461 만큼의 hash slots을 가지게 될 것이다.
—cluster-yes 옵션을 통해 cluster manager가 자동으로 명령 프롬포트에 ‘yes’를 답하도록 할 수있다.
이 옵션은 또한 REDISCLI_CLUSTER_YES 환경 변수를 통해 설정할 수도 있다.
Test the failover
failover를 테스트하기 위해서 가장 쉬운 방법은 단일 프로세스(단일 마스터)를 중단시키는 것이다.
https://github.com/antirez/redis-rb-cluster에서 consistency-test.rb 를 받아 실행한다.
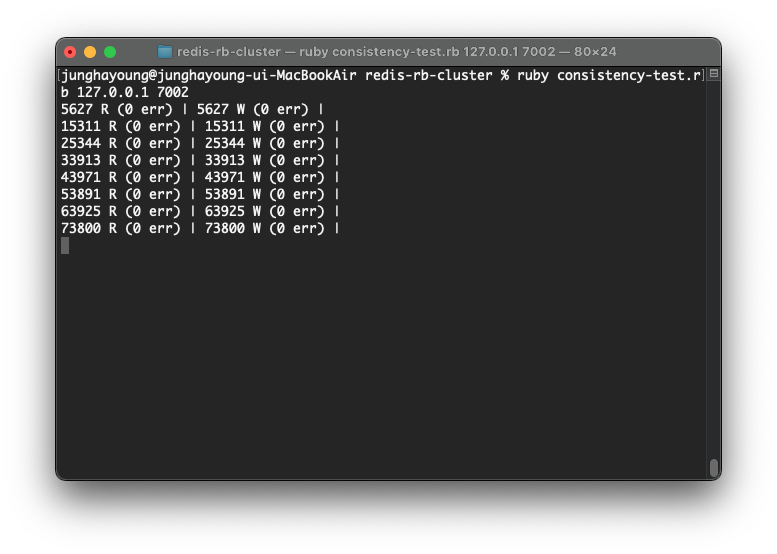
각 라인은 수행된 read, write의 수를 의미하고 error는 시스템이 동작하지 않아 쿼리가 실행이 안 된 수를 나타낸다.
master를 식별하기 위해 다음 명령어를 입력한다.
redis-cli -p 7001 cluster nodes | grep master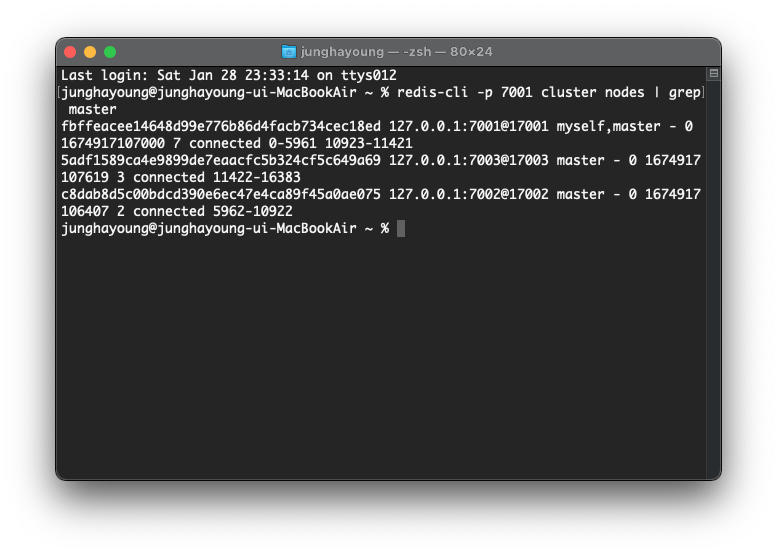
7001, 7002, 7003 이 master 노드이다.
redis-cli -p 7002 debug segfault //debug 용도로 서버를 crash 시키는 명령서버가 다운되면 이를 감지한 다른 서버들은 3초(cluster-node-timeout 설정값) 후에 다음과 같은 로그를 남긴다.
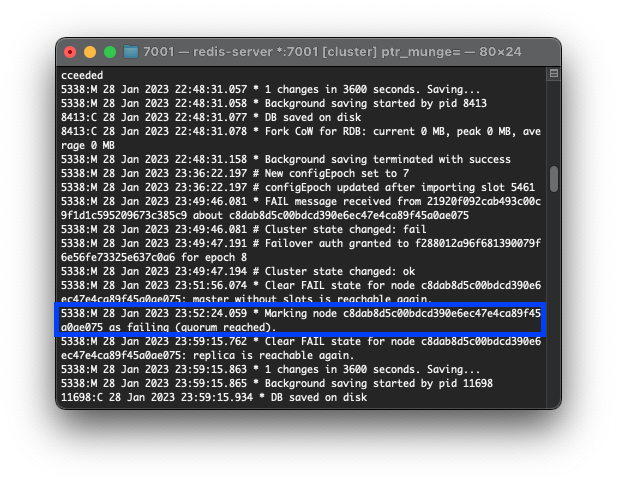
consistency test에서 다음의 결과를 확인할 수 있다.
18849 R (0 err) | 18849 W (0 err) |
23151 R (0 err) | 23151 W (0 err) |
27302 R (0 err) | 27302 W (0 err) |
... many error warnings here ...
29659 R (578 err) | 29660 W (577 err) |
33749 R (578 err) | 33750 W (577 err) |
37918 R (578 err) | 37919 W (577 err) |
42077 R (578 err) | 42078 W (577 err) |578 개의 읽기와 577개의 쓰기 에러가 발생했지만 데이터베이스의 일관성은 깨지지 않았다.
이전에 redis cluster는 비동기 복제를 사용하기 때문에 failover 동안 쓰기를 잃게 될 수 있다고 했었다.
사실 redis는 클라이언트에게 응답하고 거의 동시에 replicas에게 복제 명령을 하기 때문에
데이터를 잃는 가능성은 매우 작다. 하지만 이 말이 데이터를 잃을 가능성이 아예 없다는 것은 아니므로
일관성을 보장한다고는 할 수없다.
이제 failover 후에 클러스터 설정을 확인할 수 있다.
redis-cli -p 7001 cluster nodes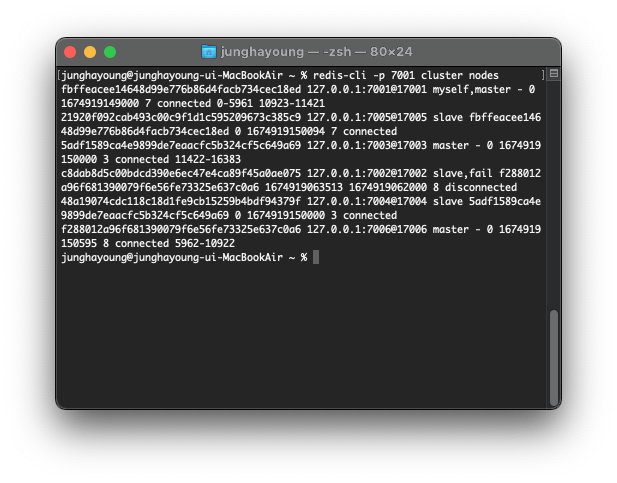
7001, 7003, 7006 포트에서 master가 실행 중인 것을 확인할 수 있다.
Manual failover
때로는 master에 어떤 문제를 일으키지 않고 failover를 하는 게 유용할 때가 있다.
예를 들어 마스터 노드 중에 하나를 업그레이드할 때 가용성에 작은 영향을 주기 위해서 slave 상태에서
진행하는 것이 좋을 때도 있다.
manual failover는 CLUSTER FAILOVER 명령어를 사용해서 사용할 수 있다.
이것은 failover 하고자 하는 master의 replicas 중에 하나에서 실행되어야 한다.
manual failover는 실제 master 실패로 인해 발생하는 failover와 비교하면 훨씬 더 안전하다.
이전의 master가 모든 복제 스트림을 처리한 경우에만 클라이언트의 연결을 기존 마스터에서 새로운 마스터로 옮기기 때문에 프로세스 내에서 데이터의 손실을 줄이는 방법으로 진행한다.
기본적으로 failover된 master에 연결된 클라이언트가 중지되고
동시에 master는 자신의 복제 오프셋을 replica에게 보내고 replica가 해당 오프셋에
도달하기를 기다린다. 복제 오프셋이 도달되면 failover가 시작되고
old master에 configuration switch에 대한 정보가 표시된다.
old master에 대한 클라이언트 차단이 해제되고 클라이언트는 new master로 리다이렉트된다.
Add a new node
새로운 노드를 추가하는 것은 empty node를 추가하고 이것으로 일부 데이터를 옮기는 과정이 될 수 있고(new master) 또는 이미 존재하는 노드의 replica로 설정하는 과정일수도 있다(replica)
new master
- 인스턴스 생성
- 레디스 클러스터에 추가
- resharding
먼저 empty node를 추가해야 한다.
이전에 7001-7006포트에 노드를 만들었기 때문에 7007포트에서 실행될 노드를 만들면 된다.
그다음 이 노드를 cluster에 추가해 주기 위해 redis-cli를 사용한다.
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001cluster에 추가된 노드를 확인할 수있다.
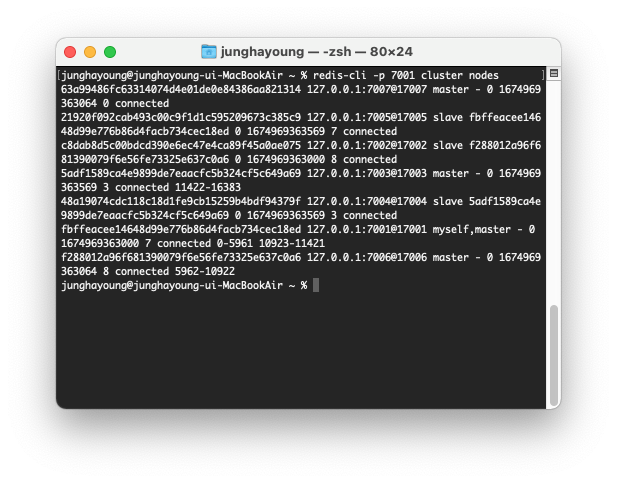
이 노드는 cluster에 연결되어 있기 때문에 client queries를 리다이렉트할수있고
cluster의 일부라고 할 수 있다. 하지만 다른 masters와 비교하면 두 가지의 특이점이 있다.
- 할당된 hash slots이 없기 때문에 데이터가 없다.
- 할당된 hash slots이 없는 master이기 때문에 replica가 master가 될 때 election process 참여할 수 없다.
resharding을 사용하여 이 노드에 hash slots을 할당하면 된다.
Add a new node as a replica
new replica를 추가하는 방법은 두 가지이다. 첫번째는 new master 추가할 때처럼 redis-cli를 사용하는 것이다.
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001 --cluster-slave어떤 master에 replica를 추가할지 설정하지 않으면 redis-cli가 적은 replicas를 가진
masters 중에 랜덤으로 하나를 꼽아 새로운 replica를 추가한다.
아래처럼 정확하게 어떤 master에 추가할지를 설정할 수도 있다.
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 --cluster-slave --cluster-master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e특정 master에 replica를 더하는 더 manual 한 방법은 empty master로 새로운 노드를 추가하고
CLUSTER REPLICATE 명령어를 통해 replica로 바꾸는 것이다.
예를 들어 11423-16383 범위에서 hash slots를 제공하는 127.0.0.1:7005 노드(Node ID 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e)를 위한
replica를 추가하기 위해서 새로운 노드에 접속해서 다음의 명령어를 사용하면 된다.
redis 127.0.0.1:7007> cluster replicate 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912eRemove a node
- resharding
- 노드 제거
replica 노드를 삭제하기 위해서 redis-cli의 del-node 명령어를 사용하면 된다.
redis-cli --cluster del-node 127.0.0.1:7001 `<node-id>`첫 번째 인수는 cluster의 아무 노드를 입력하면 되고, 두 번째 인수는 삭제하고자 하는
노드의 id를 입력한다.
이런 방식으로 master 삭제할 수 있는데 master 노드는 반드시 빈 상태여야 한다.
master 노드의 데이터를 다른 master 노드들에게 reshard 하고 삭제하여야 한다.
master 노드를 제거하는 또 다른 방법은 manual failover을 하고 노드를 삭제하는 것이다.
(master → replica, replica → master, replica 삭제)
cluster에서 master의 수를 줄이기를 원한다면 이 방법은 사용할 수 없고 resharding이 필요하다.
Replica migration
redis cluster에서 다음 명령어를 사용해서 언제든 다른 master를 복제하도록
재설정 할 수 있다.
CLUSTER REPLICATE <master-node-id>system administrator의 도움 없이 자동으로 하나의 master에서 다른 master
로 replicas를 옮기는 특별한 시나리오가 있다. replicas 자동 재설정은
replicas migration이라고 불리며 redis cluster의 안정성을 향상시킬 수 있다.
하나의 master에서 다른 master로 cluster replicas를 옮기려는 이유는
redis cluster가 master에 구성된 replicas의 수만큼 장애에 대항할 수 있기 때문일 것이다.
예를 들어 모든 master에 하나의 replica가 있다고 할 때 master 와 replica가 동시에
실패하면 master가 제공하는 hash slots의 복제본을 가질 인스턴스가 존재하지 않기 때문에
작업을 계속할 수 없다.
시스템의 안정성을 향상시키기 위해서 모든 master에 replicas를 추가할 수 있는 옵션은 가지고 있다.
하지만 이것은 비용이 매우 비싸다. replica migration을 통해 몇 개의 master에
더 많은 replicas를 추가할 수 있다.
replica migration에 대한 필수적인 내용은 다음과 같다.
- cluster는 가장 많은 replicas를 가진 master에서 replica migration 시도할 것이다.
- replica migration으로부터 이득을 얻기 위해서는 하나의 master에 여러 개의 replicas 를 추가해야 한다. 어떤 master 인지는 중요하지 않다.
- cluster-migration-barrier 설정을 통해 replica migration 을 제어할 수 있다.
Upgrade nodes in a Redis Cluster
레디스의 업데이트된 버전과 함께 노드를 멈추고 재시작하면 되기 때문에 replica 노드들을 업데이트하는 것은 쉽다.
만약 클라이언트가 replica 노드를 사용하여 scaling reads를 한다면
replica 노드가 사용 불가능하다면 다른 replica로 재접속 할것이다.
master를 업그레이드하는것은 조금 더 복잡하다.
- replicas 하나가 master로 failover 되도록 CLUSTER FAILOVER을 한다.
- master가 replica가 되도록 기다린다.
- replica를 업데이트했던 것처럼 업데이트한다.
- 방금 업그레이드한 노드가 master가 되길 원한다면, manual failover를 하면 된다.
참고
