도메인 주도 개발 시작하기을 읽고 인상 깊었던 내용을 간단히 정리합니다.
애그리거트
애그리거트
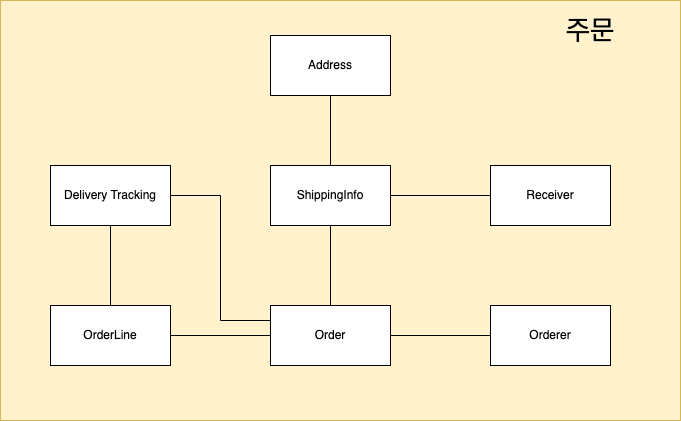
복잡한 도메인을 이해하고 관리하기 쉬운 단위로 만들려면 상위 수준에서 모델을 조망할 수 있는 방법이 필요한데 그 방법이 바로 애그리거트다.
애그리거트는 관련된 모델을 하나로 모았기 때문에 한 애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 갖는다.
애그리거트 루트
애그리거트에 속한 모든 객체가 일관된 상태(주문 상품 수량이 변경된다면 전체 금액도 변경되어야 함)를 유지하려면 애그리거트 전체를 관리할 주체가 필요한데, 이 책임을 지는 것이 바로 애그리거트의 루트 엔티티이다.
애그리거트 루트가 제공하는 메서드는 도메인 규칙에 따라 애그리거트에 속한 객체의 일관성이 깨지지 않도록 구현해야한다.
- 배송이 시작되기 전까지만 배송지 정보를 변경할 수 있다.
public class Order { public void changeShippingInfo(ShippingInfo newShippingInfo) { verifyNotYetShipped(); setShippingInfo(newShippingInfo); } private void verifyNotYetShipped() { if (state != OrderState.PAYMENT_WAITING && state != OrderState.PREPARING) { throw new IllegalStateException("already shipped"); } } } - 애그리거트 외부에서 애그리거트에 속한 객체를 직접 변경하면 안된다. 이것은 애그리거트 루트가 강제하는 규칙을 적용할 수 없어 모델의 일관성을 깨는 원인이 된다.
ShippingInfo si = order.getShippingInfo(); si.setAddress(newAddress); // 배송 상태 정보 확인 없이 주소를 변경하고 있다.
→ 도메인 모델에 대해 다음의 두가지를 습관적으로 적용해야 한다.
-
단순히 필드를 변경하는 set 메서드를 공개(public) 범위로 만들지 않는다.
-
밸류 타입은 불변으로 구현한다.
-
단순히 필드를 변경하는 set 메서드를 공개(public) 범위로 만들지 않는다.
공개 set 메서드만 넣지 않아도 일관성이 깨질 가능성이 줄어들고 cancel 이나 changePassword 처럼 의미가 더 잘 드러나는 이름을 사용하는 빈도가 높아진다.
- 밸류 타입은 불변으로 구현한다.
애그리거트 외부에서 내부 상태를 함부로 바꾸지 못하므로 애그리거트 일관성이 깨질 가능성이 줄어든다.
한 트랜잭션에서는 하나의 애그리거트만 수정하는것이 좋다.
- 성능 저하, 애그리거트의 책임 범위가 증가하는것을 막기 위해
- 도메인 이벤트를 사용하면 한 트랜잭셔에서 한 개의 애그리거트를 수정하면서도 동기나 비동기로 다른 애그리거트의 상태를 변경하는 코드를 작성할 수 있다.
- 다만 기술적으로 이벤트 방식을 도입할 수 없는 경우 한 트랜잭션에서 다수의 애그리거트를 수정해서 일관성을 처리해야 한다.
→ 애그리거트 내부에서 다른 애그리거트의 상태를 변경하는 기능을 실행하면 안된다.
두 개 이상의 애그리거트를 수정해야 한다면 애그리거트에서 다른 애그리거트를 직접 수정하지 말고 응용 서비스에서 두 애그리거트를 수정하도록 구현한다.
리포지터리와 애그리거트
객체의 영속화를 담당하는 리포지토리는 애그리거트 단위로 존재한다.
Order 애그리거트와 관련된 테이블이 세 개라면 Order 애그리거트를 저장할 때 애그리거트 루트와 매핑되는 테이블뿐만 아니라 애그리거트에 속한 모든 구성요소에 매핑된 테이블에 데이터를 저장해야한다.
//저장
orderRepository.save(order);
//조회
Order order = orderRepository.findById(orderId);
//온전한 애그리거트가 아니라면 실행 도중 NullPointerException 문제 발생JPA에서는 데이터를 가져올 때 완전한 데이터를 가져와야 한다는 사상?이 있기 때문에 특정 조건에 따라 일부 데이터만 가져와야 한다면 별도의 sql를 실행하는게 낫다는게 생각났음.
ID를 이용한 애그리거트 참조
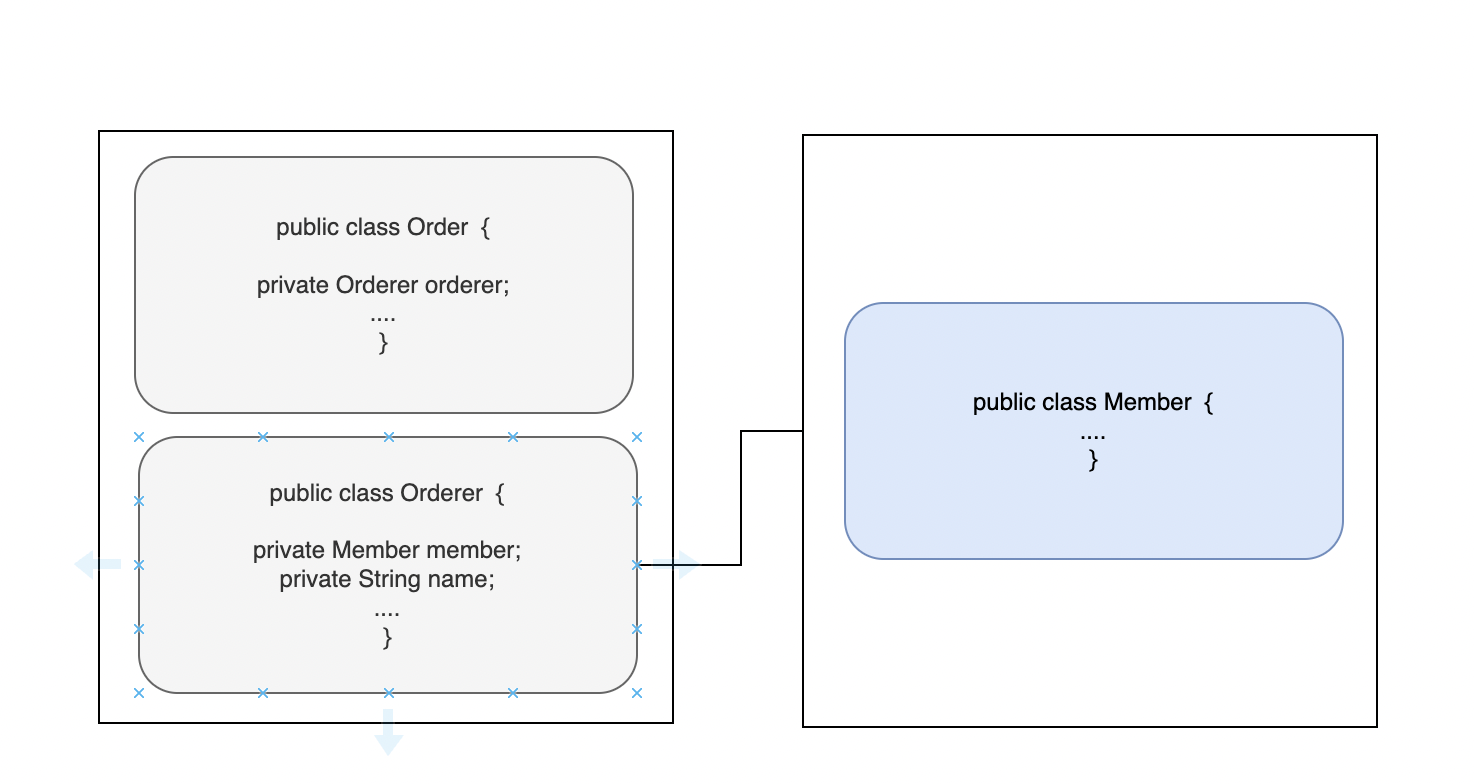
- 하나의 애그리거트에서 다른 애그리거트를 참조할 때는 애그리거트의 상태를 관리하는 애그리거트 루트를 참조한다.
-
이처럼 하나의 애그리거트에서 다른 애그리거트에 접근할 수 있게 해주는 편리함은 다른 애그리거트의 상태를 쉽게 변경할 수 있다는 위험이 된다.
- (문제1) 애그리거트의 의존 결합도는 애그리거트의 변경을 어렵게 만든다.
- (문제2) 성능과 관련된 여러가지 고민이 필요하다. (jpa를 사용할 때 lazy or eager 전략 중 무엇을 사용할 것인가?)
- (문제3) 확장성 문제
- 트래픽 증가에 따라 하위 도메인마다 하나의 데이터베이스를 사용하도록 분리할 수 있는데, 특정 도메인은 마리아db를 사용하고 다른 도메인은 몽고db를 사용한다면?
- 더 이상 다른 애그리거트 루트를 참조하기 위해 jpa와 같은 단일 기술을 사용할 수 없는 것이다.
-
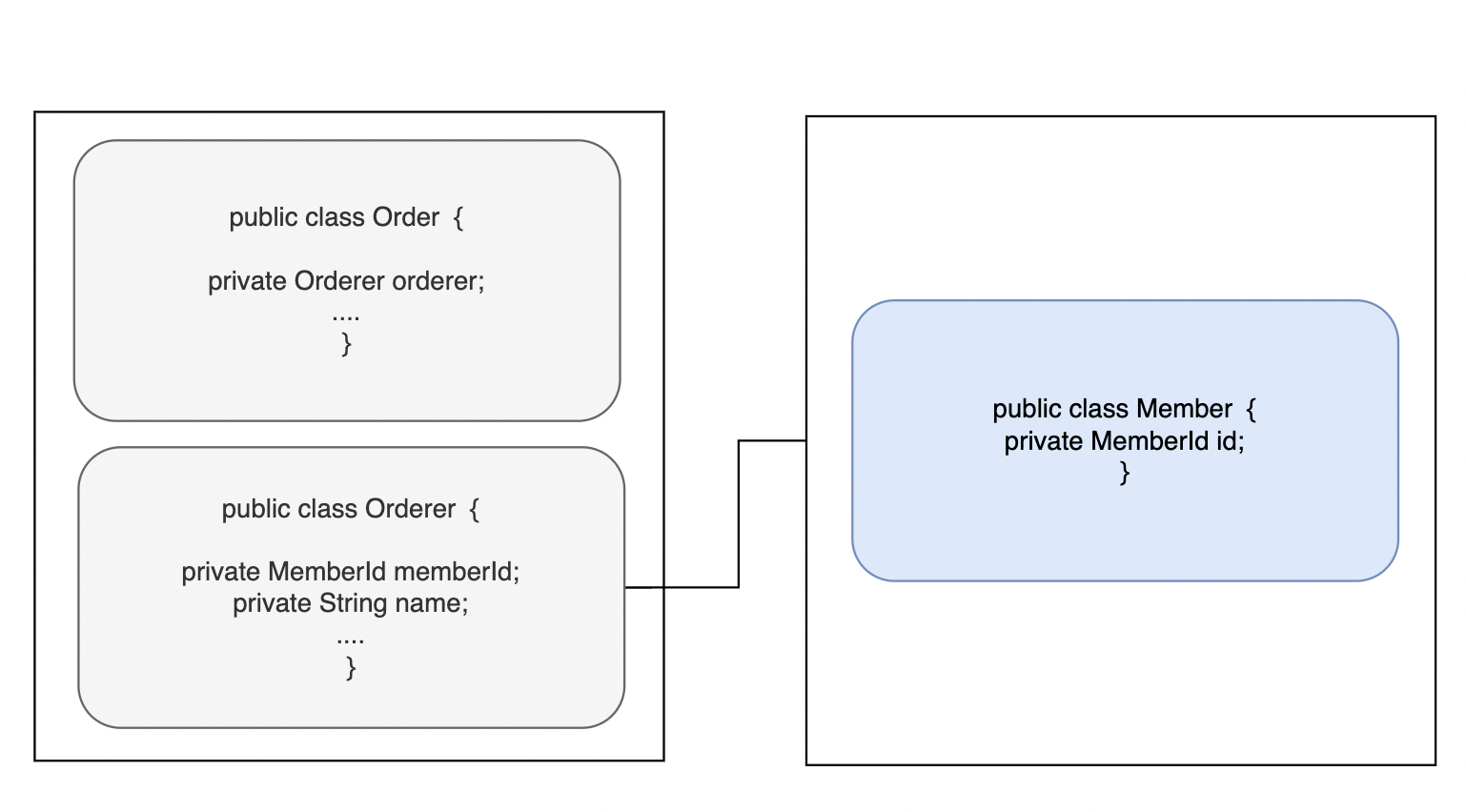
책에서 제시하는 해결방법은 id를 사용하여 참조하는 것이다.
-
애그리거트간 결합도는 낮추면서 응집도를 높이기 때문에 지연로딩을 할 지 즉시로딩으로 할 지 더 이상 고민할 필요가 없다.
-
유저가 주문한 상품 정보를 보여주는 화면이 있다고 해보자.
-
이때 유저 정보와 유저가 구매한 주문 상품에 대한 정보가 필요할 것이다.
-
만약 id참조로 설계하기로 했다면 join을 사용하지 못하고 select 쿼리를 반복적으로 수행해야 할 것이다. → N+1문제, id참조는 지연로딩과 같은 효과를 만든다.
Member member = memberRepository.findById(ordererId); //유저 정보 조회 List<Order> orders = orderRepository.findByOrderer(orderId); //주문 정보 조회 List<OrderView) dtos = orders.stream() //각 주문에 대해 주문 상품 조회 .map(order -> { ProductId productId = order.getOrderLines().get(0).getProductId(); Product product = productRepository.findById(productId); return new OrderView(order, member, product); }).collect(toList()); -
이 문제를 해결하기 위해 조회전용 DAO를 만든다.
@Repository public class JpaOrderViewDao implements OrderViewDao { @PersistenceContext private EntityManager em; @Override public List<OrderView> selectByOrderer(String orderId) { //조회 쿼리 생성해서 실행 } } -
만약 에그리거트마다 서로 다른 저장소를 사용한다면 한 번의 쿼리로 관련 애그리거트를 조회할 수 없다. 이런 경우는 조회 전용 저장소를 구성하거나 캐시를 사용하는 방법을 고려해 볼 수 있다.
-
애그리거트 간 집합 연관
- 카테고리(1) ↔ 상품(n)
- 특정 카테고리에 속한 상품을 보여주어야 하는데, 페이징을 이용해 나눠 보여준다고 해보자
public class Category {
private Set<Product> products;
public List<Product> getProducts(int page, int size) {
List<Product> sortedProducts = sortById(products); //!! 실제 보여줄 데이터가 아니라 전체 데이터를 가져오게 된다.
return sortedProducts.subList((page - 1) * size, page * size);
}
}- 이런 경우에는 n ↔ 1 연관관계로 구현에 반영한다.
public class ProductListService { public Page<Product> getProductOfCategory(Long categoryId, int page, int size) { //카테고리 구해옴 //필요한 사이즈만큼만 db에서 Product 리스트를 조회해옴 //상품 리스트 반환 } }jpa에서 다(n)쪽에서 fk를 관리하는게 이점이 있다는게 생각남.
애그리거트를 팩토리로 사용하기
- 고객으로부터 여러 차례 신고 당한 상점은 판매 상품을 등록할 수 없다고 해보자
public class Category {
private Set<Product> products;
public List<Product> getProducts(int page, int size) {
List<Product> sortedProducts = sortById(products); //!! 실제 보여줄 데이터가 아니라 전체 데이터를 가져오게 된다.
return sortedProducts.subList((page - 1) * size, page * size);
}
}- 여기서 문제점은 상품을 등록하는 중요한 도메인 기능이 응용 서비스에서 구현되고 있다는 것이다. 그리고 상점이 상품을 등록할 수 있는지 상태를 확인하는 부분과 실제 상품을 등록하는 부분은 논리적으로 하나의 도메인 기능인데 이 부분이 나뉘어져 있다는 것이다.
- 파편화된 논리적인 하나의 도메인 기능을 묶고 애그리거트 내부로 옮기자.
- 도메인의 응집도가 높아져 상품 생성 코드가 변경되어도 응용 서비스는 영향을 받지 않는다.
public class Store { public Produt createProduct(ProductId newProductId, ...) { if (isBlocked()) throw new StoreBlockedException(); return new Product(newProductId, getId(), ...); } }
- 만약 Store 애그리거트가 Product 애그리거트를 생성할 때 많은 정보를 알아야 한다면 Store 애그리거트에서 Product 애그리거트를 직접 생성하지 않고 다른 팩토리에 위임하는 방법도 있다.
// 중요한 도메인 로직은 여전히 도메인에 남게 되고,
// 도메인 로직은 한 곳에 계속 위치한다.
public class Store {
public Produt createProduct(ProductId newProductId, ...) {
if (isBlocked()) throw new StoreBlockedException();
return ProductFactory.create(newProductId, ..);
}
}