이번 프로젝트에서 ELK스택을 도입하기로 하였다.
ELK를 이용하여 우리 서버의 로그들을 수집할 것이고, 우리 서비스의 기능중에 태그를 통한 검색이 있는데 이 부분을 elasticsearch로 더욱 빠르게 해볼 생각이다. 왜 Elasticsearch를 도입했는지 알아보자.
ELK Stack: Elasticsearch의 개발자들이 제공합니다
ELK 스택이란?
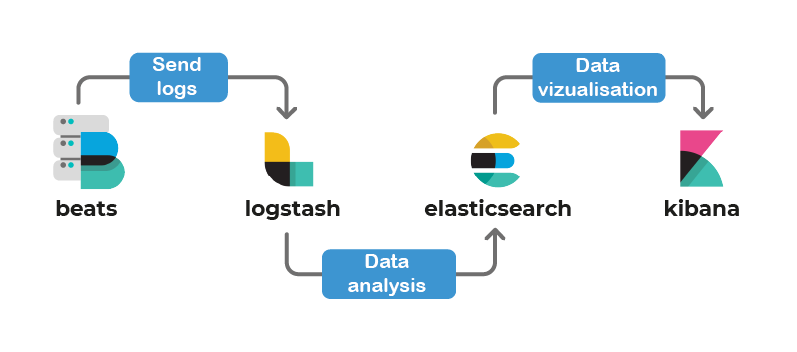
ELK의 스택을 그림으로 나타낸 것이다. 각각의 요소에 대해 간단하게 알아보자.
Elasticsearch
ElasticSearch은 분산형 검색 및 분석 엔진이다. 대용량 데이터를 실시간으로 저장하고 색인화해 빠른 검색과 집계를 제공한다. 데이터는 JSON 문서 형식으로 저장돼 있고, 강력한 검색 쿼리 기능을 갖고 있다.
Logstash
Logstash는 로그 데이터를 다양한 소스에서 수집하고 가공하는 데이터 수집 파이프라인이다. 로그 데이터를 다양한 입력 플러그인을 통해 수집하고, 필터 플러그인을 사용해 데이터를 구문 분석하고 가공하며, 출력 플러그인을 통해 다양한 대상으로 데이터를 전송한다.
Kibana
Kibana는 ElasticSearch에 저장된 데이터를 시각화하고 대시보드를 생성하는 도구이다. 데이터를 탐색하고 집계하며, 다양한 시각화 도구를 사용해 데이터를 시각적으로 분석할 수 있다.
Filebeat
Filebeat는 경량 로그 데이터 수집기이다. 로그 파일이나 위치 기반 데이터 소스로부터 로그 데이터를 수집하고 전송한다. 경량이고 시스템 리소스를 적게 사용해서 대규모 분산 환경에서도 효율적으로 동작한다. 수집된 데이터는 Logstash나 ElasticSearch로 직접 전송할 수 있다.
데이터베이스의 index
찾아보면 Elasticsearch는 Inverted Index방식을 이용한다고 나와있다. Inverted Index란 무엇일까? 그걸 알기전에 먼저 Index에 대해 알아보자.
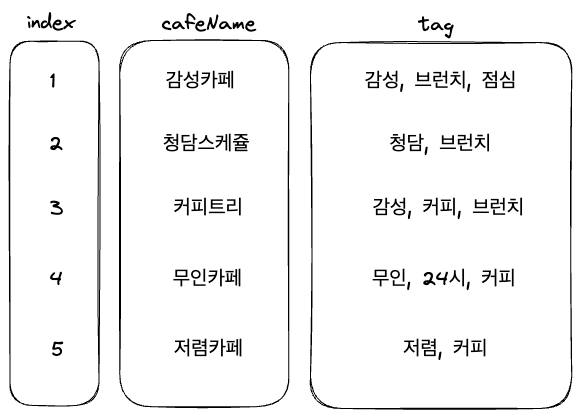
우리가 태그를 일반 데이터 베이스에 저장한다면 따로 처리를 해주지 않은 경우 이렇게 순서대로 ordered index가 생성될 것이다. 여기서 Index는 RDBMS(관계형 데이터베이스 관리 시스템)에서 테이블에 대한 검색 속도를 높여주는 자료 구조를 말하며, 테이블 내에 1개의 컬럼 혹은 여러 개의 컬럼을 이용하여 생성한다.
아니 50의 Index를 가진 데이터를 찾으려면 1번부터 순차적으로 탐색해야하는데, 이는 첫번째 데이터부터 찾아나서는 완전탐색 방식과 다를게 뭐냐? 라고 묻는다면 Index는 B-트리 또는 해시 테이블과 같은 자료구조로 구현되기 때문에 완전탐색으로 순차적으로 모두 탐색하는 것보다 훨씬 빠르게 탐색할 수 있다. 특정 테이블의 컬럼을 인덱싱(Indexing)하면 검색을 할 때 테이블의 레코드를 전부 다 확인하는 것이 아니라 인덱싱 되어있는 자료 구조를 통해서 검색되기 때문에 검색 속도가 빨라지는 것이다. 또한 Index는 빠른 검색 속도뿐만 아니라 레코드 접근에 대한 효율적인 순서 매김 동작에 대한 기초를 제공한다.
Inverted Index

그럼 Inverted Index는 무엇일까? 직역해보면 역 인덱스라고 해석되는데 만약 1번 감성카페의 데이터를 저장할때 태그들을 Index를 걸어서 저장하는 것이다. 만약 또 감성 태그를 가진 가게가 생성된다면 감성이라는 Index에 그 가게가 저장되는 것이다. 이렇게 되면 감성 이라는 태그를 가진 가게들을 가져올때 훨씬 빠른 속도로 가져올 수 있게 된다.
위의 구동 방식만 생각해 보더라도 Elasticsearch는 삽입/삭제 보다 조회에 훨씬 최적화된 검색엔진이라고 생각할 수 있다. Elasticsearch는 대량의 데이터를 효율적으로 검색하고 분석하는 데 특화된 검색 엔진이며, 조회 작업에 대해서는 빠른 응답 시간을 제공하는 경향이 있다. 그러나 데이터의 삽입 작업은 조회 작업보다 상대적으로 더 많은 오버헤드를 가질 수 있다.
이 방식이 우리 서비스의 태그 검색에 적합하다고 판단하였고, ELK스택을 도입하기로 결정하였다.
