
📍 2장
📌 Sec 35 DB 설계
데이터베이스의 구조를 3단계로 나눠볼 수 있다.
외부 단계 (외부 스키마) -> 개념 단계 (개념 스키마) -> 내부 단계 (내부 스키마)
데이터베이스 설계 순서
1) 요구 조건 분석 – 요구 조건 명세서를 작성한다.
2) 개념적 설계 - E-R모델링, 현실 세계를 추상적으로 표현한다.
3) 논리적 설계 - 추상화된 자료를 특정 DBMS에 맞게 논리적 구조로 매핑한다.
4) 물리적 설계 - 논리적 구조로된 데이터를 물리적 구조로 매핑한다.
5) 구현 - DB 스키마 생성한다.
📌 Sec 36 데이터 모델 ( 구조 + 연산 + 제약조건 )
개념적 데이터 모델 – 현실 세계 개념을 추상적 개념으로 표현
논리적 데이터 모델 – 개념적 구조를 논리적 구조로 매핑.
📌 Sec 39 E-R 모델
E-R 모델은 다음와 같은 요소들로 구성된다.
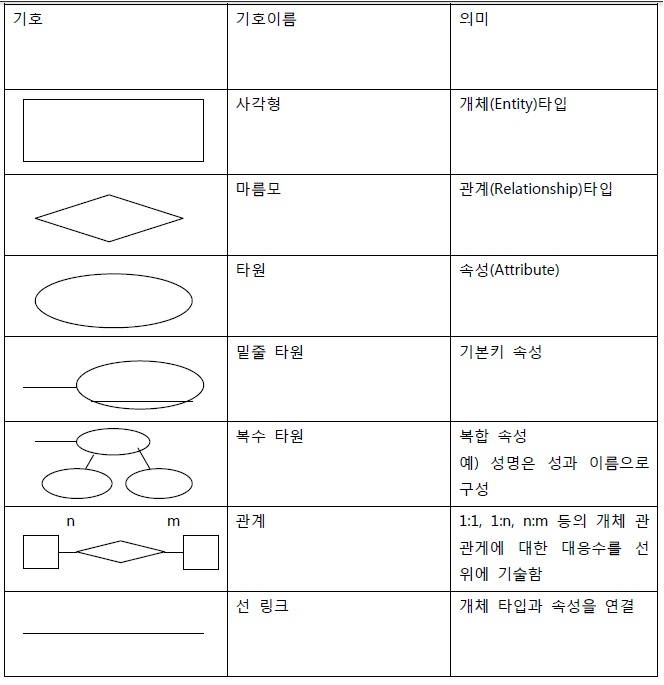
데이터베이스 릴레이션의 구성요소.
속성 – DB를 구성하는 가장 작은 논리적 단위이다.
도메인 – 하나의 속성 값이 취할 수 있는 같은 타입의 원자값들의 집합이다.
📌 Sec xx 키
키의 특성
- 유일성(uniqueness) - 하나의 릴레이션에서 모든 튜플은 서로 다른 키 값을 가져야 한다.
- 최소성(Minimality) - 꼭 필요한 최소한의 속성들로만 키를 구성한다.
키의 종류
슈퍼키 (Super Key) : 유일성을 만족하는 속성 또는 속성들의 집합.
후보키 (Candidate Key) : 유일성과 최소성을 모두 만족하는 속성 또는 속성들의 집합.
기본키 (Primary Key) : 후보키 중에서 기본적으로 사용하기 위해 선택한 키.
대체키 (Alternate Key) : 기본키로 선택되지 못한 후보키.
외래키 (Foreign Key) : 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합.
📌 Sec xx 관계 데이터 모델의 제약
개체 무결성 제약조건
- 기본키는 NULL 값을 가져서는 안 되며, 오직 하나의 값만 존재해야 한다는 조건이다.
참조 무결성 제약조건
- 자식 릴레이션의 외래키는 부모 릴레이션의 기본키와 도메인이 동일해야 하며, 자식 릴레이션의 값이 변경될 때 부모 릴레이션의 제약을 받는다는 조건이다.
도메인 무결성
- 릴레이션의 튜플들은 각 속성의 도메인에 지정된 값만을 가져야 한다는 조건이다.
📌 Sec 45 정규화
테이블을 무손실 분해하여 이상현상(삽입, 삭제, 갱신)의 발생을 줄인다.
- 두부이걸다줘라고 외우면 쉽게 암기할 수 있었다.
1 정규형 - 도 메인이 원자값을 갖는다.
2 정규형 - 부 분적 함수 종속을 제거한다.
3 정규형 - 이 행적 함수 종속을 제거한다.
BCNF - 결 정자이며 후보키가 아닌 것을 제거한다.
4 정규형 - 다 치종속을 제거한다.
5 정규형 - 조 인 종속성을 이용한다.
📌 Sec 46 반정규화
의도적으로 정규화를 위배하며 테이블을 분할 및 통합을 한다.
테이블 통합
- 1:1 관계 테이블 통합
- 1:N 관계 테이블 통합
- 슈퍼타입 / 서브타입 테이블 통합
중복 테이블 추가
- 집계 테이블 추가 - 트리거를 설정해 사용, 중복 속성을 추가한다.
- 조인이 자주 발생할 경우 사용하면 좋다.
📌 Sec 49 트랜잭션 / CRUD 분석
트랜잭션
- 논리적 기능을 수행하기 위한 작업의 단위 또는 수행되어야 할 일련의 연산을 의미한다.
트랜잭션의 특성
A tomicity (원자성) - Commit or Rollback. 즉 완성되던지 아예 안되던지 둘 중 하나이어야 한다.
C onsistency (일관성) - 트랜잭션이 완료되면 일관성 있는 상태로 변환한다.
I solation (독립성) - 트랜잭션 실행 중 끼어들 수 없다.
D urability (영속성) - 트랜잭션이 성공하면 시스템이 고장나도 영구적 반영한다.
CRUD 분석
- 프로세스와 테이블 간 매트릭스를 만들어서 트랜잭션을 분석.
📌 Sec 50 인덱스
데이터에 빠르게 접근하기 위해 <키 값, 포인터> 쌍으로 구성된 데이터 구조.
- 트리 기반 인덱스 – 트리 구조.
- 비트맵 인덱스 – 컬럼의 데이터를 0 or 1로 변환한다.
- 클러스터트 인덱스 – 키의 순서에 따라 데이터가 정렬되어 저장되며, 실제 데이터도 정렬한다.
- 넌클러스터드 인덱스 – 실제 데이터는 정렬 하지않는다. 순서를 유지하기위해 삽입 및 삭제시 재정렬이 발생한다.
📌 Sec 51 뷰 / 클러스터
뷰
- 하나 이상의 테이블로부터 유도된 가상 테이블이다.
클러스터
- 동일한 성격의 데이터를 동일한 데이터 블록에 저장하는 물리적 저장 방법.
📌 Sec 52 파티션
대용량의 테이블 또는 인덱스를 작은 논리적 단위인 파티션으로 나눈다.
범위 분할 – 열의 값을 기준으로 분할한다.
해시 분할 – 해시 함수 값에 따라 분할한다.
조합 분할 – 위 두 특성이 혼합되어있다.
📌 Sec 53 분산 데이터베이스 설계
논리적으로는 하나의 시스템 같아보이지만 물리적으로는 네트워크로 연결된 분산된 데이터베이스를 말한다.
위치 투명성 – 위치를 알 필요 없이 논리적 명칭만으로 액세스 한다.
중복 투명성 – 데이터가 중복 되더라도 마치 하나만 존재하는 것처럼 사용한다.
병행 투명성 – 트랜잭션 동시 실행 가능하다.
장애 투명성 – 네트워크, 트랜잭션 등 장애가 발생해도 정확하게 처리 할 수 있다.
📌 Sec 54 데이터베이스 이중화 / 서버 클러스터링
동일한 DB를 복제하여 관리하는 것을 말한다.
분류
Eager – 트랜잭션 중 데이터 변경이 발생하면 즉시 적용한다.
Lazy – '' 수행이 종료되면 적용한다.
구성 방법
활동 – 대기 방법 : DB1 (활성) DB2 (대기) -> 장애발생 -> DB1(장애) DB2(활성)
활동 – 활동 방법 : DB1 (활성1) DB2 (활성2) -> 장애발생 -> DB1(장애) DB2(활성1,2)
클러스터링
두 대이상의 서버를 하나의 서버처럼 운영하는 기술
고가용성 클러스터링 – 하나의 서버에서 처리하며, 장애 발생시 다른 노드에서 처리 및 중단한다.
병렬처리 클러스터링 – 하나의 작업을 여러 서버에서 분산작업한다..
장애 복구
RTO (목표 복구 시간) - 장애 발생시 복구까지의 소요 시간.
RPO (목표 복구 시점) - 장애 발생시 복구할 기준점.
📌 Sec 55 DB 보안
접근통제
D AC (임의 접근통제) : 사용자의 신원에 따라 접근 권한 부여한다.
M AC (강제 접근통제) : 주체와 객체의 등급 비교 후 권한 부여한다.
R BAC (역할 기반 접근통제) : 사용자의 역할에 따라 권한 부여한다.
📌 Sec 57 스토리지
대용량의 데이터를 저장하기 위해 서버와 저장장치를 연결하는 기술.
DAS (Direct) – 서버와 저장장치를 직접 연결.
NAS (Network) – 서버와 저장장치를 네트워크로 연결
SAN – 둘 다 혼합 되어있다. 전용 네트워크를 구성한다.
📌 Sec 60 자료구조
방향 그래프 최대 간선 수 : n(n-1)
방향이 없을 때 : n(n-1) / 2
📌 Sec 61 트리 (Tree)
근 노드
- 루트 노드
단말 노드
- 끝 노드
디그리 (Degree)
- 각 노드에서 뻗어나온 가지 수.
📌 Sec 63 정렬
합병 정렬, Heap 정렬
- O(n log n)
기수 정렬(자릿 수 별 버킷 활용)
- O(dn)
삽입, 선택, 퀵 등..
- O(n^2)
📍 3장 매우 짧음
📌 Sec 68
XML
- 특수한 목적을 갖는 마크업 언어를 만드는 데 사용되는 다목적 마크업 언어다.
SOAP (심플 오브젝트 액세스 프로토콜)
- 네트워크 상 HTTP/HTTPS 등을 이용해 XML을 교환하기 위한 통신규약이다.
WSDL (웹 서비스 디스크립션 랭기지)
- 웹 서비스 관련 서식 등을 표준적 방법으로 기술하기 위한 언어.
