임베딩이란?
임베딩이란 자연어처리에서 사람이 쓰는 자연어를 기계가 이해할 수 있도록 숫자형태인 vector로 바꾸는 과정 혹은 일련의 전체 과정을 의미합니다.
단어나 문장 각각을 벡터로 변환해 벡터 공간(Vector space)으로 끼워넣는다는 의미에서 임베딩이라고 합니다.
가장 간단한 형태의 임베딩은 단어의 빈도를 기준으로 벡터로 변환하는 것입니다.
| 구분 | 메밀꽃 필 무렵 | 운수 좋은 날 | 사랑 손님과 어머니 | 삼포 가는 길 |
|---|---|---|---|---|
| 기차 | 0 | 2 | 10 | 7 |
| 막걸리 | 0 | 1 | 0 | 0 |
| 선술집 | 0 | 1 | 0 | 0 |
위의 표에서 운수좋은 날이라는 문서의 임베딩은 [2, 1, 1]입니다. 막걸리라는 단어의 임베딩은 [0, 1, 0, 0]이며, 사랑 손님과 어머니, 삼포 가는 길이 사용하는 단어 목록이 상대적으로 많이 겹치고 있는 것을 알 수 있습니다.
위의 Matrix를 바탕으로 우리는 사랑 손님과 어머니는 삼포 가는 길과 기차라는 소재를 공유한다는 점에서 비슷한 작품일 것이라는 추정을 해볼 수 있습니다. 또한 막걸리라는 단어와 선술집이라는 단어가 운수 좋은 날이라는 작품에만 등장하는 것 역시 알 수 있습니다.
막걸리-선술집 간 의미 차이가 막걸리 기차 보다 작을 것이라고 추정해 볼 수 있을 것 입니다.
임베딩의 역할
임베딩의 역할에는 크게 3가지가 존재합니다.
- 단어/문장 간 관련도 계산
- 의미적/문법적 정보 함축
- 전이 학습
1. 단어/문장 간 관련도 계산
단어-문서 행렬은 가장 단순한 형태의 임베딩입니다.
현업에서는 이보다 복잡한 형태의 임베딩을 사용하는데요. 대표적인 임베딩 기법은 Word2Vec을 뽑을 수 있습니다. 이렇듯 컴퓨터가 계산하기 쉽도록 단어를 전체 단어들간의 관계에 맞춰 해당 단어의 특성을 갖는 벡터로 바꾸면 단어들 사이의 유사도를 계산하는 일이 가능해집니다.
자연어일 때 불가능했던 유사도를 계산할 수코사인 유사도 계산이 임베딩 덕분에 가능해지며, 또한 임베딩을 수행하면 벡터 공간을 기하학적으로 나타낸 시각화 역시 가능하게 됩니다.
2. 의미적/문법적 정보 함축
임베딩은 벡터인 만큼 사칙 연산이 가능합니다.
단어 벡터 간 덧셈/뺄셈을 통해 단어들 사이의 의미적, 문법적 관계를 도출해낼 수 있습니다.
예를들면, 아들 - 딸 + 소녀 = 소년이 성립하면 성공적인 임베딩이라고 볼 수 있는데요. 아들 - 딸 사이의 관계와 소년 - 소녀 사이의 의미 차이가 임베딩에 함축돼 있으면 품질이 좋은 임베딩이라 말할 수 있다는 이야기 입니다.
이렇게 단어 임베딩을 평가하는 방법을 단어 유추 평가(word analogy test)라고 부릅니다.
3. 전이 학습
품질 좋은 임베딩은 모형의 성능과 모형의 수렴속도가 빨라지는데 이런 품질 좋은 임베딩을 다른 딥러닝 모델의 입력값으로 사용하는 것을 transfer learning(전이학습)이라 합니다.
예를 들면, 대규모 Corpus를 활용해 임베딩을 미리 만들어 놓는것 입니다. 임베딩에는 의미적, 문법적 정보 등이 녹아 있습니다. 이 임베딩을 입력값으로 쓰는 전이 학습 모델은 문서 분류라는 업무를 빠르게 잘 할 수 있게 되는 것입니다.
임베딩 기법 역사와 종류
임베딩 기법의 발전과 흐름은 크게 4가지의 변화가 있었습니다.
1.통계 기반에서 뉴럴 네트워크 기반으로
2. 단어 수준에서 문장 수준으로
3. Rule based -> End to End -> Pre-training/fine tuning
4. 임베딩의 종류와 성능
1. 통계 기반에서 뉴럴 네크워크 기반으로
- 통계 기반 기법
잠재 의미 분석(Latent Semantic Analysis)은 단어 사용 빈도 등 Corpus의 통계량 정보가 들어 있는 행렬에 특이값 분해등 수학적 기법을 적용해 행렬에 속한 벡터들의 차원을 축소하는 방법입니다.
차원을 축소하는 이유는 Term-Document matrix 경우는 row가 더 큰 sparse matrix일 확률이 높기 때문에 쓸데 없이 계산량과 메모리자원을 낭비하는 것을 예방하기 위해서 입니다. 여기서 차원 축소를 통해 얻은 행렬을 기존의 행렬과 비교했을 때 단어를 기준으로 했다면 단어 수준 임베딩, 문서를 기준으로 했다면 문서 임베딩이 됩니다.
잠재 의미 분석 수행 대상 행렬은 여러 종류가 될 수 있으며,
Term-Document Matrix, TF-IDF Matrix, Word-Context Matrix, PMI Matrix등이 있습니다.
- 뉴럴 네트워크 기반 기법
Neural Network는 구조가 유연하고 표현력이 풍부하기 때문에 자연어의 무한한 문맥을 상당 부분 학습할 수 있습니다.
2. 단어 수준에서 문장 수준으로
- 단어 수준 임베딩 기법
각각의 벡터에 해당 단어의 문맥적 의미를 함축하지만, 단어의 형태가 동일하다면 동일단어로 인식하고, 모든 문맥 정보를 해당 단어 벡터 투영하므로 동음이의어를 분간하기 어렵다는 단점이 있습니다.
ex) NPLM, Word2Vec, GloVe, FastText, Swivel 등
- 문장 수준 임베딩 기법
2018년 초에 ELMo(Embedding from Language Models)가 발표된 이후 주목 받기 시작했습니다.
개별 단어가 아닌 단어 Sequence 전체의 문맥적 의미를 함축 하기 때문에 단어 임베딩 기법보다 Transfer learning 효과가 좋은 것으로 알려져 있습니다.
또한, 단어 수준 임베딩의 단점인 동음이의어도 문장수준 임베딩 기법을 사용하면 분리해서 이해할 수 있습니다.
ex) BERT(Bidirectional Encoder Representations from Transformer), GPT(Generation Pre-Training) 등
3. Rule based -> End to End -> Pre-training/fine tuning
1990년대에는 자연어 처리 모델 대부분은 우리가 딥러닝과 달리 머신러닝처럼 사람이 Feature를 직접 뽑았습니다. 그렇기에 Feature를 추출할 때 언어학적인 지식을 활용해야 했습니다.
그러나 2000년대 중반 이후 NLP 분야에서도 딥러닝 모델이 주목받기 시작하여 Feature를 직접 뽑지 않아도 되었습니다. 데이터를 넣어주면 사람의 개입 없이 모델 스스로 처음부터 끝까지 이해하는 End-to-End Model 기법을 사용하였기 때문 입니다.
대표적으로는 기계번역에 널리 사용됐던 Sequence-to-Sequence 모델이 있으며, 2018년 ELMo 모델이 제안된 이후 NLP 모델은 pre-training과 fine tuning 방식으로 발전하고 있습니다.
우선 대규모 Corpus로 임베딩을 만들고(Pre-train) 이 임베딩에는 Corpus의 의미적, 문법적 맥락이 포함돼 있습니다. 이후 임베딩을 입력으로 하는 새로운 딥러닝 모델을 만들어 우리가 풀고 싶은 구체적 문제에 맞는 소규모 데이터에 맞게 임베딩을 포함한 모델 전체를 업데이트 합니다.(fine tuning)
ELMo, GPT, BERT등이 이 방식에 해당됩니다.
우리가 풀고 싶은 자연어 처리의 구체적 문제들(예시 : 품사 판별(Part-Of-Speech tagging), 개체명 인식(Named Entity Recognition), 의미역 분석(Semantic Role Labeling))을 다운 스트림 태스크(DownStream task)라고 합니다. 다운스트림에 앞서 해결해야 할 과제라는 뜻의 업스트림 테스크(UpStream task)는 단어/문장 임베딩을 Pre-train하는 작업이 해당된됩니다.
임베딩 종류와 성능
임베딩의 종류는 크게 3가지가 존재합니다.
- 행렬 분해
- 예측 기반
- 토픽 기반
1. 행렬 분해
말뭉치 정보가 들어 있는 원래 행렬을 두 개 이상의 작은 행렬로 쪼개는 방식의 임베딩 기법을 의미
Corpus 정보가 들어 있는 원래 행렬을 Decomposition을 통해 임베딩하는 기법입니다.
Decomposition 이후엔 둘 중 하나의 행렬만 사용하거나 둘을 sum하거나 concatenate하는 방식으로 임베딩을 하게 됩니다.
ex) GloVe, Swivel 등
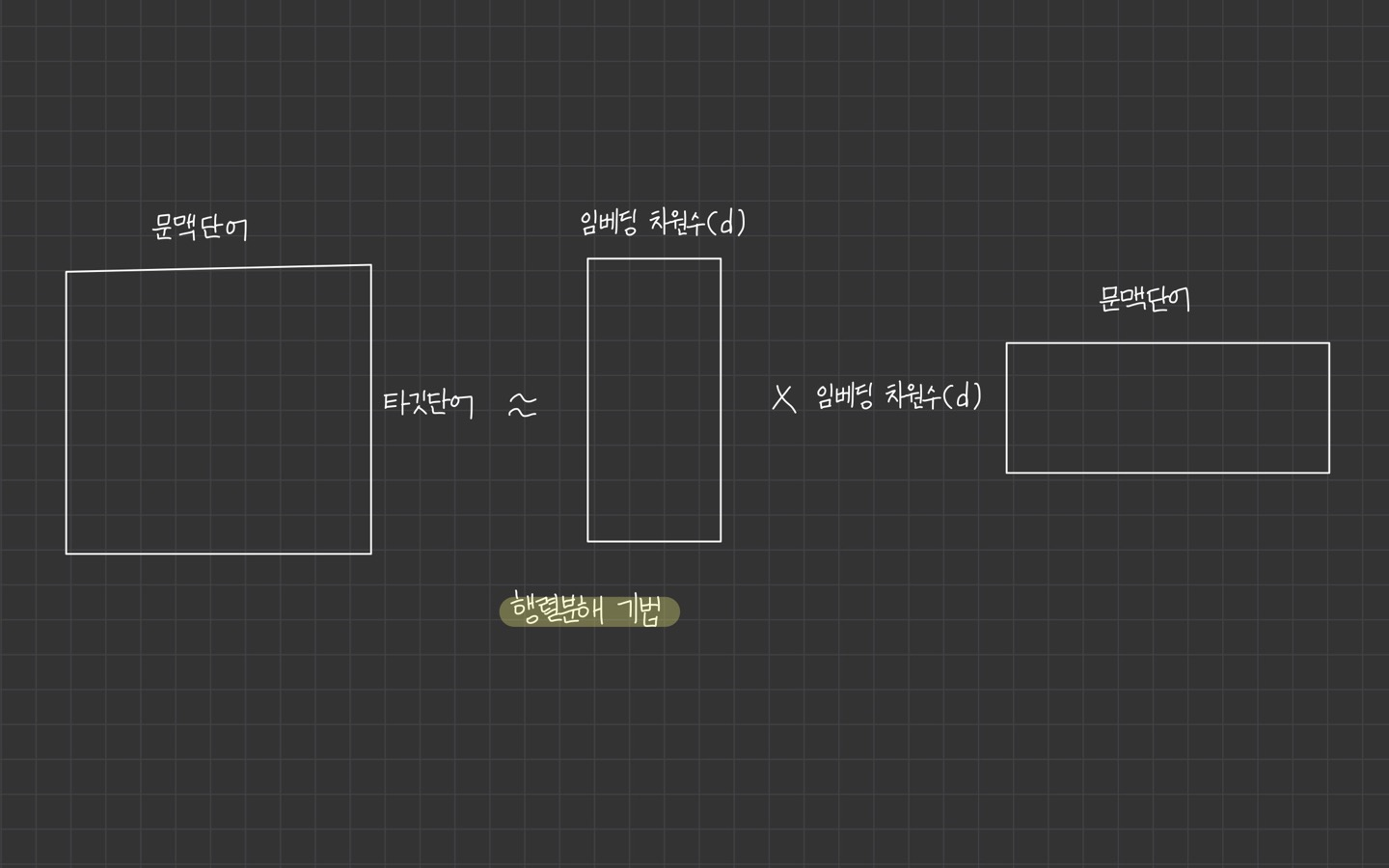
출처: https://velog.io/@cha-suyeon/NLP-임베딩Imbedding
2. 예측 기반
어떤 단어 주변에 특정 단어가 나타날지 예측하거나, 이전 단어들이 주어졌을 때 다음 단어가 무엇일지 예측하거나, 문장 내 일부 단어를 지우고 해당 단어가 무엇일지 맞추는 과정에서 학습하는 방법
Neural Network기반 방법들이 속합니다.
ex) Word2Vec, FastText, BERT, ELMo, GPT 등
3. 토픽 기반
주어진 문서에 잠재된 주제를 추론하는 방식으로 임베딩을 수행하는 기법
대표적으로 잠재 디리클레 할당(LDA)가 있습니다. LDA 같은 모델은 학습이 완료되면 각 문서가 어떤 주제 분포를 갖는지 확률 벡터 형태로 반환하기 때문에 임베딩 기법의 일종으로 이해할 수 있습니다.
용어정리
-
말뭉치(Corpus) : 임베딩 학습이라는 특정한 목적을 가지고 수집한 표본(sample)
-
컬렉션(Collection): 말뭉치에 속한 각각의 집합
-
문장(sentence): 데이터의 기본 단위
생각이나 감정을 말과 글로 표현할 때 완결된 내용을 나타내는 최소의 독립적인 형식 단위 -
문서(Document): 생각이나 감정, 정보를 공유하는 문서 집합 (단락(paragraph))
-
토큰(token): 텍스트 데이터의 가장 작은 단위
때때로 단어(word), 형태소(morpheme), 서브워드(subword)라고 부름.
토큰 분리 기준은 오픈소스 형태소 분석기에 따라 다르며예 Mecan, Kkma 등이 있다. -
토크나이즈(tokenize): 문장을 이처럼 토큰 시퀀스로 분석하는 과정
-
형태소 분석(morphhological analysis): 문장을 형태소 시퀀스로 나누는 과정.
한국어는 토큰화와 품사 판별(Part Of Speech Tagging)이 밀접한 관계를 가짐. -
어휘 집합(Vocabulary)는 말뭉치에 있는 모든 문서를 문장으로 나누고 여기에 토크나이즈를 실시한 후 중복을 제거한 토큰들의 집합
-
미등록 단어(unknown word): 어휘 집합에 없는 토큰
