Attention이란?
Decoder에서 출력 단어를 예측하는 시점마다 Encoder에서의 전체 입력 문장을 다시 한번 참고하는 것으로 예측하는 단어와 연관이 있는 단어를 좀 더 집중(Attention)하여 보는 것을 뜻합니다.
Attention의 특징
- Bottleneck 현상 해결
기존 Seq2Seq Model에서 Encoder의 마지막 Time Step의 Hidden State Vector만 활용할 경우 초기 정보가 손실 되는 문제가 발생하였습니다.
이러한 문제를 해결하기 위해 Attention이 등장하게 되었고, Encoder의 모든 Hidden state vector를 구해 Decoder 연산에 활용하게 됩니다.
- Gradient Vanishing 문제 해결
전체 과정을 순차적으로 지나며 학습을 거치는 것이 아니라, Attention Score를 통해 연산한 Attention Output값만을 활용해 학습이 진행되기 때문에 Time Step을 거치지 않고 빠르게 값을 전달해 줄 수 있게 됩니다.
Attention 작동 과정
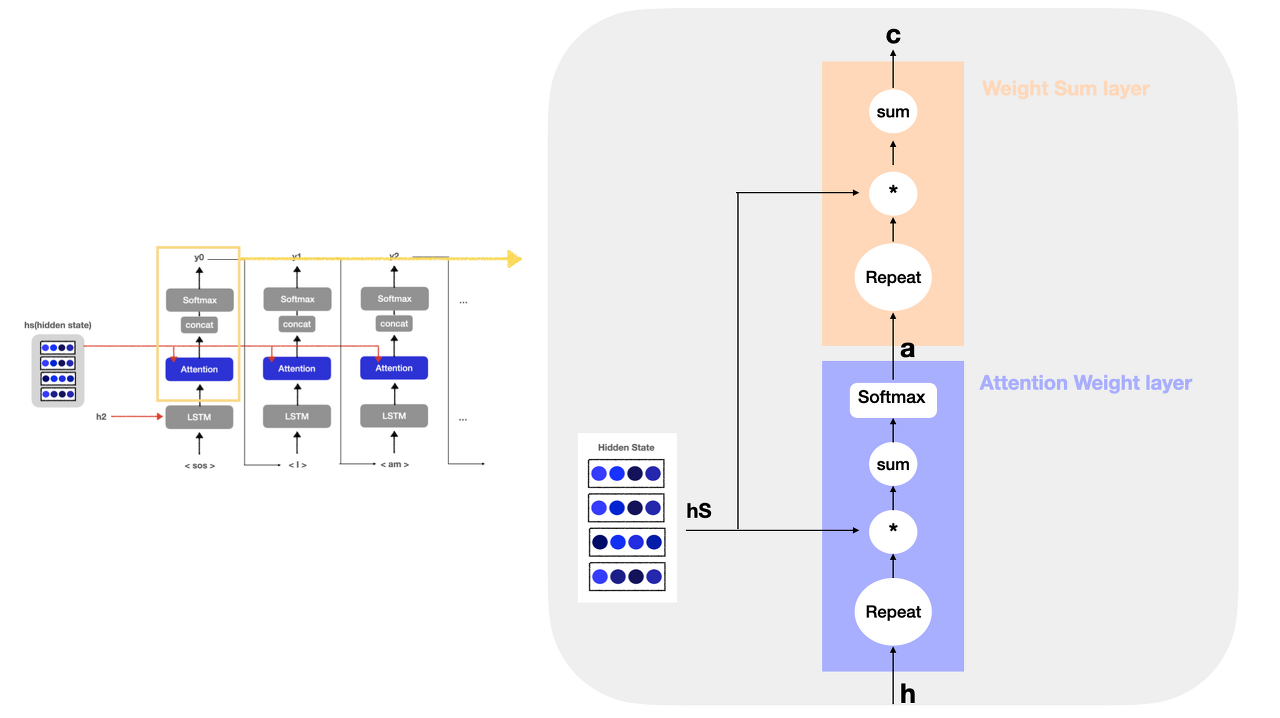
HS = Encoder에서 매 시각별 hidden state vector를 모두 모은 행렬
H = Decoder에서 건네 받은 HS와 현재 시점의 입력값으로 받아 출력되는 hidden state vector의 행렬
A = alignment 즉, 단어의 대응 관계를 나타내는 정보
C = 맥락 벡터 (Context Vector)
-
Encoder가 매 시점마다 출력하는 모든 Hidden State를 모은 "HS"에서 어떤 은닉 상태에 'Attention'해야 하는지 알기 위해 즉, 각 단어의 가중치 "A"를 알기위해 Decoder에 전달된 최종 hidden state vector "H"와 "HS"의 각 단어 백터를 내적하여 유사도를 산출 합니다.
-
"HS"와 "H" 벡터간의 유사도를 구해 "A"를 산출하게 됩니다.
-
이어서 "HS"와 산출된 "A"를 행렬곱 연산하여 추론에 가장 기여할 만한 맥락벡터 "C"를 산출하게 됩니다.
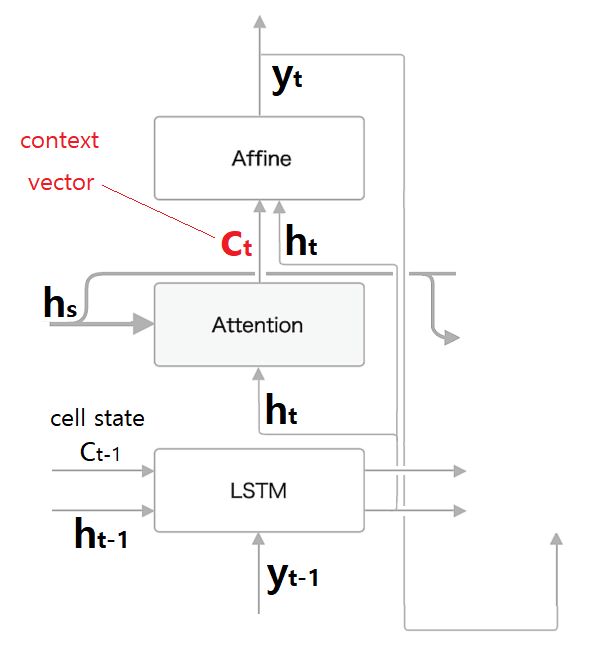
- 다시 "C"는 "H"와 연결되어 각 시점 디코더의 출력 "Y"가 되고 다시 "Y"는 매번 다음 시점의 입력값이 되어 "H"로 출력되고 위 과정을 반복하는 과정을 거치게 됩니다.
Self-Attention
단어 간의 관계성 연산 결과를 활용하여 연관성 높은 단어끼리 연결해주기 위해 활용하는 것으로 Attention과 비슷하지만 몇 가지 차이가 존재합니다.
1. Q, K, V 생성
-
Attention의 Q는 Decoder 셀에서, K, V는 Encoder 셀에거 도출 됩니다.
-
Self-Attention의 Q,K,V 모두 동일한 Embedding Vector에서 도출 됩니다.
2. Time Step
-
Attention은 이전 Layer에서 반환된 hidden state vector를 활용하는 만큼 Time-step이 필요한 연산입니다.
-
Self-Attention은 단어 한 개에 대해 모든 단어의 대하여 Attention Score를 구하므로 이전 연산이 현재 단어 연산에 영향을 끼치지 못하기 때문에 Time-step이 의미가 없게 됩니다.
3. Long-term Dependency (데이터 보존)
-
Attention은 hidden layer 연산 결과(hidden state vector)를 다음 Layer에 적용 시키는 방식으로 이전 단어의 정보를 전달합니다.
즉, attention은 hidden layer가 쌓여감에 따라 초기 해석 정보가 어쩔수 없이 사라지게 됩니다. -
Self-Attention은 Encoder는 모든 단어에 대해 / Decoder는 직전 예측 단어에 대해 Q(hidden vector)를 구하여 해당 값을 활용합니다.
이전 해석 정보에 대한 hidden state vector를 보존해 Self-attention 연산을 통해 각 단어에 대한 온전한 연산이 수행하게 되어 초기 정보가 온전히 반영될 수 있게 됩니다.
4. 방향성
-
Attention은 좌 -> 우 or 우 -> 좌로 일방향적으로 해석이 진행되는 Unidirectional한 모델입니다.
다시 말하자면, RNN 계열로 이전 단어를 예측하면서 나온 hidden state vector를 활용해 현재 단어를 예측하기 때문에 방향성이 존재하게 됩니다. -
Self-Attention의 Encoder는 현재 단어의 양쪽에 있는 모든 단어에 대하여 연산이 진행되기 때문에 방향성 개념이 상대적으로 적습니다. 그래서 Bidirectional한 모델이라고 말할 수 있습니다.
정리하자면 Attention은 RNN의 특징으로 방향이 정해졌을 때, 자신보다 미래에 input값으로 들어갈 단어들은 활용하지 못하지만,
Self-Attention은 모든 단어와 동시에 Attention 연산이 일어나기 때문에 방향성과는 상관없이 문장 내 모든 단어를 활용하여 연산이 진행되게 됩니다.
self-attention에서의 vector 처리 순서
-
input 단어들을 활용해 embedding vector를 도출
-
embedding vector를 활용해 Q,K,V vector 생성
-
Q,K,V를 활용해 attention_score를 계산
-
attention_Score를 로 변환
(연산 결과 값이 루트에 씌워 표준편차를 1로 만들어줌/softmax연산에 영향을 주지 않기 위해서) -
나눠준 모든 값을 Softmax 함수에 통과
-
5번 연산 결과값들을 V벡터와 곱셈
(곱셈을 통해 관련 있는 단어를 살리고, 관련 없는 단어를 제거하기 위함)
7.6번 연산 결과값들을 모두 더해 나오는 vector가 해당 단어의 self-attention을 거친 이후 반환할 self-attention layer의 출력값으로 변환
