Distributed Representations of Words and Phrases and their Compositionality(2013) 논문 읽기②
4. Learning Phrases
앞서 논의한 바와 같이, 많은 구(Phrase)들은 개별적인 단어들의 결합으로 얻어질 수 없는 의미를 가지고 있다.
Phrase에 대한 vector표현을 학습하기 위해서 본 논문에서는 먼저 함께 자주 등장하지만 다른 맥락에서는 자주 나타나지 않는 단어쌍을 찾았다.
가령 'New York Times", "Toront Maple Leafs"는 training data에서 unique한 토큰으로 대체되는 반면 "this is"와 같은 구는 그대로 남겨 두었다.
이러한 방법은 어휘의 크기를 크게 키우지 않으면서도 많은 reasonable phrases를 얻을 수 있게 해주었다.
이론적으로 Skip-gram model은 모든 n-gram에 대하여 훈련 할 수 있겠지만, 과도한 메모리 부하를 가져올 것이다.
phrases를 text에서 구분하기 위한 많은 기술들은 이전에 개발되었지만, 이를 비교하는 것은 논문의 작업의 범위를 넘어서게 된다.
따라서 본 논문에서는 data-driven approach를 대신 이용하여 uni-gram과 bi-gram을 이용하여 다음과 같은 점수를 이용하였다.
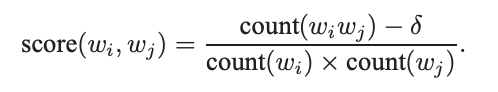
δ는 할인 계수로 사용되며 자주 사용되지 않는 단어로 너무 많은 구문이 형성되는 것을 방지합니다.
threshold를 넘어선 score를 가진 bi-gram이 선택되고 그것은 phrase로 사용되게 된다.
전형적으로 2-4 pass를 넘어서면 threshold를 감소시켜 더 긴 Phrase를 형성 할 수 있게 해주었다. 이렇게 만들어진 Phrase에 대한 실험 결과는 다음의 표와 같다.
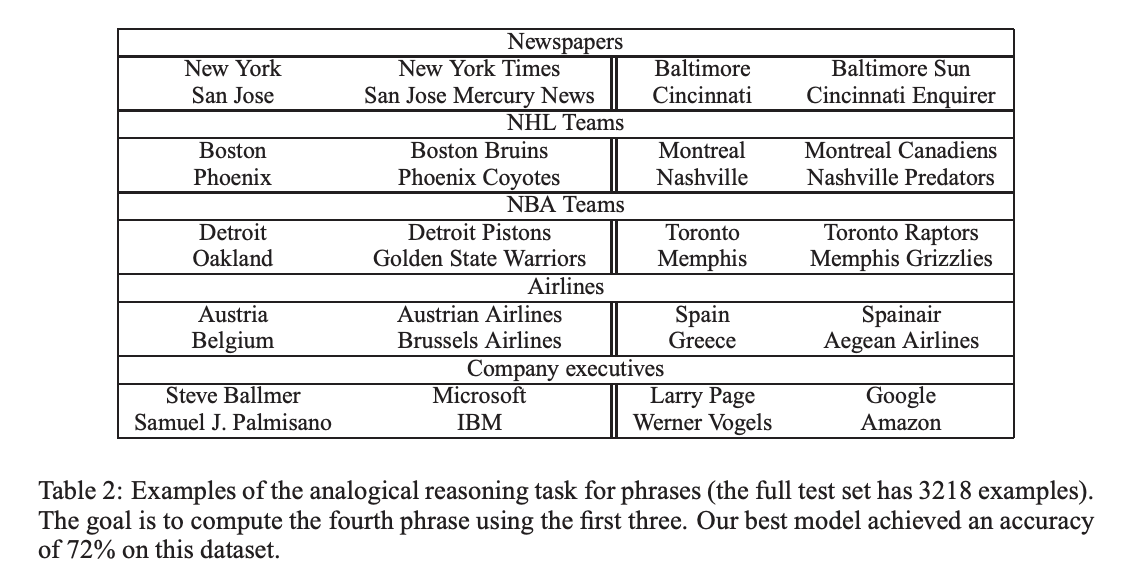
4-1. Phrase Skip-Gram Results
이전 실험과 동일한 뉴스 데이터로 시작하여, 먼저 phrase기반의 training corpus를 구성하였고, hyper parameter를 바꿔가며 Skip-gram 모델을 훈련하였다. 이때 vector의 차원은 300, context size는 5를 사용하였다.
이 setting은 이미 이전에 좋은 성능을 보여주었으며, 빈번한 단어에 대한 subsampling의 여부와 관계 없이 Negetive sampling과 Hierarchical softmax를 빠르게 비교하게 해주었다. 결과는 아래에 정리되어 있다.
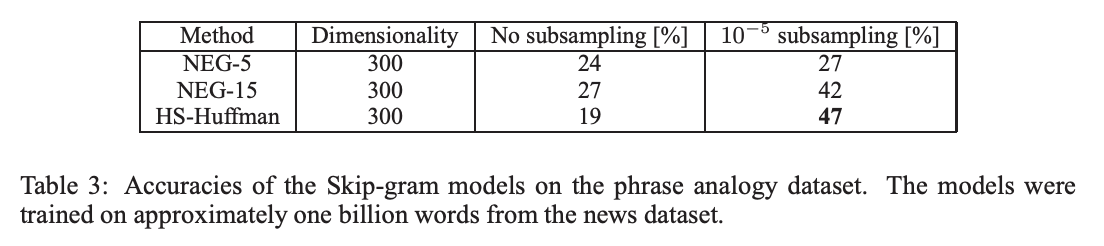
Negetive sampling이 k = 5에서도 상당한 정확도를 달성하지만, k = 15를 사용하면 훨씬 더 나은 성능을 달성한다는 것을 보여준다.
놀랍게도 Hierarchical Softmax는 subsampling을 사용하지 않았을 때 더욱 낮은 결과를 보여주었으며, 최상의 결과는 빈번하게 사용하는 단어에 대하여 downsampling을 하였을 때 나타났다.
이것은 subsampling이 더욱 빠르면서 정확한 결과를 보여줄 수 있음을 시사하고 있다.
phrase analogy task(구문 유추 작업)의 정확성을 극대화하기 위해 약 330억 개의 단어가 있는 데이터 세트를 사용하여 훈련 데이터의 양을 증가시켰다.
hierarchical sotfmax를 사용하였으며, 차원의 수는 1000과 entire sentence for the context(문장의 전체 맥락정보)를 모두 이용하였다.
이를 통해 모델의 정확도가 72%에 도달했다.
훈련 데이터 세트의 크기를 60억개의 단어로 줄였을 때 66%의 더 낮은 정확도를 달성했는데, 이는 많은 양의 훈련 데이터가 중요하다는 것을 시사한다.
모델마다 학습된 표현이 얼마나 다른지에 대한 추가적인 통찰력을 얻기 위해 다양한 모델을 사용하여 자주 사용되지 않는 구문의 가장 가까운 이웃에 대한 정보를 수동으로 검사했으며, 샘플은 아래에 있다.

이전의 결과들과 일관적으로 가장 좋은 결과를 보이는 것은 subsamping을 수행한 Hierarchical Softmax였다.
5. Additive Compositionality
본 논문에서는 Skip-gram을 이용한 단어나 구에 대한 표현이 단순한 벡터의 구조를 가지고도 analogical reasoning에서 정확한 성능을 보일 수 있는 선형 구조를 나타낸다는 것을 입증 했다.
흥미롭게도, Skip-gram의 표현은 의미있는 요소들의 결합을 벡터의 합으로 표현할 수 있음을 보여주고 있다. 이러한 현상은 아래에 표현되어 있다.

벡터의 부가적인 특성은 training의 objective를 관찰하면 설명될 수 있다. word vector은 비선형적인 softmax의 input를 포함하며 선형적인 관계를 가지고 있다.
word vector들이 문장에서 주변 단어들을 예측하도록 훈련되기 때문에, 벡터들은 단어가 나타나는 문맥의 분포를 나타내는 것으로 볼 수 있다.
이러한 값은 output layer의 결과와 로그연산으로 관련되어 있음으로, 두 단어의 합은 두 단어가 표현하는 context의 곱과 관련되어 있다. 곱셈(Product)는 여기서 AND연산으로 동작하게 되고, 두 단어 벡터에 의해 높은 확률이 할당된 단어는 높은 확률을 가지며, 다른 단어는 낮은 확률을 가집니다.
따라서 "Volga River"가 "Russian"과 "river"라는 단어와 함께 같은 문장에서 자주 나타난다면, 이 두 단어 벡터의 합은 "Volga River"의 벡터에 가까운 특징 벡터를 만들게 됩니다.
6. Comparison to Published Word Representations
신경망 기반의 단어 표현은 많은 연구자들에 의하여 연구되었고 그 결과가 이미 공개되어 있다.
이미 다른 연구들과 Skip-gram모델의 결과를 word analogy task와 비교하여 평가를 해놓았다
학습된 vector의 quality의 다름에 대한 통찰을 얻기 위하여, 아래에서, 자주 사용되지 않은 word의 인접한 이웃들에 대한 실험적인 비굣를 보여주고 있다.
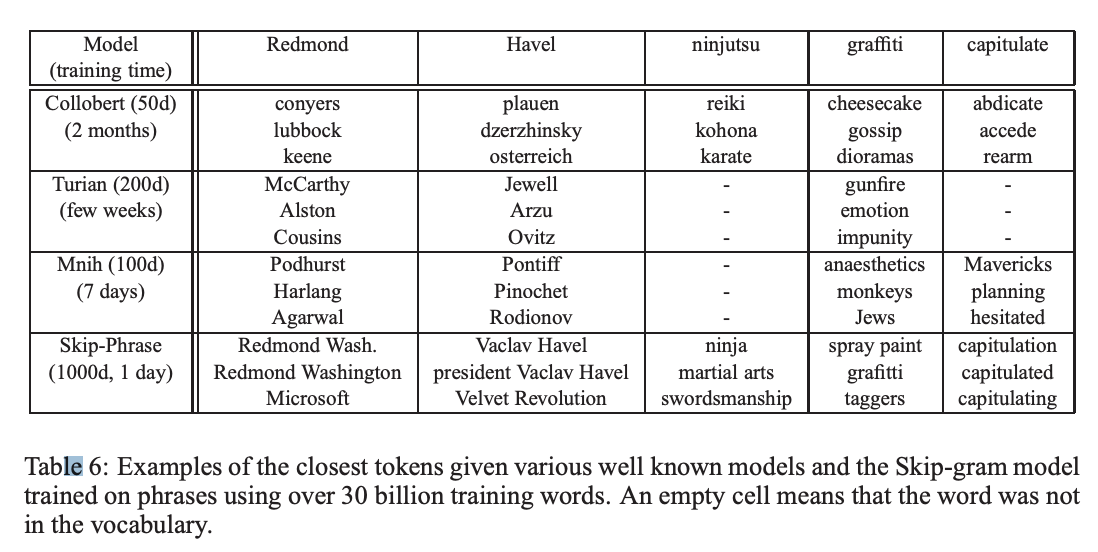
큰 말뭉치에 대해 훈련된 big Skip-gram 모델이 학습한 표현의 품질이 다른 모든 모델에 비해 눈에 띄게 능가한다는 것을 보여준다.
이는 부분적으로 이 모델이 이전 작업에 사용된 일반적인 크기보다 약 2~3배 많은 데이터인 약 300억 단어에 대해 훈련되었다는 사실에 기인할 수 있다.
놀랍게도 학습 데이터가 큼에도 불구하고 Skip-gram 모델의 훈련 시간은 이전의 모델들보다 더 빨랐다.
7. Conclusion
Skip-gram 모델에 대하여 단어와 구에 대한 분산적인 표현의 훈련의 방법을 보여주고, 이러한 표현이 정밀한 유추가 가능한 선형 구조를 나타낸다는 것을 보여주며, 이러한 방법은 CBOW모델의 훈련에도 사용될 수 있다.
계산적으로 효율적인 모델 아키텍처 덕분에 이전에 발표된 모델보다 몇 배 더 많은 데이터에 대해 모델을 성공적으로 학습했다.
이는 특히 희귀한 entities에 대해 학습된 단어와 구 표현의 품질을 크게 향상시킨다.
또한 자주 등장하는 단어에 대한 subsampling이 빠른 학습 속도와 드물게 등장하는 단어에 대해 훨씬 더 잘 표현하는 것을 발견하였다.
본 논문의 또 다른 기여는 매우 간단한 Negative sampling을 이용하여 자주 등장하는 단어들에 대해 정확한 표현을 학습하는 간단한 학습 방법이다.
서로 다른 Task가 서로 다른 최적의 hyper-parameter 구성을 갖는다는 것을 발견했기 때문에 훈련 알고리듬과 hyper-parameter 선택은 task별로 결정해야한다.
우리의 실험에서 성능에 영향을 미치는 가장 중요한 결정은 모델의 구조, vector의 크기, subsampling의 비율, window의 크기이다.
이 task의 매우 흥미로운 결과는 word vector가 단순한 벡터 덧셈(+)을 사용하여 의미 있게 결합될 수 있다는 것이다.
본 논문에서 제시된 문구의 표현을 학습하기 위한 또 다른 접근법은 단일 토큰으로 구(phrases)를 단순히 표현하는 것이다.
두 가지 접근 방식의 조합은 계산 복잡성을 최소화하면서 더 긴 텍스트 조각을 표현하는 방법을 강력하면서도 간단한 방법을 제공한다.
따라서 우리의 작업은 재귀 행렬 벡터 연산을 사용하여 구문을 표현하려는 기존 접근 방식을 보완하는 것으로 볼 수 있다.
전체 요약
기존 Original Skip-gram의 개선을 위해 즉, vector representation quality를 높이기 위해 아래와 같은 제안을 한다.
-
기존의 구(phrases)에 대해 학습하지 못하는 문제를 Word 대신에 각 Phrase들을 하나의 토큰으로 분리하고 그것이 phrase인지 또는 단순한 단어의 조합인지(an apple처럼 의미 없는)를 구별해내도록 만들었다.
-
빈도수가 높은 단어를 Sub-sampling함으로 훈련 속도를 2 ~ 10배 가량 증가시키며 더불어, 빈도수가 적은 단어들의 표현에 대한 정확도를 높일 수 있었다.
-
vector representation의 quality를 높이기 위해 계층적 Softmax 대신에 Noise Contrastive Estimation(NCE)를 단순화 시킨 Negative Sampling(NEG)방식을 제안했다.
- 단순한 Vector의 덧셈(+)을 통해 의미 있는 결과를 만들어낼 수 있음을 확인 했다. 예를 들자면, vector(Russia) + vector(river)은 vector(Volga River)과 가까웠고, vector(Germany) + vector(capital)은 vector(Berlin)과 가까웠다.
