Fine-grained Post-training for Improving Retrieval-based Dialogue Systems(2021) 논문 읽기②
4. Experiments
4-1. Datasets
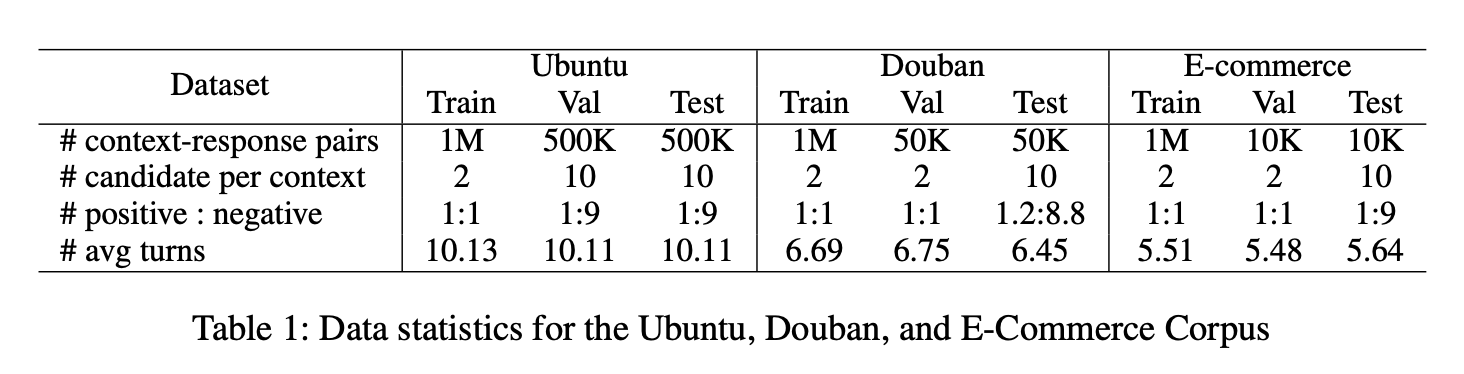
본 논문에서는 Ubuntu Corpus V1, Douban Corpus 및 E-commerce Corpus를 포함하여 널리 사용되는 벤치마크에서 모델을 테스트했다. 세 개의 데이터 세트에 대한 통계는 아래에 제시되어 있다.
-
Ubuntu Corpus
Ubuntu IRC Corpus V1(Lowe et al., 2015)은 공개적으로 사용 가능한 도메인별 대화 데이터 세트인 채팅 로그 대화이다. 이 대화 자료는 우분투 관련 주제를 다룬다. 본 연구에서는 Xu이 제안한 데이터를 사용한다. 데이터는 숫자, URL 및 시스템 경로와 같은 특수한 자리 표시자로 미리 처리된다.
-
Douban Corpus
Douban Corpus는 인기 있는 소셜 네트워킹 서비스인 Douban 그룹의 중국 오픈 도메인 데이터 세트이다. 두 사람 사이의 대화로 구성된다. -
E-commerce Corpus
전자상거래 코퍼스는 중국 최대 전자상거래 플랫폼인 타오바오(Taobao)에서 수집한 중국의 멀티턴 대화체이다. 여기에는 고객과 고객 서비스 직원 간의 실제 대화가 포함되어 있다. 말뭉치는 상담, 추천 등 다양한 대화로 구성된다.
4-2. Post-training Data
fine-grained post-training를 위해 3가지 벤치마크 데이터셋을 재구성하였다.
구체적으로, 각 벤치마크의 훈련 세트에 있는 100만 개의 3가지 종류 중에서, 본 연구는 50만 개의 3가지 positive 대화 세션으로 사용했다.
하나의 대화 세션에서 여러 개의 short context-response 쌍을 만들 수 있었기 때문에, 결국 Ubuntu Corpus, Douban Corpus, E-commerce Corpus에 각각 12M, 9M, 6M의 sub context-response 쌍을 구성했다.
이러한 sub context-response 쌍은 post- training되었다
4-3. Evaluation Metric
본 연구에서 평가지표는 Recall을 사용했다. R10@k로 표시되며, 이는 10개의 후보 응답 중 상위 k개의 후보 사이에 정답이 존재함을 의미한다.
구체적으로, 실험에서는 R10 @1, R10 @2, 및 R10 @5를 사용하였다.
R10@k와는 별도로, 데이터 세트의 정답 후보 중 긍정적인 응답이 둘 이상 포함할 수 있기 때문에 Douban Corpus에 MAP(평균 정밀도), MRR(평균 상호 순위) 및 P@1(정밀도)을 사용했다.
4-4. Baseline Methods
본 논문에서는 fine-grained post-training 모델인 BERT-FP를 이전 모델과 비교했으며, 초기 checkpoint를 위해 Devlin의 BERT-base(110M)을 적용했다.
-
Single-turn matching models
Lowe, Kadlec은 RNN, CNN 및 LSTM을 사용한 기본 모델을 제안했다. -
SMN
Wu은 context-response 쌍을 여러 context-response 쌍으로 분해하고, 모든 발화와 응답을 matching 시킨 후, matching vector는 최종 matching score로 누적된다. -
DUA:
Zhang은 심층 발화 집계를 사용하여 이전 발화를 맥락으로 공식화한다. -
DAM
Zhou은 transformer encoder 기반 모델을 제안하고 self-Attenion과 Cross Attention을 통해 context와 response 간의 matching score를 계산했다. -
IoI
Tao는 여러 상호 작용 블록 체인을 통해 발언과 response 간의 deep- level matching을 허용했다. -
ESIM
Chen과 Wang은 신경언어추론(NLI)의 ESIM 모델을 응답선택에 적용하였다. -
MSN
Yuan의 모델은 multi-hop selector를 사용하여 더 관련된 context 발언을 선택하고, 선택된 문맥 발언과 response 간의 일치 정도를 결정했다. -
BERT
pre-trained BERT 기반에서 post-training 없이 응답 선택 작업에 fine-tuning한 바닐라 모델 -
RoBERTA-SS-DA
Lu은 서로 다른 화자를 구별하고 대화 확대를 적용하는 화자 분할 접근법을 제안했다. -
BERT-DPT
Whang는 도메인 사후 훈련(DPT)을 적용하는 모델을 제안했다. 이 모델은 BERT의 post-training 방법인 MLM 및 NSP로 post-training 한 다음 응답 선택 작업에 fine-tuning된다. -
BERT-VFT
Whang는 Houlsby가 제안한 효율적인 variable fine-tuning (VFT) 방식을 적용했다. -
SA-BERT
Gu는 모델에 스피커 인식 임베딩을 통합했다. 따라서 스피커 변경 정보를 인식한다. -
Whang은 세 가지 작업(즉, 발화 삽입, 삭제 및 검색)으로 구성된 다중 작업 학습 프레임워크를 제안했다. -
BERT-SL
Xu는 4가지 자체 감독 작업을 도입하고 이러한 보조 작업으로 대응 선택 모델을 멀티태스킹 방식으로 훈련시켰다.
4-5. Experimental Results
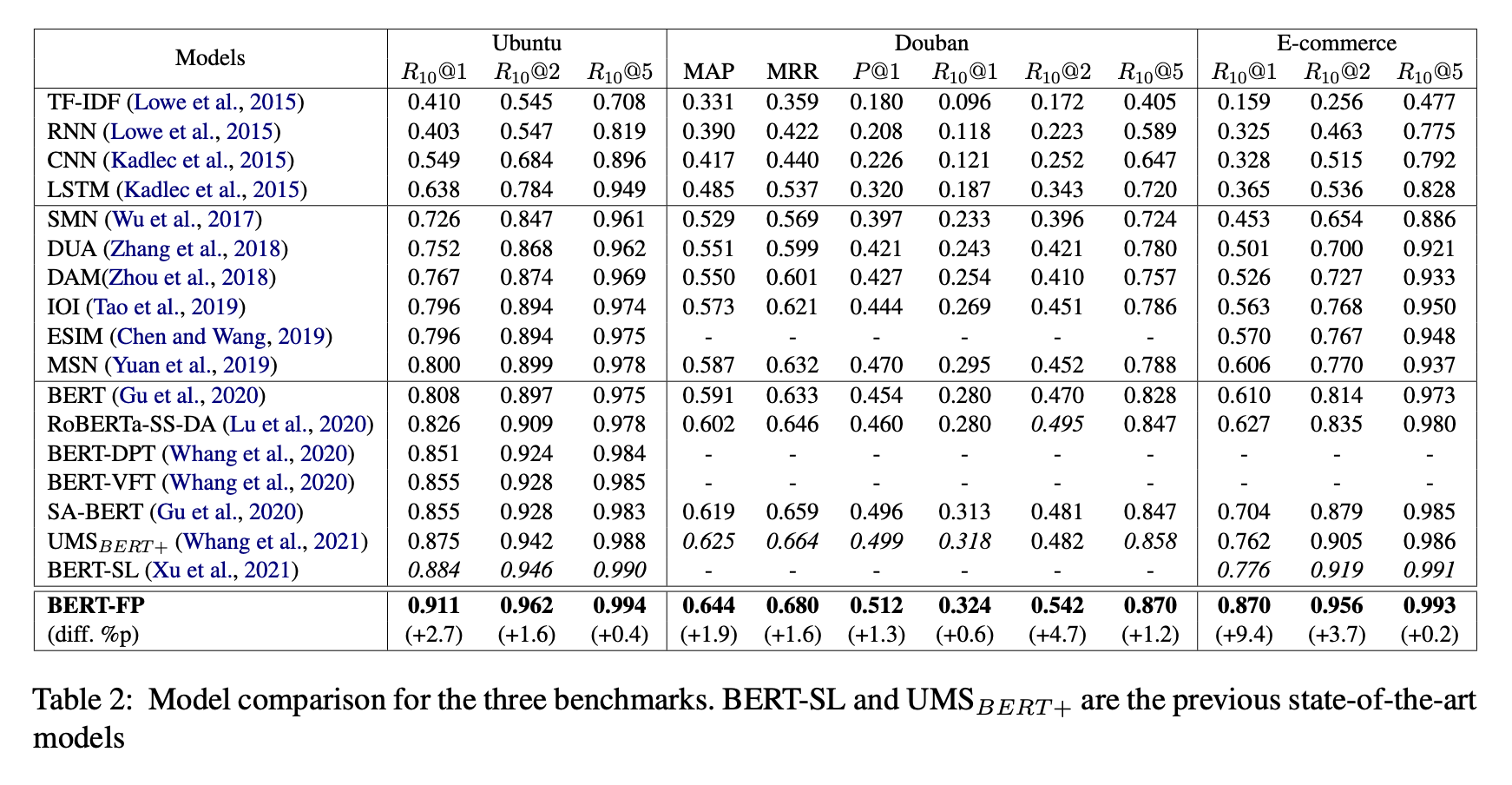
위 표는 세 가지 벤치마크에서 평가된 BERT-FP의 성능을 보여주며, 결과에서 볼 수 있듯이 본 논문의 모델은 baseling으로 사용되는 다른 모든 모델보다 성능이 뛰어났다.
BERT의 바닐라 모델과 비교하여, 우리 모델은 Ubuntu Corpus V1, Douban Corpus 및 E-commerce Corpus에서 각각 10.3%p, 4.4%p, 26%p씩 R10@1에서 절대적인 개선을 달성했다.
BERT-DPT와 비교하여 우리 모델은 Ubuntu Corpus에서 R10@1에서 6%p의 절대적인 개선을 달성했다.
이러한 결과는 대화의 특성을 반영한 fine-grained post-training이 이전의 post-training보다 우수함을 나타낸다.
이전의 SOTA 모델인 및 BERT-SL과 비교하여 우리 모델은 세 가지 벤치마크에 대한 모든 메트릭 측면에서 큰 폭으로 향상된 성능을 달성했다.
이러한 결과는 우리의 방법이 내부 발화 간의 의미론적 관련성과 일관성을 효과적으로 학습하여 선택 성능을 크게 향상시킨다는 것을 보여준다.
5. Further Analysis
5-1. Performance across Different Lengths of Short Context
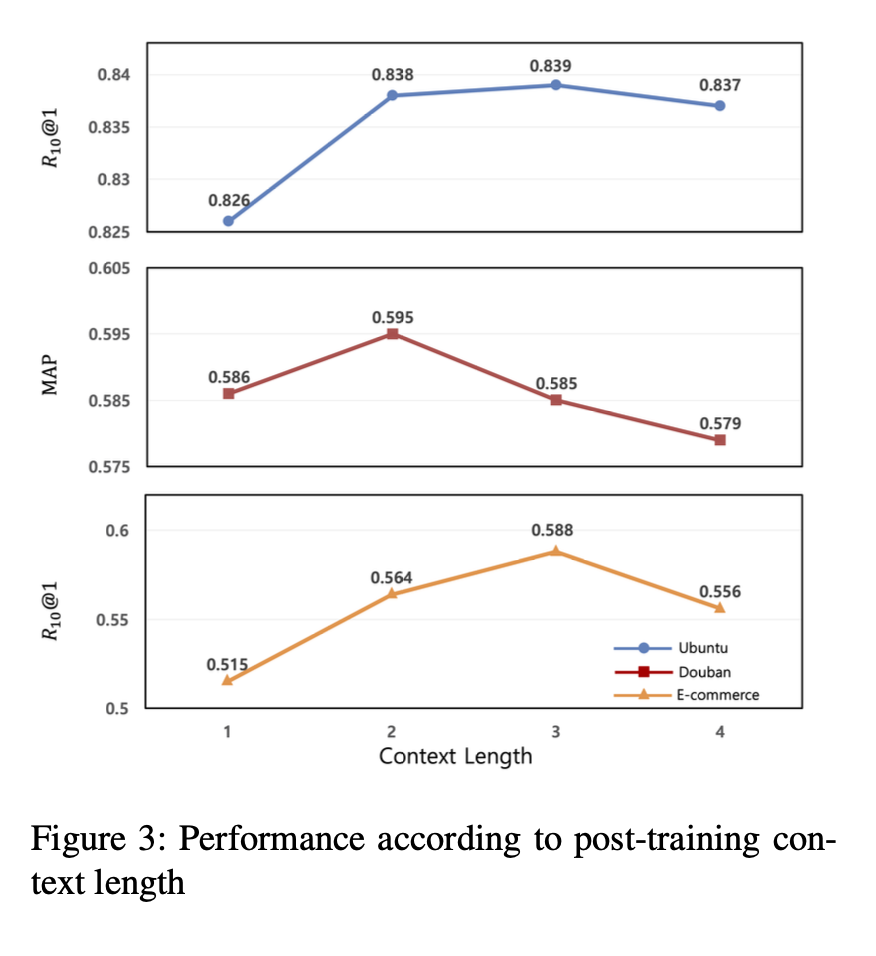
위 그림은 short context의 길이에 따른 BERT-FP의 성능 변화를 보여준다.
이 실험에서는 traiin set의 10%로 모델을 훈련시키고, 전체 test set로 평가하여 실험을 수행했다.
따라서, 더 낮은 성능을 달성했으며, Ubuntu Corpus와 E-commerce Corpus의 경우, R10@1의 최고 성능은 context length가 3일 때 달성된다.
Douban Corpus의 경우 선택지에 여러 개의 정답이 있을 수 있기 때문에 R10@1이 아닌 MAP로 성능을 평가했으며 최상의 성능은 context length가 2일 때 달성된다.
5-2. Performance according to Training Objective
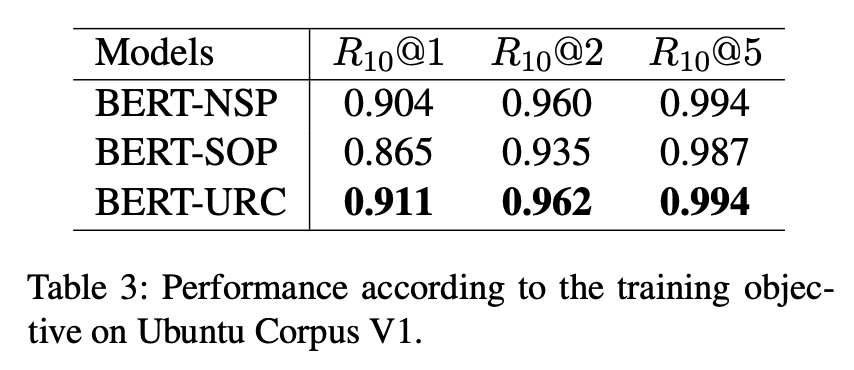
우리는 본 논문에서 제안한 URC를 이전 훈련 목표(NSP, SOP)와 비교했으며, 위 표는 우리의 training objective가 다른 training objective를 능가한다는 것을 보여준다. 이는 주제와 내부 발화 간 일관성을 모두 학습하는 것이 중요하다는 것을 나타낸다.
5-3. Ablation Study
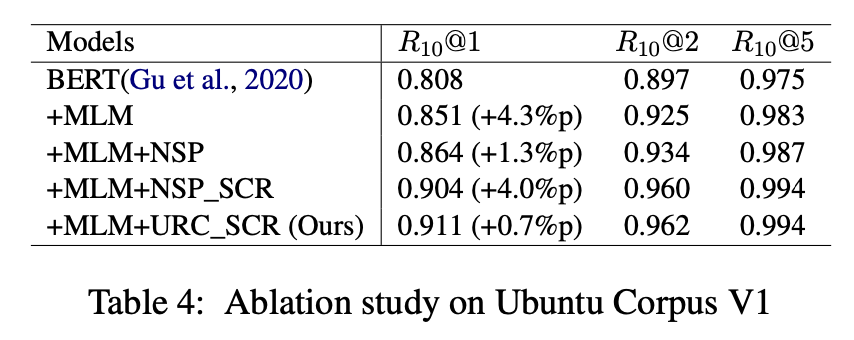
위 표는 Ubuntu 코퍼스에 대한 일련의 Ablation experiments를 통해 fine-grained post-training의 각 부분이 미치는 영향을 조사했다.
(post-training이 없는 모델을 기준으로 사용된다.)
그런 다음, 본 연구는 점진적 post-training을 적용했다.
+MLM은 모델이 MLM으로만 사후 훈련되었음을 나타낸다.
_SCR는 short context-response 쌍으로 post-training한 모델을 나타낸다.
+MLM과 +MLM+NSP를 비교한 결과, 기존 post-training 중 NSP가 성능에 거의 영향을 미치지 않는 것으로 나타났으나, +MLM과 MLM+NSP_SCR의 비교에서 알 수 있듯이 hort context-response 쌍으로 훈련된 NSP는 모델 성능을 크게 향상시켰다.
실험 결과는 또한 NSP 대신 URC를 사용하는 것이 성능을 향상시킨다는 것을 보여주었다.
5-4. Comparison with the Data Augmentation
post-training 방법은 Data Augmentation의 효과가 있다. 그러나 fine-tuning 단계에서 직접 Data Augmentation하는 일반적인 방법과는 다르다.
따라서, fine-grained post-training(BERT-FP) 방법을 Ubuntu Corpus의 일반적인 Data Augmentation(BERT-DA)과 비교했다.
Data Augmentation 전략은 Chen과 Whang이 하는 방법과 유사하게, 각 발화를 response으로 간주하고 이전 발화를 context로 고려했다.
결과는 아래와 같다.
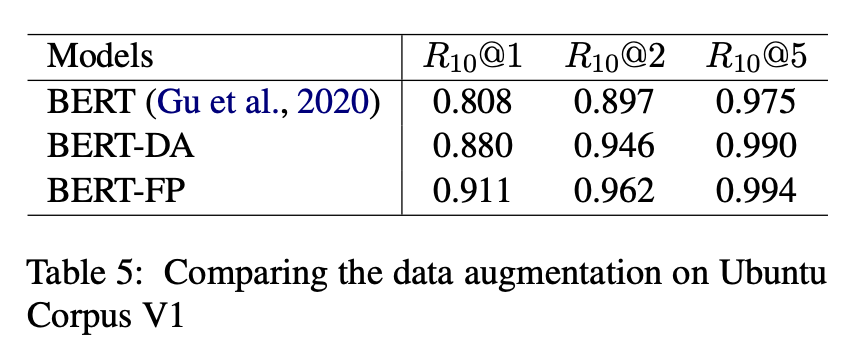
BERT-FP는 R10@1에서 Data Augmentation 모델(BERT-DA)을 3.1%p 능가하며, 이런 상당한 개선은 Data Augmentation과 비교하여 제안된 방법의 효과를 보여준다.
post-training과 fine-tuning를 포함한 본 연구의 방법은 BERT-DA보다 약 2.5배 빠르며, 특히 post- trained model은 BERT-DA보다 fine-tuning 되는데 훨씬 더 적은 시간이 소요되어 다양한 애플리케이션에 쉽게 적용할 수 있다.
5-5. The Effectiveness of Fine-grained Post-Training for Response Selection Task
응답 선택 작업에 대한 fine-grained post-training 방법의 효과를 입증하기 위해 BERT, BERT-FP 및 BERT-FP-NF(fine-tuning 없이 post-training한 모델)의 세 가지 다른 모델을 비교했다.
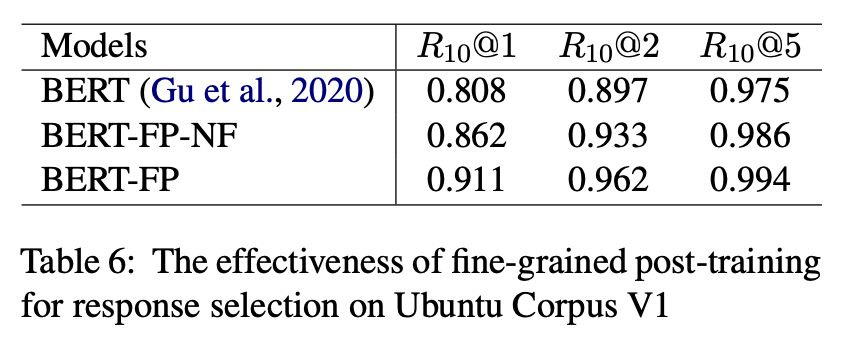
위 표와 같이 BERT-FP-NF의 성능은 fine-tuning된 BERT-FP에 가깝다.
이러한 결과는 응답 선택 작업에 대해 fine-tuning 전에도 fine-grained post-training만으로도 context와 response 간의 matching degree를 측정할 수 있음을 보여준다.
6. Conclusion
본 논문에서는 multi-turn dialogue에 적합한 새로운 fine-grained post-training 방법을 제안했다.
제안된 방법은 matching model이 대화에서 발언의 의미론적 관련성과 일관성을 학습할 수 있도록 하며, 모델이 적절한 응답을 선택할 수 있는 능력을 향상시킨다.
3가지 벤치마크 데이터셋에 대한 실험 결과는 response selection에 대한 post-training 방법의 우수성을 보여준다.
이를 통해 본 논문의 모델은 3가지 벤치마크 모두에서 SOTA 성능을 달성했다.
