Hyper parameter
Transformer에 들어가는 Hyper parameter에는 크게 6가지기 있습니다.
- Vocab_Size = 9000 | 단어장의 크기
- Num_layers = 4 | Encoder와 Decoder의 층의 개수
- = 512 | Position-wise FFNN의 은닉층 개수
- = 128 | Encoder와 Decoder의 입,출력 차원
- Num_head = 4 | Multi-head Attention의 병렬 헤드의 개수
- Dropout = 0.3 | 드롭아웃 비율
손실 함수
다중 클래스 분류 문제를 풀 경우 Cross Entropy Loss 사용
def loss_function(y_true, y_pred):
y_true = tf.reshape(y_true, shape=(-1, MAX_LENGTH - 1))
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')(y_true, y_pred)
mask = tf.cast(tf.not_equal(y_true, 0), tf.float32)
loss = tf.multiply(loss, mask)
return tf.reduce_mean(loss)손실 함수 종류
대표적인 모델과 손실함수의 종류는 아래와 같습니다.
-
회귀 모델일 경우
- MSE(평균제곱오차)
- MAE(평균절대값오차)
- RMSE(평균제곱근오차)
-
분류 모델일 경우
- Binary Cross-Entropy
- Categorical Cross-Entropy
- Sparse Categorical Cross-Entropy
MSE(평균제곱오차)

-
장점
- 실제 정답에 대한 정답률 오차 + 다른 오답에 대한 정답률 오차도 포함해 계산
- MAE와 달리 최적값에 가까워 질수록 이동값이 다르게 변화해 최적값 수렴에 용이
-
단점
- 값을 제곱하기 때문에 왜곡이 발생할 수 있음
- 제곱하기 때문에 특이값에 영향을 많이 받음
MAE(평균절대값오차)
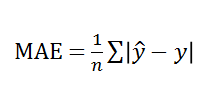
- 장점
- 전체 데이터의 학습된 정도를 쉽게 파악 가능
- 단점
- 절대값으로 인해 오차 발생 시 음수 인지 양수인지 판별 불가능
- 최적에 가까워 져도 이동거리가 일정하기 때문에 최적값 수렴 어려움
RMSE(평균제곱근오차)
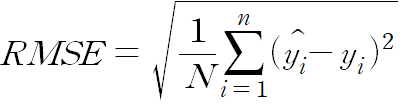
- 장점
- MSE와 유사하나 제곱된 값에 루트를 씌우기 때문에 제곱으로 인한 왜곡이 감소 및 직관적으로 볼 수 있음
- 루트를 씌워주기 때문에 오류 값을 실제값과 유사한 단위로 변환하여 해석 가능
- 단점
- 스케일에 의존적
- 실제 값에 대해 과소 또는 과대인지 파악 어려움
Binary Cross-Entropy
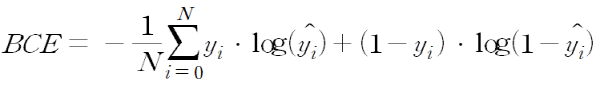
- 이진 분류에 사용 되는 방식
- 양성 or 음성 2개의 Class 분류 시 사용하는 방식으로 예측값 0 ~ 1 시아의 확률 값으로 나옴
- 1에 가까울 수록 Class(양성)일 확률이 큰 것
- 0에 가까울 수록 Class(음성)일 확률이 큰 것
Categorical Cross-Entropy
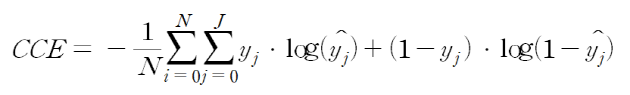
- 분류해야할 Class가 3개 이상인 경우 (=멀티 클래스 분류)
- 라벨이 [1,0,0,0] , [0,0,1,0] 등과 같은 One-Hot 형태로 제공될 때 사용
- 예측값은 [0.1,0.1,0.85,0.05]와 같은 형태로 나와 여러 Class 중 가장 적절한 하나의 Class를 분류시 사용
sparse categorical cross entropy
- categorical cross entropy과 동일하게 다중 클래스 분류 시 사용
- 단 라벨값이 One-Hot이 아닌 0,1,2 처럼 정수의 행태로 제공될 때 주로 사용
학습률
학습률 스케줄러(Learning rate Scheduler)는 미리 학습 일정을 정해두고 그 일정에 따라 학습률이 조정되는 방법입니다.
Trnasformer의 경우 사용자가 정한 단계까지는 학습률을 증가시켰다가 단계에 이르면 학습률을 점차적으로 떨어트리는 방식을 사용합니다.
step_num(단계)이란 optimazer가 매개변수를 업데이트 하는 한 번의 진행 횟수를 의미합니다.
Trnasformer에서는 warmup_steps이라는 변수를 정하고 step_num이 warmup_steps보다 작을 경우는 학습률을 선형적으로 증가 시키고,
step_num이 warmup_steps에 도달하게 되면 학습률을 step_num의 역제곱근에 따라서 감소시킵니다.
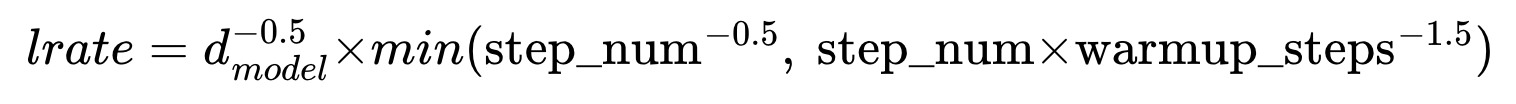
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps**-1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)sample_learning_rate = CustomSchedule(d_model=128)
plt.plot(sample_learning_rate(tf.range(200000, dtype=tf.float32)))
plt.ylabel("Learning Rate")
plt.xlabel("Train Step")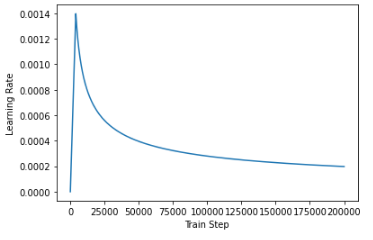

딥러닝 지식의 백지에서 깜지까지