Hash Table
Key와 해시 함수를 이용해 얻은 해시 코드를 인덱스 삼아 Key와 값(value)를 대응시켜 저장하는 자료구조
해시 함수(Hash function) & 해시 코드(Hash code)?
임의의 길이의 데이터를 고정된 길이로 매핑하는 함수. 이 때 매핑된 값이 해시 코드
이 때, 입력값은 무한할 수 있는데 반해 출력값은 고정된 길이로 유한하기 때문에 입력 값이 다름에도 불구하고 똑같은 해시 코드가 나올 수 있음
→ 이런 상황을 해시 충돌(collison)이라고 함
→ 해시 충돌 자체를 없애는건 어렵기 때문에 가능한 모든 해시 코드에 균등하게 발생하는 것이 좋음
해시 테이블은 왜 사용할까?
효율적인 탐색을 위해 사용
예를 들어, N명의 학생 정보가 저장된 자료구조를 생각해보자. 이 때, 만약 이름이 Glenn이라는 학생을 찾으려면 어떻게 해야할까?
-
배열로 저장한 경우
Glenn이 저장된 인덱스를 알 수 없으니 배열의 장점인 Random access가 불가능하다. 따라서 처음부터 끝까지 탐색해야하기 때문에 O(N)이 소요된다
-
리스트로 저장한 경우
리스트 역시 배열과 다를 바 없다. 처음부터 끝까지 Glenn을 찾아야 하기 때문에 O(N)이 소요된다
이처럼 기존의 자료구조로는 탐색에 소요되는 시간이 O(N)이다. 충분히 빠르다고 생각할 수도 있지만, N이 커질수록 부담될 수밖에 없다. 이런 상황에서 해시 테이블은 해시 코드를 이용해 모든 데이터를 탐색할 필요 없게 만들어 원하는 데이터를 빠르게 탐색할 수 있다.
해시 테이블의 동작 과정(Chaining 방식)
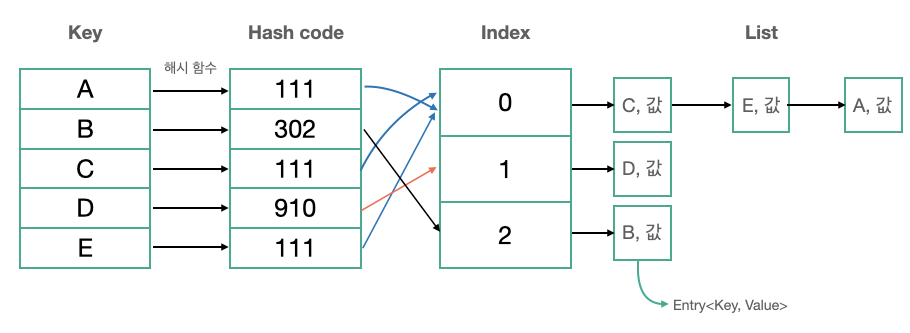
- 입력받은 Key를 해시함수를 이용해 해시 코드를 계산한다
- Key의 종류가 무한하기 때문에 같은 해시코드가 나올 수 있음
- 모듈러 연산(%)과 같은 방법을 사용해 해시 테이블의 어떤 인덱스에 저장할지 계산한다
- 다른 키값이어도 같은 해시 코드가 나올 수 있기 때문에 같은 인덱스에 여러 값이 매핑될 수 있음
- 해시 테이블의 인덱스에는 (키, 값)으로 구성된 리스트가 존재한다. 이 리스트에 입력받은 (키, 값) 쌍을 추가한다
- 리스트가 존재하는 이유는 해시 충돌로 인해
다른 키 -- 해시 함수 --> 같은 해시 코드인 경우가 발생할 수 있기 때문 - 그렇기 때문에 만약 해시 충돌로 인해 같은 인덱스에 모든 키값이 매핑된다면 리스트를 사용하는 것과 다를 바 없어져 탐색 시간이 O(N)이 되어버림
- JAVA에서는 (키, 값) 쌍을
Entry라는 인터페이스로 저장함
- 리스트가 존재하는 이유는 해시 충돌로 인해
정리
-
데이터 탐색: O(1 + k)k는 해당 인덱스에 속해있는 Entry의 개수
해시 충돌이 많이 발생하면 발생할수록 k가 커지기 때문에 속도가 느려진다
-
데이터 삽입: O(1)해시코드 계산 → 인덱스 계산 → 해당 인덱스의 맨 앞에 엔트리 추가
-
데이터 삭제: O(1 + k)해시코드 계산 → 인덱스 계산 →리스트에서 삭제하려는 데이터 탐색(O(k)) → 리스트에서 삭제
Hash를 사용한 JAVA의 자료구조
HashSet
Set 자료구조를 Hash를 사용해 구현한 클래스. 중복되지 않는 unique한 key들의 집합
- 데이터를 삽입한 순서가 지켜지지 않는다
- 내부적으로
HashMap을 사용하고 있음
HashSet의 연산
-
add(key)Set에 key 추가
-
remove(key)Set에서 key 제거
-
contains(key)key가 Set에 있는지 확인
-
isEmptySet이 비어있는지 확인
정리
-
데이터 삽입 순서가 보장되지 않음
→ 순서가 중요한 경우
LinkedHashSet과 같은 구현체를 이용 -
데이터 탐색: O(1 + k) -
데이터 삽입: O(1) -
데이터 삭제: O(1 + k)
HashMap
Map 자료구조를 Hash를 사용해 구현한 클래스. (key, value) 쌍으로 이루어져 있다
- 데이터를 삽입한 순서가 지켜지지 않음
HashMap의 연산
-
putMap에 (key, value) 삽입
-
getMap에서 key에 해당하는 value값 얻음
-
removeMap에서 key 제거
-
containsKeykey가 Map에 있는지 확인
-
isEmptyMap이 비어있는지 확인
정리
-
데이터 삽입 순서가 보장되지 않음
→ 순서가 중요한 경우
LinkedHashSet과 같은 구현체를 이용 -
데이터 탐색: O(1 + k) -
데이터 삽입: O(1) -
데이터 삭제: O(1 + k)
