
웹 서비스를 공개한 뒤 그 상태로 방치해서는 안된다.
오랜 시간 이용됨에 따라 데이터가 쌓여 저장공간을 압박할 수 있기 때문이다.
이로인해, 서버가 지연되거나 다운될 가능성도 있다.
이런 상황을 미연에 방지하거나 대응하기위해서 모티터링을 해야한다.
🖥️ 모니터링
- 효율적인 모니터링을 위해서는 크게 3가지를 고려해야한다.
- 집중 관리
- 알림
- 지속적인 정보 수집
🧘♂️집중관리
- 웹 서비스는 웹서버나 데이터베이스 서버등 여러요소로 구성되어 있어, 이 정보들이 이곳저곳에 흩어져있으면 문제가 발생했을때 찾아내기 어렵다.
- 따라서 모든 서비스의 정보를 한곳에 모아서 집중관리 할 수 있어야 한다.
- 필요한 정보를 한 곳에 모아 관리할 수 있는 대시보드를 사용한다.
🔔 알림
- 대시보드가 눈으로 보기는 좋지만, 하루종일 내내 보고있을 수는 없다.
- 그래서 서버가 장애를 일으키거나 이용자가 갑자기 증가해 반응이 지연되는 등 무언가 대응이 필요한 경우에만 감지하는 시스템을 알람(또는 alert)라 부른다.
- 보통 즉각적인 대응이 필요한 긴급한 경우 : 모바일 푸시알림, SNS채팅 등
- 약간의 지연을 허용하는 경우 : 메일 알림
🗳️ 지속적인 정보 수집
-
문제의 원인은 그때뿐만아니라, 평소에도 자주 나타났을 수도 있다.
-
예를 들어,
-
상황: 온라인 쇼핑몰 서비스의 결제 서버 문제
-
발생 시점 원인:
- 온라인 쇼핑몰의 결제 서버에 문제가 발생하여 고객들이 결제를 완료하지 못하고 주문이 중단되는 상황입니다. 이 문제는 주로 결제 서버의 소프트웨어 업데이트 중에 발생했을 수 있습니다. 업데이트 과정에서 버그나 호환성 문제가 발생하여 결제 처리가 제대로 이루어지지 않았을 수 있습니다.
-
평소 발생 가능한 원인:
- 평소에도 결제 서버 문제가 발생할 수 있습니다. 예를 들어, 결제 서버의 자원이 부족하여 동시에 많은 결제 요청을 처리하지 못해 서비스 지연이 발생할 수 있습니다. 또한, 결제 서버의 데이터베이스에 이상이 생겨 결제 정보가 손실되거나 불일치할 수 있습니다.
-
-
이러한 문제를 대응하기위해서는 지속적인 정보를 수집해서 저장해두었다가 언제든 참조할 수 있도록 해야한다.
📌주요 모니터링 항목
- 모니터링할 서비스의 중요성이나 대상 리소스에 따라 다양하지만, 최소한으로 모니터링할 항목들을 다룬다.
💡 생사 모니터링
- 해당 리소스가 작동하는가?
- 특정 리소스를 서비스 안에서 이용할 수 없게 되는 것을 체크한다.
- 물리적인 장애나 운영체제 오류, 네트워크 단절 등 다양한 원인
- 가장 신속하게 오류 발생을 확인하고 대응해야 할 장애
- 해결방법 : 죽은 리소스를 다시 살려야 한다.
📈 CPU 사용률
- 리소스에서 과도한 작업을 수행하는가?
- OS에서는 여러 처리를 동시에 실행할 수 있는 멀티태스크라는 기능을 제공한다.
- 그러나 지나치게 많은 태스크를 동시에 실행하려고 하면, CPU가 감당하지 못하게되어, 실행을 기다리는 처리가 늘어나게 된다.
- CPU의 사용률 상태가 100%이면 실행을 기다리는 처리가 발생한다는 의미
- 해결방법
- 스케일 업, 스케일 아웃
- 비효율적인 알고리즘 개선, 반복 횟수 줄이기등
- 캐시 활용
- 배치 작업 분산, 서버간 요청 분산
📊 메모리 사용률
- 리소스에 제공되는 메모리가 많이 쓰이지 않는가?
- 메모리는 리소스가 처리를 실행할 때 이용하는 작업 영역과 같은 것
- 메모리에는 제한이 있으므로,이 또한 여유가 없으면 처리가되지 않기 때문에 대기가 발생한다.
- 해결방법
- I/O 작업(DB조회, 파일입출력등은 메모리사용이 큼) 비동기처리
- 스케일 아웃
- 캐시 전략 검토
- 효율적인 데이터 구조 사용(큐, 스택, 해시맵등을 적절하게 사용)
- 메모리 최적화
🧺 디스크 용량
- 리소스에 연결된 디스크의 빈 용량이 충분한가?
- 디스크에는 2가지 정보가 저장된다.
- 크게 증가하지 않는 정보 : 서비스를 구축하는 프로그램, 설정 파일 등
- 시간이 흐름에 따라 증가하는 정보 : 서비스에 등록되는 데이터, 로그 등
- 저장되어야할 정보가 저장되지않아 서비스가 이상 종료되기도 한다.
- 해결방법 :
- 디스크용량을 늘린다.
- 불필요한 파일 삭제
- 압축 및 아카이빙
🛣️ 네트워크 트래픽
- 네트워크를 경유해 리소스에 접근하거나, 리소스에서 나오는 통신량을 확인
- 네트워크를 통해 주고받을 수 있는 데이터양에는 제한이 있다.
- 많은 사용자가 동시에 이용하거나, 한 사용자가 대량의 데이터를 다운로드하면 다른 사용자는 리소스를 이용하거나 통신하기 어려워진다.
- 즉, 사용자는 네트워크가 느려서 서비스를 이용할 수 없는 상황이 나올 수 있다.
- 해결방법 :
- 트래픽 분산(CDN)
- 비동기 처리
- 품질관리(QoS) : 우선순위가 높은 트래픽 먼저
- 대역폭 확장
🗂️ 리소스별 모니터링 항목
| 생사 | CPU사용량 | 메모리사용량 | 디스크용량 | 네트워크트래픽 | 기타 | |
|---|---|---|---|---|---|---|
| EC2 | 🔴 | 🔴 | 🔴 | 🔴 | 🔺 | - |
| RDS | 🔴 | 🔴 | 🔴 | 🔺 | 🔺 | SQL레이턴시, 처리량 등 |
| ALB | - | - | - | - | 🔴 | - |
| S3 | - | - | - | 🔴 | 🔴 | - |
EC2
- OS나 미들웨어가 원인이 되는 서버 다운이 발생할 수 있다.
- 보통 직접 인터넷에 연결하지 않으므로 크게 신경쓸 일은 없다.
RDS
- OS나 미들웨어는 매니지드 서비스이므로 안정적으로 가동하나, 종종 보안 대응으로 인해 재기동이 발생할 수 있다.
- SQL 실행에 소요되는 시간(레이턴시)과 일정시간당 처리량도 감시하면 좋다.
ALB
- 통신량이 비용에 직접 반영됨으로, 과도한 통신이 발생하지 않는지 트래픽을 모니터링
S3
- 이 또한, 통신과 용량에따라 비용이 발생함으로, 모니터링
이처럼 모니터링은 안정적인 서비스 운영을 위해 꼭 필요한 작업이다.
하지만, 모니터링 만큼이나 중요한 것은 모니터링을 통해 문제를 알았을 때 대응책이 준비되어있어야한다는 것이다.
⌚️ CloudWatch
- aws에서 제공해주는 모니터링 서비스이다.
- 기본적인 기능은 무료로 이용할 수 있다.
주요기능
| 기능 | 설명 |
|---|---|
| 수집 | 지속해서 수집 리소스와 관계된 로그를 실시간으로 수집하고 기록 |
| 모니터링 | 집중관리 기능 보기쉽게 한 장소에서 그래프로 볼수 있음 |
| 액션 | 주로 알림 기능 이용자에게 SNS, 메일, API호출등 다양한 형태로 알림 가능 |
📲 리소스 모니터링하기
순서
- 대시보드 생성
- 대시보드에 위젯 추가

- 알림 생성
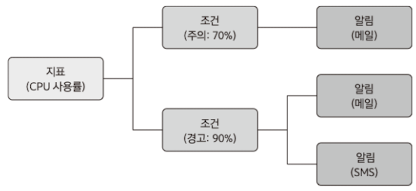
- 지표 : 만든 위젯이나, 수집한 정보를 선택
- 조건 : 수집한 정보의 값을 단계별로 조건에 따라 나눌 수 있다.
- 알림 : 지표의 값이 조건을 만족했을때 일어나는 반응이다.

한단계씩 올라가는 개발자