
데이터 전처리
머신러닝 학습과정에서 가장 많은 시간이 소요되는 부분이다. 전체의 약 80%를 차지하는 중요한 부분이다.
- 데이터 확인: 데이터 자료형, 변수 속성 등을 파악한다.
- 결측치 확인 및 처리: 결측치의 존재 여부를 조사한 후, 결측치의 처리 방법을 결정한다. 결측치는 제거하는 것이 기본이나 데이터셋의 성질에 따라 적절한 값으로 채워야 하는 경우도 존재한다.
- 데이터 변환: 데이터를 분석에 적합한 형태로 변환한다.
- 이상치 처리: 다른 데이터와 동떨어진 관측치(Outlier)를 찾아 처리한다. 3-sigma 규칙 및 IQR 방법론을 사용할 수 있다.
- 특징 공학(feature engineering): 데이터에 정보를 추가하는 일련의 과정을 의미한다.
타이타닉 데이터 분석 실습
1. 타이타닉 데이터셋 다운로드
타이타닉 데이터셋은 kaggle에서 제공하고 있다.
타이타닉 데이터셋 다운로드
2. Python을 이용해서 데이터 불러오기(with pandas)
import pandas as pd
# train.csv의 로컬 경로
train = pd.read_csv('./datasets/titanic_train.csv')
train| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 12 columns
3. 불러온 데이터의 대략적인 정보 확인
데이터를 구성하고 있는 feature들을 확인해보자.
PassengerId: 탑승객 번호Survived: 탑승객의 생존여부Pclass: 탑승객의 탑승권 등급Name: 탑승객의 이름Sex: 탑승객의 성별Age: 탑승객의 나이SibSp: 함께 탑승한 친척의 수Parch: 함께 탑승한 가족의 수Ticket: 탑승권 정보Fare: 해당 탑승객이 선상에서 지불한 요금Cabin: 해당 탑승객의 선실 번호Embarked: 해당 탑승객이 탑승한 선착장
일반적으로 데이터의 feature들을 살펴보았을 때 의미 없는 feature는 크게 세 가지 정도로 생각할 수 있다(PassengerId, Name, Ticket). 하지만 Name의 경우, Age에 존재하는 결측치를 채워넣는 과정에서 아주 중요하게 활용할 수 있다(후술할 내용 참고).
Survived는 데이터의 정답지이지만 0과 1을 각각 해당 탑승객이 사망할 확률과 생존할 확률로 생각해본다면 다른 관점에서의 데이터 분석이 가능하다.
train.groupby('Sex')['Survived'].mean().plot(kind='bar')
plt.xlabel('Sex')
plt.ylabel('Survived')
plt.title('Mean Survival Rate by Sex')
plt.show()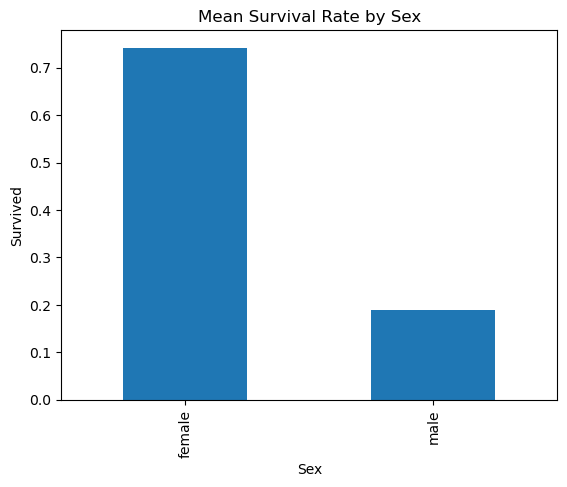 !
!
Sex
female 0.742038
male 0.188908
Name: Survived, dtype: float64여성의 경우 약 74%, 남성의 경우 약 19%의 확률로 생존한다고 추정할 수 있다.
위의 방법론을 통해 여러가지 정보를 습득해보자.
train.groupby('Pclass')['Survived'].mean().plot(kind='bar')
plt.xlabel('Pclass')
plt.ylabel('Survived')
plt.title('Mean Survival Rate by Pclass')
plt.show()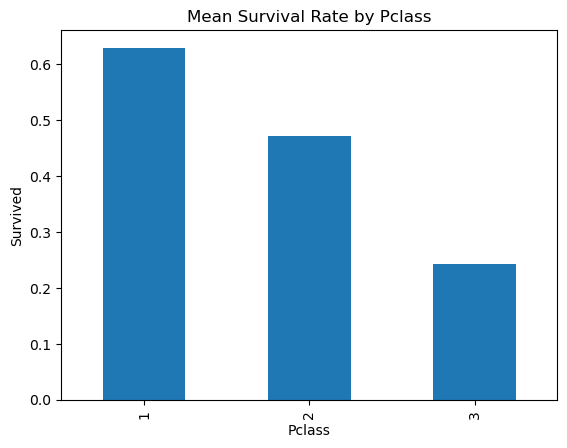
Pclass
1 0.629630
2 0.472826
3 0.242363
Name: Survived, dtype: float64train.groupby('Embarked')['Survived'].mean().plot(kind='bar')
plt.xlabel('Embarked')
plt.ylabel('Survived')
plt.title('Mean Survival Rate by Embarked')
plt.show()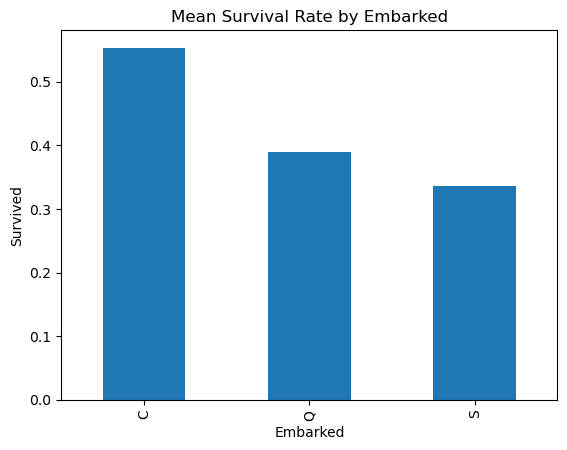
Embarked
C 0.553571
Q 0.389610
S 0.336957
Name: Survived, dtype: float64위와 같은 방법을 토대로 다른 feature들의 속성도 파악할 수 있다.
4. 본격적인 데이터 전처리
- 결측치 확인 및 시각화
train.isnull().sum()
sns.heatmap(train.isnull(), yticklabels=False, cbar=False, cmap='viridis')
plt.show()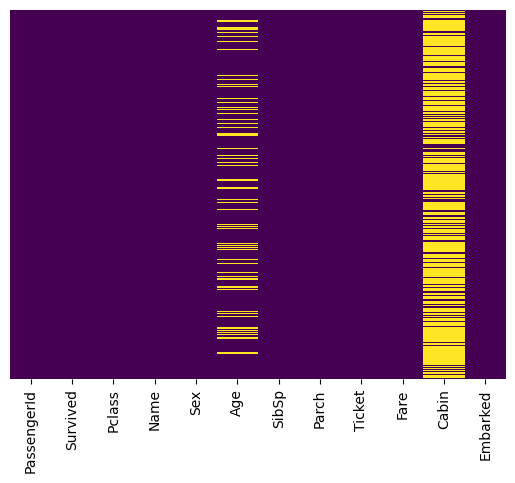
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64타이타닉 데이터셋의 데이터 개수는 891개인데, Cabin의 경우 그 중 687개가 결측치이고, 결측치의 비율이 매우 크기 때문에 채워넣는다고 해도 오히려 학습에 안 좋게 작용할 가능성이 높다. 따라서 이후 전처리 과정에서 Cabin은 제거하는 방향으로 진행한다. Age의 경우는 결측치의 비율이 Cabin만큼 높지는 않지만 891개의 데이터에서 177개를 삭제하게되면 기존에도 부족한 데이터의 수가 더 줄어들게 되기 때문에 '합리적'으로 채워넣는 방법을 구상해야한다. Embarked의 경우 가장 최빈값인 S로 채우는 방법을 선택했다.
- 필요없는 feature삭제
PassengerId는 탑승객의 단순 번호, 말하자면 데이터의 인덱스이기 때문에 학습에 도움이 되지 않는 feature라고 판단하였다.Ticket은 탑승객의 탑승권 정보이기 때문에 이 역시 탑승객의 생존여부를 판단하는 데에 도움이 되지 않을 것이라고 판단하였다.Cabin의 경우는 위에서 설명하였다.
train = train.drop(['PassengerId', 'Ticket', 'Cabin'], axis=1)
train.head()| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | 7.2500 | S |
| 1 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | 71.2833 | C |
| 2 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | 7.9250 | S |
| 3 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 53.1000 | S |
| 4 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 8.0500 | S |
Pclass
Pclass의 경우 데이터 자체는 숫자 1, 2, 3으로 이루어져 있어서 연속형 데이터라고 착각할 수 있지만, 엄연히 탑승객의 탑승권 등급을 나타내는 범주형 데이터이다. 범주형는 데이터 모델의 학습에 사용하기 위해서 원-핫 인코딩 기법을 이용해 전처리 해야한다.원-핫 인코딩 기법은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식이다.
from sklearn.preprocessing import OneHotEncoder
onehot_Pclass = OneHotEncoder(sparse=False)
label_Pclass = train['Pclass'].values.reshape(-1, 1)
onehot_Pclass.fit(label_Pclass)
label_Pclass = onehot_Pclass.transform(label_Pclass)
train_Pclass = pd.DataFrame(label_Pclass, columns=['Pclass_1', 'Pclass_2', 'Pclass_3'])
train = pd.concat([train, train_Pclass], axis=1)
train = train.drop(['Pclass'], axis=1)
train.head()| Survived | Name | Sex | Age | SibSp | Parch | Fare | Embarked | Pclass_1 | Pclass_2 | Pclass_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | 7.2500 | S | 0.0 | 0.0 | 1.0 |
| 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | 71.2833 | C | 1.0 | 0.0 | 0.0 |
| 2 | 1 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | 7.9250 | S | 0.0 | 0.0 | 1.0 |
| 3 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 53.1000 | S | 1.0 | 0.0 | 0.0 |
| 4 | 0 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 8.0500 | S | 0.0 | 0.0 | 1.0 |
Sex
성별 데이터도Pclass와 마찬가지로 범주형 데이터이기 때문에 원-핫 인코딩 기법으로 전처리해준다.
onehot_Sex = OneHotEncoder(sparse=False)
label_Sex = train['Sex'].values.reshape(-1, 1)
onehot_Sex.fit(label_Sex)
label_Sex = onehot_Sex.transform(label_Sex)
train_Sex = pd.DataFrame(label_Sex, columns=['female', 'male'])
train = pd.concat([train, train_Sex], axis=1)
train = train.drop(['Sex'], axis=1)
train.head()| Survived | Name | Age | SibSp | Parch | Fare | Embarked | Pclass_1 | Pclass_2 | Pclass_3 | female | male | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Braund, Mr. Owen Harris | 22.0 | 1 | 0 | 7.2500 | S | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 |
| 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | 1 | 0 | 71.2833 | C | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | 1 | Heikkinen, Miss. Laina | 26.0 | 0 | 0 | 7.9250 | S | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 |
| 3 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 35.0 | 1 | 0 | 53.1000 | S | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 0 | Allen, Mr. William Henry | 35.0 | 0 | 0 | 8.0500 | S | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 |
SibSp,Parch
SibSp는 함께 탑승한 친척의 수,Parch는 함께 탑승한 가족의 수이다. 그렇다면SibSp값과Parch값을 더한 후 +1을 하게된다면 탑승한 총 인원 수를 알 수 있다.
train['Family'] = train['SibSp'] + train['Parch'] + 1
train.head()| Survived | Name | Age | SibSp | Parch | Fare | Embarked | Pclass_1 | Pclass_2 | Pclass_3 | female | male | Family | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Braund, Mr. Owen Harris | 22.0 | 1 | 0 | 7.2500 | S | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 2 |
| 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | 1 | 0 | 71.2833 | C | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 |
| 2 | 1 | Heikkinen, Miss. Laina | 26.0 | 0 | 0 | 7.9250 | S | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1 |
| 3 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 35.0 | 1 | 0 | 53.1000 | S | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 |
| 4 | 0 | Allen, Mr. William Henry | 35.0 | 0 | 0 | 8.0500 | S | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 |
Fare
Fare는 선상에서 해당 탑승객이 사용한 요금이다. 연속형 데이터이고, 시각화해서 나타내보면 정규분포와 비슷한 형태를 띄고 있는걸 알 수 있다. 따라서sklearn에서 제공하는StandardScaler를 이용해 정규화 전처리하였다.
plt.figure(figsize=(10, 6))
sns.distplot(train['Fare'])
plt.show()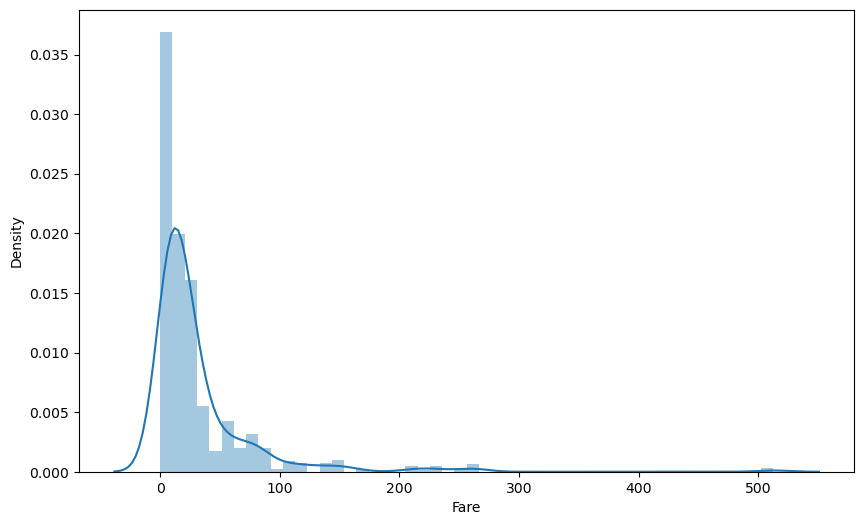
from sklearn.preprocessing import StandardScaler
scaler_Fare = StandardScaler()
label_Fare = train['Fare'].values.reshape(-1, 1)
scaler_Fare.fit(label_Fare)
label_Fare = scaler_Fare.transform(label_Fare)
train_Fare = pd.DataFrame(label_Fare, columns=['Fare_scaled'])
train = pd.concat([train, train_Fare], axis=1)
train = train.drop(['Fare'], axis=1)
train.head()| Survived | Name | Age | SibSp | Parch | Embarked | Pclass_1 | Pclass_2 | Pclass_3 | female | male | Family | Fare_scaled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Braund, Mr. Owen Harris | 22.0 | 1 | 0 | S | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 2 | -0.502445 |
| 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | 1 | 0 | C | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.786845 |
| 2 | 1 | Heikkinen, Miss. Laina | 26.0 | 0 | 0 | S | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1 | -0.488854 |
| 3 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 35.0 | 1 | 0 | S | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.420730 |
| 4 | 0 | Allen, Mr. William Henry | 35.0 | 0 | 0 | S | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.486337 |
Embarked
Embarked는 해당 탑승객이 탑승한 선착장이다. 결측치가 2개 존재하므로 결측치를 채워넣은 후, 범주형 데이터이기 때문에 원-핫 인코딩하였다.
train['Embarked'] = train['Embarked'].fillna('S')
onehot_Embarked = OneHotEncoder(sparse=False)
label_Embarked = train['Embarked'].values.reshape(-1, 1)
onehot_Embarked.fit(label_Embarked)
label_Embarked = onehot_Embarked.transform(label_Embarked)
train_Embarked = pd.DataFrame(label_Embarked, columns=['Embarked_C', 'Embarked_Q', 'Embarked_S'])
train = pd.concat([train, train_Embarked], axis=1)
train = train.drop(['Embarked'], axis=1)
train.head()| Survived | Name | Age | SibSp | Parch | Pclass_1 | Pclass_2 | Pclass_3 | female | male | Family | Fare_scaled | Embarked_C | Embarked_Q | Embarked_S | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Braund, Mr. Owen Harris | 22.0 | 1 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 2 | -0.502445 | 0.0 | 0.0 | 1.0 |
| 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.786845 | 1.0 | 0.0 | 0.0 |
| 2 | 1 | Heikkinen, Miss. Laina | 26.0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1 | -0.488854 | 0.0 | 0.0 | 1.0 |
| 3 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 35.0 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.420730 | 0.0 | 0.0 | 1.0 |
| 4 | 0 | Allen, Mr. William Henry | 35.0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.486337 | 0.0 | 0.0 | 1.0 |
Name,Age
Name을Age의 결측치를 채우는 데 사용할 수 있다. 보통 결측치를 채워넣을 때에는 대푯값을 이용한다.
대푯값은 어떤 데이터를 대표하는 값으로 평균, 중앙값, 최빈값 등이 존재한다.
- 평균: 모든 데이터를 더한 후, 갯수로 나눈 값
- 중앙값(중간값): 데이터를 순서대로 정렬한 후 위치상 가운데에 있는 값
- 최빈값: 데이터에서 가장 많이 등장하는 값
Age의 결측치를 채울 때에는 중앙값을 이용한다. 평균을 이용하면 되지 않느냐,라고 생각할 수 있는데 평균을 쓰지 않는 이유는 '평균의 함정'때문이다.
평균의 함정은 데이터에서 극단적인 값이 존재할 때, 평균값이 실제 상황을 왜곡할 수 있는 현상을 의미한다.
단순히 전체 데이터셋의 중앙값을 이용해 채우는 방법도 있지만, 조금 더 과학적으로 접근해보자. 그럴듯하게 채울 방법을 생각해보면 전체 데이터셋의 중앙값을 이용해 채우는 방법보단 성별에 따른 중앙값을 이용하는것이 조금 더 합리적이라고 생각한다.
그리고 바로 이 부분에서 Name데이터를 이용할 수 있는 방법이 있다. 타이타닉 데이터셋은 미국의 데이터셋이고 미국에서는 사람의 이름을 부르거나 기록할 때 Title을 붙여 말한다. 예를 들면 Mr, Mrs, Miss..등이다. Name데이터의 값을 살펴보면 해당 단어들이 포함되어 있음을 알 수 있다. Title은 남성과 여성, 그리고 기혼 여부에 대한 정보를 알 수 있기 때문에 이것을 기반으로 Age의 결측치를 채우게 된다면 가장 합리적일 것이다.
따라서, 먼저 Name에서 Title을 추출해야 한다. 정규표현식을 이용하면 손쉽게 추출할 수 있다.
train['Title'] = train['Name'].str.extract('([A-Za-z]+)\.', expand=False)
train = train.drop(['Name'], axis=1)
train.head()| Survived | Age | SibSp | Parch | Pclass_1 | Pclass_2 | Pclass_3 | female | male | Family | Fare_scaled | Embarked_C | Embarked_Q | Embarked_S | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 22.0 | 1 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 2 | -0.502445 | 0.0 | 0.0 | 1.0 | Mr |
| 1 | 1 | 38.0 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.786845 | 1.0 | 0.0 | 0.0 | Mrs |
| 2 | 1 | 26.0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1 | -0.488854 | 0.0 | 0.0 | 1.0 | Miss |
| 3 | 1 | 35.0 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.420730 | 0.0 | 0.0 | 1.0 | Mrs |
| 4 | 0 | 35.0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.486337 | 0.0 | 0.0 | 1.0 | Mr |
Mr, Mrs, Miss, Master가 가장 많은 4개의 Title이다. 해당 값들을 제외한 나머지는 모두 Other로 치환해준다.
def title_change(title):
if title not in ['Mr', 'Mrs', 'Miss', 'Master']:
return 'Other'
else:
return title
train['Title'] = train['Title'].apply(title_change)
train.head()| Survived | Age | SibSp | Parch | Pclass_1 | Pclass_2 | Pclass_3 | female | male | Family | Fare_scaled | Embarked_C | Embarked_Q | Embarked_S | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 22.0 | 1 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 2 | -0.502445 | 0.0 | 0.0 | 1.0 | Mr |
| 1 | 1 | 38.0 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.786845 | 1.0 | 0.0 | 0.0 | Mrs |
| 2 | 1 | 26.0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1 | -0.488854 | 0.0 | 0.0 | 1.0 | Miss |
| 3 | 1 | 35.0 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.420730 | 0.0 | 0.0 | 1.0 | Mrs |
| 4 | 0 | 35.0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.486337 | 0.0 | 0.0 | 1.0 | Mr |
범주형 데이터로 변환했으니, 원-핫 인코딩 처리를 해준다.
onehot_Title = OneHotEncoder(sparse=False)
label_Title = train['Title'].values.reshape(-1, 1)
onehot_Title.fit(label_Title)
label_Title = onehot_Title.transform(label_Title)
train_Title = pd.DataFrame(label_Title, columns=['Master', 'Miss', 'Mr', 'Mrs', 'Other'])
train = pd.concat([train, train_Title], axis=1)
train.head()| Survived | Age | SibSp | Parch | Pclass_1 | Pclass_2 | Pclass_3 | female | male | Family | Fare_scaled | Embarked_C | Embarked_Q | Embarked_S | Title | Master | Miss | Mr | Mrs | Other | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 22.0 | 1 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 2 | -0.502445 | 0.0 | 0.0 | 1.0 | Mr | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | 1 | 38.0 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.786845 | 1.0 | 0.0 | 0.0 | Mrs | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | 1 | 26.0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1 | -0.488854 | 0.0 | 0.0 | 1.0 | Miss | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 1 | 35.0 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.420730 | 0.0 | 0.0 | 1.0 | Mrs | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 0 | 35.0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.486337 | 0.0 | 0.0 | 1.0 | Mr | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
이제 Age의 결측치를 채운 후 시각화해보자.
train['Age'] = train['Age'].fillna(train.groupby('Title')['Age'].transform('median'))
plt.figure(figsize=(10, 6))
sns.distplot(train['Age'])
plt.show()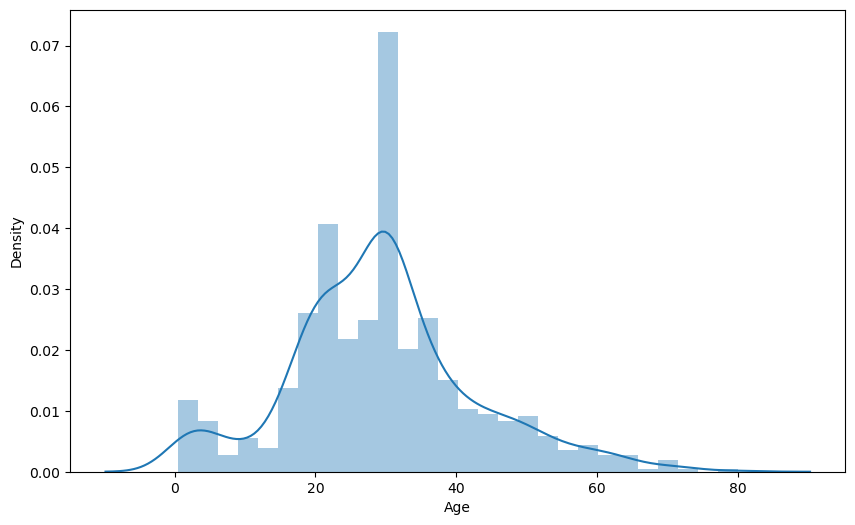
데이터의 범위가 크기 때문에 스케일링 작업을 거쳐야 할 것 같다고 판단하였다. 스케일링 작업 이후 최종적으로 Title은 제거해주었다.
scaler_Age = StandardScaler()
label_Age = train['Age'].values.reshape(-1, 1)
scaler_Age.fit(label_Age)
label_Age = scaler_Age.transform(label_Age)
train_Age = pd.DataFrame(label_Age, columns=['Age_scaled'])
train = pd.concat([train, train_Age], axis=1)
train = train.drop(['Age'], axis=1)
train.head()| Survived | SibSp | Parch | Pclass_1 | Pclass_2 | Pclass_3 | female | male | Family | Fare_scaled | Embarked_C | Embarked_Q | Embarked_S | Title | Master | Miss | Mr | Mrs | Other | Age_scaled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 2 | -0.502445 | 0.0 | 0.0 | 1.0 | Mr | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | -0.557365 |
| 1 | 1 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.786845 | 1.0 | 0.0 | 0.0 | Mrs | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.649713 |
| 2 | 1 | 0 | 0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1 | -0.488854 | 0.0 | 0.0 | 1.0 | Miss | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | -0.255596 |
| 3 | 1 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.420730 | 0.0 | 0.0 | 1.0 | Mrs | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.423386 |
| 4 | 0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.486337 | 0.0 | 0.0 | 1.0 | Mr | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.423386 |
이제 학습 데이터셋의 전처리를 완료했다. 테스트 데이터셋의 데이터도 동일한 방식으로 전처리 해주면 된다. 단, 테스트 데이터셋에서 결측치를 채울 때에는 groupby를 사용할 수 없다. 왜냐하면 실제 환경에서 테스트 데이터는 데이터셋이 입력되는것이 아니라 말 그대로 데이터가 한줄씩 입력된다. 테스트 데이터셋에서 groupby를 사용한다는 것은 모든 데이터의 값을 이미 알고 있다는 전제이므로 예언자가 아닌 이상 불가능한 가정이기 때문이다.
최종 전처리 결과이다.
| Survived | SibSp | Parch | Pclass_1 | Pclass_2 | Pclass_3 | female | male | Family | Fare_scaled | Embarked_C | Embarked_Q | Embarked_S | Master | Miss | Mr | Mrs | Other | Age_scaled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 2 | -0.502445 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | -0.557365 |
| 1 | 1 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.786845 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.649713 |
| 2 | 1 | 0 | 0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1 | -0.488854 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | -0.255596 |
| 3 | 1 | 1 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 2 | 0.420730 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.423386 |
| 4 | 0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.486337 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.423386 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 0 | 0 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1 | -0.386671 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | -0.180153 |
| 887 | 1 | 0 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1 | -0.044381 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | -0.783692 |
| 888 | 0 | 1 | 2 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 4 | -0.176263 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | -0.632808 |
| 889 | 1 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1 | -0.044381 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | -0.255596 |
| 890 | 0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.492378 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.197059 |
891 rows × 19 columns
| SibSp | Parch | Pclass_1 | Pclass_2 | Pclass_3 | female | male | Family | Fare_scaled | Embarked_C | Embarked_Q | Embarked_S | Master | Miss | Mr | Mrs | Other | Age_scaled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.490783 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.385665 |
| 1 | 1 | 0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 2 | -0.507479 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.328695 |
| 2 | 0 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1 | -0.453367 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 2.460330 |
| 3 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.474005 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | -0.180153 |
| 4 | 1 | 1 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 3 | -0.401017 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | -0.557365 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 413 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.486337 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.046174 |
| 414 | 0 | 0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1 | 1.544246 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.725155 |
| 415 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.502445 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.687434 |
| 416 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 1 | -0.486337 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.046174 |
| 417 | 1 | 1 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 3 | -0.198244 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.953049 |
418 rows × 18 columns
5. AI 모델선정
- 타이타닉 데이터셋의 목적이 탑승객의 생존여부를 분류하는 이진분류이기 때문에 이진분류에 적절한 AI모델을 선정해보자. 나는 모델 선정을 위해
LazyPredict를 이용하기로 했다.
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from lazypredict.Supervised import LazyClassifier6. 데이터 스플릿
데이터를 모델에 학습시키기 위해 일정 비율로 분리하는 작업이다(train, validation). 학습 데이터를 모델에 100% 학습시키는 경우, 해당 데이터에 대해 과적합(over-fitting)될 가능성이 높아지기 때문에 학습 데이터를 일정 부분 나누어 학습 중간 중간 검증하는 용도로 사용한다.
X = train.drop(['Survived'], axis=1).values
y = train['Survived'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
X_train.shape, X_test.shape, y_train.shape, y_test.shape((712, 18), (179, 18), (712,), (179,))
7. 모델 학습 및 모델 평가
clf = LazyClassifier(verbose=0, ignore_warnings=True, custom_metric=None)
models, predictions = clf.fit(X_train, X_test, y_train, y_test)
models| Model | Accuracy | Balanced Accuracy | ROC AUC | F1 Score | Time Taken |
|---|---|---|---|---|---|
| LinearDiscriminantAnalysis | 0.90 | 0.87 | 0.87 | 0.90 | 0.03 |
| RidgeClassifierCV | 0.90 | 0.87 | 0.87 | 0.90 | 0.01 |
| RidgeClassifier | 0.90 | 0.87 | 0.87 | 0.90 | 0.02 |
| LogisticRegression | 0.89 | 0.87 | 0.87 | 0.89 | 0.01 |
| LinearSVC | 0.89 | 0.86 | 0.86 | 0.89 | 0.04 |
| CalibratedClassifierCV | 0.89 | 0.86 | 0.86 | 0.89 | 0.03 |
| PassiveAggressiveClassifier | 0.88 | 0.86 | 0.86 | 0.88 | 0.01 |
| NuSVC | 0.89 | 0.86 | 0.86 | 0.89 | 0.04 |
| SVC | 0.89 | 0.85 | 0.85 | 0.89 | 0.04 |
| Perceptron | 0.87 | 0.85 | 0.85 | 0.87 | 0.01 |
| SGDClassifier | 0.87 | 0.85 | 0.85 | 0.87 | 0.01 |
| AdaBoostClassifier | 0.86 | 0.84 | 0.84 | 0.86 | 0.11 |
| LGBMClassifier | 0.86 | 0.84 | 0.84 | 0.86 | 0.07 |
| KNeighborsClassifier | 0.87 | 0.84 | 0.84 | 0.87 | 0.12 |
| GaussianNB | 0.85 | 0.84 | 0.84 | 0.86 | 0.01 |
| NearestCentroid | 0.87 | 0.83 | 0.83 | 0.86 | 0.05 |
| XGBClassifier | 0.85 | 0.83 | 0.83 | 0.85 | 0.10 |
| BaggingClassifier | 0.85 | 0.83 | 0.83 | 0.85 | 0.04 |
| RandomForestClassifier | 0.85 | 0.83 | 0.83 | 0.85 | 0.21 |
| BernoulliNB | 0.85 | 0.83 | 0.83 | 0.85 | 0.01 |
| DecisionTreeClassifier | 0.83 | 0.82 | 0.82 | 0.83 | 0.01 |
| ExtraTreesClassifier | 0.82 | 0.80 | 0.80 | 0.82 | 0.16 |
| LabelSpreading | 0.82 | 0.80 | 0.80 | 0.82 | 0.04 |
| LabelPropagation | 0.82 | 0.80 | 0.80 | 0.82 | 0.04 |
| ExtraTreeClassifier | 0.80 | 0.77 | 0.77 | 0.80 | 0.01 |
| QuadraticDiscriminantAnalysis | 0.67 | 0.52 | 0.52 | 0.59 | 0.01 |
| DummyClassifier | 0.68 | 0.50 | 0.50 | 0.55 | 0.01 |
LinearDiscriminantAnalysis모델과 RidgeClassifierCV모델의 결과가 가장 좋았다. RidgeClassifierCV모델로 학습하여 kaggle에 답을 제출해보자.
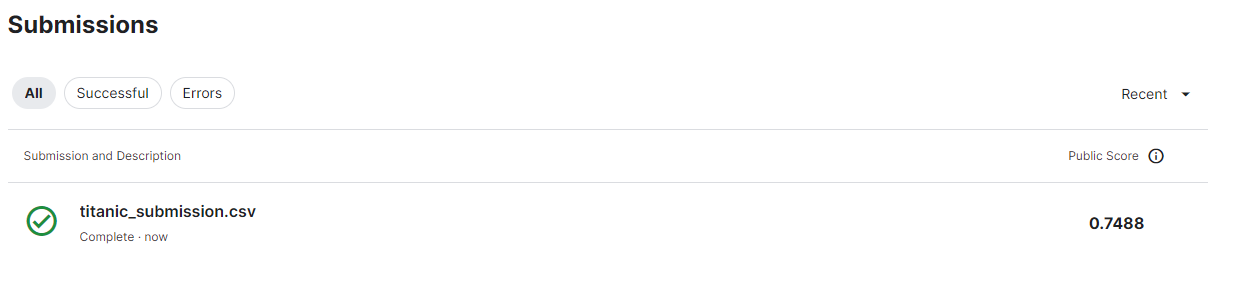
최종적으로 0.7488의 정답률을 기록하였다.
