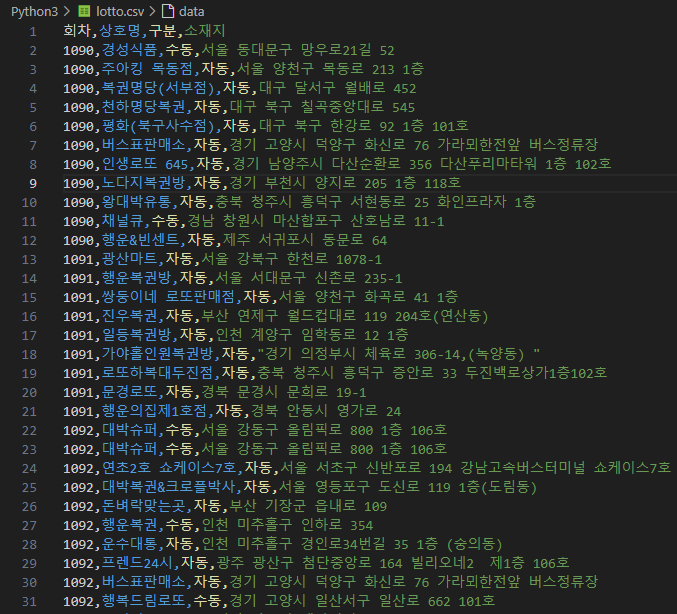
Python을 이용해서 크롤링 실습을 해보자.
크롤링이란?
크롤링(Crawling)의 사전적 의미는 기어다닌다는 의미이다. 말 그대로 웹상을 기어다니며 데이터를 긁어모은다는 뜻이다. 엄연히 구분하자면 웹 스크래핑과 구분할 수 있지만, 이 글에서는 따로 구분하지 않겠다.
크롤링 실습
크롤링 할 사이트 접속하기
본 실습에서는 동행복권 홈페이지를 접속해 회차별 1등 판매점의 정보를 가져와보도록 하겠다.
우선 웹 크롤링을 위해서는 두 가지 정도의 파이썬 라이브러리가 필요하다.
import requests
from bs4 import BeautifulSoup
import pandas as pdHTTP Request패킷을 전송해야 하기 때문에 requests라이브러리를 이용하고, 가져온 정보를 좀 더 손쉽게 처리하기 위해 BeautifulSoup라이브러리를 사용한다.
또한, 크롤링한 데이터를 데이터 프레임에 저장하고 CSV로 뽑아내기 위해 pandas를 같이 이용했다.
크롤링할 사이트에 접속해보자.
동행복권 회차별 당첨 판매점
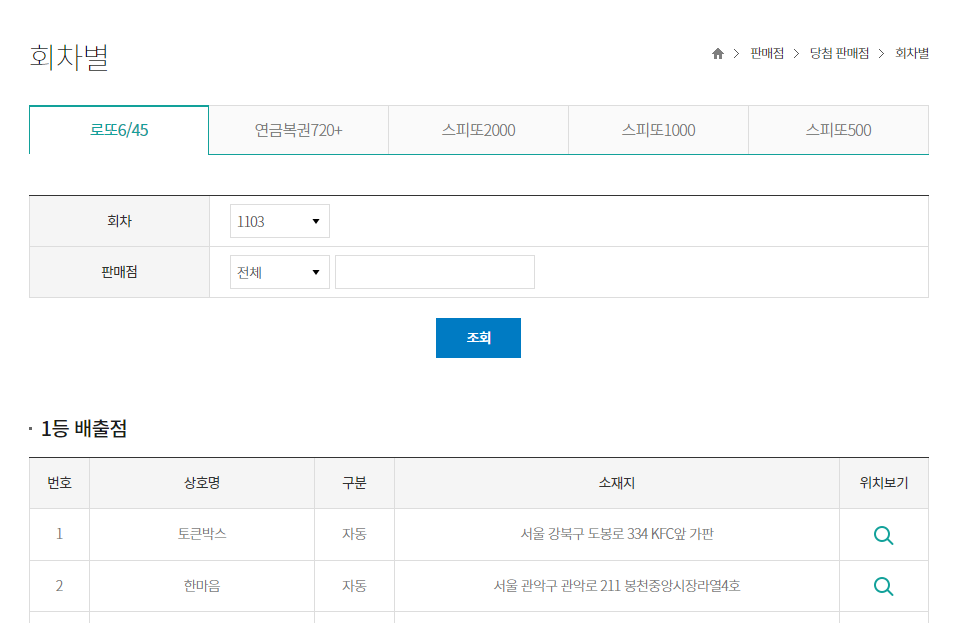
우리가 할 일은 1등 배출점의 상호명과 구분, 소재지를 가져오는 것이다.
우선 해당 페이지는 POST방식이므로 크롬의 개발자 도구를 이용해서 어떤 파라미터 값을 전송하는지 확인하자.
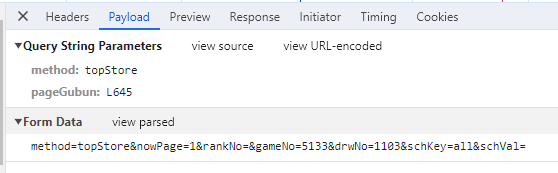
이 페이지는 method=topStore&nowPage=1&rankNo=&gameNo=5133&drwNo=1103&schKey=all&schVal=라는 정보를 HTTP Body에 실어서 POST방식으로 전달하는 구조이다. 우리는 회차별 1등 배출점의 정보를 가져올 것이기 때문에 우리가 봐야할 곳은 drwNo=1103이다. 저 부분을 반복문을 이용해서 값을 바꿔준다면 반복적으로 다른 회차의 정보를 가져올 수 있을것이다.
url = r'https://dhlottery.co.kr/store.do?method=topStore&pageGubun=L645'
num_list = [] # 회차
name_list = [] # 상호명
category_list = [] # 구분
address_list = [] # 소재지우선 url변수에 홈페이지 링크를 입력해주고, 각각의 데이터를 보관할 리스트를 선언했다.
# 1090 ~ 1103회차
for i in range(1090, 1104):
# POST 방식으로 요청
post_data = {'method':'topStore', 'nowPage':'1', 'rankNo':'', 'gameNo':'5133', 'drwNo':str(i), 'schKey':'all', 'schVal':''}
response = requests.post(url, data=post_data)
# 응답 데이터를 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 상호명, 구분, 소재지 추출
name = soup.select('#article > div:nth-child(2) > div > div:nth-child(4) > table > tbody > tr > td:nth-child(2)')
category = soup.select('#article > div:nth-child(2) > div > div:nth-child(4) > table > tbody > tr > td:nth-child(3)')
address = soup.select('#article > div:nth-child(2) > div > div:nth-child(4) > table > tbody > tr > td:nth-child(4)')
# 추출한 데이터를 리스트에 저장 및 출력
for j in range(len(name)):
num_list.append(i)
name_list.append(name[j].text)
category_list.append(category[j].text.strip())
address_list.append(address[j].text)
print(i, name[j].text, category[j].text.strip(), address[j].text)크롬의 개발자 도구를 이용해서 각각의 셀렉터를 복사해준 후 BeautifulSoup의 select함수를 사용하여 각각의 정보를 불러와준 후 텍스트 정보만 리스트에 저장해주며 출력해보았다.
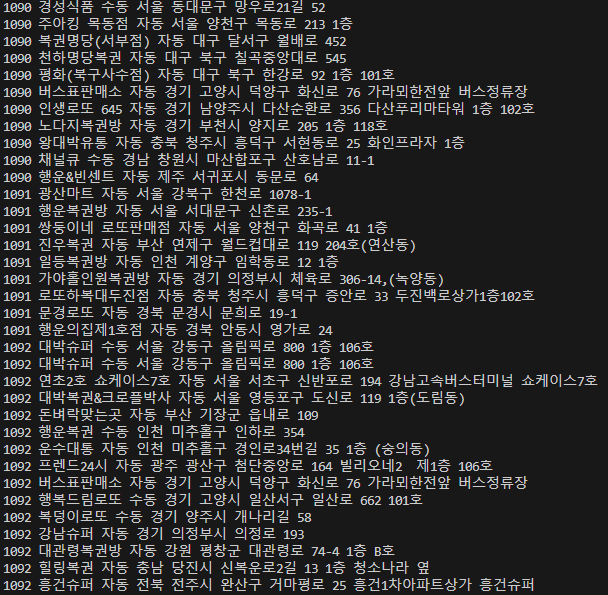
잘 가져와지는것을 확인했다. 이제 pandas라이브러리를 이용하여 CSV파일로 저장해보자.
# 데이터 프레임 생성 및 csv 파일로 저장
df = pd.DataFrame(zip(num_list, name_list, category_list, address_list), columns=['회차', '상호명', '구분', '소재지'])
df.to_csv('lotto.csv', index=False, encoding='utf-8-sig')이후, 저장된 CSV파일의 모습이다.