VERITROSS (4기) System team에 들어온 후에...
발표를 잘했다는 평가를 받아 좀 뿌듯했던 첫 세미나...
의 내용을 기록하기 위한 글
이번 글에서 리뷰할 논문은 아래와 같습니다.
WiscKey: Separating Keys from Values in SSD-Conscious Storage, Lanyue Lu et al. (2017)
https://dl.acm.org/doi/abs/10.1145/3033273
논문에서 제시하는 내용:
WiscKey, an SSD-conscious persistent key-value store derived from the popular LSM-tree implementation, LevelDB.
Key idea: Separation of keys and values
1. Introduction
-
LSM-tree...
-
Is not optimized to SSD, and is HDD friendly
- LSM-tree requires many sequential I/O to avoid random I/O
: Maintains keys & values in sorted order
→ Unnecessary & Waste of bandwidth
SSDs don’t have much difference in performance between sequential and random I/O -
LSM-tree should be designed to efficiently utilize SSD’s internal parallelism
-
LSM-tree’s high Write Amplification reduces SSD’s life span
하드디스크에서의 random I/O는 sequential I/O 보다 100배 이상 느리다.
그러한 이유로 LSM-tree는 random I/O를 가능한 피하기 위해 항상 key와 value를 sorting된 상태로 유지하면서 많은 sequential I/O를 수행한다.
그렇다 보니 어떤 data들은 여러번 read와 write가 되는 일도 생기게 된다.
이 방식은 HDD의 입장에서는 효율적이지만 SSD의 입장에서는 불필요하게 bandwidth를 낭비하는 것이 된다.
왜냐하면 HDD와 다르게 SSD는 sequential access와 random access의 성능 차이가 그렇게 크지 않기 때문이다.
SSD는 internal parallelism이 굉장히 잘 이루어진다는 큰 장점을 가지고 있다.
그런데 LSM-tree는 그 특성을 잘 활용하지 못하고 있기 때문에 SSD 위에서는 LSM-tree가 이를 잘 활용하도록 하는 설계가 필요하다.
-
WiscKey ...
Separates keys from values
→ Only keys are sorted ! -
Avoids the unnecessary movement of values while sorting
→ Significantly reduces write amplification -
The size of the LSM-tree is noticeably decreased
→ Fewer device reads & better caching during lookups -
Retains the benefits of LSM-tree technology
: Excellent insert & lookup performance,
But without excessive I/O amplification
WiscKey는 key와 value의 분리를 통해 I/O amplification을 줄이려 하는데,
key와 value를 분리하면 sorting시에 key만 이동시키기 때문에 write amplification을 줄일 수 있다.
또한 LSM-tree에 key만 저장되기 때문에 size가 확연히 줄어서 lookup시의 read amplification 도 줄일 수 있다.
- Challenges & Solutions
- Solves range-query performance issue using SSD internal parallelism
- Solves garbage collection problem with online & lightweight garbage collector
- Guarantees crash consistency using modern file system property
하지만 key value의 분리는 기존의 LSM-tree의 설계구조와 다르기 때문에 해결해야 할 문제들이 발생한다.
먼저, Key가 sorting될때 value가 같이 sorting되지 않기 때문에, range query 성능에 영향을 미칠 수 있다.
WiscKey는 SSD 장치의 풍부한 internal parallelism을 이용하여 이 문제를 해결한다.
두번째로는, WiscKey에서는 key의 삭제가 발생하면 key만 삭제되고 value는 따로 분리되어 있기 때문에 value를 삭제할 새로운 garbage collection 기술이 필요하다.
이 부분은 효율적인 garbage collector를 도입해서 해결한다.
세번째로, crash consistency의 유지가 어려워진다.
WiscKey는 현대의 file system의 속성을 활용해 이를 해결한다.
2. Background and Motivation
1. Log-Structured Merge-Tree (LSM-tree)
- Provides efficient indexing
- Defers & batches data writes into large chunks to use high sequential bandwidth of HDDs
- Random writes are nearly two orders of magnitude slower than
sequential writes on HDD
→ LSM-trees provide better write performance than
traditional B-trees (which require random accesses)
LSM-tree는 key-value database에서 사용되는 자료구조이고,
효율적인 indexing을 제공하며 write를 지연시키고 batch를 통해 hard disk의 좋은 sequential write 성능을 활용한다.
LSM-tree Structure
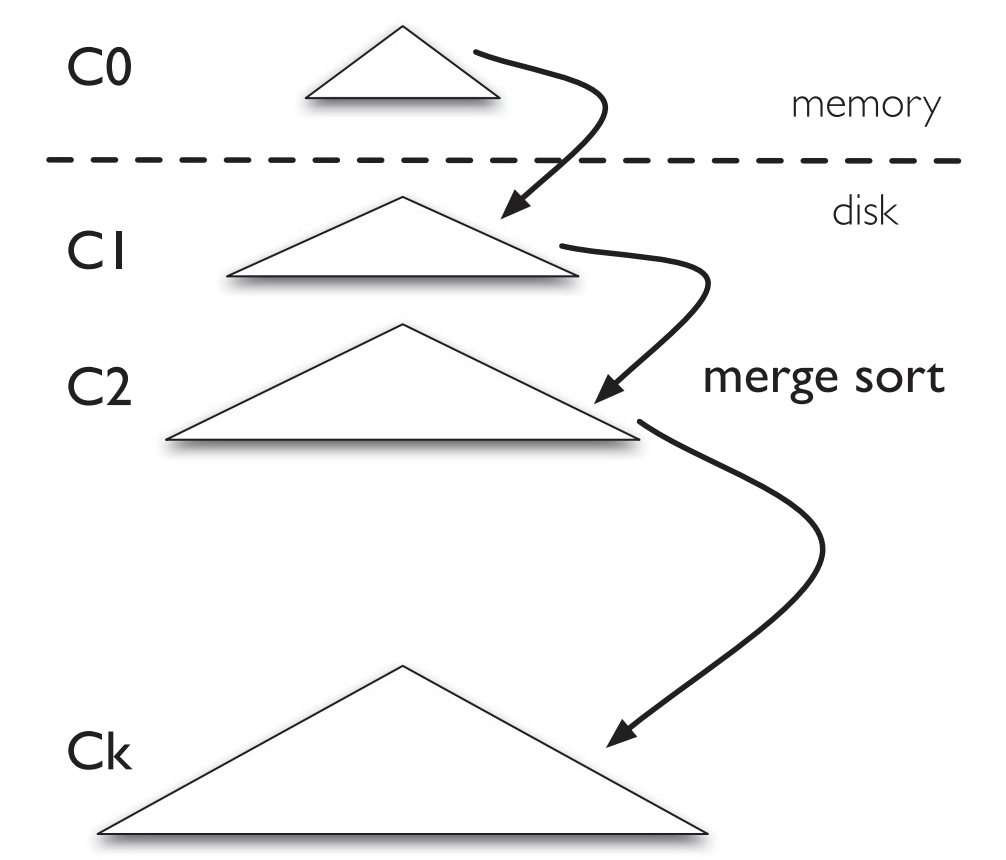
- Number of components of exponentially increasing sizes,
C0 to Ck - C0 : Memory-resident update-in-place sorted tree
- C1 ~ Ck : Disk-resident append-only B-trees.
Insertion
- Inserted KV pair → Log (On-disk, sequential, for crash recovery)
- KV → C0 (In-memory, sorted by keys)
- C0 reaches its size limit → Compaction
- Merge sort to C1 (On-disk)
- Newly merged C1 → Written to disk sequentially, replacing the old version of C1
- Ci reaches size limit → Compaction (Ci → Ci+1)
- Compaction : Executed asynchronously in the background.
KV pair 삽입시, 먼저 Disk상의 Log에 저장한 후(crash consistency를 위한 backup), Memory상의 C0에 저장한다.
C0가 다 차면 Disk상의 C1으로 내리는데 merge sort와 유사한 방식으로 이루어진다.
이 과정을 compaction이라고 한다.
C1이 다 차면 C2로의 compaction이 이루어질 것이고, 그렇게 Ci에서 Ci+1로의 compaction이 background에서 계속 일어날 것이다.
그리고 당연히 낮은 Component일수록 가장 최신의 data를 저장하고 있을 것이다.
KV의 삽입은 예전에 이미 삽입이 된 Key에 대해서도 일어날 수 있다.
같은 Key에 대한 KV가 여러 Component들에 걸쳐 여러개 존재할 경우 valid한 KV는 더 낮은 Component에 존재하는, 더 최신의 KV이다.
Lookup
- LSM-trees may need to search multiple components
(C0 contains the freshest data, followed by C1, and so on) - Searches components starting from C0 in a cascading
fashion
- Until it locates the desired data in the smallest component Ci - LSM-trees are most useful when inserts are more common than lookups
LSM-tree는 찾고자 하는 KV pair의 위치에 도착할때까지 C0부터 차례대로 탐색한다.
B-tree에 비해 더 많은 read를 수행해야 하는 경우가 적지 않을 것이기 때문에, LSM-tree는 lookup보다 insert가 주로 수행되는 환경에서 유용하다.
2. LevelDB
- LSM-tree based Key-value store
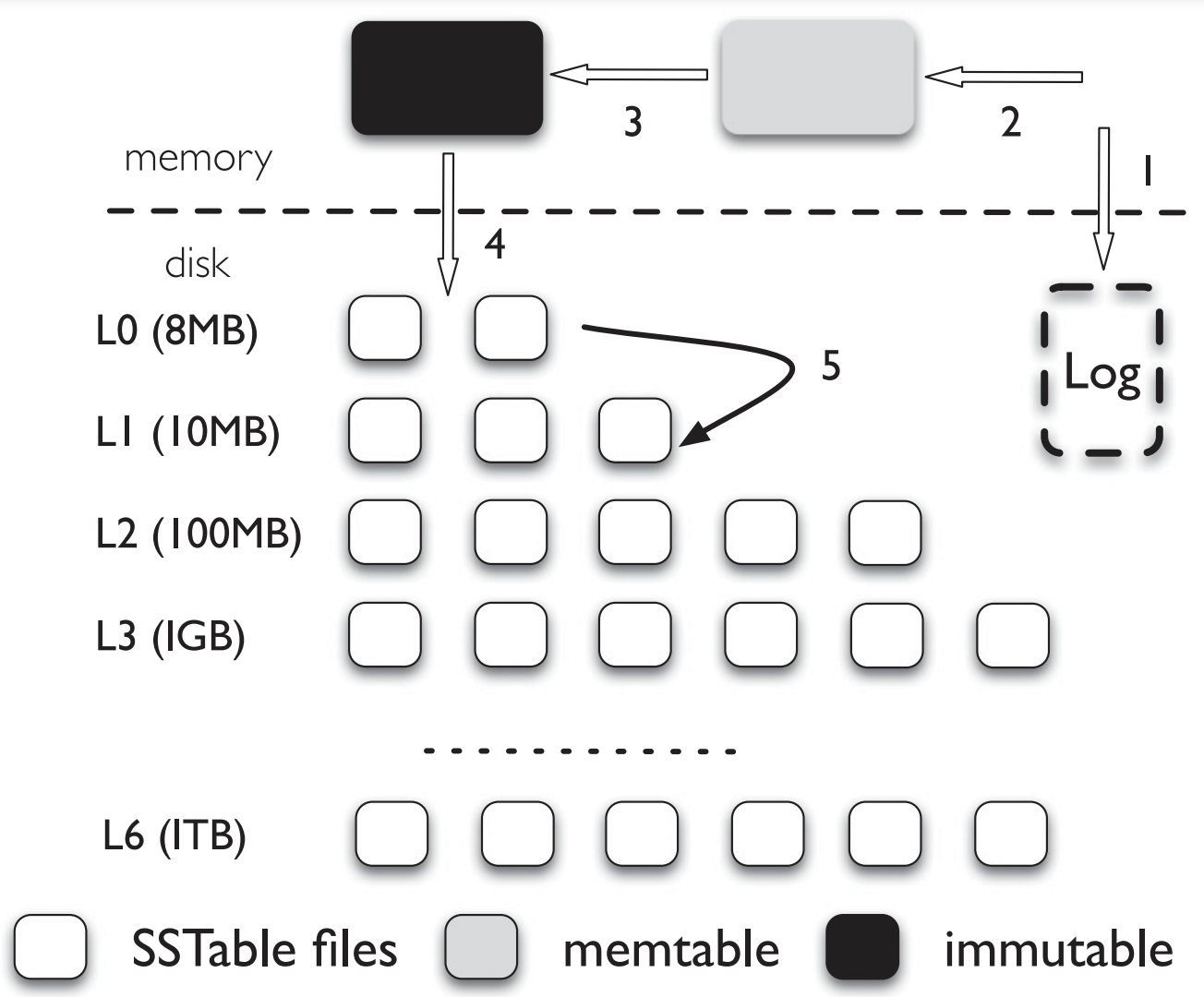
Insertion
- Inserted KV pair → Log (On-disk)
- KV → Memtable (In-memory, sorted by keys)
- Memtable reaches its size limit → New Memtable, Log
- In the background, Memtable is converted into Immutable
- Compaction thread → Minor Compaction
- Flushes to L0 (On-disk), as a new SSTable file
- Discard the previous Log file
KV pair가 삽입되면 먼저 Disk상의 Log에 저장한 후, Memory 상의 Memtable에 저장한다.
Memtable이 다 찼을 경우 LevelDB는 새로운 Memtable과 Log로 전환을 하고,
background에서는 Memtable을 Immutable memtable로 전환시킨다.
Immutable memtable은 compaction thread에 의해 Disk로, 정확히는 L0로 flush된다.
이 과정을 Minor compaction이라고 한다.
그렇게 L0에는 새로운 SSTable file이 생기게 된다.
그 다음 이전의 Log file이 삭제된다.
LevelDB Structure
-
The size of all files in each level is limited
- Increases by a factor of 10 with the level number. -
To maintain the size limit...
a. Li reaches its size limit → Major Compaction
b. Compaction thread → Choose one file from Li
- Merge sort with all the overlapped files of Li+1
- Generate new Li+1 SSTable files
- Continues until all levels are within their size limits -
All files in L1 ~ do not overlap in their key ranges
-
Keys in files of L0 can overlap (since they are directly flushed from the memtable)
SSTable Structure
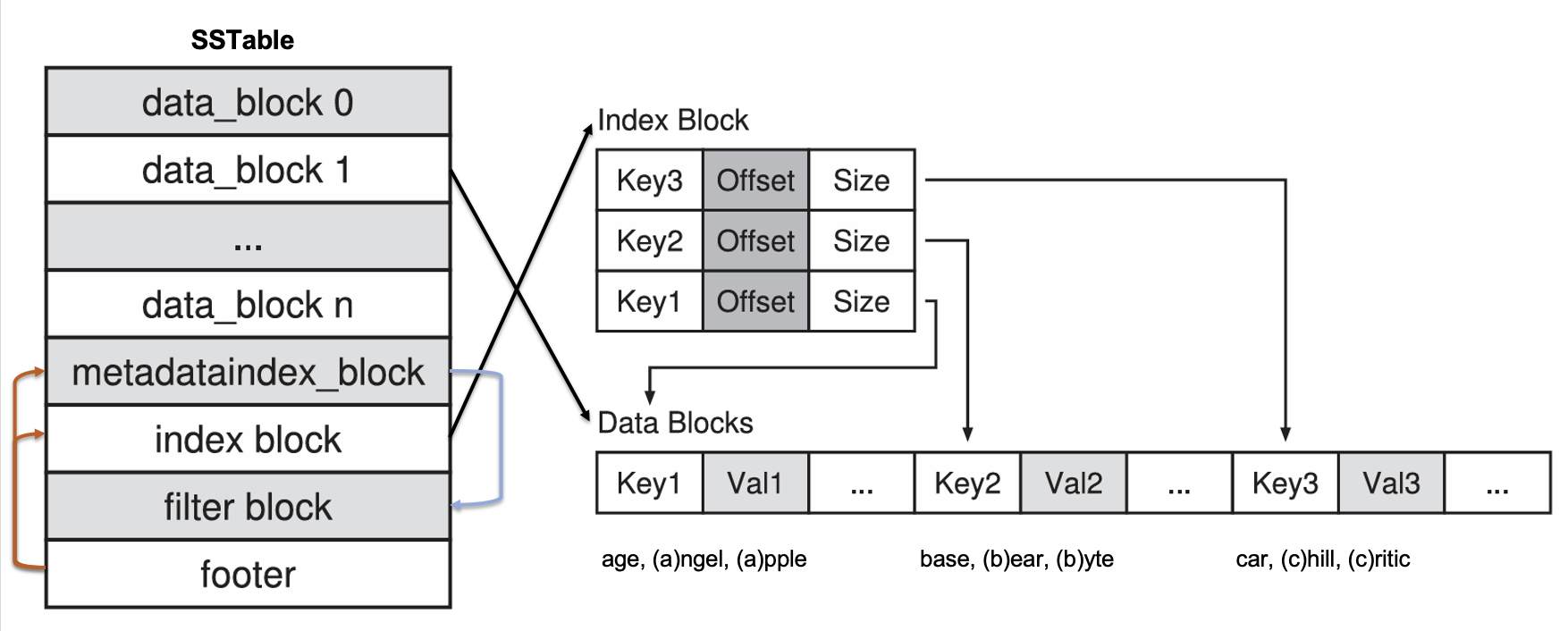
- Data blocks
- For 16(by default) KV pairs, stores only a suffix of each key, ignoring the prefix it shares with the previous key - Index blocks
- <key, offset, size> for each data block- Key points the first key in the block
- Medatata index block
- Pointer to the filter block - Filter block
- Bloom filter for the file - Footer block
- Pointer to the index blocks & metadata index block
Lookup
- Memtable
- Immutable
- L0 → ... → L6
KV 쌍을 검색할 때에는 먼저 memtable을 찾고 없을 경우 immutable, 없을 경우 L0부터 높은 Level로 들어가며 찾는다.
Write and Read Amplification
-
I/O Amplification
- [Amount of data requested by the user] : [Amount of data written to (read from) storage device] -
Read Amplification
- LevelDB may need to check multiple levels
- LevelDB needs to read multiple metadata blocks within the SSTable file -
Write Amplification
- LevelDB writes more data than necessary to achieve mostly sequential disk access
- Moves file across multiple levels during compaction
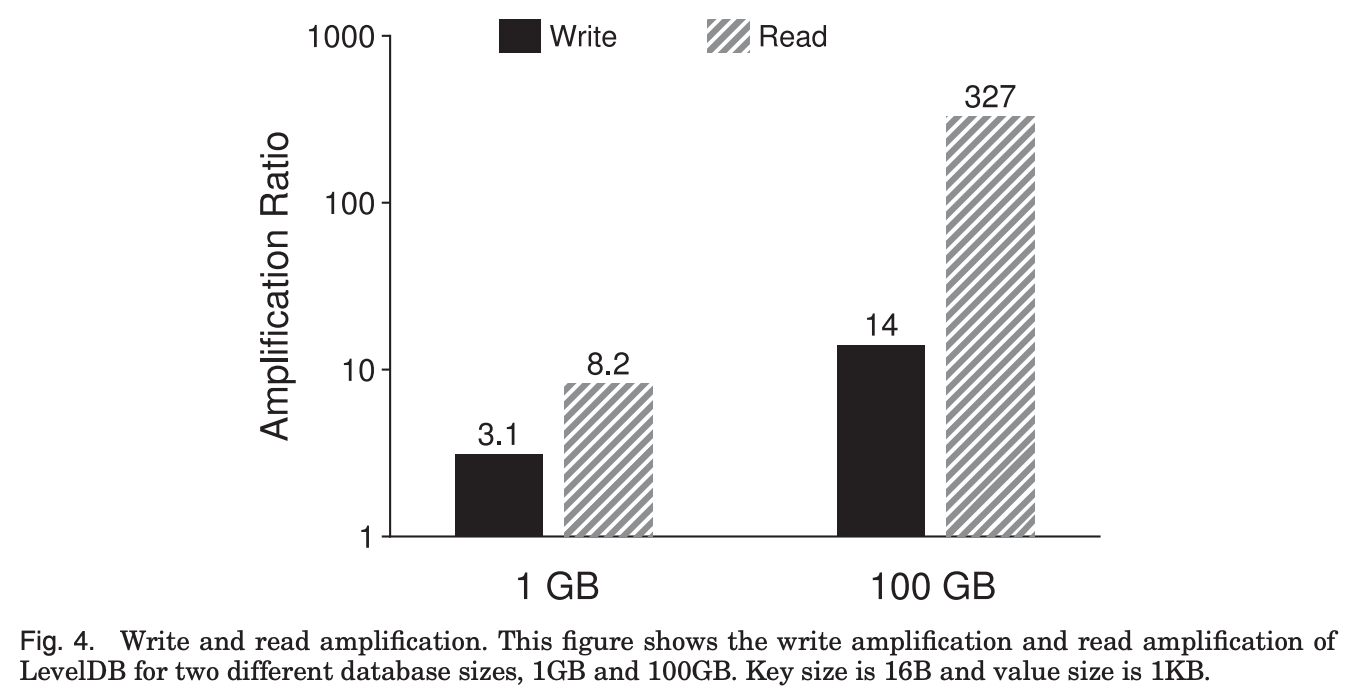
이 그래프는 실제 LevelDB에서의 amplification을 측정한 결과이다.
1KB key-value로 database를 load한 다음 100,000개의 entry에 대해서 lookup을 수행하였더니,
1GB database 보다 100GB database에서 write amplification이 더 큰데,
database의 크기가 크니까 key-value 쌍이 더 깊은 level로 들어갔을 가능성이 높아져서 compaction을 할때 data write를 더 여러번 할수밖에 없기 때문이다.
그리고 read amplification도 100GB database에서 훨씬 큰데,
작은 database의 경우 SSTable의 index block과 bloom filter들이 memory에 모두 cache가 될 수 있지만,
큰 database는 각각의 lookup마다 다 다른 SSTable file을 확인하면서 index block이랑 bloom filter를 읽어야 하는 경우가 생길 수 있어서 비용이 더 들게 된다.
3. WiscKey + 4. Evaluation
LSM-trees are not optimal for modern SSDs…
WiscKey
→ Derived from LevelDB
For SSD-optimized key-value store,
- Four critical ideas
- Separating keys from values
- Using parallel random-read characteristic of SSD
- Utilizing unique crash consistency & garbage collection techniques
- Removing LSM-tree log
- Design Goals
- Low write amplification
- Low read amplification
- SSD optimized
- Feature-rich API
- Realistic key-value sizes
기존의 LSM tree는 compaction시에 계속해서 SSTable을 정렬해야 했고, 이는 성능을 낮추는 원인이 되었다.
그런데 WiscKey에서는 key와 value가 분리되어,
Key만 LSM-tree에 둬서 compaction시에 key만 sorting을 하고 value는 따로 Value Log라는 곳에 두고 관리한다.
따라서 LSM-tree의 size가 많이 줄어들고, write amplification도 줄일 수 있다.
WiscKey Data Layout
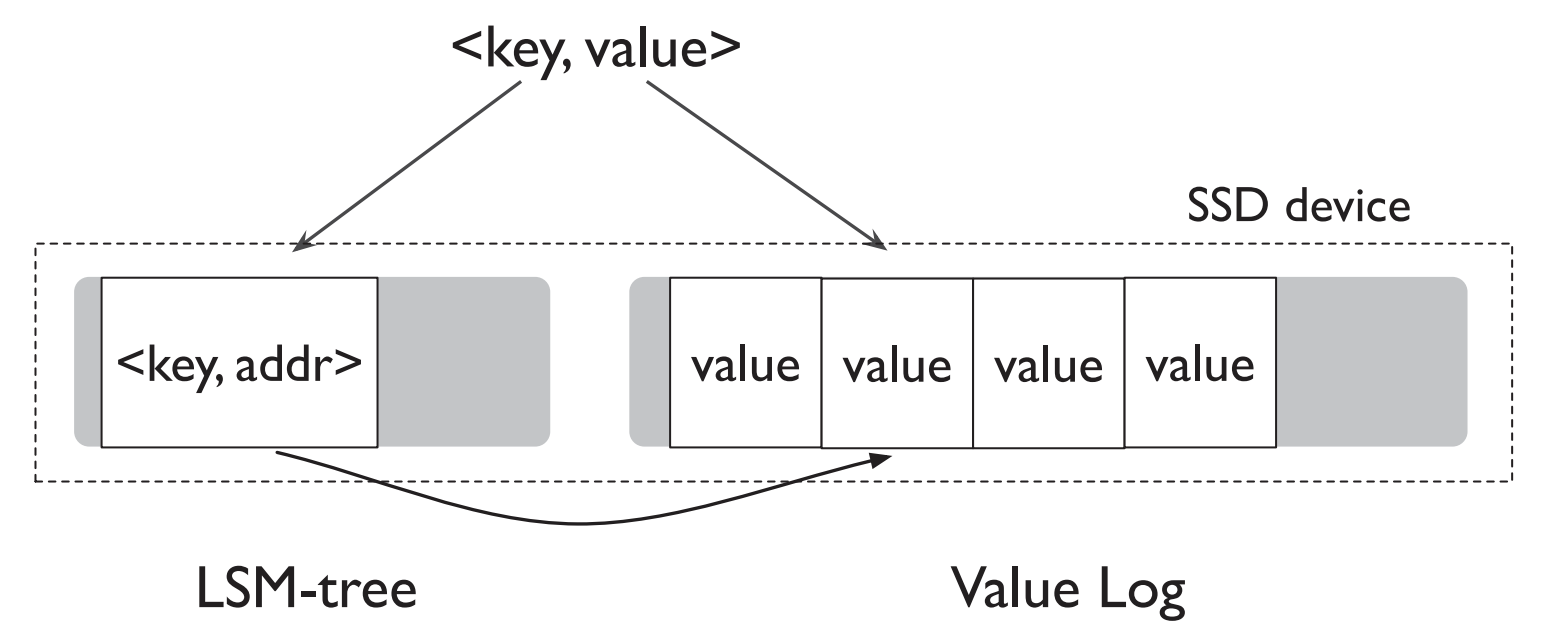
- Keys & Values' locations → LSM-tree
- Values → Value Log file
Lookup
- Searches LSM-tree for the key & the value's location
- Reads Value Log to retrieve the value
- Won't the extra I/O to retrieve value make the lookup slower?
→ No !- Will likely search fewer levels of table files in the LSM-tree
- Furthermore, a significant portion of the LSM-tree can be easily cached in memory
- Each lookup only requires a single random read (for retrieving the value) → Achieves better lookup performance than LevelDB !
Lookup시에는 LSM tree에서 key와 value address 를 찾는다.
그 다음 실제 value를 얻기 위한 read를 수행한다.
그럼 value를 읽기 위해 read가 추가적으로 필요한거면, 더 느려지는게 아닌가 하는 의문이 생길 수 있다.
그런데 그렇지 않다.
왜냐하면, 일단 LSM-tree 크기가 훨씬 작고, 따라서 memory에 쉽게 cache가 될 수 있어서 한번의 random read만으로 value를 얻을 수 있다.
이를 검증하기 위해 논문에서 성능 평가를 진행하였다.
- Experimental Setup
Machine: 2 Intel Xeon CPU E5-2667 v2 @ 3.30GHz processors, 64GB memory
OS: 64-bit Linux 3.14
FS: Ext4
Storage device: 500GB Samsung 840 EVO SSD
- Sequential read: 500MB/s
- Sequential write: 400MB/s
- Random read: ↓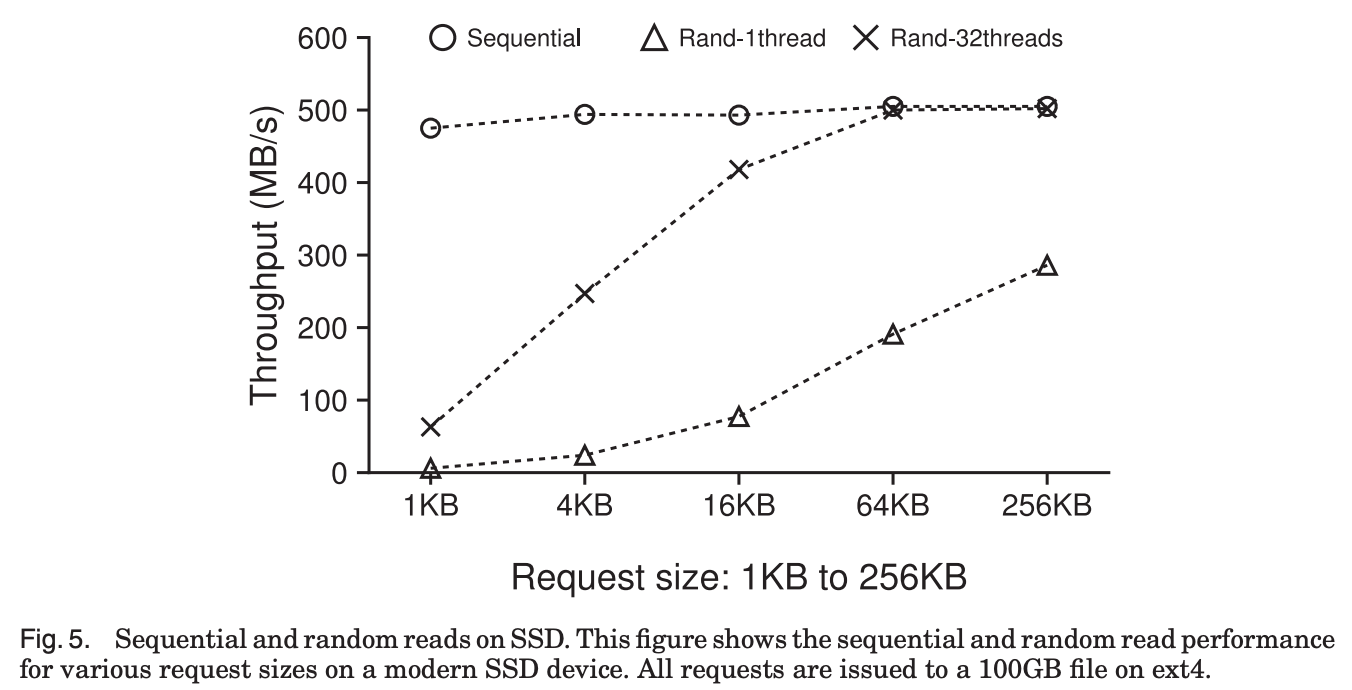
Evaluation
LevelDB와 Wisckey의 point query 성능을 비교해보겠다.
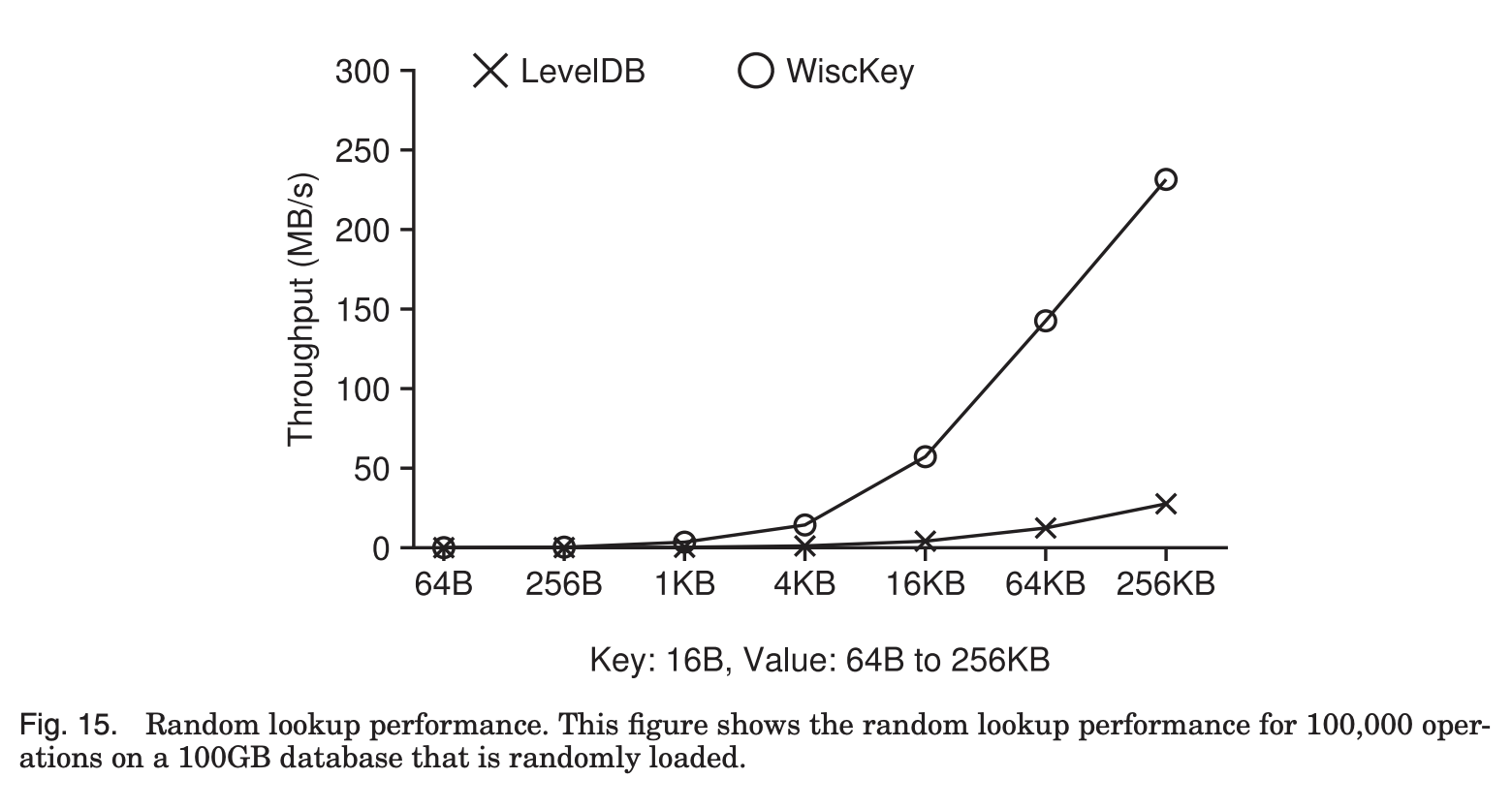
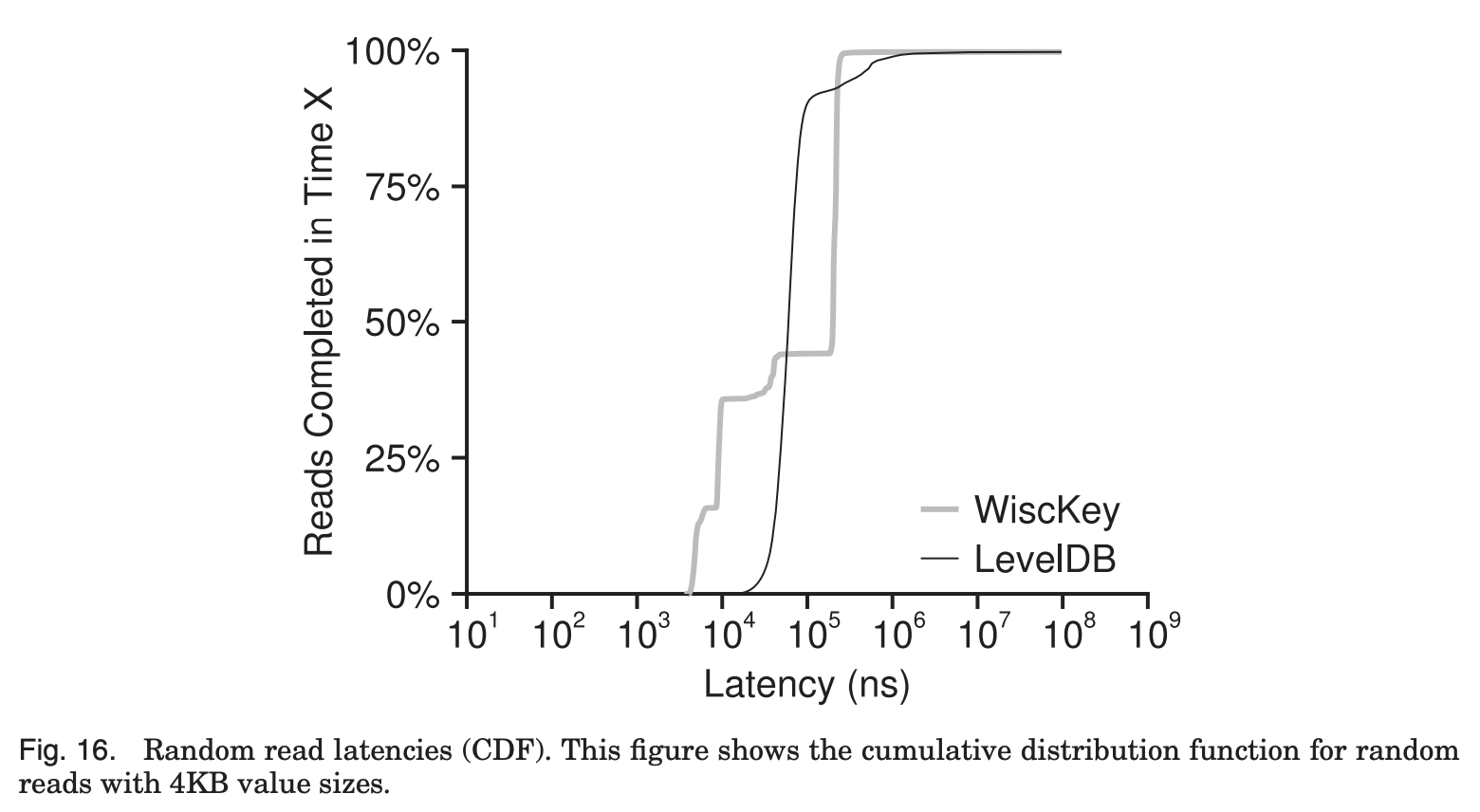
Fig. 15은 random load된 100GB 데이터베이스에 대해 10만번 random lookup을 수행했을때의 throughput의 비교이다.
Key와 value의 분리로 Wisckey의 read는 LSM-tree와 vLog를 모두 확인해야 해서 성능 저하가 우려됐는데,
첫번째 그래프를 보면 Wisckey의 throughput이 훨씬 빠른것을 알 수 있다.
이유는 앞에서 언급했듯이 LSM-tree의 사이즈가 확연히 작아 read amplification의 정도가 낮고, compaction시에도 I/O의 부담이 적기 때문에 성능이 더 뛰어난 것이다.
Fig. 16은 random read latency의 CDF를 나타낸다.
x축이 지연시간, y축이 x축의 시간 내에 완료된 작업을 백분율로 나타내고 있는데,
각 latency 시간내에 어느 정도의 작업이 완료되었는지를 보여주는 그래프로 이해하면 된다.
WiscKey와 LevelDB가 교차되는 point를 보면 WiscKey는 LevelDB에 비해서 요청의 대략 절반이 현저히 적은 latency를 발생시키는 것을 볼 수 있다.
그 이유는 LSM-tree의 size가 작으면 memory에 cache되는 부분이 많아지므로 더 빠른 접근이 가능해지기 때문이다.
하지만 일부 Lookup operation에 대해서는 vLog에 random access를 하는 cost 때문에 LevelDB보다 느림을 알 수 있다.
Insertion
- User inserts a key-value pair
- The value is appended to the vLog
- The key is inserted into the LSM-tree, along with the value address ( <vLog-offset, value-size> )
Insertion이 수행될 때에는,
사용자가 key-value 쌍을 삽입하면, value는 vLog에 append되고, key는 LSM-tree에 value 주소와 함께 저장된다.
Deletion
- Deletes a key from the LSM-tree, without accessing the vLog
- Invalid values in the vLog (which doesn’t have corresponding keys in the LSM-tree)
→ Garbage collected later
먼저 LSM tree에서 key 삭제만 수행한다.
그러면 vLog에는 대응되는 key를 잃어버려서 invalid한 value가 생기게 되고, 그런 value들은 garbage collection으로 수거된다.
Garbage Collection
- WiscKey reads a chunk of key-value pairs from the tail of the vLog
- Finds which of those values are valid(not yet overwritten/deleted) by querying the LSM-tree
- Appends valid values back to the head of the vLog
- Frees the space occupied by the chunk
- Updates the tail accordingly
WiscKey가 vLog의 tail부터 시작해서 key-value의 chunk를 읽는다.
그리고 valid한 value, 즉 overwrite나 삭제가 되지 않은 value가 어떤것들인지 LSM-tree를 보면서 찾는다.
그렇게 valid한 value를 vLog의 head에 append를 하고,
앞에서 읽은 chunk의 공간을 free한다.
그리고 변경된 tail을 update한다.
그러면 이제 invalid한 값들은 사라지고 vLog에 valid한 값들만 있는 상태가 된다.
Challenges
1. Parallel Range Query
- In LevelDB…
- Keys and values are stored together and sorted → A range query can sequentially read key-value pairs
- Parallel random reads with large request size
→ Can fully utilize SSD internal parallelism!
- Prefetch values from the vLog during range queries
LevelDB에서는 key와 value가 함께 저장돼서 정렬이 됐기 때문에 range query시에 sequential하게 key-value 쌍을 읽을 수 있었다.
그런데 WiscKey는 이렇게 sequential read를 못하기 때문에 random read에서 어떻게 효율적으로 읽을지 고민해봐야 한다.
위에서 보여준 Fig.5에서 알 수 있듯이, SSD에서는 64KB 이상의 큰 size로 random read를 하면, throughput이 sequential read와 같은 수준까지 올라오기 때문에,
WiscKey는 이런 SSD의 internal parallelism을 full로 활용하기 위해서 range query시에 vLog에서 value를 prefetch해서 큰 단위의 read를 하도록 만든다.
Evaluation
- Randomly loaded database
- Value size smaller than 4KB:
Small data size → SSD’s limited random read performance → WiscKey’s poor throughput
- Value size bigger than 4KB:
Big data size → LevelDB accesses more SSTable → LevelDB’s poor throughput
- Sequentially loaded load database
- 64B: WiscKey reads both key & value from vLog → WiscKey’s poor throughput
- Over 4KB: WiscKey’s higher throughput
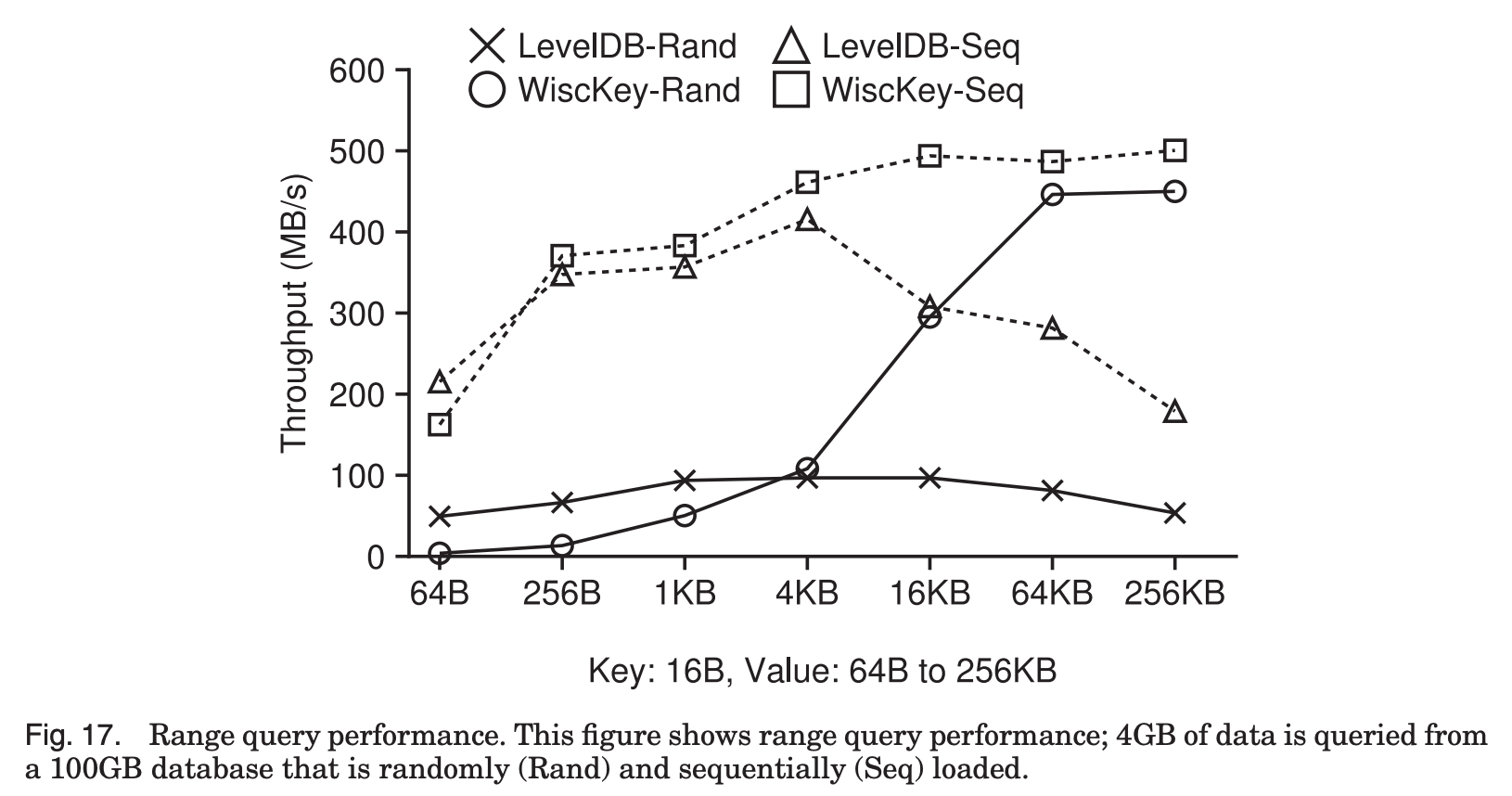
Fig. 17은 range query의 성능을 보여준다.
두개의 실선은 Random하게 load된 database에 대한 성능이고,
나머지 두 점선은 Sequential하게 load된 database에 대한 성능을 나타낸다.
먼저 실선을 보면, Random하게 load된 database의 경우,
LevelDB는 여러 레벨의 파일을 읽어야 되고,
WiscKey의 경우 vLog에 대한 random access를 필요로 한다.
따라서 64B같이 작은 크기의 data의 경우 SSD의 제한된 parallel random read throughput으로 인해 WiscKey의 성능이 LevelDB에 비해 12배 떨어진다.
하지만 4KB 이상 value size의 부분을 보면,
LevelDB는 value의 size가 커짐에 따라 SSTable에 적은 수의 key-value만 저장할 수 있게 되고,
여러개의 SStable을 open해서 각 file의 index block과 Bloom filter를 읽는 overhead가 생긴다.
반면에 WiscKey의 경우 data size가 커짐에 따라 random read throughput이 SSD의 sequential read throughput에 도달한다.
이때 WiscKey는 LevelDB의 최대 8.4배의 device sequential bandwidth를 보여준다.
나머지 두 점선, Sequential load된 database에 대한 성능을 보면,
Sequnetial load된 database는 LevelDB, WiscKey 모두 순차적으로 데이터를 scan할 수 있다.
마찬가지로 value size가 64B 정도로 작은 경우, WiscKey는 vLog에서 key, value를 모두 읽기 때문에 LevelDB에 비해 25% 느리지만,
key-value size가 큰 경우에는 Wisckey가 LevelDB에 비해 2.8배 빠르다.
2. Garbage Collection
- If data relating to a deleted/overwritten key-value pair is found,
- Standard LSM-trees
- Compaction: The data is discarded and space is reclaimed
- WiscKey
- Only invalid keys are reclaimed
- Standard LSM-trees
- Lightweight & Online garbage collector!
- Stores the corresponding key along with the value in vLog
- Tuple <key size, value size, key, value> is stored in the vLog
- Stores the corresponding key along with the value in vLog
- Keeps valid values in a contiguous range of the vLog
- Head
- New values are appended
- Tail
- Garbage collection starts freeing space
- Head
Invalid한 key-value가 생겼을 때,
기존의 LSM-tree의 경우 compaction시에 data가 삭제되고, 공간이 회수되었다.
WiscKey에서는, 앞에서 설명했듯이, invalid한 값들만 회수하는 방식의 garbage collection을 수행한다.
그리고 garbage collection을 효율적으로 수행하기 위해서 vLog에 value와 함께 key도 저장한다.
Head에는 새롭게 값들이 append되고, tail에서는 garbage collector가 회수를 하는데,
이 방식은 head와 tail 사이에 항상 valid한 값들만을 연속적으로 둘 수 있도록 해준다.
Evaluation
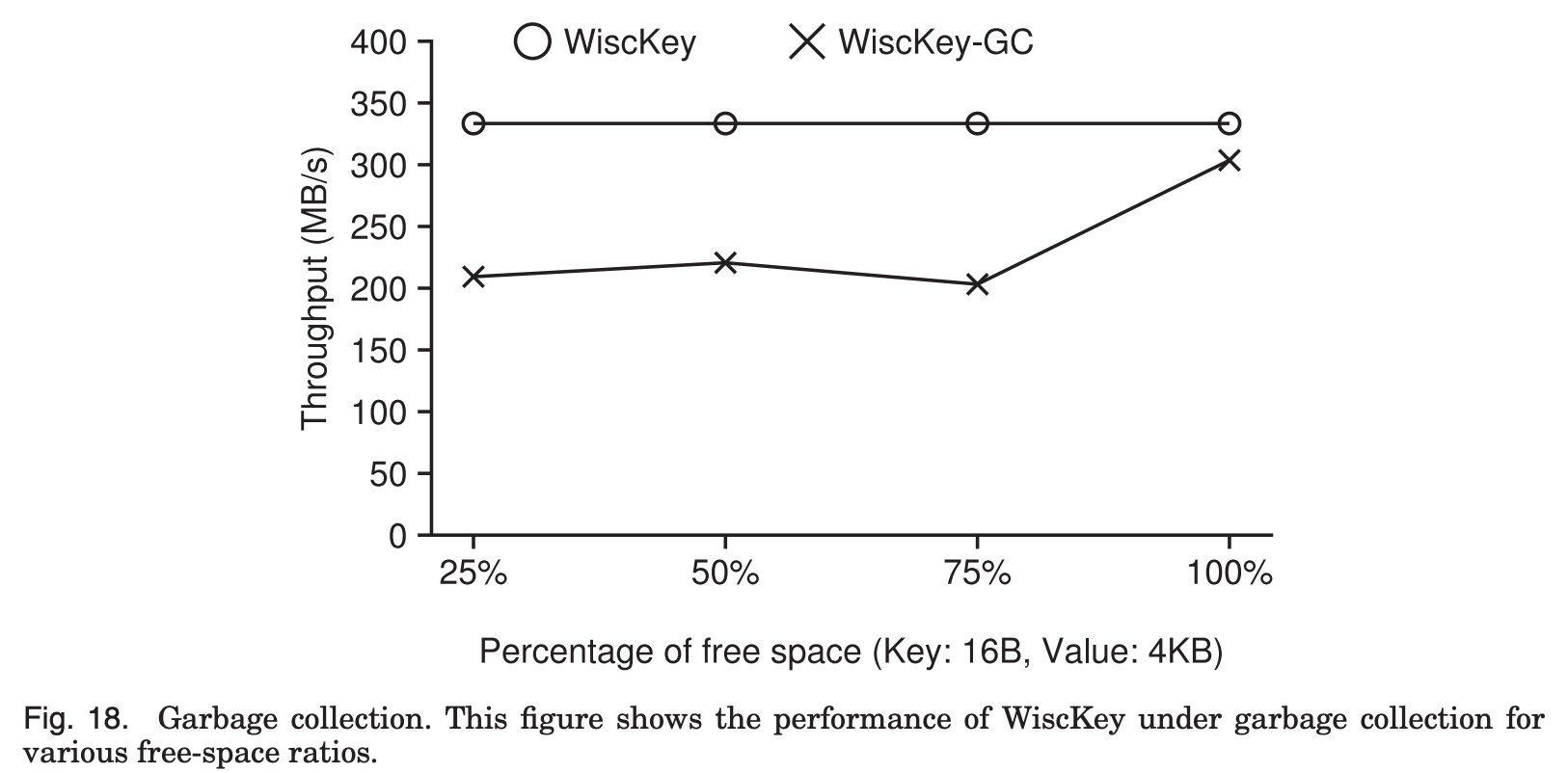
- Percentage of free space found during garbage collection = Percentage of invalid data
Background에서 수행되는 garbage colletion이 성능에 어떤 영향을 미치는지 확인하고 싶은데,
성능은 garbage colletion 도중에 발견되는 free space의 비율에 따라 달라질 수 있다.
왜냐하면 발견된 free space의 비율은 write된 data의 양과 garbage collection thread가 free를 하는 공간의 크기에 영향을 주기 때문이다.
따라서 garbage collection의 영향을 가장 많이 받는 작업인 random load를 foreground workload로 수행해서 다양한 free space 비율에 대한 성능평가를 진행했다.
위의 그래프를 보면, garbage collector가 발견하는 free space의 비율이 100%,
즉 모든 data가 invalid할 때 throughput이 10%만 낮아지는 것을 볼 수 있다.
Garbage collection이 tail에서 read만 하고, head에 append 또는 write를 하는 data는 없기 때문이다.
다른 비율의 경우 head에 데이터를 write를 하기 때문에 throughput이 약 35% 정도 감소한다.
그렇지만, LevelDB와 비교하면 최소 70배 이상 빠르다.
왜냐하면 뒤에서 더 설명하겠지만, 아래 Fig. 11에서 알 수 있듯이 LevelDB의 random write throughput이 훨씬 낮기 때문에 그렇다.
3. Crash Consistency
- In WiscKey, Values are appended sequentially to the end of the vLog file
→ If a value X in the vLog is lost in a crash, all values inserted after X are lost too
-
User queries a key-value pair
-
If WiscKey cannot find the key in the LSM tree (key lost during a system crash),
- WiscKey behaves exactly like traditional LSM-trees
: even if the value had been written in the vLog before the crash, it will be garbage collected later.
- WiscKey behaves exactly like traditional LSM-trees
-
If the key could be found in the LSM tree,
- WiscKey verifies whether the value address retrieved from the LSM-tree falls within the current valid range of the vLog
- WiscKey verifies whether the value found corresponds to the queried key
- If the verifications fail, WiscKey assumes that the value was lost during a system crash
- Deletes the key from the LSM-tree
- Informs the user that the key was not found.
-
사용자가 1에서 50까지의 sequence에 51에서 100까지의 sequence를 append했는데 crash가 유발된 경우,
일부가 prefix들이 유실되어 recovery 수행시 file에 51에서 70까지만 append가 될 것이다.
Append하는 byte들의 Non-prefix byte들이나 random byte들이 file에 추가될수가 없기 때문이다.
WiscKey에서는 value들이 vLog file의 head에 연속적으로 append된다.
그래서 만약 crash 발생으로 어떤 값 X를 잃어버리게 되면, X 이후에 삽입된 값들까지 모두 잃어버리게 되는 것이다.
그래서 사용자가 key-value 쌍을 요청했을 때,
만약 key를 LSM-tree에서 찾지 못했을 경우, 즉 crash로 key가 유실됐을 경우,
WiscKey는 기존 LSM-tree와 같이 동작하는데, crash가 발생하기 전에 vLog에 값이 이미 write가 됐어도, 이를 garbage collection때 회수한다.
그리고 key를 LSM-tree에서 찾은 경우,
먼저 value address가 vLog의 valid range 안에 있는지 확인한다.
그리고 그 value가 이 key와 대응되는지를 확인한다.
만약에 이 검증들이 실패하면 wisckey는 crash로 값이 유실됐다고 판단하고 LSM-Tree에서 key를 삭제한다.
그리고 사용자에게 key를 찾지 못했다고 알린다.
Evaluation
- Worst Case
- LevelDB recovery time: 0.7s < WiscKey recovery time: 2.6s
이 방식의 성능 평가를 위해,
Worst case에서 crash를 발생시켜 이 때의 recovery time을 측정했다.
LevelDB의 경우 crash후 데이터베이스를 복구하는 데 0.7초가 걸리는 반면 Wisckey는 2.6초가 걸렸다.
WiscKey의 recovery time이 더 오래 걸렸지만, LSM-tree에 vLog의 head pointer를 더 자주 update 하면 해결되는 문제이다.
Optimizations
1. Value-Log Write Buffer
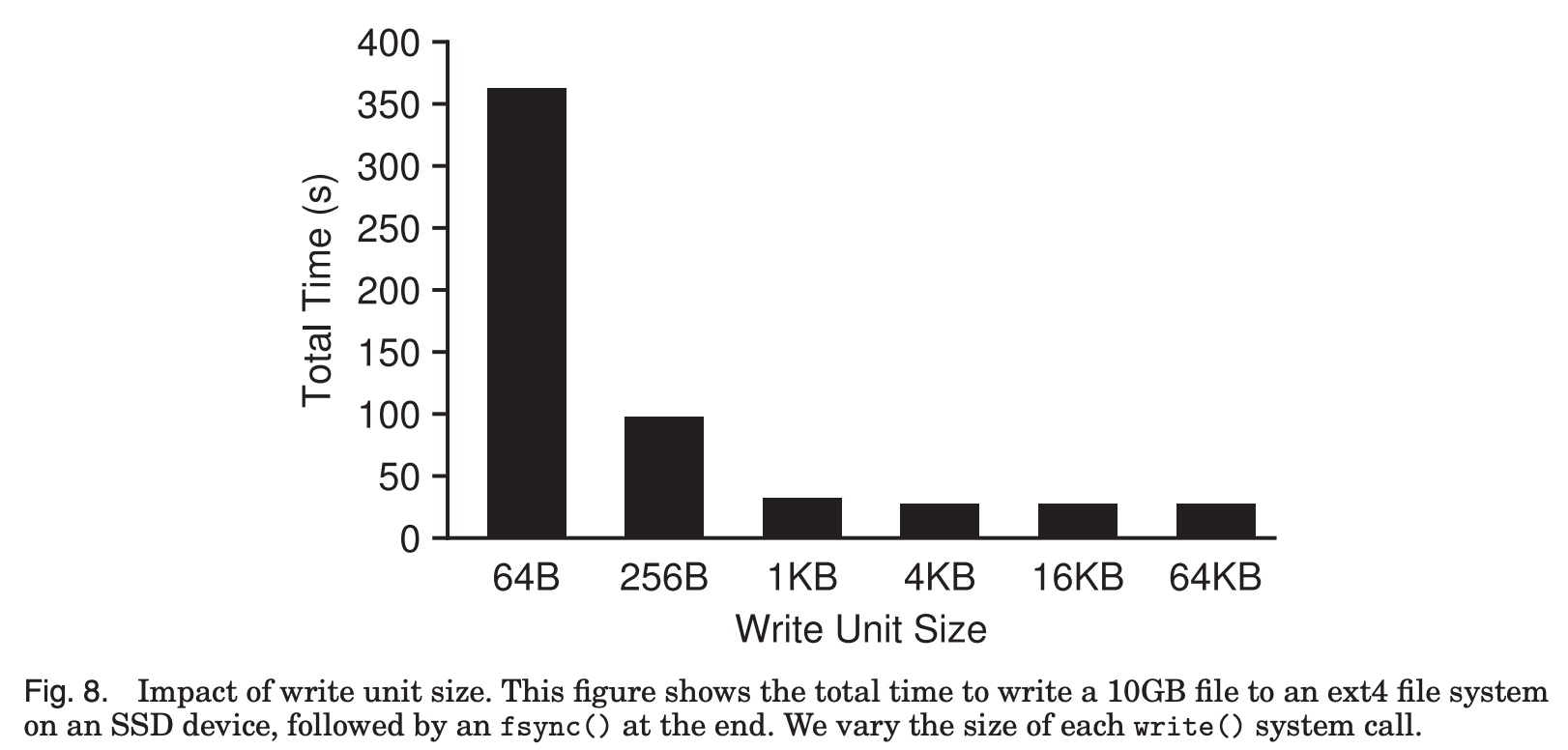
- For small writes…
- Overhead of each system call aggregates significantly
- With writes larger than 4KB, device throughput is fully utilized
- WiscKey buffers values in a user-space buffer and flushes the buffer only when the buffer size exceeds a threshold
(or when user requests a synchronous insertion)
→ WiscKey only issues large writes!
- For lookup…
- WiscKey first searches the vLog buffer
- If not found, reads from the actual vLog
WiscKey에서는 두가지 최적화를 적용했는데,
첫번째는 Value-log write buffer이다.
작은 크기로 write를 수행할 경우 각각의 system call들이 모여 overhead가 크게 증가하게 된다.
그런데 아래 Fig. 8을 보면, 4KB 보다 큰 write를 하면 걸리는 시간을 크게 줄일 수 있고, device의 성능을 최대치까지 활용할 수 있다.
그래서 WiscKey는 user-space buffer에 값들을 저장했다가, buffer의 크기가 threshold를 넘어간 경우에만 disk로 flush를 하는 방식을 사용한다.
이런 방법으로 큰 write만 발생시켜서 효율을 높인다.
Lookup에 대해서는,
vLog buffer에서 먼저 찾고, 찾지 못했을 경우에 실제 vLog에서 read를 수행하는 방식으로 이루어진다.
Evaluation
- Sequential Load

먼저 Sequential load 성능을 살펴보자면,
Fig. 9에서 볼 수 있듯이 LevelDB의 경우 value size가 256KB까지 커져도 throughput이 device bandwidth인 500MB/s에 한참 못미친다.
반면에 WiscKey는 value size가 4KB 이상일 때 device bandwidth를 최대로 활용하는 것을 볼 수 있다.
작은 value size에서도, 3배 빠른 성능을 보이는데, 이는 LSM-tree에 log write를 안하고 vLog에 append하기 때문이다.
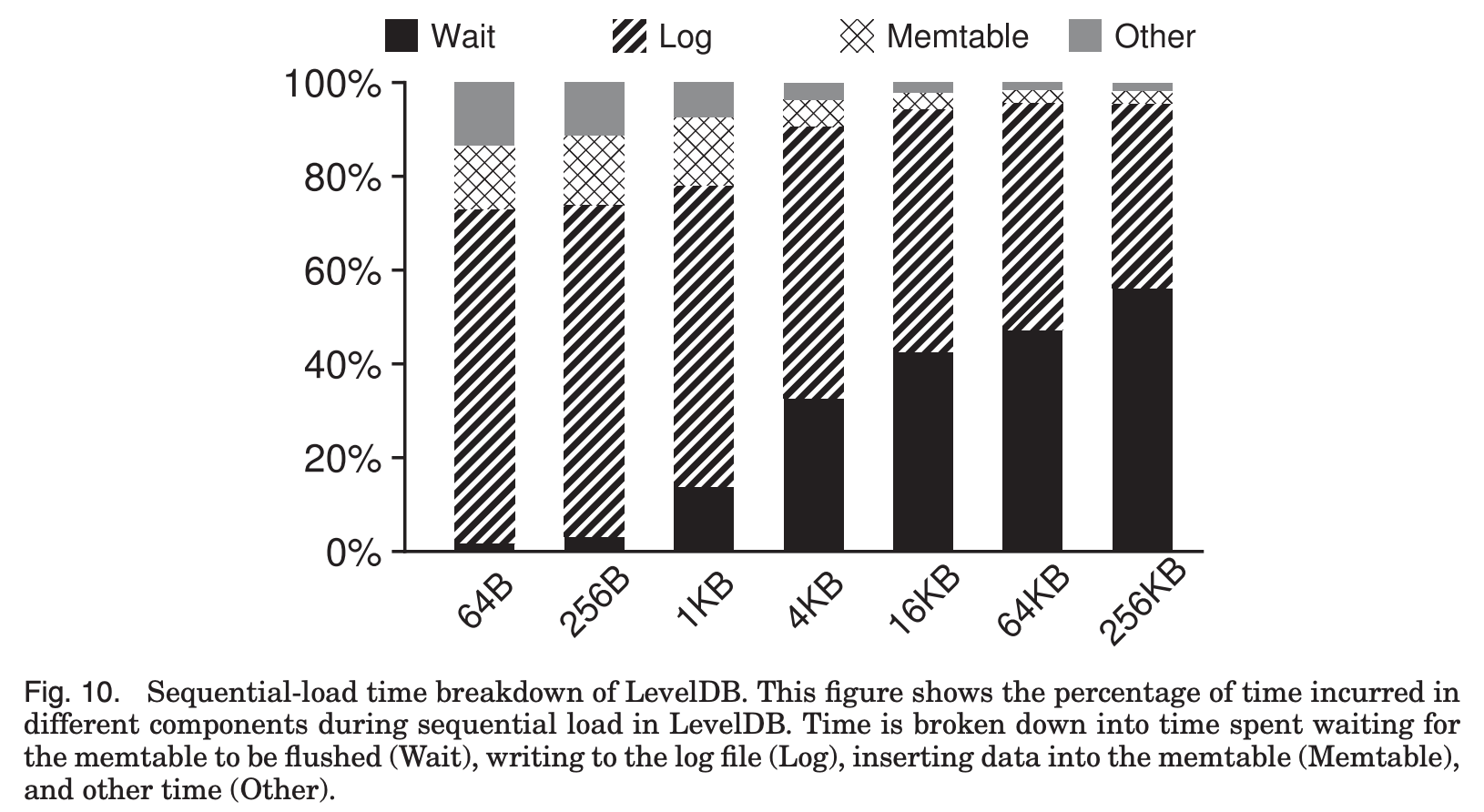
이를 더 구체적으로 분석하기 위한 Fig. 10을 보면,
LevelDB가 실행될 때 서로 다른 구성요소들에서 시간이 어떻게 사용되는지 알 수 있는데,
value size가 작은 경우 write의 비효율성으로 인해 LSM-tree log에 기록하는 시간이 오래 걸리고(Fig. 8),
value size가 커지면 Log 기록과 Memtable 정렬은 효율적인 반면 Memtable flush를 기다리는 시간이 오래 걸린다.
WiscKey는 LSM-tree log가 존재하지 않고 buffer에서 바로 vLog로 추가되므로 LevelDB에 비해 더 좋은 성능을 보인다.
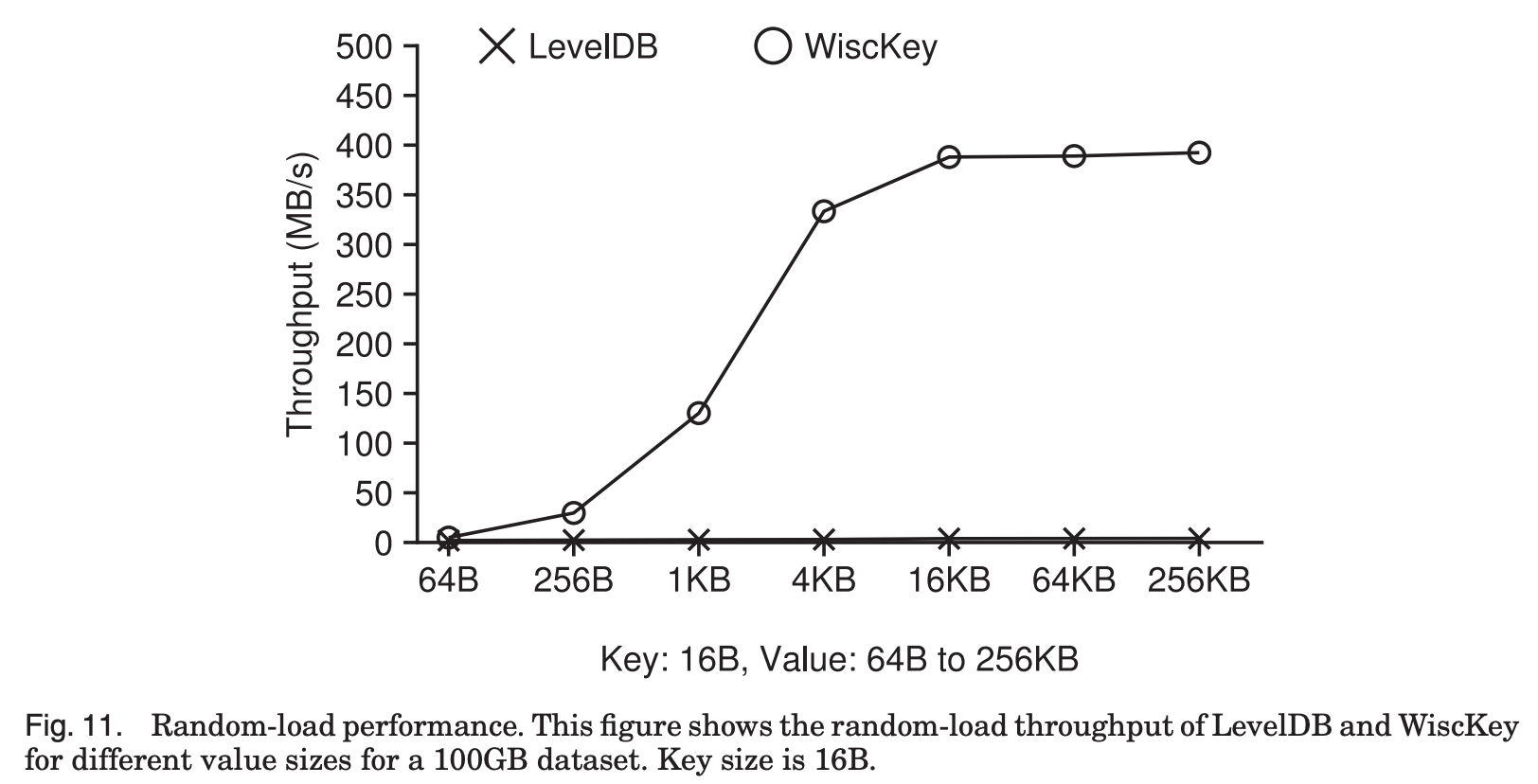
- Random Load
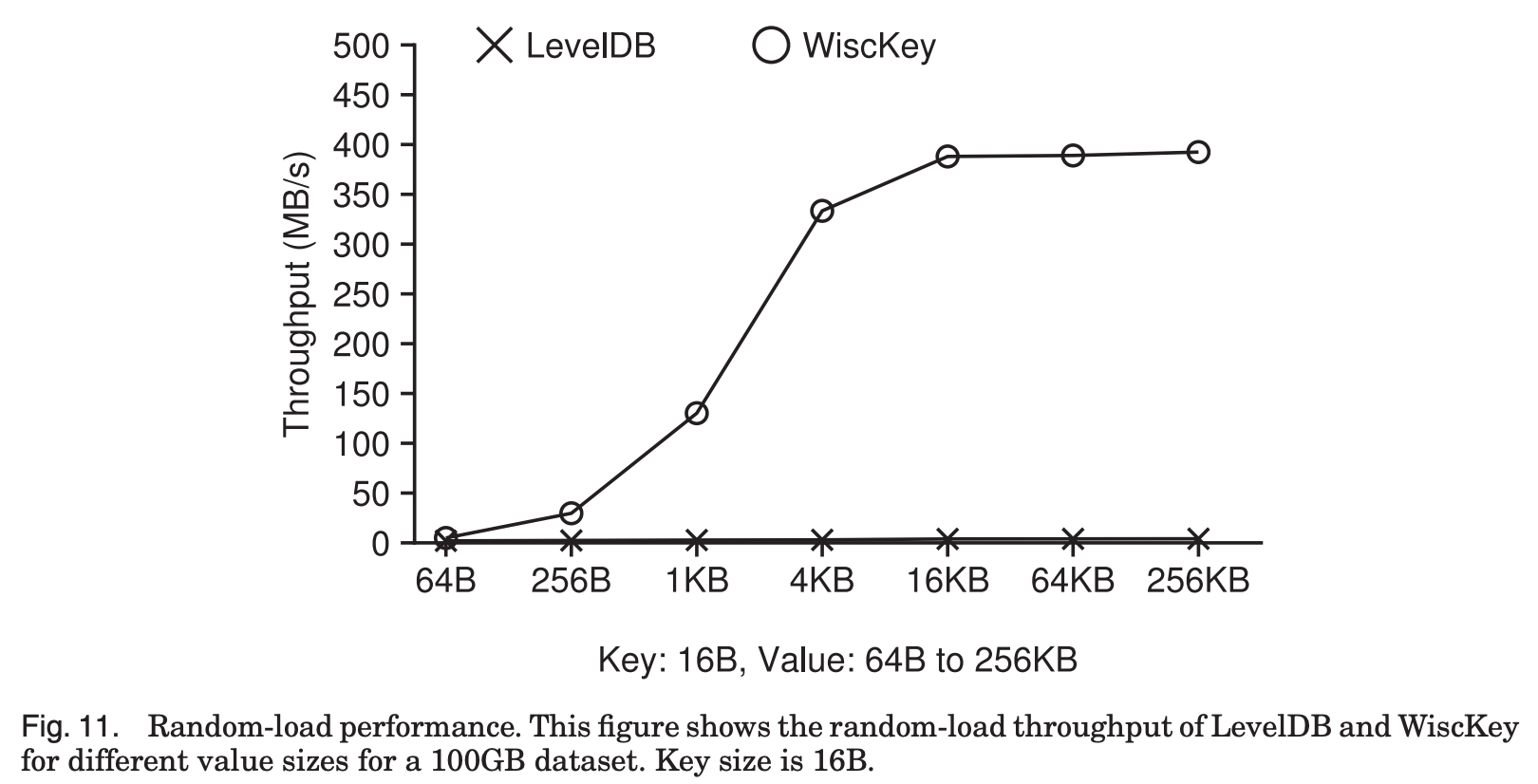

추가로 Random load의 성능 평가 결과를 살펴보면,
Fig. 11에서, Random load의 경우 Sequential load와 다르게 compaction이 발생한다.
Compaction 과정에서 장치의 bandwidth를 사용하게 되면 foreground write에도 영향을 미쳐서 throughput이 줄어들게 된다.
따라서 compaction 과정이 throughput에 얼마나 영향을 미치는지가 중요하다.
Fig. 12는 Write Amplification을 측정한 것이고, 우리가 기대했던대로 WiscKey는 write amplification이 크게 감소함을 알 수 있다. LevelDB의 경우 12를 넘는 반면, WiscKey는 거의 1에 수렴하고 있다.
이는 우리가 기대했던대로 Key-value의 분리로 LSM-tree의 크기가 작아지고, write amplification을 줄이는데 성공했다는 사실을 확인시켜주는 결과이다.
Fig. 11에 나와있듯이 LevelDB의 경우 throughput이 2MB/s 에서 4.1MB/s로 아주 저조한 반면,
WiscKey의 경우 value size가 4KB를 넘어가면서 장치의 최대 성능을 보임을 알 수 있다.
구체적으로, value Size가 1KB일 때 WiscKey는 LevelDB의 46배, 4KB일때는 111배의 throughput을 보여준다.
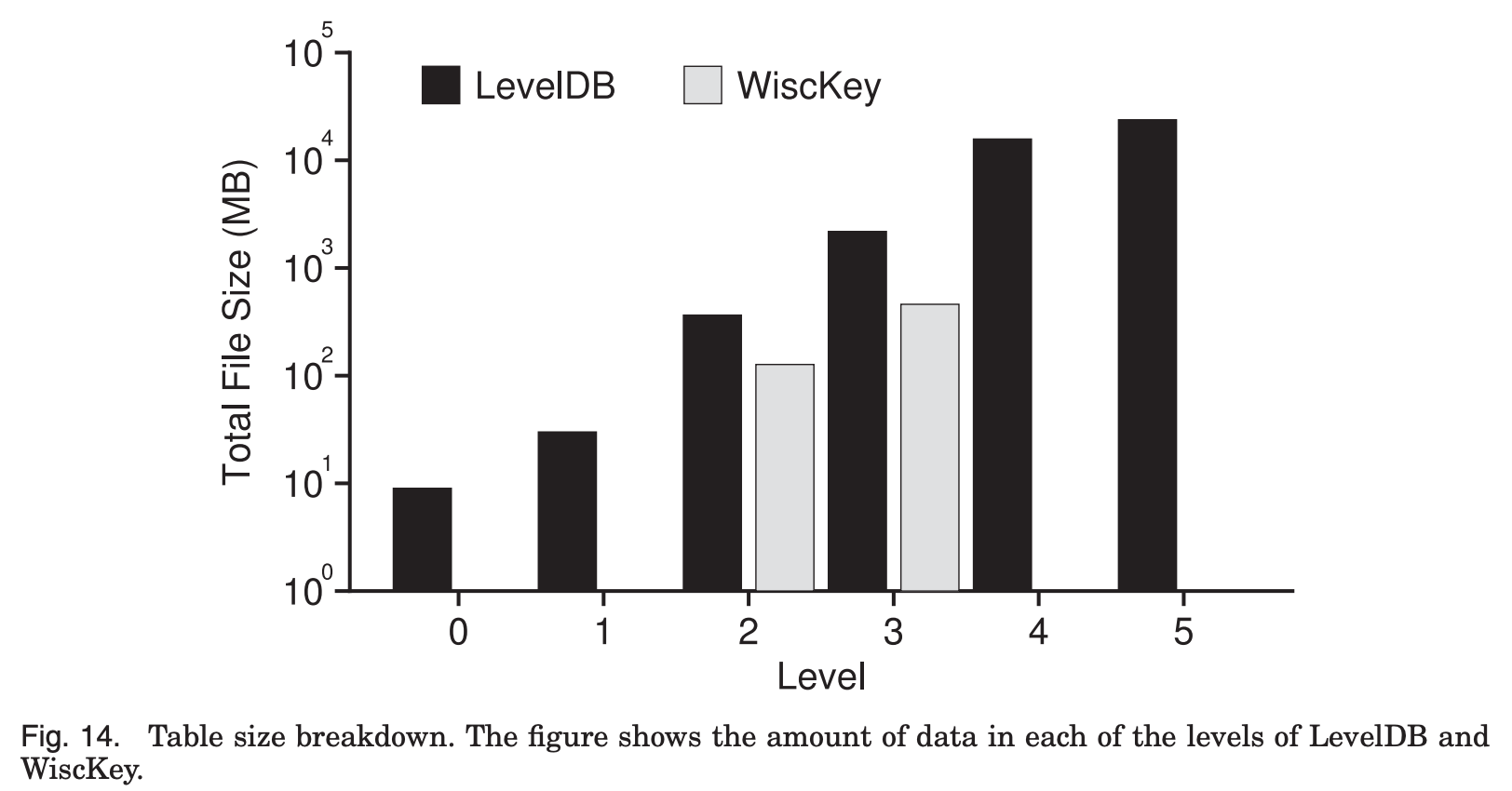
이 그래프는 random load 수행 후의 LSM-tree size를 보여준다.
LevelDB의 LSM tree가 6개 level에 걸쳐서 총 100GB의 크기를 보이는 반면,
WiscKey의 경우 두개의 level로 압축되고 358MB의 크기를 보여준다.
결론적으로 둘의 차이는 대략 280배 정도로,
우리가 기대한대로 Key-Value분리를 통해 LSM-tree의 size가 기하급수적으로 감소하였고,
따라서 Compaction 과정이 더 적게 일어나게 된다.
즉 이는 더 높은 성능으로 이어지게 된다.
2. Optimizing the LSM-tree Log
- In WiscKey, the LSM-tree is only used for keys & value addresses
-
If a crash happens before the keys are persistent in the LSM-tree…
-
Naïve algorithm: Scanning the entire vLog for recovery
-
WiscKey periodically records the head of the vLog in the LSM-tree
- Key-value pair <head-marker, head-vLog offset>
- Starts the vLog scan from the most recent head position stored in the LSM-tree
- LSM-tree inherently guarantees that keys inserted into it will be recovered in the inserted order
-
두번째 최적화는 LSM-tree log를 대체하는 것인데,
WiscKey에서 LSMtree는 key와 value 주소를 저장하는 데에만 쓰인다.
그리고 앞에서 설명했던 것처럼 garbage collection을 위해 vLog에 key도 같이 저장한다.
Crash가 발생했을때 단순한 알고리즘은 vLog 전체를 scan하면서 recovery를 수행하는 것이다.
여기서 scan을 줄이기 위해서 WiscKey는 vLog의 head를 LSM-tree에 주기적으로 기록한다.
그래서 가장 최근에 저장된 head 위치에서부터 vLog를 scan을 할 수 있게 된다.
Head의 위치는 LSM-tree에 저장되어있으면서,
LSM-tree 내부적으로 key들이 삽입된 순서대로 recover가 되도록 보장해주기 때문에 crash consistent하다고 할 수 있다.
