
SK AI Dream Camp & 심층학습 수강기
데이터 분석과 머신러닝의 기초를 다졌던 SK AI Dream Camp,
그리고 이를 바탕으로 인공지능의 깊이를 더한 상명대학교 전공심화 심층학습.
두 과정을 통해
“데이터가 어떻게 가치 있는 정보가 되고,
실제 서비스에 적용되는지”
를 단계적으로 이해할 수 있었다. 이 글은 그 여정을 정리한 기록이다.
SK AI Dream Camp
지원동기
구분 : 📋수료
항목 : SK AI Dream Camp (초급)
주관기관 : SK mySUNI
기간 : 25.07.01~08.14
이번 여름, SK AI Dream Camp에 대한 공지가 올라왔다.

파이썬은 교내 프로젝트와 알고리즘 코딩 테스트 등으로 많이 다뤄봤지만, 데이터 분석과 머신러닝은 아직 다룬 경험이 없어서 이 교육이 AI에 입문하는데 큰 도움이 될 것 같았다. 중,고급반은 실제 데이터를 다룰 수 있는 숙련도가 필요해서 아쉽지만 초급으로 시작하게 되었다.
학습과정
지원 후 과목을 살펴보니
데이터 분석 -> 머신러닝 -> AI경연(SK텔레콤 LTE 기지국 장비의 성능 상태 예측)
으로 앞선 과목을 수강해야 다음 과목이 수강 가능한 방식이었다.
수강시작까지 기간이 조금 남아서 pandas, numpy, series, dataframe등에 관해 미리 학습했다.

데이터 분석
pandas numpy 기반으로 series, dataframe을 기본적인 파이썬으로 배우고 실습하는 과정이었다. 사전에 미리 학습했기에 크게 어려운 부분은 없었다.
이런식으로 문제가 주어지고 빈칸에 코드를 작성하고 실행해서 원하는 결과가 나오면 넘어가는 식이었다.
시각화에 대해서도 배웠다. 통계나 그래프를 위해 seaborn을 사용했다. matplotlib으로도 가능하지만
- 쉬운 사용성 (1줄 완성 그래프)
- seaborn 에서만 제공되는 통계 기반 plot
- 아름다운 스타일링
- Pandas의 데이터프레임과 높은 호환성
이런 특징이 있어 seaborn을 사용한다고 했다.
다양한 map이나 plot들에 대해서도 다뤄보았다.
머신러닝
지도/비지도 학습과 같은 학습 방법, 회귀/분류나 군집/차원 축소 같은 문제 유형과
머신러닝 모델들에 관해 배웠다.
특히 인상 깊었던 것은 단순히 모델을 돌리는 것이 아니라,
데이터 준비 → 학습 → 평가 → 제출
까지 이어지는 End-to-End 프로세스를 정립했던 것이었다.
머신러닝 프로세스
1) 결측치 처리
2) 데이터 전처리(모두 숫자형으로)
3) Feature Engineering
4) 주요 특성 선택 및 제거
5) 학습을 위해 데이터 분리(X,Y 분리)
6) 레이블에 따른 모델 선정
7) 모델 학습
8) 모델 평가
9) 예측 데이터 추론
10) 결과 제출
보이는 문제에만 집중하는 그리디한 개발자와 전체 프로세스를 알고 설계하는 개발자는 다를 수 밖에 없겠다는 생각이 들었다.
분류/회귀/군집 개념에 대해서도 명확하게 이해할 수 있었다.
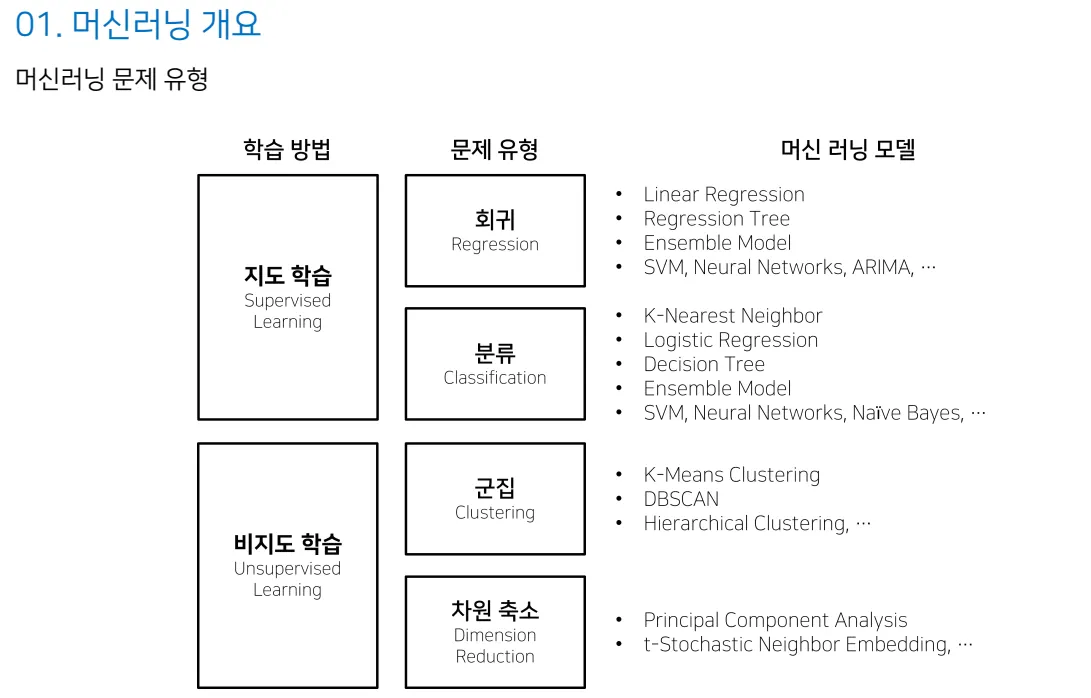
분류 : 정답이 범주일 때
회귀 : 값이 연속일 때
군집 : 정답 없이 비슷한 것끼리 묶기
학습 방법과 문제 유형, 그리고 머신 러닝 모델에 따라 머신러닝 문제 유형이 나뉜다는 것을 알 수 있었다.
또한 비지도 학습의 대표적인 알고리즘인 K-Means를 통해 정답(Label)이 없는 데이터들을 거리 기반으로 군집화(Clustering)하여 숨겨진 패턴을 찾는 방법도 실습해 볼 수 있었다.
학습 후
모든 과정이 마무리되고, 수료증을 발급 받았다.

수료증은 발급받았지만, 가볍게 기본 개념을 배운 느낌이라 그 다음이 없어서 아쉬웠다.
그러나 학교 전공과목에서 그 아쉬움을 달랠 수 있는 과목을 발견했다.
바로 전공 심화 과목인 '심층학습'이다.
심층학습
SK AI Dream Camp가 머신러닝의 '전체 숲'을 보는 과정이었다면,
심층학습은 그 숲속에 있는 '거대한 나무'들의 내부 구조를 파헤치는 시간이었다.
기존 머신러닝(ML)으로는 해결하기 어려웠던 비정형 데이터(이미지, 텍스트, 시계열) 처리를 위해, 심층 신경망(DNN)이 어떻게 발전해 왔는지 단계별로 학습했다.
CNN (합성곱 신경망)
기존 ML에서는 사람이 직접 특징을 설계해야 했다.
CNN은:
Convolution + Pooling
을 통해 스스로 중요한 특징을 학습한다.
Stride / Padding 등을 수식으로 계산하며,
LeNet-5, ResNet (Skip Connection으로 기울기 소실 해결)
같은 구조를 이해할 수 있었다.
이를 통해 Feature Engineering이 모델 내부로 들어왔다는 것을 알 수 있었다.

별개로, AlexNet의 핵심 3요소인 GPU, ReLu, Dropout에서
Dropout의 역할이 과적합 방지인 이유가 기억에 남는다.
-서브 네트워크를 만들어서 앙상블 효과를 만들기 때문.
-뉴런을 확률적으로 끄기 때문에 뉴런 자체의 역할을 강건하게 함.
서브 네트워크 개념을 떠올리지는 못했었는데 교수님의 설명을 듣고 놀랐던 기억이 난다.
시계열 & NLP
SK 캠프 경연 주제였던 '시계열 예측'을 심층학습에서는 훨씬 정교한 모델로 다루었다.
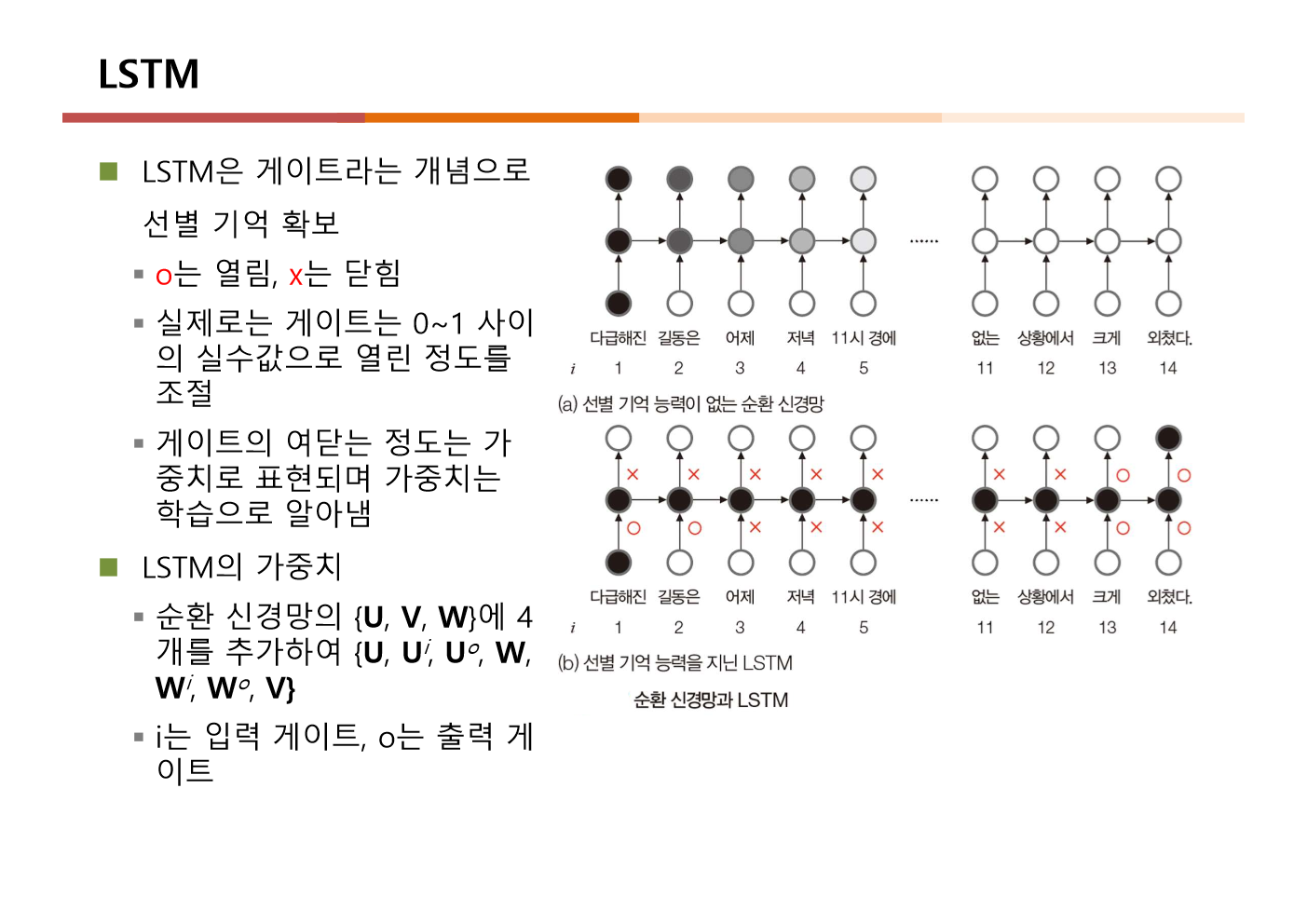
시계열 데이터를 처리하는 RNN은 데이터 길이가 길어지면 앞의 내용을 까먹는(장기 의존성 문제) 치명적인 단점이 있다.
이를 해결하기 위해 망각(Forget), 입력(Input), 출력(Output) 게이트를 도입한 LSTM 구조를 상세히 뜯어보았다.
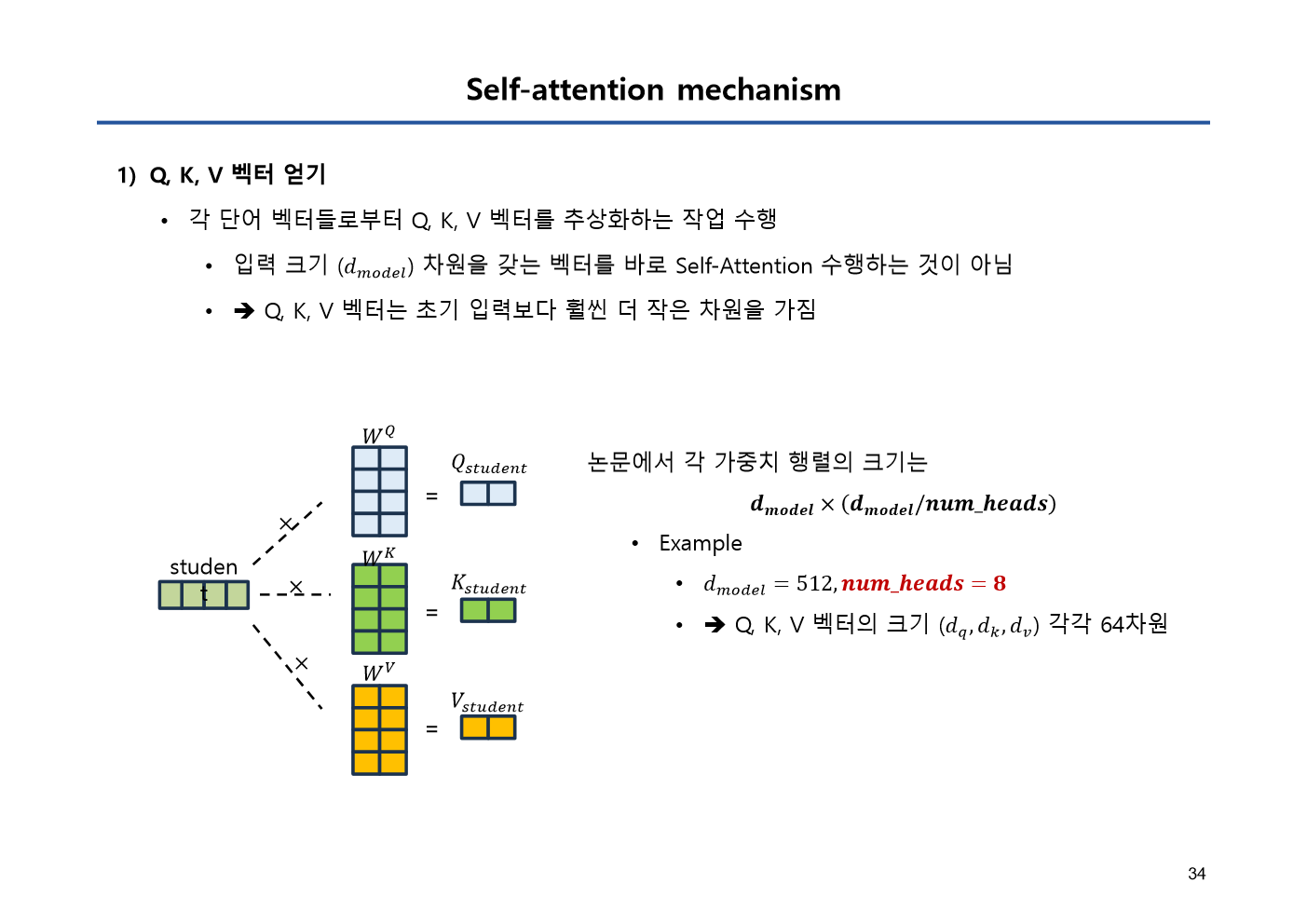
Transformer는 현재 자연어 처리(NLP)의 표준이 된 모델이다.
순차적으로 처리하는 RNN의 한계를 넘어,
Self-Attention() 메커니즘을 통해 문장 전체의 문맥을 한 번에 병렬로 파악하는 원리를 학습했다.
생성 모델
VAE: 확률 분포 기반 생성
GAN: 생성자와 판별자의 경쟁
단순 분류를 넘어서,
모델이 새로운 데이터를 창조할 수 있다는 점이 인상적이었다.
SK AI Dream Camp와 심층학습 수강 후
Dream Camp를 먼저 듣고 심층학습을 배우니,
왜 이 기술이 필요한가?
가 분명해졌다.
🔗 연결 1 — Feature Engineering → 자동화
Dream Camp: 내가 직접 변수 고민
Deep Learning: 필터가 자동으로 특징 학습
🔗 연결 2 — 시계열 이해
Dream Camp: 회귀/통계 위주 접근
Deep Learning: RNN/LSTM/Attention으로 순서와 상태를 보존
🔗 연결 3 — Transfer Learning
Pre-trained 모델을 가져와 미세조정
현실적인 데이터 부족 문제 해결
마치며
Dream Camp는 Workflow를,
심층학습은 엔진 내부 구조를 이해하게 해 주었다.
데이터 파이프라인 이해
모델 구조와 연산 비용 감각
클라우드 환경에서 AI를 다루는 시야
ML 프로세스를 직접 구현해 봄으로써, 데이터 수집부터 전처리, 학습, 추론으로 이어지는 MLOps 파이프라인의 구조를 이해하게 되었다.
또한 CNN, Transformer 등 거대 모델의 연산 비용과 구조를 이해함으로써, 향후 클라우드 환경에서 GPU 리소스 할당이나 모델 서빙(Serving) 아키텍처를 설계할 때 더 효율적인 의사결정을 할 수 있을 것이다.
앞으로는
실제 서비스에 AI를 연동하고,
클라우드 환경에서 안정적으로 운영하는 경험을 쌓으며
AI를 이해하는 백엔드 엔지니어로 성장하고자 한다.

심층학습 개어렵던데