
Example 1-1. 네이버 금융
목표
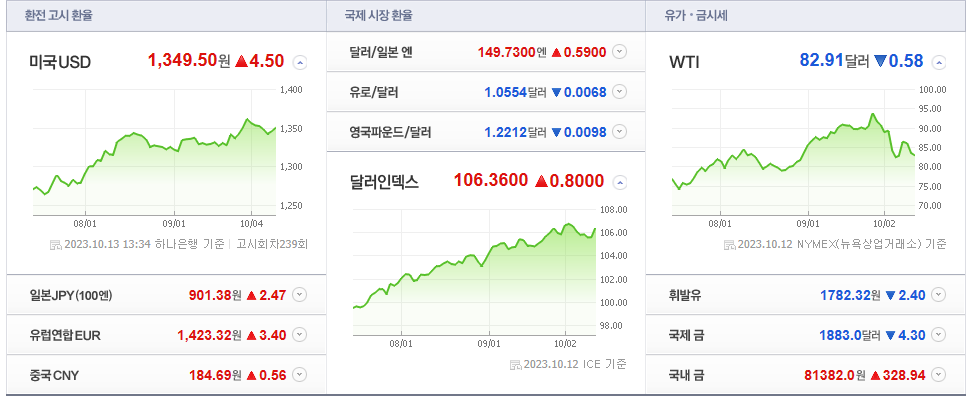
- 금액에 해당하는 금융 데이터 12개를 가져오는 것
- 링크 : https://finance.naver.com/marketindex/
- 크롬( Chrome) 개발자 도구 활용
- 크롬 설정 - 도구 더보기 - 개발자 도구
- 아이콘 선택
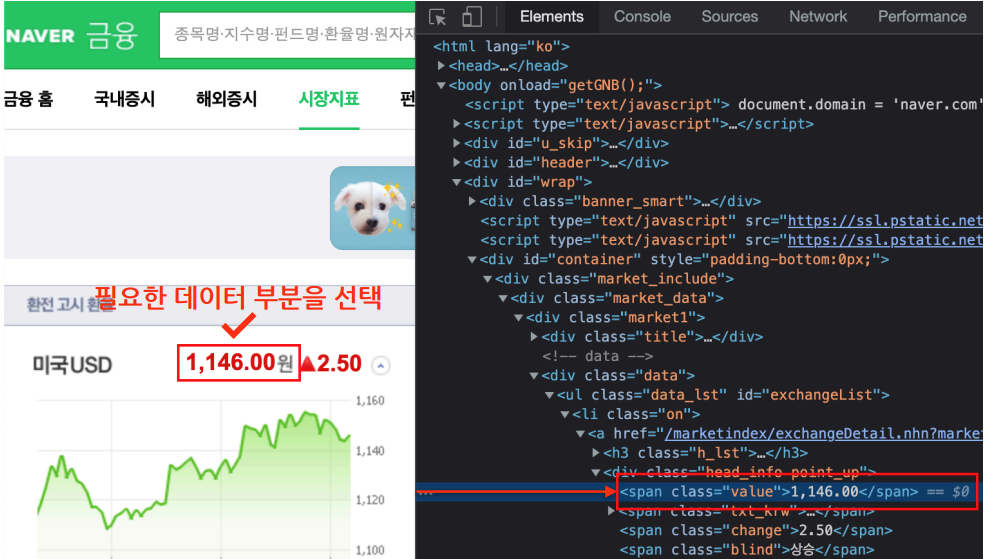
- 필요한 데이터 부분 선택
- 선택하면 선택한 태그에 해당하는 코드로 이동
- 기억할 것 :
**<span class = ‘value’>**
- Module Load
# import
from urllib.request import urlopen
from bs4 import BeautifulSoup- 보고자 하는 페이지 호출
url = "https://finance.naver.com/marketindex/"
# page = urlopen(url)
response = urlopen(url)
response
soup = BeautiefulSoup(page, "html.parser")
print(soup.prettify())
환율 가격(<span class = "value">) 불러오기
# 1
soup.find_all("span", "value"), len(soup.find_all("span", "value"))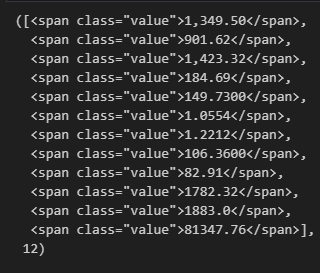
- 보고자 하는 지역에 해당하는 값(Value ) 호출
soup.find_all("span", {"class":"value"})[0].text, soup.find_all("span", {"class":"value"})[0].string, soup.find_all("span", {"class":"value"})[0].get_text()Output : ('1,171.10', '1,171.10', '1,171.10')
Example 1-2. 네이버 금융
Summary
- !pip install requests
- find, find_all
- select, select_one
- find, select_one : 단일 선택
- select, find_all : 다중 선택
import requests # 요청하고, 응답
# from urllib.request.Request
from bs4 import BeautifulSoupurl = "https://finance.naver.com/marketindex/"
response = requests.get(url)
# requests.get(), requests.post()
# response.text
soup = BeautifulSoup(response.text, "html.parser")
print(soup.prettify())
변수명.status: 크롤링을 진행했을 때, 정상적으로 요청하고 응답받았는지를 확인시켜주는 숫자
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
response.status# soup.find_all("li", "on")
# id => #
# class => .
exchangeList = soup.select("#exchangeList > li")
len(exchangeList), exchangeList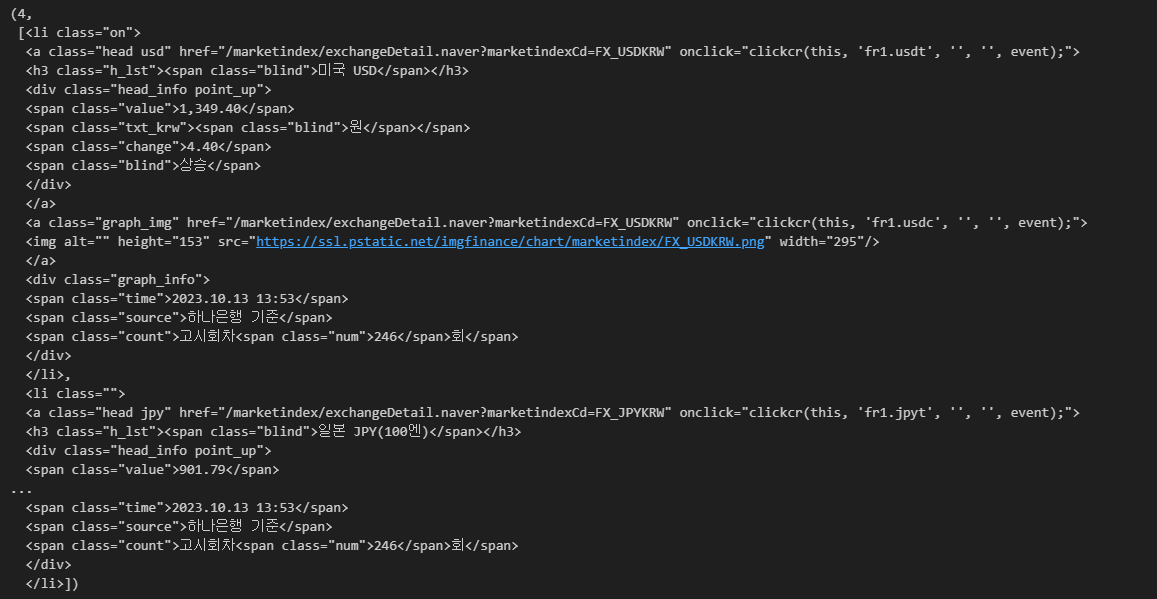
title = exchangeList[0].select_one(".h_lst").text
exchange = exchangeList[0].select_one(".value").text
change = exchangeList[0].select_one(".change").text
updown = exchangeList[0].select_one(".head_info.point_up > .blind").text
# link
title, exchange, change, updownOutput : ('미국 USD', '1,349.40', '4.40', '상승')
- 4개의 값(Value)에 해당하는 정보를 가져옴
- find_all
select를 사용할 경우 상/하위 이동이 좀 더 자유로움
findmethod = soup.find_all("ul", id="exchangeList")
findmethod[0].find_all("span", "value")- 주소값 호출
exchangeList[0].select_one("a").get("href")의 output /marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW 네이버 금융에서 보기 때문에 주소 추가 필요
baseUrl = "https://finance.naver.com"
baseUrl + exchangeList[0].select_one("a").get("href")Output : 'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW'
- 데이터 수집
exchange_datas저장 형태 : dictionary
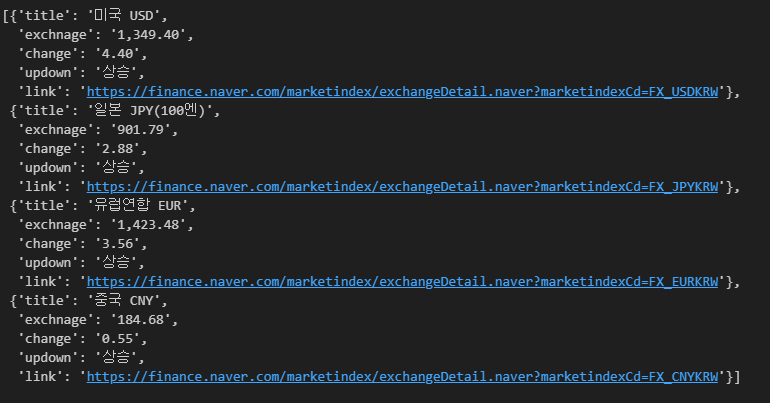
import pandas as pd
# 4개 데이터 수집
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title": item.select_one(".h_lst").text,
"exchnage": item.select_one(".value").text,
"change": item.select_one(".change").text,
"updown": item.select_one(".head_info.point_up > .blind").text,
"link": baseUrl + item.select_one("a").get("href")
}
print(data)
exchange_datas.append(data)
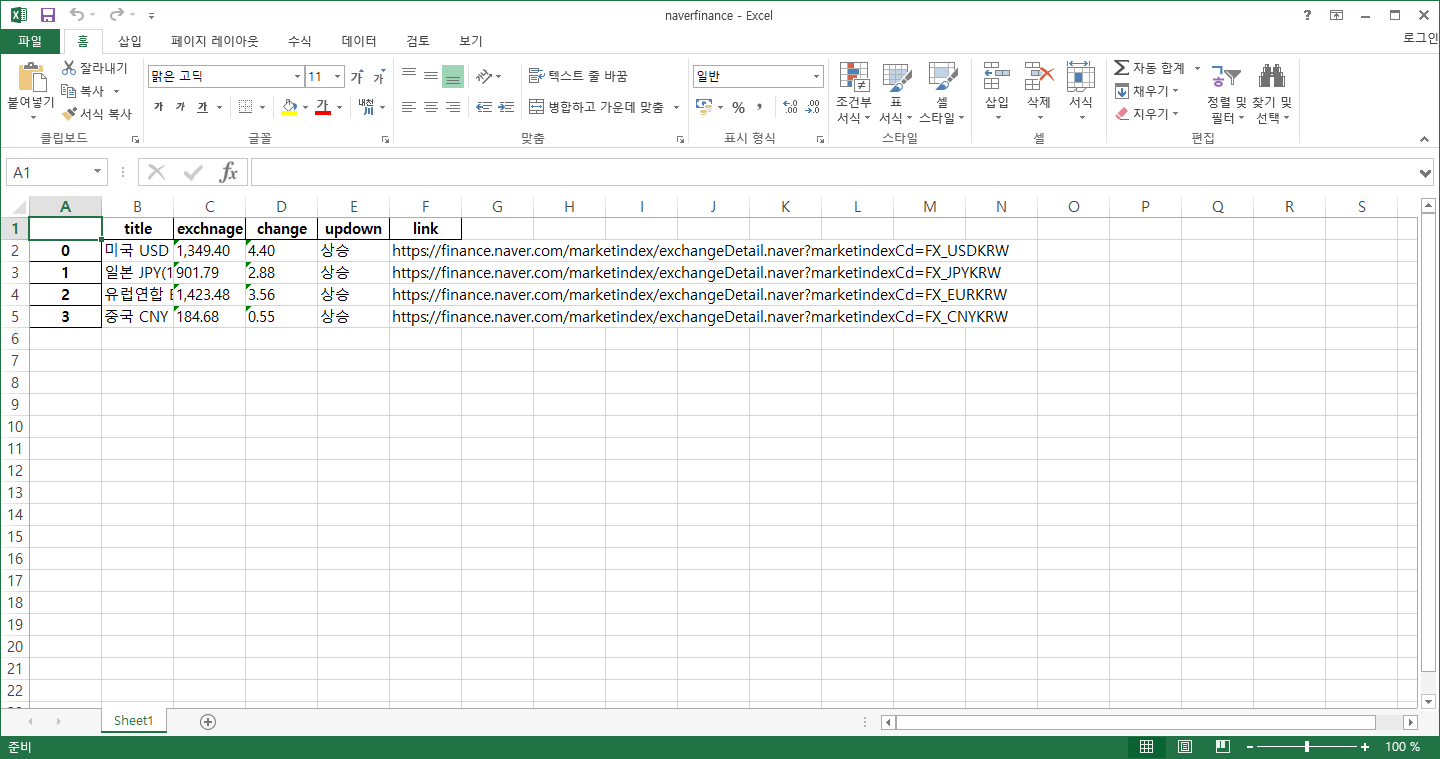
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx")
- 저장 엑셀 파일
Example 2-1. 위키백과 문서 정보 가져오기
목표
-
ModuleLoad
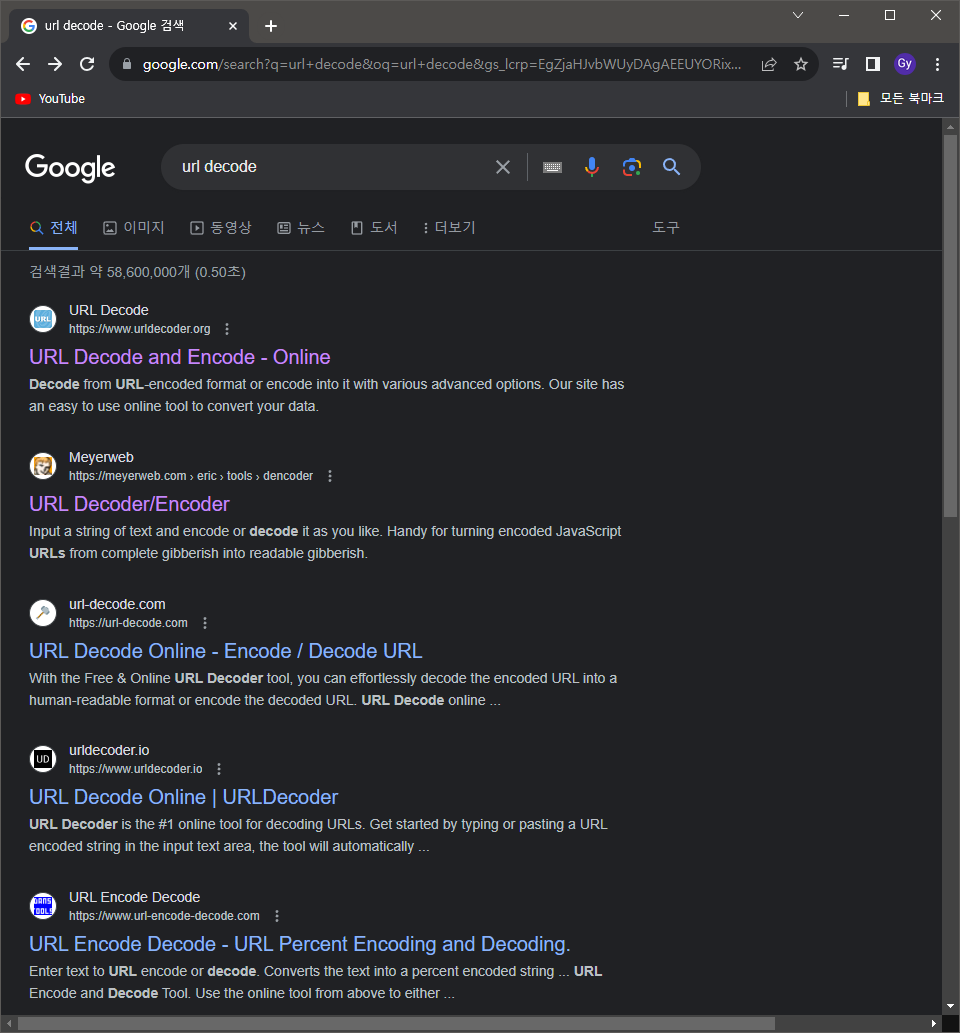
- 웹 주소를
utf-8로 인코딩 해야 함 - Google 검색 : url decode
- 글자를 URL로 인코딩
- 웹 주소를
import urllib
from urllib.request import urlopen, Request
html = "https://ko.wikipedia.org/wiki/{search_words}"
# https://ko.wikipedia.org/wiki/여명의_눈동자
req = Request(html.format(search_words=urllib.parse.quote("여명의_눈동자"))) # 글자를 URL로 인코딩
response = urlopen(req)
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify())
n = 0
for each in soup.find_all("ul"):
print("=>" + str(n) + "========================")
print(each.get_text())
n += 1
soup.find_all("ul")[15].text.strip().replace("\xa0", "").replace("\n", "")Output : '채시라: 윤여옥 역 (아역: 김민정)박상원: 장하림(하리모토 나츠오) 역 (아역: 김태진)최재성: 최대치(사카이) 역 (아역: 장덕수)’

Start