
PivotTable
ModuleLoad
import pandas as pd
import numpy as np
url = "/Users/min/Documents/ds_study/제로-베이스---데이터-사이언스-스쿨---강의자료---part-01---05--230120-/Part 04. EDA & Part 05. SQL/Part 04. EDA웹 크롤링파이썬 프로그래밍 - 강의자료/210923 - 02. Analysis Seoul Crime/data/"DataLoad
df = pd.read_excel(url + '02. sales-funnel.xlsx')
df.head()
인덱스 설정
Name을 인덱스로 Data. 재설정
# Name을 기준으로 인덱스로 두고 Data 재정렬
pd.pivot_table(df, index = ['Name'], values=['Account', 'Quantity', 'Price']) # 피벗 테이블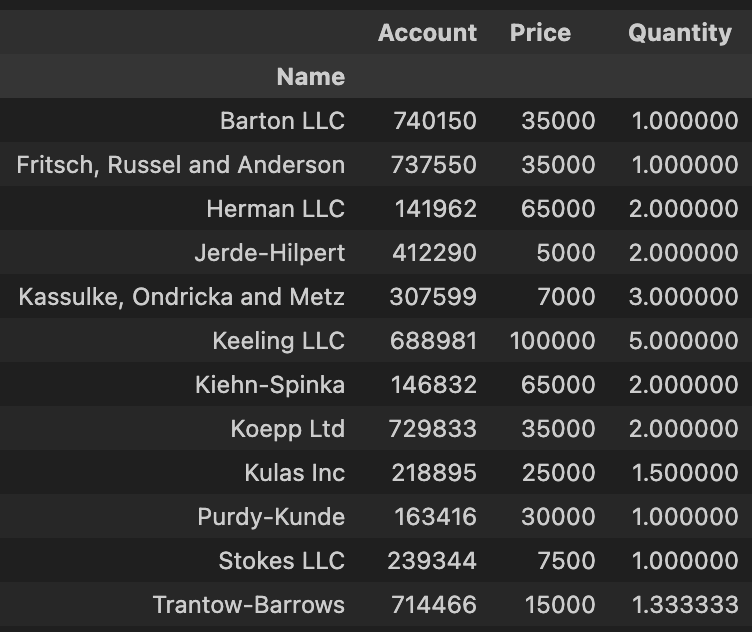
- 인덱스(Index)는 여러개 설정 가능
# 인덱스는 여러개 설정 가능
pd.pivot_table(df, index = ['Name', 'Rep' ,'Manager'], values=['Account', 'Quantity', 'Price'])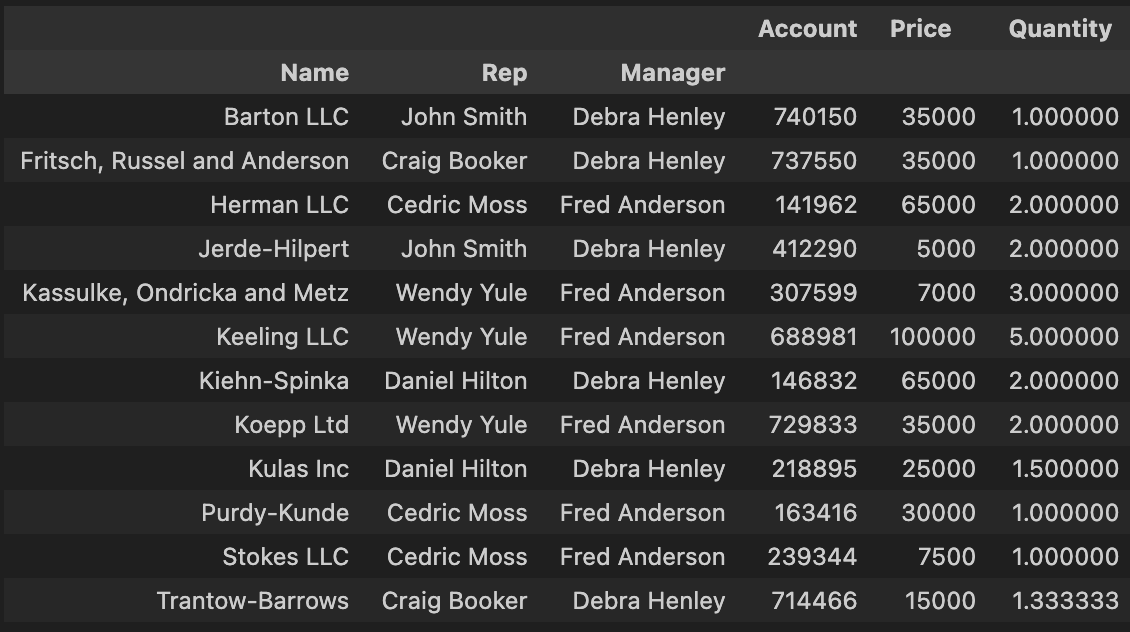
pd.pivot_table(df, index = ['Rep' ,'Manager'], values=['Account', 'Quantity', 'Price'])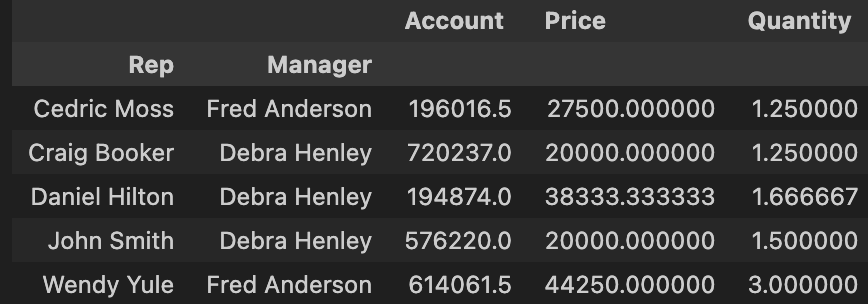
Option
- 중복된 데이터 정리를 위한 Option으로, 기본 Option은 평균(Mean)으로 지정됨
pd.pivot_table(df, index = ['Rep' ,'Manager'], values=['Price']) # 중복된 데이터 정리 기본 옵션 : 평균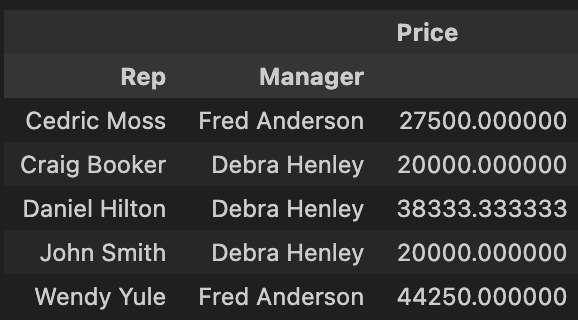
평균(Mean),합계(Sum),길이(Length)등 다양한 Option 설정 가능
pd.pivot_table(df, index = ['Rep' ,'Manager'], values=['Price'], aggfunc = "sum") # 중복된 데이터 정리 옵션 설정 가능 : mean, sum, length 등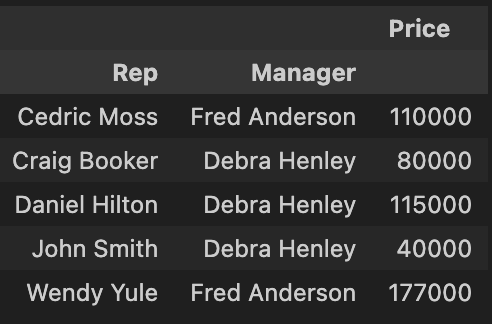
- numpy module을 통해서도 설정 가능
pd.pivot_table(df, index = ['Rep' ,'Manager'], values=['Price'], columns= ['Product'], aggfunc = [np.sum], fill_value = 0) # 중복된 데이터 정리 옵션 설정 가능 : mean, sum, length 등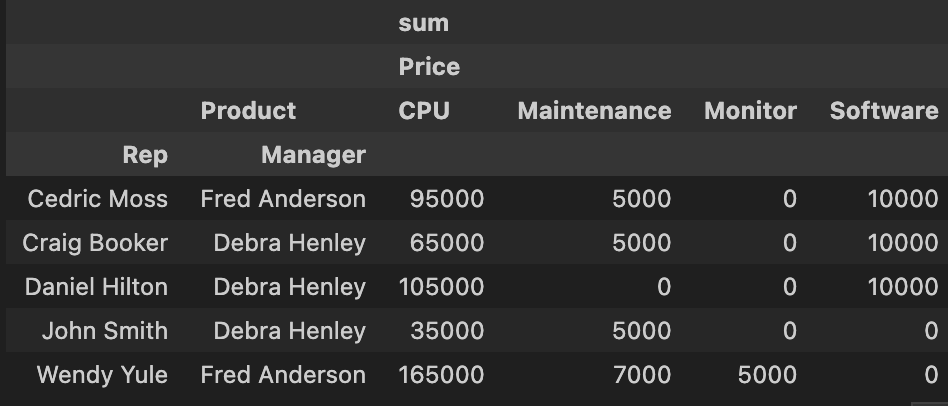
- 여러개의 Option을 표현 가능
pd.pivot_table(df, index = ['Manager', 'Rep' ,'Product'],
values=['Price', 'Quantity'],
aggfunc = [np.sum, np.mean],
fill_value = 0,
margins = True) # 중복된 데이터 정리 옵션 설정 가능 : mean, sum, length 등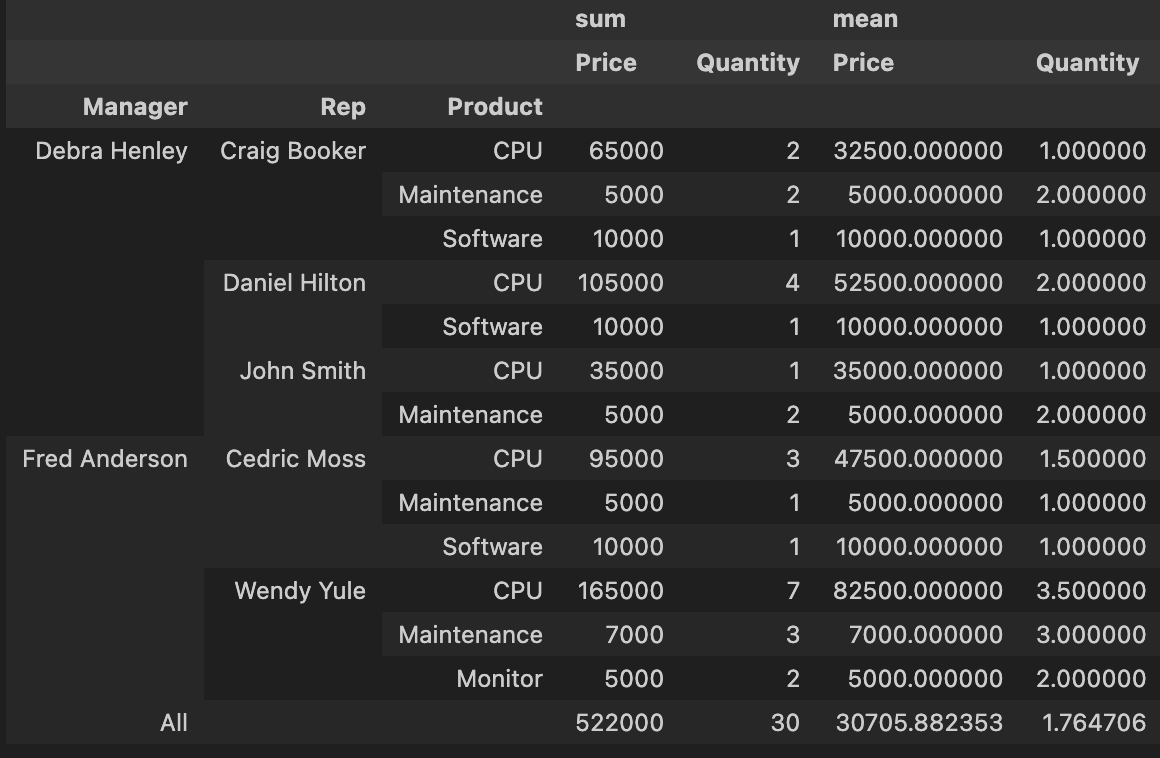

Start