오늘은 파생변수 day..
어제 했어야했는데 ㅎㅎ;
여태까지 한 내용들 튜터님께 피드백을 받았는데 잘 진행하고 있다고 해주셔서 다행이었다 우리 팀장님 덕분이다.. 짱
전체 파일에서 client_id 기준 group by
# groupby + aggregate
grouped = trans_clean.groupby('client_id_y').agg({
'amount': 'mean',
'date': 'last', #휴면 계좌용 - 가장 최근 결제 일자
'acct_open_date': 'min', #휴면 계좌용 - 가장 오래된 계좌 개설 날짜짜
'current_age': 'first',
'retirement_age': 'first',
'credit_limit': 'first',
'gender': 'first',
'latitude': 'first',
'longitude': 'first',
'yearly_income': 'first',
'total_debt': 'first',
'credit_score': 'first',
'num_credit_cards': 'first'
}).reset_index()
grouped- 소득 대비 지출 비율 (
amount/yearly_income)
grouped['income_am'] = ((grouped['amount'] / grouped['yearly_income']) * 100)
grouped[['client_id_y', 'income_am']]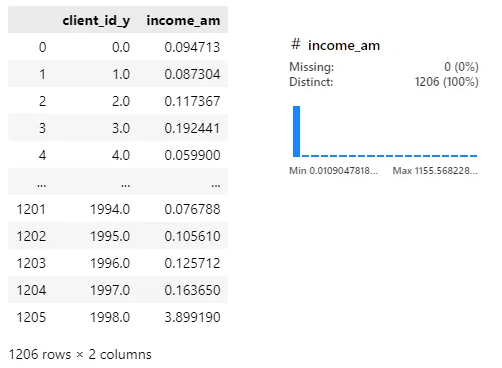
1000 넘는 값도 있는데 이 경우엔 소득 대비 지출이 엄청나다고 봐도 될지..? 잘못된 데이터인지 확인해 봐야할 듯. 100을 곱해도 대부분 극히 적은 숫자인데 1000을 곱해야 하는건지..?
- 소득 대비 한도 (
credit_limit/yearly_income)
grouped['income_limit'] = (grouped['credit_limit'] / grouped['yearly_income'])*100
grouped[['client_id_y', 'income_limit']]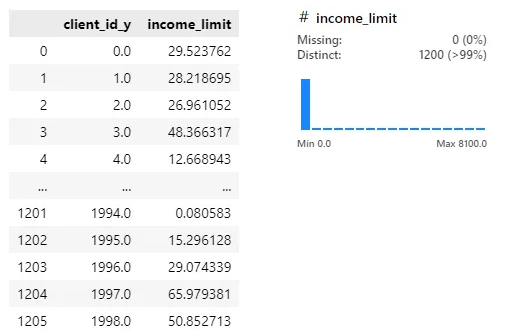
8000 넘는 값 있음, 소득은 낮은데 한도가 너무 큰 값..?
- 소득 대비 부채 (
total_debt/yearly_income)
grouped['debt_income'] = (grouped['total_debt'] / grouped['yearly_income'])
grouped[['client_id_y', 'debt_income']]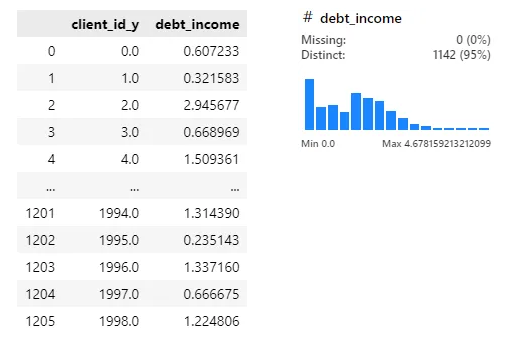
극단적인 값은 X, 부채 비율 높은 사람에게 어떤 카드 추천해줄 수 있을지 고민
- 지출 대비 한도 (
credit_limit/amount)
grouped['am_limit'] = (grouped['credit_limit'] / grouped['amount'])
grouped[['client_id_y', 'am_limit']]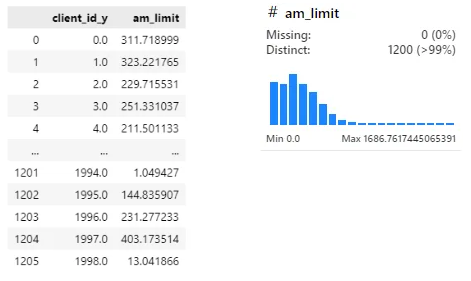
지출은 적은데 한도가 높다 → 돈을 잘 안쓴다?
- 휴면 가능성 ((
last_date-act_open_date) /current_age)
#활동 기간 계산
grouped['active_days'] = (grouped['date'] - grouped['acct_open_date']).dt.days
#휴면 가능성 계산 (나이로 나누기)
grouped['dormancy_score'] = grouped['active_days'] / grouped['current_age']
grouped[['client_id_y', 'active_days', 'dormancy_score', 'current_age']]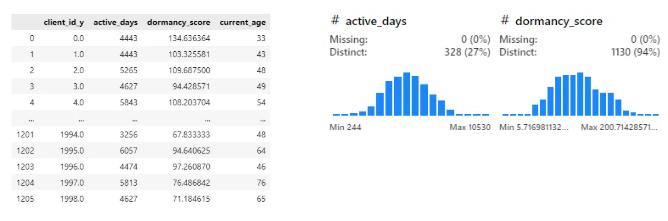
해당 값 클수록 충성고객, 짧을 수록 휴면 가능성
- 신용등급 대비 지출, 한도, 소득 (groupby
credit_grade.mean())
bins = [300, 600, 660, 780, 850]
labels = ['Poor', 'Fair', 'Good', 'Excellent'] # 등급 라벨
# 등급 컬럼 추가
grouped['credit_grade'] = pd.cut(grouped['credit_score'], bins=bins, labels=labels, include_lowest=True)
grouped[['client_id_y', 'credit_grade']]
# 등급 별 결제 금액, 소득, 한도
summary = grouped.groupby('credit_grade')[['amount', 'yearly_income', 'credit_limit']].mean().reset_index()
summary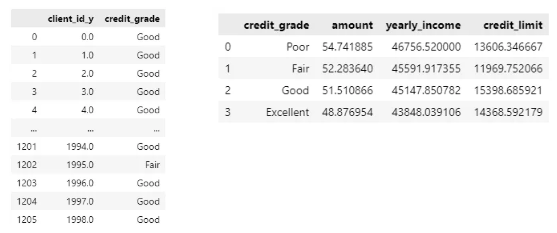
plt.figure(figsize=(10, 6))
sns.barplot(data=grouped, x='credit_grade', y='amount')
plt.title("Average Spending by Credit Grade")
plt.ylabel("Average Amount")
plt.xlabel("Credit Grade")
plt.show()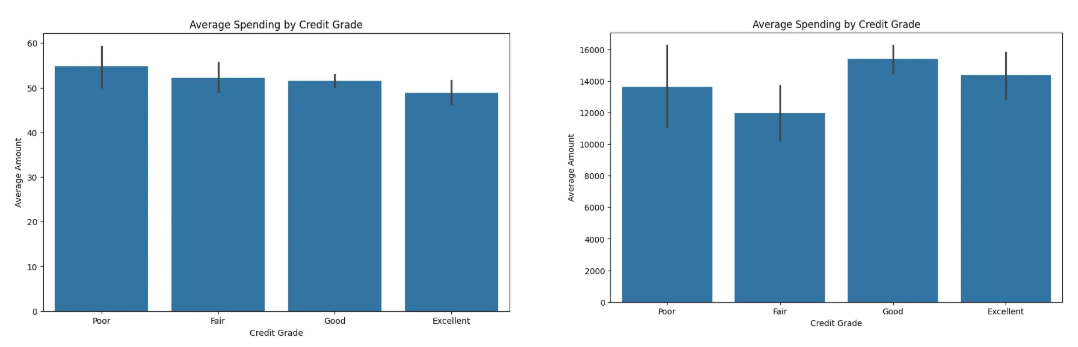
amount,yearly_income은 비슷하게 나타나는데credit_limit은 fair가 더 낮다.. 왜지?- 이걸 어떻게 파생변수로 만들 수 있는지 모르겠음 ㅠ
- 연령+성별+카테고리별 결제 금액 파악 파생변수 ([
age_group,gender,category])[amount].sum()
df = merged_clean[['category', 'amount', 'client_id_x', 'current_age', 'gender']]
df# 연령대별 구분
def age_group(current_age):
if current_age < 20:
return '10대'
elif current_age < 30:
return '20대'
elif current_age < 40:
return '30대'
elif current_age < 50:
return '40대'
elif current_age < 60:
return '50대'
else:
return '60대 이상'
df['age_group'] = df['current_age'].apply(age_group)
df# 소비 총액 구하기
category_age = df.groupby(['age_group', 'gender', 'category'])['amount'].sum().reset_index()
category_age = category_age.sort_values(by=['age_group', 'gender', 'amount'], ascending=[True, True, False]).reset_index()
category_age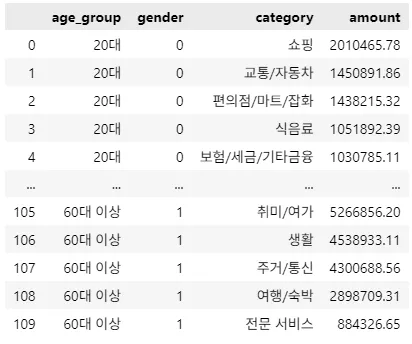
20대 여성 1위 쇼핑 제외 각 1등 교통/자동차로 크게 다르지 않음 …. 핵심 지표라고 생각했는데 ㅠ
# 각 age_group별 총 소비액을 구함
category_age['total'] = category_age.groupby('age_group')['amount'].transform('sum')
# 비율 컬럼 추가
category_age['age_percent'] = category_age['amount'] / category_age['total'] * 100
category_age
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 6))
sns.barplot(data=category_age, x='age_group', y='age_percent', hue='category')
plt.title("consume ratio")
plt.ylabel("consume ratio (%)")
plt.xlabel("age_group")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()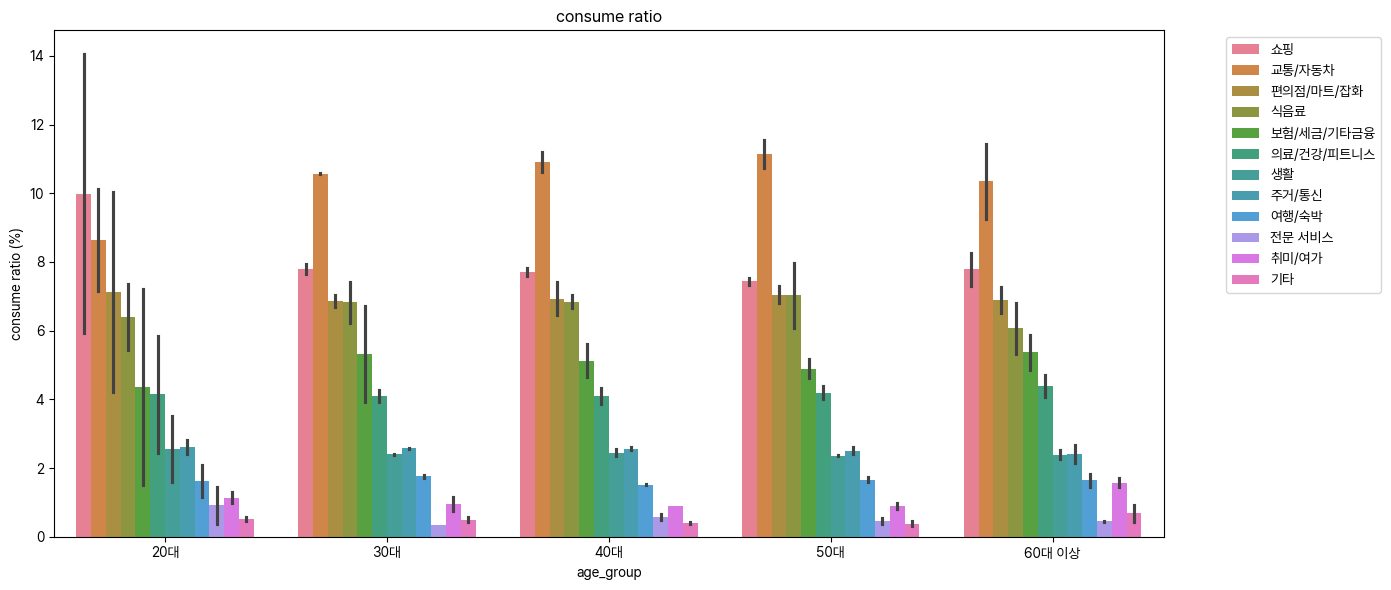
시각화도 해봤다.. 근데 이걸 어떻게 파생 변수 한개로 요약할지는.. 모름..
- use_chip 별 결제 금액
# use_chip 별 결제금액 비율
amount_by_chip = grouped.groupby('use_chip')['amount'].sum()
amount_ratio = amount_by_chip / amount_by_chip.sum()
amount_ratio = amount_ratio.reset_index()
amount_ratio.columns = ['use_chip', 'amount_ratio']
amount_ratio['amount_ratio'] = (amount_ratio['amount_ratio'] * 100).round(2)
amount_ratio['amount_ratio']chip_transaction이 80% 이상이라 큰 의미 없을듯
내일부턴 k-means 노가다 하지 않을까.. 차라리 아무 생각없이 하는 노가다가 나을 것 같기도 하고.. 근데 또 파생변수 계속해서 추가하는게 좋으니까 또 계속 생각은 해야겠지.. 내일의 나 화이팅..

스포츠 광인
"짱"..이라고했다...