Ⅰ. 핵심 키워드
1. SQL
1) SELECT문
① 기본형태
SELECT 필드목록 FROM 테이블- SELECT * FROM City
- SELECT name, popul FROM City;
② 조건문(WHERE)과 함께 사용
SELECT 필드목록 FROM 테이블 WHERE 조건- SELECT * FROM City WHERE name = '서울';
- SELECT name, area FROM City WHERE area > 1000;
- SELECT * FROM City WHERE name != '서울';
- SELECT * FROM City WHERE name = '서울' AND (popul >= 100 OR area >= 700);
③ 부분 문자열 검색(LIKE)
SELECT 필드목록 FROM 테이블 WHERE 필드 LIKE 와일드카드를 포함한 문자 (와일드 카드에 대한 정보는 아래의 표를 참조)

- SELECT * FROM City WHERE name LIKE '%서%’
- SELECT * FROM City WHERE name NOT LIKE '%서%’
- SELECT * FROM City WHERE name LIKE '[a-z]’
- SELECT * FROM City WHERE name LIKE '서_’
④ 이상 이하(BETWEEN)
SELECT 필드목록 FROM 테이블 WHERE 필드 BETWEEN A AND B;
// 문자열에도 사용 가능. 문자열에는 사전 순을 적용- SELECT * FROM City WHERE popul BETWEEN 50 AND 100;
- SELECT name FROM City WHERE (name BETWEEN '가' AND '서') AND (popu BETWEEN 50 AND 100);
⑤ 포함 여부 확인(IN)
SELECT 필드목록 FROM 테이블 WHERE 필드 IN ('문자열1','문자열2','문자열3')- SELECT * FROM City WHERE name IN ('서울','대구');
- SELECT * FROM City WHERE name NOT IN ('서울','대구','부산');
2) INSERT문
INSERT INTO 테이블명(컬럼1, 컬럼2, 컬럼3,…) VALUES(값1, 값2, 값3,…)테이블의 순서에 맞게 모든 컬럼에 배정될 값을 VALUES에서 전달하는 경우, 컬럼은 생략할 수 있다. 특정 컬럼에만 값을 배정하는 경우라 할지라도 NOT NULL인 컬럼은 생략할 수 없다.
- INSERT INTO EMPLOYEE VALUES(18021, '홍길동', '대전시 중구 중앙로 76', '설계부');
- INSERT INTO EMPLOYEE VALUES(20002, '홍길순', '' , '토목' );
- INSERT INTO EMPLOYEE(EMP_ID, EMP_NAME, DEPT_NAME) VALUES(17113, '강감찬', '총무부');
- INSERT INTO EMPLOYEE(EMP_ID, EMP_NAME) VALUES(19007, '이성계');
결과는 아래와 같이 나타나게 된다.

3) UPDATE문
① 기본형태
UPDATE 테이블명 SET 컬럼1 = 값1, 컬럼2 = 값2 WHERE 조건 = 조건값;- UPDATE EMPLOYEES SET Salary=2500 WHERE Salary < 2500; COMMIT;
- UPDATE EMPLOYEES SET Last_Name = ‘Drexler’ WHERE Employee_ID = ‘157’; COMMIT;
② 서브쿼리와 함께 사용
UPDATE 테이블명 SET 컬럼1 = 서브쿼리 WHERE 조건 = 조건값;변경하고자 하는 값을 자신은 모르고 다른 테이블에서 조회한 값으로 갱신해야 하는 경우 서브쿼리로 변경하고자 하는 값을 가져와서 갱신해주면 된다. 아래의 예시는 서브쿼리의 내용이 중복될 경우 한번에 업데이트할 수도 있음을 보여준다.
UPDATE EMPLOYEES
SET Salary = (SELECT Salary FROM EMPLOYEES WHERE Last_Name=’Jones’),
Manager_ID = (SELECT Manager_ID FROM EMPLOYEES WHERE Last_Name=’Jones’),
Department_ID = (SELECT Department_ID FROM EMPLOYEES WHERE Last_Name=’Jones’),
WHERE Employee_ID IN (’103’, ‘203’);
COMMIT;UPDATE EMPLOYEES
SET (Salary, Manager_ID, DEPARTMENT_ID) = (SELECT (Salary, Manager_ID, DEPARTMENT_ID)
FROM EMPLOYEES WHERE Last_Name=’Jones’)
WHERE Employee_ID IN (’103’, ‘203’);
COMMIT;4) DELETE문
① 테이블 전체 데이터 삭제
DELETE FROM 테이블명- DELETE FROM Test;
② 조건절을 이용하여 일부 삭제
DELETE FROM 테이블명 WHERE 조건- DELETE FROM TEST WHERE Name='철수';
5) WHERE절
테이블의 필터링을 위해 사용되며 위에서 예시를 많이 보았기 때문에, 기본형태를 제외한 응용 형태를 알아보기로 하자.
① 논리연산(AND, OR)
SELECT * FROM EMPLOYEE WHERE Number = 30 AND JOB = ‘Sales_Man’;② 산술연산(+, -, *, /)
SELECT * FROM EMPLOYEE WHERE Number + 10 = 30;③ 대소비교(>, ≥, <, ≤)
SELECT * FROM EMPLOYEE WHERE Salary ≥ 3000;
// 문자열의 경우, 사전 순으로 비교한다.④ 등가비교(=, ≠)
SELECT * FROM EMPLOYEE WHERE Salary ≠ 3000;
// ≠와 <>, ^=는 모두 같은 의미이다.⑤ 논리 부정 연산
SELECT * FROM EMPLOYEE WHERE NOT Salary = 3000;⑥ 포함연산(IN)
SELECT * FROM EMPLOYEE WHERE Job IN(’Manager’, ‘Sales_Man’, ‘Clerk’);⑦ 이상/이하 연산(BETWEEN)
SELECT * FROM EMPLOYEE WHERE Salary NOT BETWEEN 2000 AND 3000;⑧ LIKE + 와일드카드
SELECT * FROM EMPLOYEE WHERE Name LIKE ‘S%’;⑨ IS NULL, IS NOT NULL
SELECT * FROM EMPLOYEE WHERE Dept IS NULL; 연산에 대한 우선순위도 존재하는데, 이는 때때로 유용할 수 있다.

6) GROUP BY절
데이터 유형 별 갯수를 알고 싶을 때, 컬럼의 데이터를 그룹화할 수 있는 GROUP BY절을 사용한다. GROUP BY와 함께 쓰이는 개념으로, HAVING이 있다. GROUP BY는 특정 컬럼을 그룹화하는 명령이고, HAVING은 특정 컬럼을 그룹화한 결과에 조건을 거는 명령이다.
그러면 GROUPBY에 WHERE절을 사용한 것과 동일한 것 아니냐 하고 오해할 수 있는데, WHERE은 그룹화 하기전에 조건을 처리한다는 점에서 명백한 차이가 있다.
① 컬럼 그룹화
SELECT 컬럼 FROM 테이블 GROUP BY 그룹화할 컬럼;② 조건 처리 이후 컬럼 그룹화
SELECT 컬럼 FROM 테이블 WHERE 조건식GROUP BY 그룹화할 컬럼;③ 컬럼 그룹화 이후 조건 처리
SELECT 컬럼 FROM 테이블 GROUP BY 그룹화할 컬럼 Having 조건식;④ 조건 처리 이후 컬럼 그룹화 이후 다시 조건 처리
SELECT 컬럼 FROM 테이블 WHERE 조건식GROUP BY 그룹화할 컬럼 Having 조건식;⑤ ORDER BY가 있는 경우
SELECT 컬럼 FROM 테이블 WHERE 조건식GROUP BY 그룹화할 컬럼 Having 조건식 ORDER BY 컬럼 1;7) ORDERBY절
내림차순 혹은 오름차순으로 데이터를 정렬해야 할 때 ORDER BY절을 사용한다. 보통 ORDER BY는 가장 마지막에 위치한다.
SELECT * FROM 테이블 명 ORDER BY 기준 컬럼 ASC or DESC
// ASC는 기본 값이므로 오름차순 정렬을 원하는 경우 생략 가능하다.2. JOIN
1) INNER JOIN
내부조인은 쉽게 말해 두 테이블의 교집합이다. 즉, 겹치는 컬럼이 존재하는 경우에만 사용 가능하다. 아래의 예시를 보자.
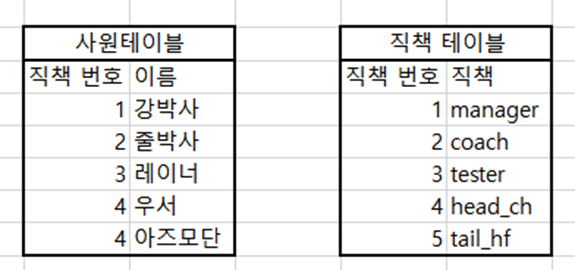
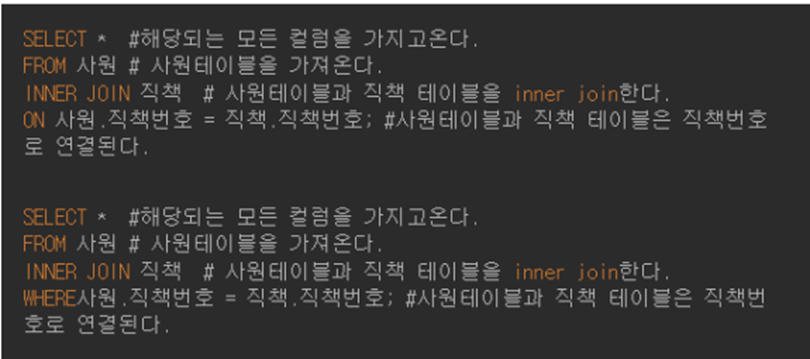
사원 테이블과 직책 테이블에서 INNER JOIN을 수행해서 두 테이블의 모든 정보를 가져온다고 하자. 두 테이블의 연결고리 역할을 하는 직책 번호 컬럼으로 INNER JOIN을 수행하는 SQL문은 아래와 같다(ON은 WHERE로 대체 가능하다).
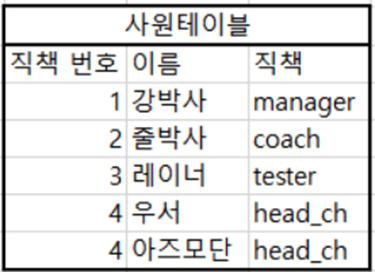
그 결과 테이블은 아래와 같이 정리된다.
2) OUTER JOIN
외부조인은 두 테이블의 정보를 이용한다는 점은 내부조인과 같다. 하지만 내부조인은 단순히 교집합이 되는 컬럼만 가지고 오는 반면, 외부조인은 그렇지 않다.
OUTER JOIN에는 기준 테이블(드라이빙 테이블)과 대상 테이블이 있는데 대상 테이블의 경우 JOIN 조건이 일치하지 않아도 가져온다.
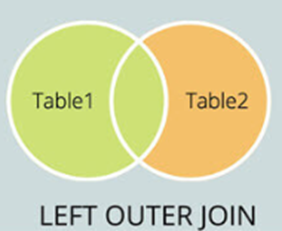
① LEFT JOIN
- OUTER JOIN의 한 종류로, LEFT OUTER JOIN이라고도 한다. 아래 그림에서 녹색표시가 되어있는 곳이 해당영역이다.
- 아래의 예시를 보자. 좌측 테이블을 A, 우측 테이블을 B라하자.
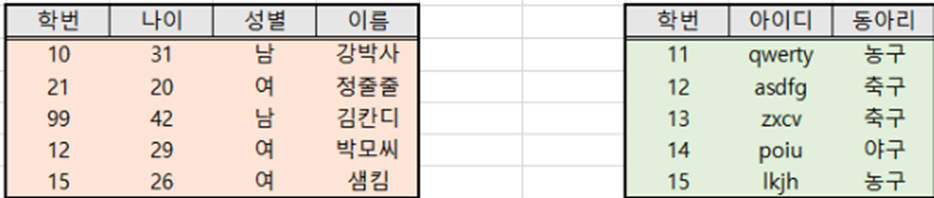
- LEFT OUTER JOIN의 경우 기준 테이블을 왼쪽에 둔다. 기준 테이블은 변경이 없고 대상 테이블은 변경된다.

- 위 SQL문을 실행한 결과는 아래와 같다.
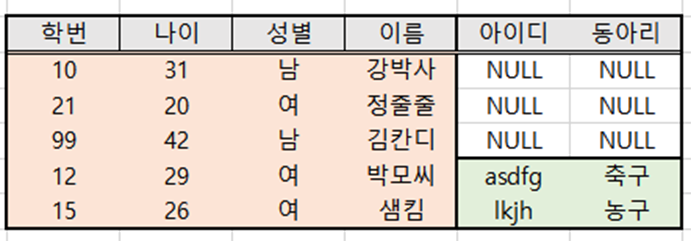
- A 테이블의 학번을 기준으로 B테이블이 이어 붙게 된다. 이 때, 10, 21, 99학번인 학생은 B 테이블에 존재하지 않으므로 NULL 값이 입력되었다.
② RIGHT JOIN
- 마찬가지로 OUTER JOIN의 한 종류로 RIGHT OUTER JOIN이라고도 한다. 아래 그림에서 녹색표시가 되어있는 곳이 해당영역이다.
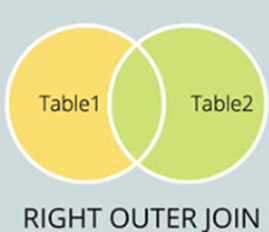
- 기준 테이블을 오른쪽에 두고 OUTER JOIN을 수행한다. 이번에도 기준테이블은 변형이 없고 대상 테이블만 변형된다.

- 위 SQL문을 실행한 결과는 아래와 같다.
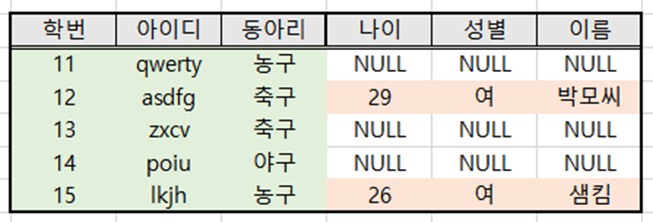
- 이번에는 B 테이블이 기준이기 때문에 B 테이블을 모두 가져왔다. 다만 A 테이블에는 11, 13, 14학번 학생이 없기 때문에 나이와 성별 이름이 모두 NULL이 되었다.
③ FULL OUTER JOIN
- FULL OUTER JOIN 은 왼쪽과 오른쪽 테이블의 모든 데이터를 읽어 결과를 생성한다. 즉, RIGHT OUTER JOIN과 LEFT OUTER JOIN의 결과를 합친 것으로 볼 수 있다.
- 기준테이블을 A, 대상 테이블을 B라하자.

- 위의 SQL문을 실행한 결과는 아래와 같다.
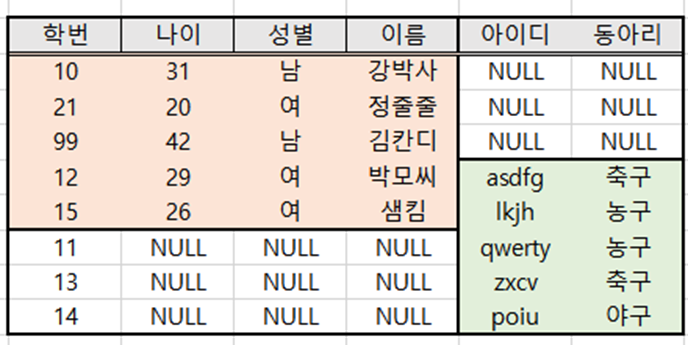
- A와 B의 내용이 모두 포함되었고 이에 따라 생기는 빈칸에는 NULL이 입력되었다.
3. 서브쿼리
먼저 쿼리란, 데이터베이스에 정보를 요청하는 것을 의미한다. 쿼리는 웹 서버에 특정한 정보를 보여달라는 웹 클라이언트 요청에 의한 처리이다. 이러한 점에서 알 수 있듯, 우리는 SQL로 작성된 Query를 통해 데이터베이스에서 자료를 불러오게 된다.
서브쿼리란 하나의 SQL문에 포함되어 있는 또 다른 SQL문을 말한다. 서브쿼리를 사용할 때에는 반드시 괄호로 감싸서 사용해야 한다. 서브쿼리에서는 ORDER BY는 사용할 수 없지만, 단일 행 또는 복수 행 비교 연산자와 함께 사용하는 것은 가능하다. 서브쿼리를 사용할 수 있는 절은 아래와 같다. 예시는 UPDATE문의 설명 중 서브쿼리와 함께 사용 부분을 참고하라. (서브쿼리의 끝에는 세미콜론을 사용하지 않는다.)
- SELECT 절
- FROM 절
- WHERE 절
- HAVING 절
- ORDER BY 절
- INSERT 문의 VALUES절
- UPDATE 문의 SET절
4. 집계함수
집계함수란, 여러 행으로부터 하나의 결과값을 반환하는 함수이다. SELECT 구문에서만 사용되며, 일반적인 함수들이 행끼리 연산을 수행하는 반면, 집계함수는 열끼리 연산을 수행한다는 특징이 있다. 주로 평균, 합, 최대, 최소 등을 구하는 데 이용된다. 참고로 GROUP BY와 HAVING을 이용하여, 테이블의 일부 행에만 집계 함수를 적용할 수도 있다.
① COUNT
- 특정 열의 행의 개수를 세는 함수로 COUNT *의 경우 테이블에 존재하는 행의 개수가 반환되고, 특정 열에 사용하는 경우 NULL이 아닌 행의 개수를 반환한다.
- SELECT COUNT(Name) FROM table;
- SELECT COUNT(DISTINCT Country) FROM table;
// DISTINCT 키워드를 이용하면 중복을 제외한 값의 개수를 구할 수 있다.② MIN/MAX
SELECT MAX(Age) FROM table;
// 숫자뿐 아니라 문자에도 사용 가능하다.
③ AVG/SUM
숫자에만 적용 가능하고 NULL값은 무시된다.
SELECT AVG(Age) FROM table;
SELECT SUM(Weight) / COUNT(Weight) FROM table;
5. 윈도우 함수
SQL의 윈도우 함수란 행과 행 간의 비교, 연산 등을 정의하기 위한 함수이다. 다른 함수들과 달리 중첩해서 사용할 수는 없지만 서브 쿼리에서는 사용 가능하다.
1) 순위함수
① RANK
- ORDER BY를 포함한 쿼리문에서 특정 컬럼의 순위를 구하는 함수이다. PARTITION 내에서 순위를 구할 수도 있고 전체 데이터에 대한 순위를 구할 수도 있다. 동일한 값에 대해서는 같은 순위를
부여하며 중간 순위를 비운다.

② DENSE_RANK
- RANK와 동일하게 동작하나, 같은 값에 대해서는 같은 순위를 부여하고 중간 순위를 비우지 않는다.

2) 일반 집계함수
SUM, MAX, MIN, COUNT, AVG 등이 있다. 설명은 이미 했으니 넘어가도록 하겠다.
3) 그룹 내 행 순서 함수
FIRST_VALUE, LAST_VALUE, LAG, LEAD가 있다. 사용빈도가 낮으므로 자세한 설명은 생략하기로 한다.
4) 그룹 내 비율 함수
RATIO_TO_REPORT, CUME_DIST가 있다. 역시 사용빈도가 낮으므로 자세한 설명은 생략하기로 한다
[이미지 출처]
