6. OAuth
1) 개념
OAuth란, Open Authorization의 줄임말로, 웹 및 모바일 애플리케이션에서 사용자 인증 및 권한 부여를 위한 개방형 표준 프로토콜을 말한다. 이 프로토콜을 통해 별도의 회원가입 없이 외부 서비스에 인증이 가능하고, 해당 서비스의 API를 이용할 수 있게 된다. 현재는 OAuth 2.0이 사용되고 있다.
※ OAuth 1.0 VS OAuth 2.0
HTTPS가 필수가 되면서 암호화를 전적으로 HTTPS에 맡길 수 있게 되었다.
OAuth를 사용하면 별도의 비밀번호 제공없이 다른 웹 사이트에 있는 자신의 정보에 대해 웹이나 애플리케이션에 접근 권한을 부여할 수 있다. OAuth의 가장 큰 이점은 여러 곳에 개인정보를 제공할 필요가 없다는 것이다.
카카오나 구글, 페이스북의 정보 관리는 어느 정도 믿을 수 있지만, 생판 모르는 사이트의 경우 내 개인정보를 맡기기에 꺼려지는 부분이 있을 수 있다. 보안에 대한 사용자들의 관심이 늘어남에 따라 최근에 출시된 대부분의 서비스에서 OAuth 기능을 제공하고 있다.
2) OAuth 인증 과정
인증서버는 google이나 kakao의 서버를 말하고, 자원서버는 소셜로그인을 통해 API를 지원받기 위한 사이트의 서버를 말한다.
① 클라이언트는 사용자에게 서비스 제공자의 인증 페이지로 리다이렉트하는 링크를 제공한다.
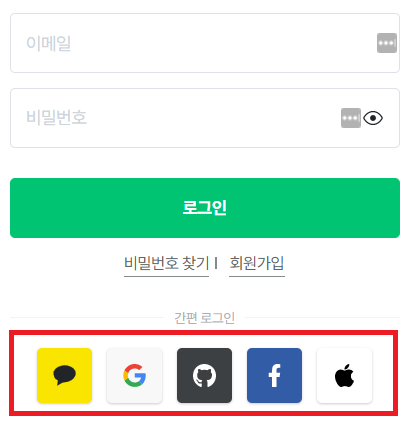
② 클라이언트는 인증 서버에 로그인 페이지를 요청하고, 사용자는 서버가 제공한 인증페이지로 이동한다.
③ 인증페이지에서 자신의 ID와 PW를 입력하여 인증을 진행한다.
④ 입력받은 값을 인증 서버에 보내면, 인증 서버는 Authorization code를 발급해준다.
⑤ 이 code로 인증 서버에 Access Token을 요청하면, 인증 서버가 Access Token을 발급해준다.
⑥ 자원서버에 Access Token을 담아 데이터를 요청하면, 이 토큰을 검증한 후 응답을 보낸다.
⑦ 마찬가지로, Access Token이 만료되었거나 위변조 되었을 경우에 클라이언트는 Refresh Token을 보내 Access Token을 재발급 받는다.
OAuth를 사용하면 사용자는 자신의 계정 정보를 직접 제공하지 않고도 안전하게 애플리케이션에 액세스할 수 있다. 클라이언트는 사용자의 암호를 저장하거나 액세스하지 않으며, 서비스 제공자는 사용자의 권한을 관리하고 액세스 토큰을 통해 클라이언트의 요청을 제어한다. 이로써 사용자의 개인 정보 보호와 보안을 강화할 수 있다.
7. Social Token
Social Token은 소셜 미디어 플랫폼이나 서비스에서 사용되는 토큰이다. 이 토큰은 사용자가 해당 플랫폼에 인증하고 권한을 부여받은 후에 발급되며, 일반적으로 API 요청을 보낼 때 사용된다.
소셜 미디어 플랫폼은 사용자의 데이터를 보호하기 위해 액세스 권한을 효과적으로 관리해야 한다. 따라서 사용자가 인증되고 권한을 부여받은 후에는 해당 플랫폼의 API를 사용하기 위한 인증 수단이 필요하다. 이 때, Social Token이 사용되는 것이다.
Social Token은 주로 OAuth (Open Authorization) 프로토콜을 기반으로 발급된다. OAuth는 위에서 설명한 바 있듯 사용자가 자신의 계정 정보를 제3자 애플리케이션에 공유하지 않으면서도 제3자 애플리케이션이 사용자의 계정에 접근할 수 있는 권한을 제공하는 프로토콜이다. OAuth를 사용하면 사용자는 소셜 미디어 플랫폼의 인증 및 권한 부여 과정을 거치고, 플랫폼은 사용자에게 액세스 토큰(소셜 토큰)을 발급하여 제3자 애플리케이션이나 서비스가 해당 플랫폼의 API를 사용할 수 있도록 한다.
소셜 토큰은 일반적으로 문자열 형태로 제공되며, API 요청의 인증 헤더에 포함되어 전달된다. 이 토큰은 사용자의 신원을 확인하고 해당 사용자가 API를 호출할 권한을 가지고 있는지 확인하는 데 사용된다. API서버는 소셜 토큰을 검증하여 요청을 처리하고, 유효하지 않은 토큰이나 권한이 없는 토큰의 경우 요청을 거부한다.
8. Paging 처리
먼저 Paging이란, 사용자에게 데이터를 제공할 때, 전체 데이터 중의 일부를 보여주는 방식이다. 이는 페이지의 로딩 속도를 빠르게하고, 원하는 데이터를 빠르게 찾을 수 있는 장점을 제공한다.

페이징 및 검색을 처리하는 데에는 몇 가지 파라미터가 필요하다.

페이징과 검색만 해도, 뷰(HTML)에서 수집해야할 파라미터가 5개나 된다. 파라미터가 많은 만큼 클래스로 관리하는 것이 효율적이다. 이외에도 다양한 파라미터가 있는데, 이 내용은 직접 코드를 실습해보면서 확인하기로 하고 넘어가자.
페이징 처리는 JPA에서 조회기능을 구현할 때 빠져선 안 되는 중요한 기능이다. 사용자 목록을 조회할 때, 사용자가 만명이라고 해서 만명의 정보를 한번에 보내면 서버의 부하가 크게 걸리기 때문에 10000명을 한번에 보내지 않고, 한번 보낼 때 수를 정해서 보낸다. 페이지 수를 10으로 지정하면 최대 10페이지까지만 표기한다.
몇번째 페이지를 불러올건지, 1페이지당 몇개를 불러올건지를 요청해서 서버에 넘겨주면, 서버는 그 요청을 받아서 페이지 개수에 맞게 인덱싱을 해준다. 이는 데이터베이스 쿼리의 OFFSET과 LIMIT 기능을 활용해 구현된다. 이 때, 서버는 클라이언트에게 다음 페이지가 존재함을 반드시 알려주어야 한다.
9. Regex
Regex는 Regular Expression의 줄임말로 정규표현식을 의미한다. Regex는 문자열 패턴을 표현하고 일치하는 문자열을 검색하거나 변형하는 데 사용되는 형식 언어이다. 정규 표현식은 다양한 프로그래밍 언어와 텍스트 편집기에서 지원되며, 문자열 처리와 검색 작업을 간편하게 수행할 수 있도록 도와준다.
문자열 패턴에는 문자, 숫자, 공백, 특수문자 등이 포함될 수 있어 이메일 주소, 전화번호, URL, 날짜 형식 등의 특정 패턴을 찾거나 추출할 수 있다. 정규 표현식은 강력하고 유연한 문자열 처리 도구로써, 데이터 유효성 검사, 문자열 추출, 문자열 대체 등 다양한 용도로 활용된다. 하지만 표현식 자체가 복잡하고 이해하기 어렵다는 단점이 있다. 아래는 우리가 실습에서 진행한 코드 중 일부이다. 이메일이 정규표현식과 일치하지 않을 경우 INVALID_EMAIL 에러를 발생시킨다.
@PostMapping("/log-in")
public BaseResponse<PostLoginRes> loginMember(@RequestBody PostLoginReq postLoginReq){
try{
if(!isRegexEmail(postLoginReq.getEmail()))
return new BaseResponse<>(POST_USERS_INVALID_EMAIL);
return new BaseResponse<>(memberService.login(postLoginReq));
} catch (BaseException exception) {
return new BaseResponse<>(exception.getStatus());
}
}10. Test.env, Prod.env
파일을 작성하다보면, 코드에 개인정보와 같이 외부로 공개되어서는 안되는 정보를 다뤄야 하는 상황이 생길 수 있다. 이런 경우, 직접적으로 파일에 정보를 넣는 대신에 .env 파일을 생성해 파일을 따로 관리하는 것이 유용하다.
일반적으로 test.env파일은 테스트 환경을 위해 사용되며, prod.env파일은 프로덕션(실제 운영)환경을 위해 사용된다. 이러한 환경변수 파일을 일반적으로 key-value의 쌍으로 구성되며, 각 키는 애플리케이션의 설정 값을 나타낸다.
<test.env>
DB_HOST=localhost
DB_PORT=3306
DB_USERNAME=testuser
DB_PASSWORD=testpass
LOG_LEVEL=DEBUG<prod.env>
DB_HOST=prodhost
DB_PORT=3306
DB_USERNAME=produser
DB_PASSWORD=prodpass
LOG_LEVEL=INFO위의 예시에서 test.env는 로컬 테스트 환경을 위해 데이터베이스의 호스트, 포트, 사용자 이름, 암호, 로깅 수준을 설정하고 있다. 반면, prod.env는 실제 운영 환경을 위한 데이터베이스의 호스트, 포트, 사용자 이름, 암호, 로깅 수준을 설정하고 있다.
애플리케이션은 이러한 환경 변수 파일을 읽어와서 해당 환경에 맞는 설정 값을 사용한다. 스프링 프레임워크에서는 application.properties 또는 application.yml 파일을 통해 환경 변수를 설정하고, 환경 변수 파일의 값을 참조할 수 있다.
환경 변수 파일을 사용하여 애플리케이션을 구성하면, 다양한 환경에서 동일한 코드를 사용하면서 환경별로 다른 설정 값을 유지할 수 있다.
11. In-app Billing
In-app Billing은 모바일 어플리케이션 내에서 디지털 컨텐츠나 추가 기능을 판매하고 구매하는 기능을 제공하는 것을 의미한다. In-app billing은 앱 사용자가 앱 내에서 다양한 디지털 상품을 구매할 수 있도록 지원한다. 종류는 아래와 같이 구분될 수 있다.
① 소비성 아이템 (Consumable Items)
- 가상 화폐, 게임 내 아이템 등과 같이 사용 후 소모되는 아이템이다.
- 여러 번 구매할 수 있다.
② 비소비성 아이템(Non-consumable Items)
- 한번 구매하면 영구적으로 사용 가능한 아이템이다.
- 앱의 광고 제거 기능, 프리미엄 기능, 추가 콘텐츠 등이 해당된다.
③ 구독(Subscription)
- 특정 기간 동안 앱의 프리미엄 서비스, 콘텐츠 등에 액세스할 수 있는 기능이다.
- 월간, 연간 등의 구독 옵션을 제공할 수 있다.
In-app Billing은 주로 모바일 앱 플랫폼(Google Play 스토어, App Store 등)에서 제공하는 기능을 활용하여 구현된다. 플랫폼은 개발자가 앱 내 구매를 관리하고 사용자 결제를 처리할 수 있는 API와 도구를 제공한다. 개발자는 이러한 API를 사용하여 앱 내에서 구매 상품의 목록을 표시하고, 구매 프로세스를 처리하고, 결제 정보를 관리할 수 있다.
In-app Billing을 통해 개발자는 앱을 무료로 제공하면서 추가적인 수익을 창출하고, 사용자는 앱 내에서 원하는 기능이나 콘텐츠를 손쉽게 구매할 수 있다.
Ⅱ. 보충 설명
1. 서버 클러스터링과 Stateless
서버 클러스터링은 여러 대의 서버를 하나의 클러스터로 그룹화하여 작동하는 방식을 말한다. 클러스터에 속한 각 서버는 동일한 애플리케이션 또는 서비스를 실행하며, 클러스터 전체로 작업을 분산시키고 부하를 분담함으로써 성능과 가용성을 향상시킨다. 서버 클러스터링은 다양한 이점을 제공한다.
① 가용성과 신뢰성을 향상
- 클러스터에 속한 서버 중 하나가 고장나더라도 다른 서버가 작업을 처리할 수 있으므로, 시스템 전체의 가용성이 유지된다.
② 서버 성능 향상
- 클러스터는 작업을 분산시킴으로써 부하를 분담하므로, 각 서버는 처리해야 할 작업이 줄어들어 응답 시간이 개선될 수 있다.
③ 확장성 제공
- 클러스터에 새로운 서버를 추가함으로써 시스템의 용량을 증가시킬 수 있다.
- 사용량이 증가할 때 유연하게 대응할 수 있다.
Stateless 웹 애플리케이션은 확장성과 재사용성이 용이하기 때문에 서버 클러스터의 성능과 가용성을 향상시킬 수 있다.
2. 로드밸런싱과 Stateless
로드 밸런싱은 여러 대의 서버 사이에 들어오는 네트워크 트래픽을 균등하게 분산시키는 기술이다. 로드 밸런싱을 사용하면 서버의 부하를 분산시켜 성능을 향상시킬 수 있으며, 가용성과 신뢰성을 높일 수 있다.
로드 밸런싱은 클라이언트의 요청을 여러 대의 서버로 분배하는 역할을 한다. 클라이언트는 로드 밸런서에게 요청을 보내면, 로드 밸런서는 서버 풀에 속한 여러 서버 중 적절한 서버에 요청을 전달한다. 로드 밸런서는 서버들 사이의 부하를 측정하고, 각 서버의 상태를 모니터링하여 효율적인 분배를 수행한다. 이를 통해 부하가 골고루 분산되어 서비스의 응답성과 가용성을 향상시킬 수 있다.
로드 밸런싱은 여러 가지 방식으로 구현될 수 있다. 일반적으로는 두 가지 주요 유형인 서버 기반 로드 밸런싱과 DNS 기반 로드 밸런싱이 있다.
① 서버 기반 로드 밸런싱
- 로드 밸런서가 클라이언트의 요청을 받아들이고, 서버 풀에 있는 여러 대의 서버 중 하나로 요청을 전달한다.
- 로드 밸런서는 서버들의 상태를 모니터링하고, 알맞은 규칙에 따라 트래픽을 분배한다.
② DNS 기반 로드 밸런싱
- DNS 서버를 이용하여 트래픽을 분산시키는 방식이다.
- 여러 대의 서버에 대한 IP 주소를 하나의 도메인 이름에 연결하여 클라이언트의 요청을 분산시킨다.
- DNS 서버는 클라이언트의 요청을 받으면 해당 도메인 이름에 대한 IP 주소를 반환하고, 클라이언트는 해당 IP 주소로 직접 서버에 접속한다.
- DNS 기반 로드 밸런싱은 간단하고 효율적이지만, 서버의 상태 정보를 고려하지 않고 단순히 IP 주소를 반환하기 때문에 상태 정보가 중요한 경우에는 부적합할 수 있다.
Stateless 웹 어플리케이션은 로드 밸런싱을 용이하게 만들어준다. 클라이언트의 상태 정보가 서버에 저장되지 않기 때문에 로드 밸런서는 들어오는 요청을 여러 서버로 단순하게 분산시킬 수 있다. 각 요청은 독립적으로 처리되기 때문에 서버 간의 상태 동기화 문제나 의존성 문제가 발생하지 않는다. 이를 통해 로드 밸런싱의 효과적인 구현이 가능해진다.
[이미지 출처]
