
드디어 그동안 미루고 미루던 AWS S3 실습을 포스팅하러 왔습니다. 이번 포스팅을 통해서 AWS S3는 어떤 서비스인지, 어떻게 생성하는지 알아봅시다.
1. AWS S3 서비스 소개

AWS S3는 인터넷 스토리지 서비스이다. 먼저 S3는 S가 3개라는 뜻이다(마치 EC2가 Elastic Compute Cloud인 것처럼). Simple, Storage, Service의 약자이다. 쉽게 말하면 파일 저장 서비스로, 데이터를 객체 형태로 저장하는 역할을 수행한다. 주로, 이미지나 동영상 파일을 저장하기 위해 사용된다. AWS S3를 사용함으로써 얻을 수 있는 이점은 아래와 같다.
① 높은 내구성과 보안성
- SSL을 통해 데이터를 전송 및 암호화하므로 해킹의 위험으로부터 자유롭다.
② 저렴한 비용
- EC2에 이미지, 영상을 저장할 때보다 훨씬 더 저렴한 비용으로 사용 가능하다.
③ 빠른 처리속도
- 파일 저장에 최적화 되어있어 업로드/다운로드의 속도가 매우 빠르다.
- 정적 웹페이지의 경우 EC2 대신 S3를 이용하여 성능은 높이고 비용은 절감할 수 있다.
④ 저장 용량
- 무한대에 가까운 객체를 저장할 수 있어 확장 및 축소를 고려할 필요가 없다.
2. 배경지식
1) 객체(Object)
S3에 데이터가 저장되는 기본단위로써 파일과 메타데이터로 이루어진다. 객체 하나의 크기는 1Byte부터 5TB까지 허용되며, 메타데이터는 MIME형식으로 파일 확장자를 통해 자동으로 설정된다(임의 지정도 가능).
2) 버킷(Bucket)
S3에서 생성할 수 있는 최상위 디렉토리의 개념으로 이름은 S3 리전 중에서 유일해야 한다. 계정별로 100개까지 생성 가능하며, 버킷에 저장할 수 있는 객체 수와 용량에는 제한이 없다.
3) 표준 스토리지
S3 서비스 수준 계약으로 객체에 대해 99.999999999%의 내구성을 보장하며 99.99%의 가용성을 제공한다. 하지만 높은 내구성을 보장해야 하는 만큼 비용이 높으므로 유실되면 안되는 원본 데이터, 민감정보, 개인정보 등의 중요한 데이터를 저장하는 것이 적합하다.
※ 객체의 내구성과 가용성
내구성(Durability)이란, 시스템이 발생한 데이터를 영구적으로 저장하고 보존하는 능력을 의미한다. 데이터가 시스템에 기록되면, 시스템 장애나 전원 이상과 같은 상황에서도 데이터는 보존되어야 한다. 내구성은 데이터의 지속성을 보장하는 척도이다.
가용성(Availability)은 시스템이 사용자에게 지속적으로 서비스를 제공하고 사용 가능한 상태를 유지하는 능력을 의미한다. 시스템은 장애, 네트워크 문제, 예상치 못한 상황 등에도 계속해서 사용자 요청에 응답할 수 있어야 한다. 가용성은 시스템의 신뢰성과 지속적인 운영을 보장하는 척도이다.
4) RRS(Reduced Redundancy Storage)
표준 스토리지보다 저렴한 비용으로 데이터를 저장할 수 있다. RRS 옵션은 여러 시설 전반에 다양한 디바이스에 객체를 저장하며, 일반 디스크 드라이브의 400배에 달하는 내구성을 제공한다. 하지만, 표준 스토리지 만큼 많이 객체를 복제하지는 않기 때문에 원본을 복제한 데이터나 가공한 데이터를 저장하기에 적합하다.
3. Spring Boot와 S3 연동하기
1) S3 생성하기
① AWS에 접속한 후 S3 서비스로 들어가주자. 좌측 메뉴의 버킷을 클릭하고 버킷 만들기 버튼을 눌러주면 된다.
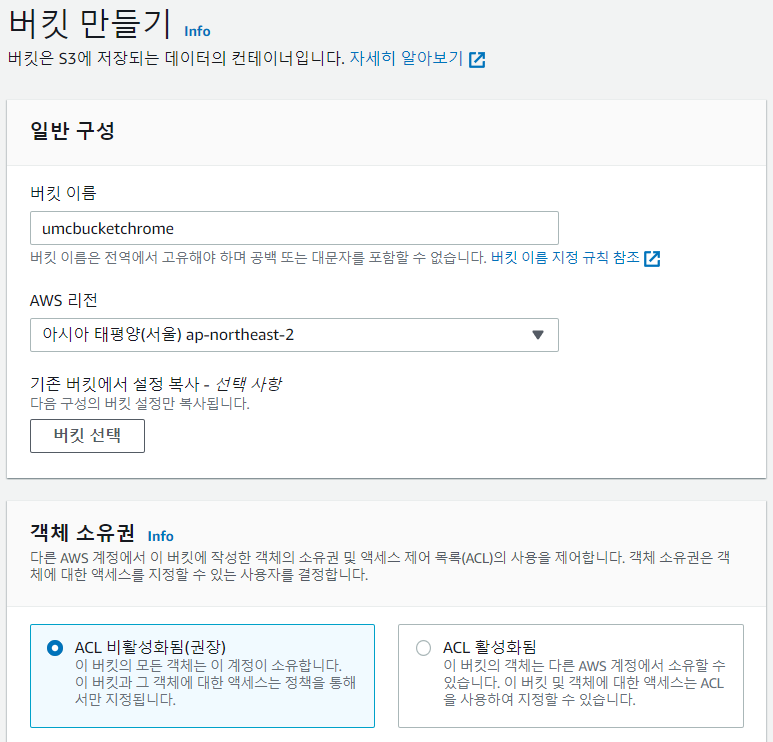
② 이름은 umcbucketchrome이라고 지어주자. 참고로 이름에는 대문자를 사용할 수 없으며 설정 리전에서 유일해야 한다(네이밍이 다소 까다롭다). 리전은 그대로 놔두면 된다. 필요에 따라 가장 가까운 곳으로 바꿔도 된다.
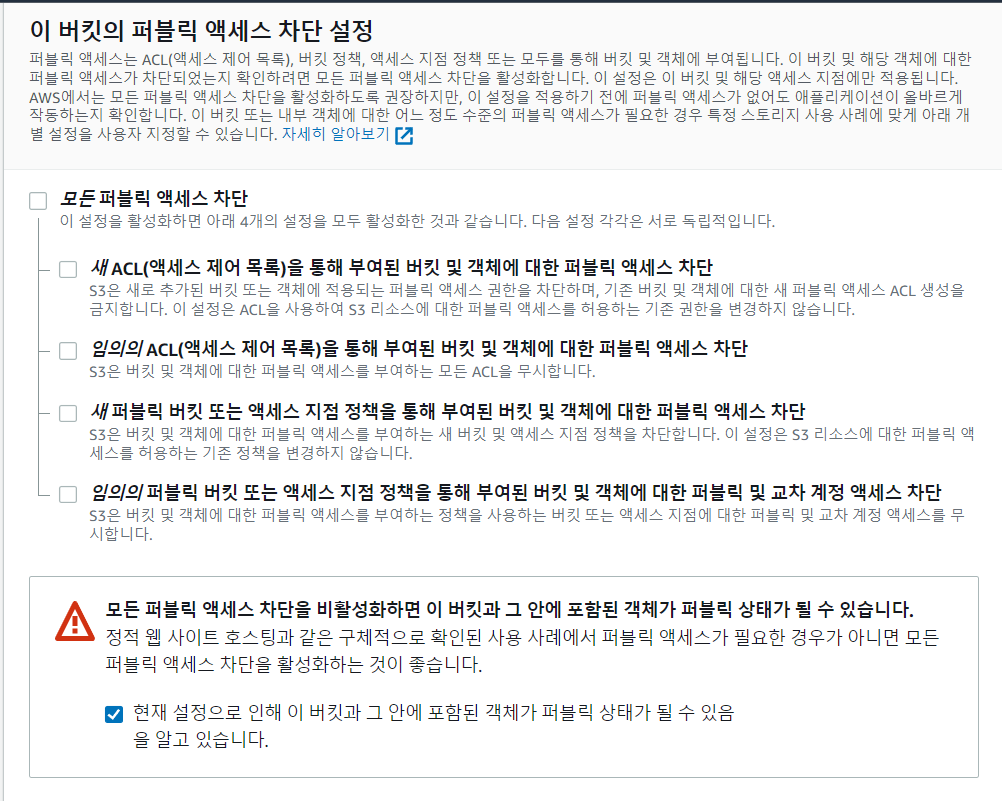
③ 객체 소유권은 비활성으로 놔두고 퍼블릭 액세스 설정창으로 넘어오면 된다. S3를 외부에 공개할 생각이라면 모든 퍼블릭 액세스 차단을 체크해제하면 되고, 공개하지 않을 예정이라면 체크를 해주면 된다. 외부에 S3를 공개하기 위해 체크 해제하기로 하자.
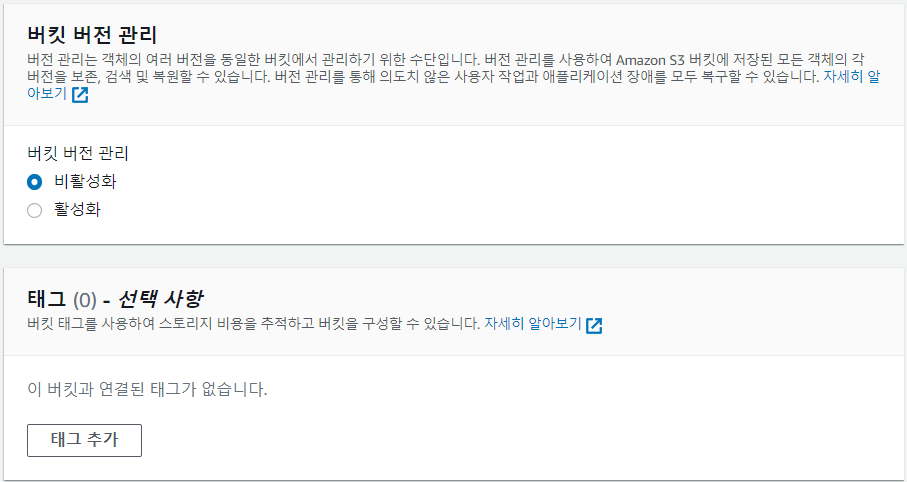
④ 버킷 버전 관리는 비활성화로 설정해야 과금되지 않는다. 만약 활성화할 경우 파일을 버전 별로 관리해주기 때문에 삭제된 파일에 대한 복원 기능을 제공해준다고 한다. 하지만, 과금이 안 나오는게 더 중요하므로 비활성화한다.
⑤ 기본암호화를 활성화하면 버킷에 객체를 저장할 때 암호화해서 저장하고 다운로드할 때 복호화한다고 한다. 굳이 필요하지 않은 내용이므로 비활성화한다.
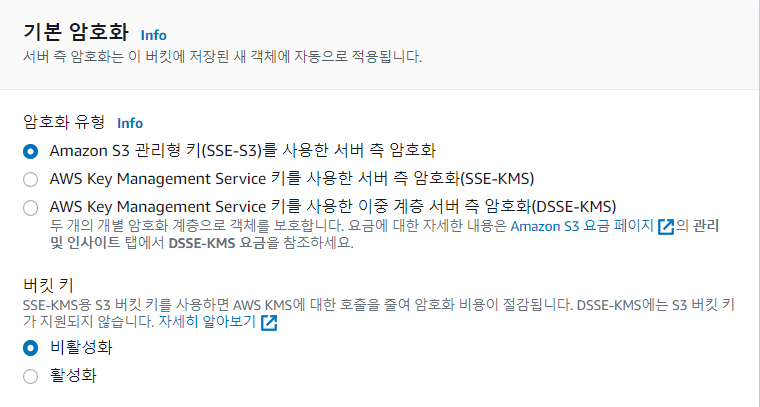
⑥ 고급설정은 그대로 두고 버킷만들기를 눌러주면 생성이 완료된다.
2) Public Access 설정하기(퍼블릭 정책 활성화)

① 생성된 버킷을 클릭하여 권한 > 버킷 정책 > 편집 > 정책 생성기를 클릭한다.
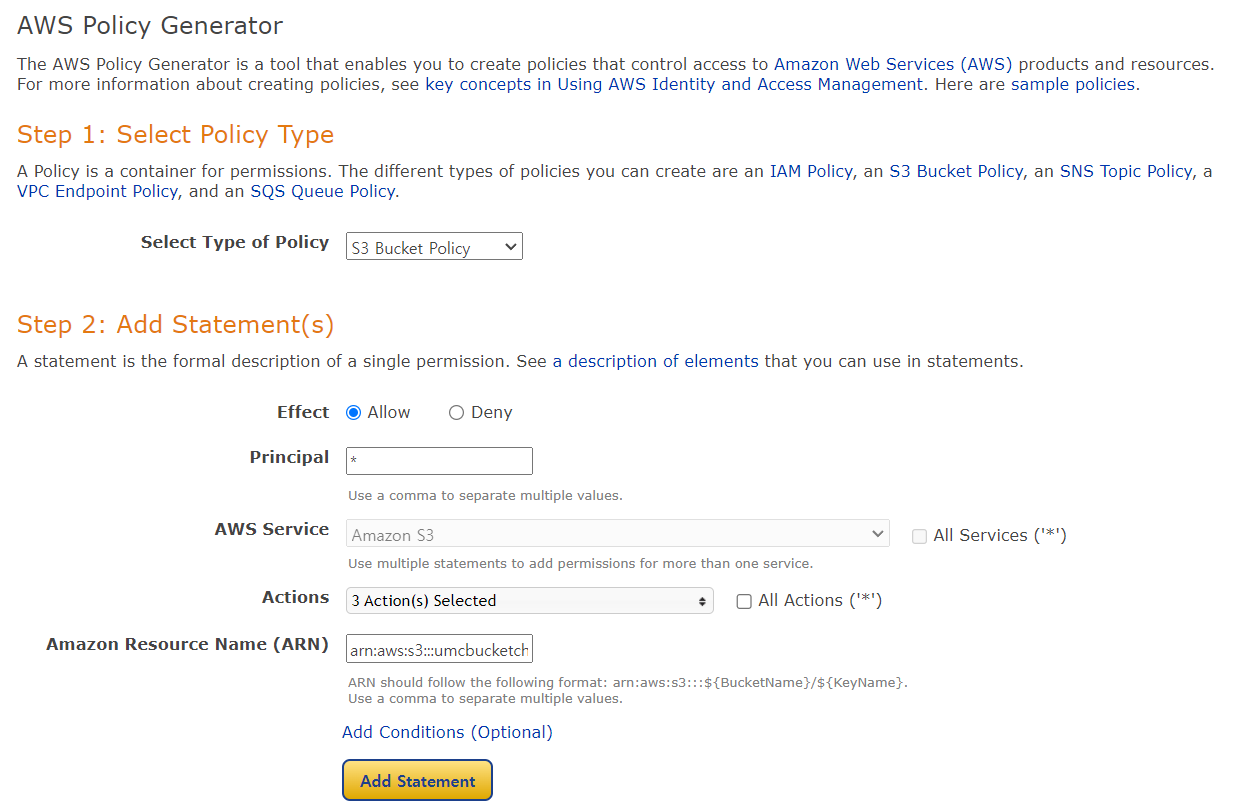
② 아래와 같이 설정한다.
- Select Type of Policy: S3 Bucket Policy
- Effect: Allow (접근하는 모든 사람을 허용)
- Principal: * (모두에게 접근 권한 부여)
- Actions: GetObject, PutObject, DeleteObject (사진 조회, 업로드, 삭제)
- ARN: arn:aws:s3:::내 버킷 이름
③ Add Statement를 누르고 Generate Policy를 클릭하면 아래와 같은 창이 뜨는데, 이 내용을 복사해주자.
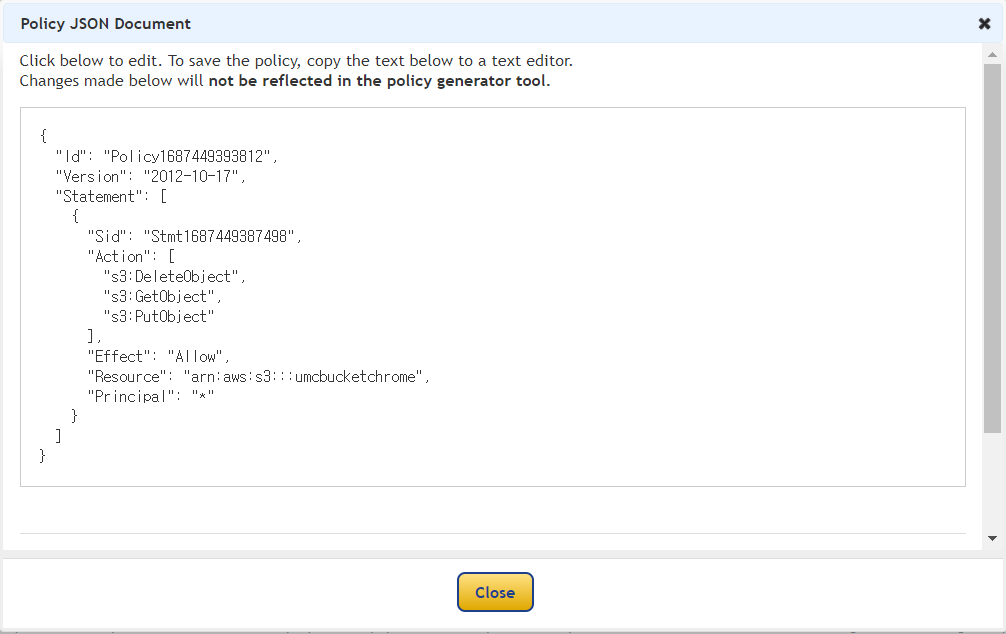
④ 버킷 정책에 붙여넣으면 된다.
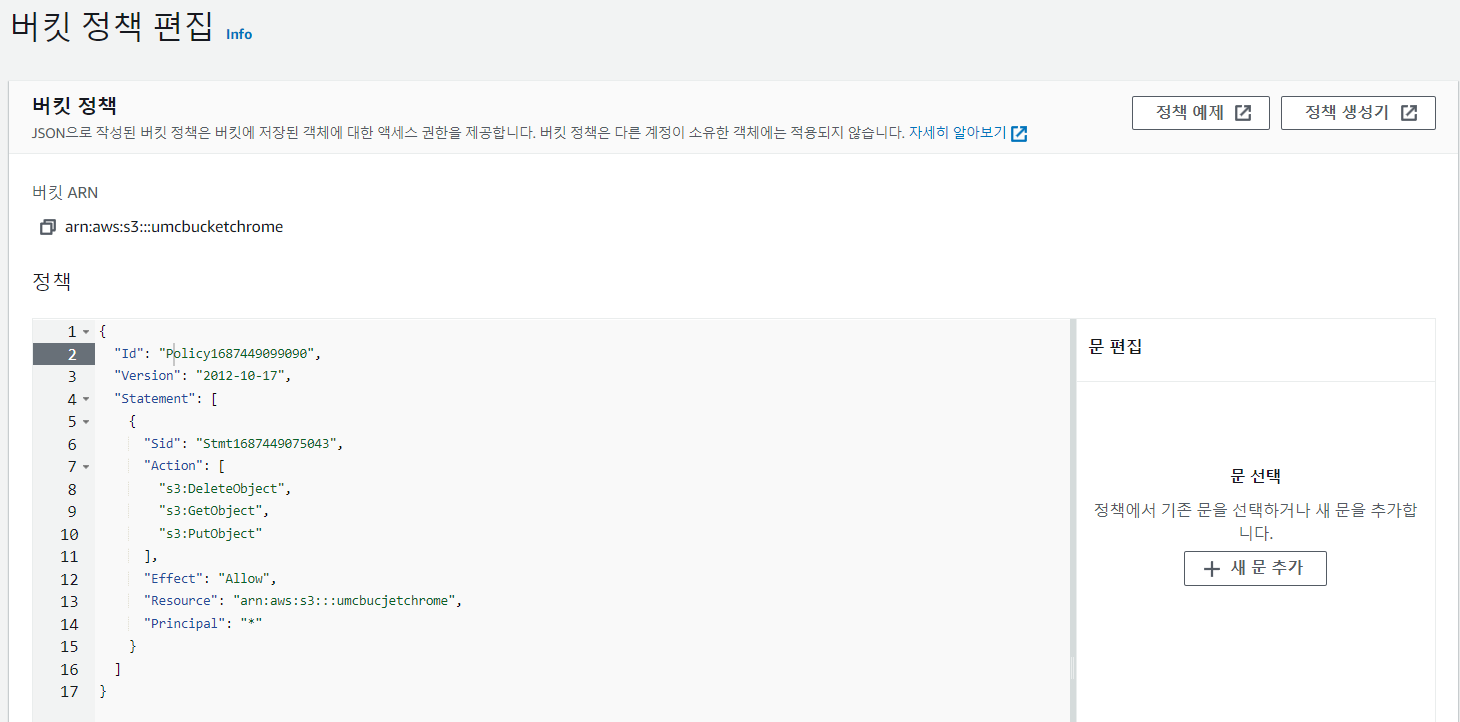
⑤ 하지만 접근할 수 있는 resource의 경로를 지정해주지 않아 에러가 발생한다.
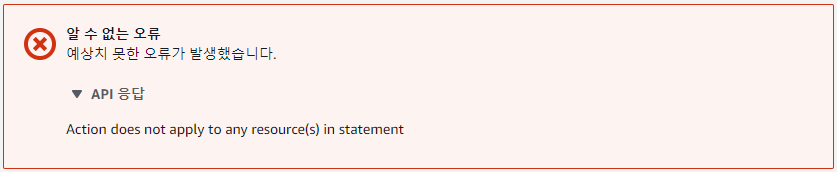
⑥ 해결방법은 생각보다 간단하다. 정책에서, Resource 속성 값의 맨 뒤에 /*을 달아주면 된다. 만약, 특정 폴더에만 접근하게 하고 싶다면 /폴더이름을 써도 된다.
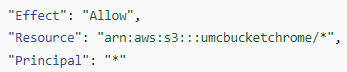
⑦ 다시 변경 사항을 저장하니 이번에는 잘 저장되었다. 시간이 지나면 아래와 같이 퍼블릭 액세스가 가능하다고 변경되어 있을 것이다.

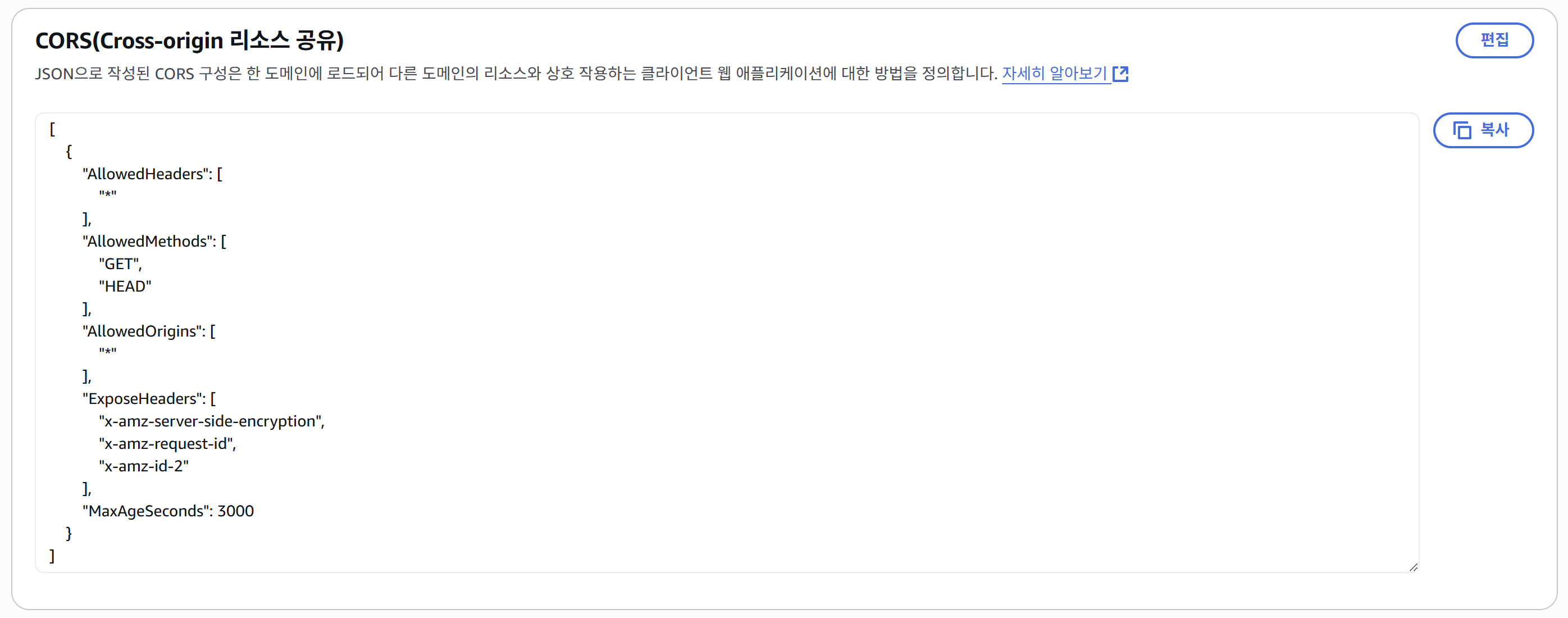
⑧ CORS 문제 해결이 필요할 경우, 권한 > CORS(Cross-origin 리소스 공유)에 아래의 내용을 입력하면 된다.
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"HEAD"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": [
"x-amz-server-side-encryption",
"x-amz-request-id",
"x-amz-id-2"
],
"MaxAgeSeconds": 3000
}
]
3) Spring Boot 환경설정
① spring-cloud-starter-aws 라이브러리를 build.gradle에 추가하고 refresh 해주자.
implementation 'org.springframework.cloud:spring-cloud-starter-aws:2.2.6.RELEASE'② build.gradle에서 추가한 의존성을 제대로 인식하지 못해 에러가 발생하는 경우에는 아래와 같이 대처한다.
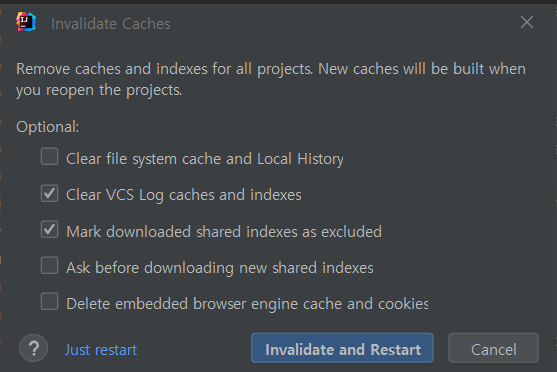
- File > Invalidate caches > Clear VCS Log caches and indexes, Mark downloaded shared indexes as excluded를 체크한 후 Invalidate and Restart를 눌러주면 된다.
③ application.yml 파일에도 아래의 내용을 추가해주어야 한다.
spring:
servlet:
multipart:
max-request-size: 30MB
max-file-size: 30MB
cloud:
aws:
s3:
bucket: umcbucketchrome
region:
static: ap-northeast-2
stack:
auto: false지금까지는 기본적인 설정만 한 것일뿐 S3와 Spring Boot가 연동된 것은 아니다. 다음 포스팅에선 S3와 Spring Boot를 연동시키는 방법에 대해 배워보기로 하자.
