아래 깃허브에 있는 파일은 JPA를 학습하기 위해 제작한 Template 코드입니다. JPA를 제대로 배우려면 매우 넓은 범위를 다루어야 하는데, 이것이 현실적으로 쉽지 않기 때문에 이 코드에 대해 해석해보는 과정을 통해 JPA에 대해 학습해보기로 하겠습니다.
>> JPA_TEMPLATE 깃허브 링크
1. Controller, Repository, Service의 역할 및 관계
1) Controller
Controller는 스프링 애플리케이션에서 사용자 요청을 처리하는 컴포넌트이다. 웹 애플리케이션의 요청을 받아 해당 요청에 대한 처리를 수행하고, 그 결과를 사용자에게 반환한다. 주로 사용자와의 상호작용을 담당하며, 일반적으로 사용자 요청을 처리하기 위해 Service 계층의 메서드를 호출한다.
2) Repository
Repository는 데이터베이스나 다른 영속 저장소에 접근하는 계층이다. 데이터의 영속성을 관리하고, 데이터베이스와의 상호작용을 추상화하여 개발자가 데이터에 접근하고 조작할 수 있는 인터페이스를 제공한다.
주로 데이터베이스에 데이터를 저장하거나 조회하는 등의 작업을 수행한다. Repository는 일반적으로 데이터베이스 ORM(Object-Relational Mapping) 기술을 사용하여 데이터베이스와의 상호작용을 캡슐화한다.
※ 데이터 영속성
데이터가 생성된 후에도 지속적으로 유지되는 특성이다. 일반적으로 데이터는 메모리(RAM)에 저장되어 있는 동안에만 유지된다. 그러므로 애플리케이션이 종료되거나, 시스템이 재부팅되면 메모리에 저장된 데이터는 사라진다.
이러한 데이터의 비영속성은 대부분의 애플리케이션에 있어 문제가 될 수 있다. 예를 들어, 온라인 상점에서 주문 정보를 영속적으로 저장하지 않으면, 애플리케이션이 재시작될 때 이전의 주문 내역을 파악할 수 없게 된다.
데이터의 영속성을 확보하기 위해서는 데이터를 영구적으로 저장하는 영속 저장소(Persistent Storage)를 사용해야 한다. 일반적으로 데이터베이스가 가장 일반적인 영속 저장소이다. 데이터베이스는 디스크에 데이터를 저장하고, 필요할 때에 읽고 쓸 수 있으며, 데이터의 지속성을 보장한다.
데이터베이스는 다양한 형태로 존재할 수 있다. 예를 들어 관계형 데이터베이스(RDBMS)인 MySQL, PostgreSQL, Oracle 또는, NoSQL 데이터베이스인 MongoDB, Cassandra 등이 있다.
3) Service
Service는 비즈니스 로직을 처리하는 계층이다. 비즈니스 요구 사항을 구현하고 도메인 객체들 간의 상호작용을 조정한다. Repository로부터 데이터를 가져와 가공하거나 다른 Service를 호출하여 작업을 수행한다.
주로 복잡한 비즈니스 규칙을 처리하고, 데이터의 일관성과 유효성을 유지하기 위한 작업을 수행한다. Controller 계층과 Repository 계층 사이에서 중재자 역할을 수행한다.
2. Member 클래스
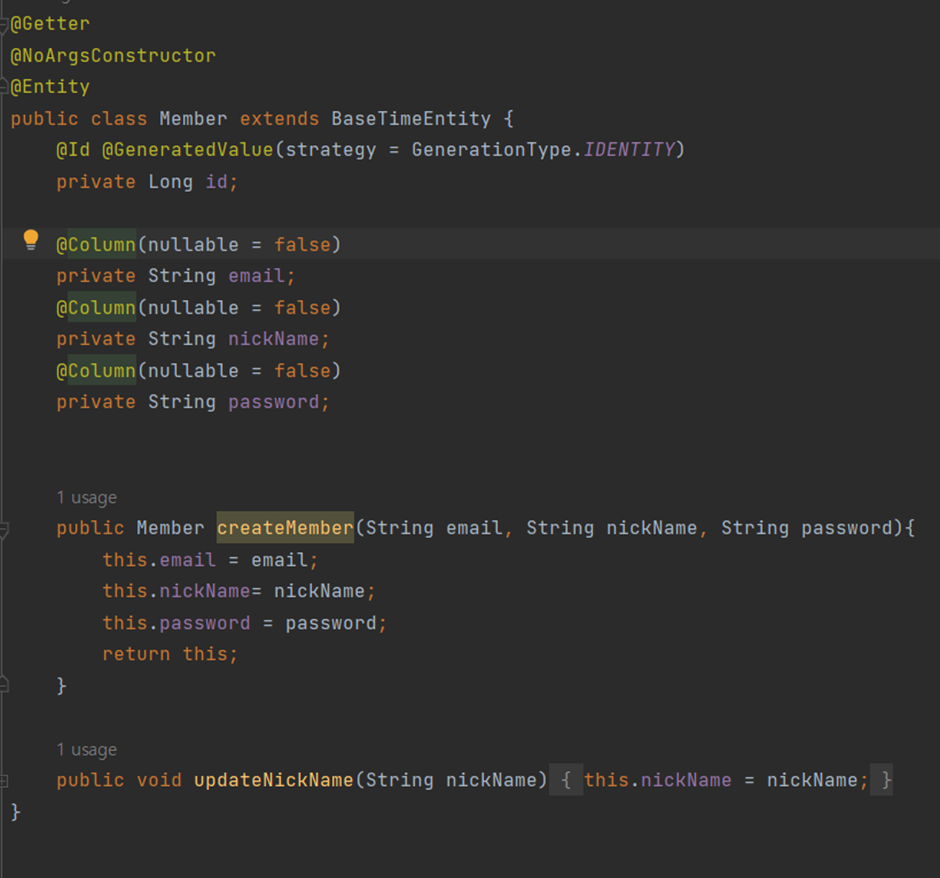
1) 선언 전 어노테이션
① @Getter
- 해당 클래스의 필드값을 가져오는 함수이다. 즉, 직접 getEmail(), getNickName(), getPassword()를 정의하지 않고도 바로 사용할 수 있다.
- 이 때 메서드명은 Camel Case로 표기해야 한다.
- 예를 들어 필드명이 email이라면 getter를 사용할 때에는 getEmail() 처럼 표기해야 한다.
② @NoArgsConstructor
- 입력값이 없는 생성자로, 쉽게 말해 디폴트 생성자이다.
- 마찬가지로, 생성자를 직접 정의하지 않고 바로 사용할 수 있게 해준다.
③ @Entity
- 데이터베이스의 테이블과 매핑되는 자바 클래스(객체)를 의미한다.
- 이 어노테이션이 사용된 객체는 JPA에서 관리하는 엔티티로 간주된다.
- @Entity가 붙은 객체에는 기본생성자가 반드시 정의되어 있어야 한다.
- 이것이 위에 @NoArgsConstructor를 사용한 이유이다.
2) Extend BaseTimeEntity
알다시피 extends는 추상클래스 또는 인터페이스를 구현한 구체 클래스에 붙이는 키워드이다. 즉, BaseTimeEntity를 구현한 구체클래스라는 뜻인데, 여기서 BaseTimeEntity란 생성/수정시간을 자동으로 설정해주는 클래스로 아래와 같이 정의되어 있다.
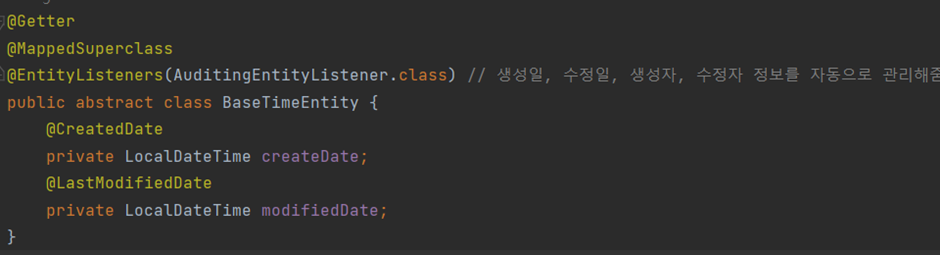
① @Getter
- creatDate와 modifiedDate 값을 가져오기 위해 사용되었다.
② @MappedSuperclass
- JPA Entity 클래스가 BaseTimeEntity를 상속받는 경우 createdDate, modifiedDate 두 필드도 컬럼으로 갖도록 자동으로 설정한다.
③ @EntityListeners(AuditingEntityListener.class)
- 엔티티 클래스의 변경이벤트를 감지하고 처리하는 용도로 사용된다.
- AuditingEntityListener는 JPA에서 제공하는 Entity Listener의 일종으로, 주로 생성일자와 수정일자를 자동으로 관리하기 위해 사용한다.
- 즉 이 어노테이션은 엔티티의 생성 및 수정시간을 자동으로 갱신하는 역할을 수행한다.
④ abstract class
- 상속을 위한 클래스이므로, abstract class로 정의한다.
※ 인터페이스 대신 추상 클래스를 사용한 이유
인터페이스와 달리 추상클래스는 메서드를 정의할 수 있기에 @Getter를 사용할 수 있다. (인터페이스였다면 자손 클래스에서 매번 getter를 정의해야 했을 것이다.)
또한 인터페이스에는 변수를 사용할 수 없고 그저 상수만 사용 가능하다.
이외에도 인터페이스는 자손 클래스에서 함수의 구현을 강제한다는 차이점도 있으나 위의 경우와는 무관하다. 이러한 이유로 인터페이스가 아닌 추상 클래스로 BaseTimeEntity를 정의한다.
⑤ LocalDateTime
- BaseTimeEntity의 createDate와 modifiedDate의 자료형은 Date를 써도 되지만, LocalDateTime을 사용할 것을 권장한다.
- 이유를 간단히만 말하자면 LocalDateTime이 더욱 최근에 추가된 기능이기 때문이다.
⑥ @CreateDate, @LastModifiedDate
- 생성과 수정시의 날짜를 자동 갱신하는 역할을 수행한다.
⑦ JPA Auditing 활성화
- 결과적으로 Member테이블의 컬럼에 생성날짜와 수정날짜가 자동으로 추가된다.
- Application 파일에 @EnableJpaAuditing 어노테이션을 추가해야 JPA Auditing이 활성화된다.

3) @Id
해당 컬럼을 기본키로 설정한다는 의미이다. 특히 @Id는 @GeneratedValue와 함께 쓰이는 경우가 많은데, 기본키를 자동으로 생성하는 전략 중 일반적으로 가장 많이 이용되는 전략은 GenerationType.IDENTITY이다.
이 전략은 쉽게 말해 id값을 따로 할당하지 않아도 데이터베이스가 자동으로 AUTO_INCREMENT하여 기본키를 생성해준다.
4) @Column
객체의 필드를 테이블의 컬럼에 매핑하는 역할을 수행한다. 속성 값에는 name과 nullable이 주로 사용된다. name을 지정하지 않으면 필드명 그대로 name이 되므로 생략하는 경우가 많다.
다만, nullable의 경우 default로 true 값을 갖기 때문에 필수 입력 필드에 대해서는 반드시 nullable을 false로 지정해주어야 한다.
5) 메서드
createMember함수는 입력값을 바탕으로 Member 객체를 반환하는 함수이고, updateNickname 함수는 닉네임을 변경하는 함수이다.
3. MemberController "create" 요청
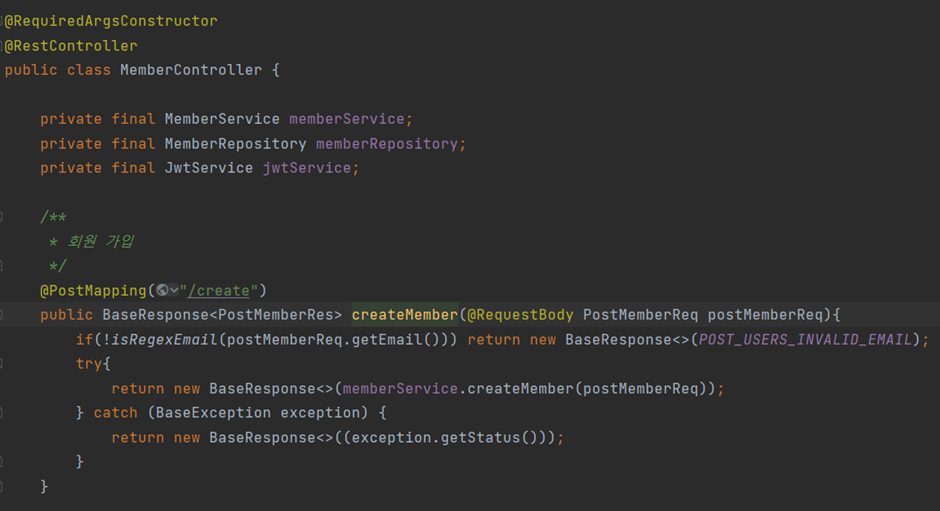
1) 선언 전 어노테이션
① @RequiredArgsConstructor
- final 또는 @NotNull이 붙은 필드(주입 받은 객체가 변하지 않는다는 보장이 있어야 함)의 생성자를 만들어준다.
- 이는 의존성주입 중 생성자 주입 방식에 해당한다.
- @RequiredArgsConstructor를 사용하지 않았다면 아래와 같이 코드를 짰어야 했다.
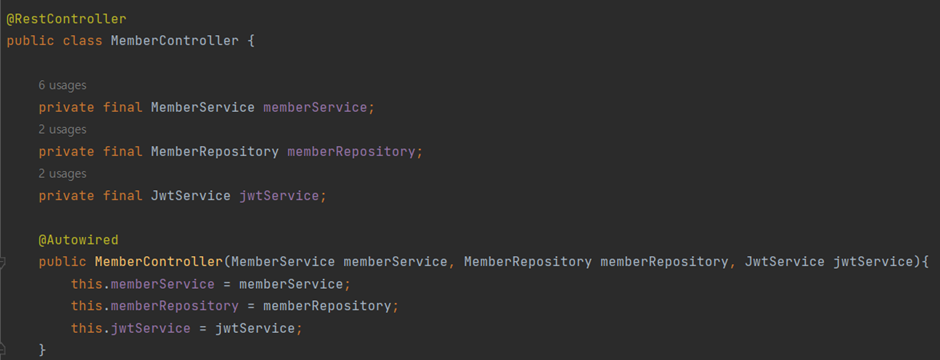
② @RestController
- @Controller와 @ResponseBody의 합성 어노테이션으로 JSON방식으로 객체 데이터를 반환하기 위해 사용된다.
- 데이터를 응답으로 제공하는 REST API를 개발할 때 주로 사용되며, 객체를 ResponseEntity로 감싸서 반환한다.
- @Controller는 주로 View를 반환하기 위해 사용된다는 점에서 차이가 있다.
2) final 필드
컨트롤러에서 사용할 필드를 선언하고 @RequiredArgsConstructor를 이용해 의존객체를 생성자를 통해 주입한다. 반드시 final로 선언해야 한다. 이는 객체의 불변성을 확보하기 위함이다.
3) @PostMapping
HTTP메서드 중 Post에 해당하는 요청에 사용되는 어노테이션이다. 주어진 URI표현식과 일치하는 HTTP POST 요청을 처리한다.
4) BaseResponse
BaseResponse란 일반적으로 API 응답을 표현하는 데 사용되는 기본 응답 모델이다. 말그대로 API 요청에 대한 결과를 반환하기 위해 사용되며 형태는 JSON 형식을 따른다.
BaseResponse는 일반적으로 status, message, data 필드로 구성된다. status는 success여부를 나타내고, message는 응답과 관련한 설명 즉, 클라이언트가 요구사항을 이해할 수 있도록 돕는 메시지를 나타낸다. data는 실제 응답 데이터로, 요청에 대한 처리 결과이다.
정리하자면, BaseResponse는 오류의 내용이나 상태코드를 클라이언트가 이해하기 쉬운 방식으로 제공하는 역할을 수행한다. 여기서 사용된 BaseResponse는 아래와 같이 정의되었다.
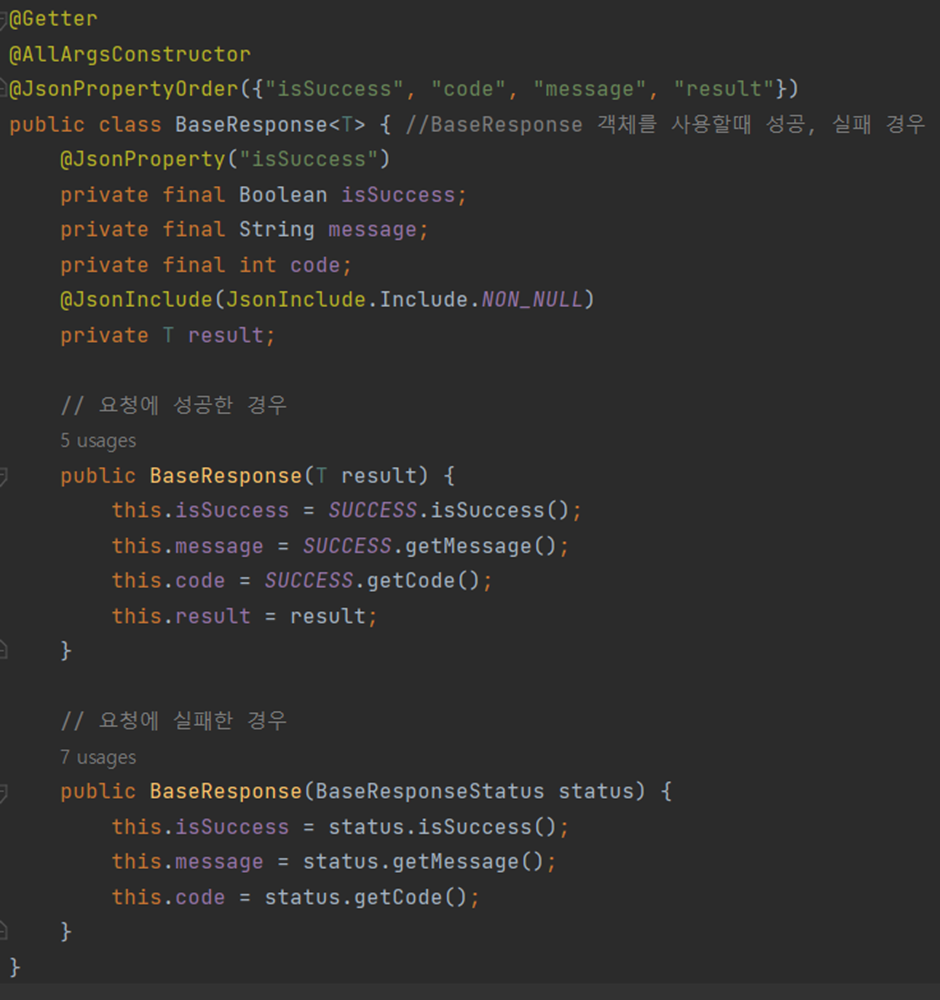
① @JsonPropertyOrder
- Jackson 라이브러리에서 제공하는 어노테이션으로, JSON 직렬화를 위한 필드의 순서를 정의하는 어노테이션이다.
※ JSON 직렬화
객체를 JSON 형식으로 변환하는 과정으로 이해하면 된다. 객체는 메모리에 존재하는 데이터 구조인 반면, JSON은 텍스트이다. 즉, 객체를 JSON으로 직렬화하여 데이터를 보다 효율적으로 관리하고 전송할 수 있게 되는 것이다. - 서버는 객체를 JSON으로 직렬화하여 클라이언트에게 응답으로 제공하고, 클라이언트는 JSON을 객체로 변환하여 사용하게 된다. 이 때, JSON이 생성되는 형식은 isSuccess, code, message, result의 순서의 key-value쌍이 된다.
- 아래에 선언된 필드를 보면, isSuccess, message, code, result순으로 적혀있으나 결과 값이 출력될 때에는 직렬화의 순서에 따라 출력된다. 즉, isSuccess, code, message, result 순으로 출력된다.
② @JsonPropoerty
- JSON의 key형식과 클래스의 필드명이 맞지 않을 때, 매핑을 위해 사용하는 어노테이션이다.
- JSON에서는 언더바를 사용하는 snake_case를 선호하는 반면, 자바에서는 camelCase를 선호하다보니 둘이 맞지 않는 경우가 종종 발생할 수 있다.
- 위 예시의 JSON에서 isSuccess가 아닌 is_success였다면 이 어노테이션을 반드시 사용해야 한다.
- 위 예시에서는 JSON에서도 동일하게 카멜 케이스를 적용하고 있으므로 굳이 붙이지 않아도 상관은 없으나 명시적인 코드 작성을 위해 사용하였다.
③ @JsonInclude
- JSON 타입의 데이터에서 특정 필드만 포함하고 싶을 때 사용하는 어노테이션으로 위에서는 NON_NULL을 include하고 있다.
- 이는 JSON을 직렬화 할 때 null 값을 갖는 필드는 결과에서 제외한다는 의미이다.
④ T
- generics로 BaseResponse의 타입이다.
⑤ BaseResponse 생성자 오버로딩
- 두가지 생성자는 각각 요청에 성공한 경우를 위한 생성자와 요청에 실패한 경우를 위한 생성자이다.
- SUCCESS는 BaseResponseStatus라는 enum class의 타입이다. BaseResponseStatus는 isSuccess와 code, message를 필드로 갖는다.
- 참고로 enum은 상수클래스이므로 필드에 final 키워드를 사용할 것을 권장한다.
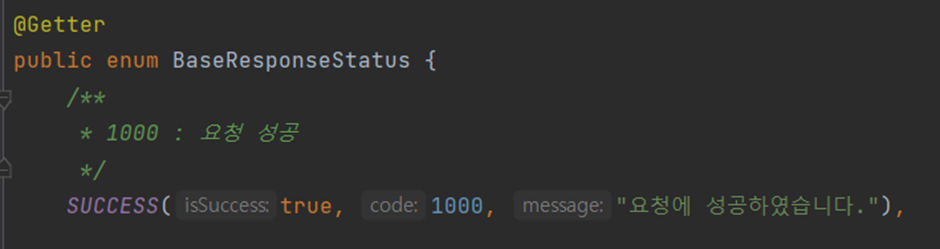
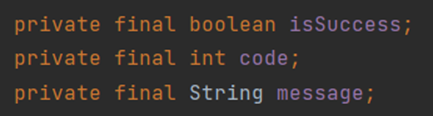
- SUCCESS는 생성자로써(생성자가 호출되므로) 입력 파라미터의 값으로 필드 값을 설정한다.
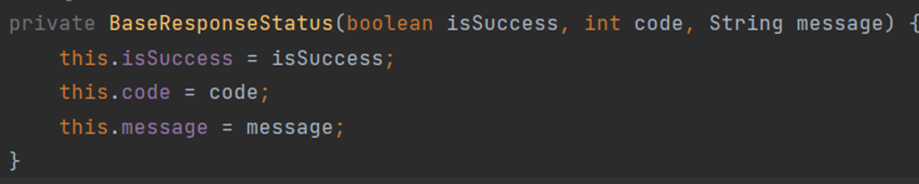
- 즉, 요청에 성공한 경우에 SUCCESS 생성자의 필드 값을 가져와 BaseResponse의 필드에 입력한다는 것이다.
- 요청에 성공한 경우와 실패한 경우 이름은 같지만 완전히 다른 생성자가 불리는데, 이를 생성자 오버로딩이라 한다.
- 즉, 아래와 같이 BaseResponse 생성자에 result 값을 인자로 넣어주면 성공이고, BaseResponse 생성자에 exception을 인자로 넣어주면 실패이다.

- 요청에 실패한 BaseReponse 생성자에 입력되는 값은 BaseException 클래스의 객체인 exception의 상태(status)이다. BaseException클래스는 아래와 같이 정의되었다.
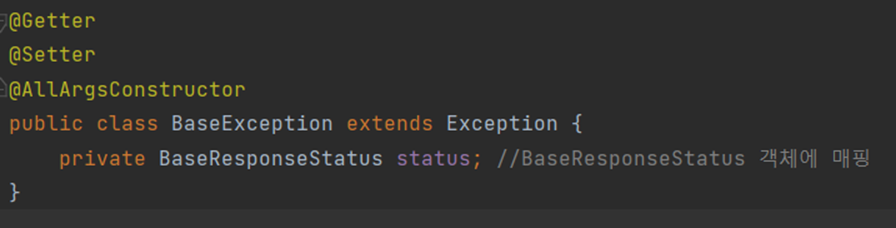
- status를 필드로 갖고, 이에 대한 생성자와 set, get함수를 가지고 있다.
- 참고로 extends Exception은 예외 클래스를 작성할 때 반드시 포함해주어야 한다. 간혹 RuntimeException을 extends하는 경우도 있는데, 위와 같이 강제적인 예외처리가 필요할 때(예외처리 없이는 컴파일이 안 되는 경우)에는 Exception 클래스를 확장한다.
- 즉, BaseException 클래스의 객체를 통해 getStatus() 메서드를 호출하고 있는 것이다.
- 이 status 객체가 무엇을 가리키는지는 상황에 따라 다르다. 어떠한 상황에서 예외가 발생했느냐에 따라 유동적으로 예외를 처리하는 로직이기 때문이다.
- 간단히 예를 들어보자. MemberController에는 아래의 내용이 포함되어 있다.

- 위 예시에서는 구체적으로 어떠한 예외 사항인지가 명시되어 있다. 아직 isRegexEmail메서드에 대해서 설명하진 않았지만, 대충 입력 받은 이메일이 이메일의 정규표현식과 일치하는지를 검사하는 메서드 정도로 생각하면 된다. 이 검사를 통과하지 못했다는 것은 invalid한 이메일을 입력했다는 것이고, 이에 따라 POST_USERS_INVALID_EMAIL을 status 값으로 전달한다.
- 이에 따라 BaseResponseStaus의 POST_USERS_INVALID_EMAIL 생성자가 호출된다.

- 즉, 요청에 실패했을 때 사용하기 위해 오버로딩 한 생성자에서 위 값을 본인의 필드에 할당해 클라이언트에게 반환하는 것이다.
- 이외에도 다양한 예외 상황에 맞는 코드와 에러 메시지가 클라이언트에게 전달될 수 있다.
5) PostMemberRes
BaseResponse의 generics로 사용되고 있는 PostMemberRes는 아래와 같이 정의되었다.
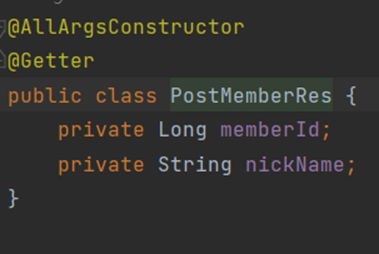
참고로 Res는 Response라는 뜻으로, 응답에 사용되는 DTO를 정의한다. 즉, BaseResponse의 result 값으로 들어가는 createMember의 반환 값이 memberId와 nickName이란 뜻이다.
6) @RequestBody
이 어노테이션이 붙은 파라미터로 http 요청의 본문(body)이 그대로 전달된다는 의미이다. 주로 Post에서 JSON 기반의 메시지를 요청할 때 사용되는 어노테이션이다. 이 어노테이션은 PostMemberReq에 붙었는데, 참고로 여기서의 Req는 request를 의미한다. PostMemberReq는 아래와 같이 정의되었다.
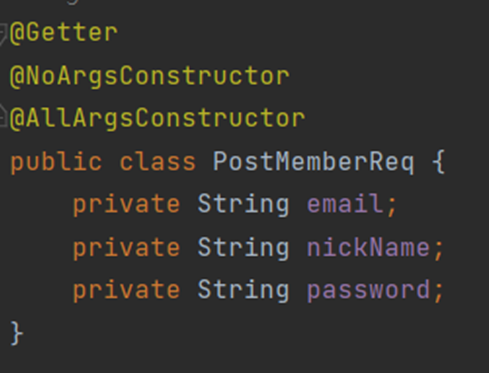
즉, 클라이언트로부터 http body에 JSON 타입으로 입력 받은 email과 nickname, password를 createMember 메서드의 인자로 전달하겠다는 의미이다.
7) if(!isRegexEmail())
이전에 잠깐 설명했듯, 이메일이 정규표현식을 만족하는지 검사하는 메서드이다. 특이한 점이라면 객체 호출 없이 사용하고 있다는 것이다. 일반적으로 메서드를 사용할 때에는 메서드를 정의한 클래스로 찍어낸 객체가 있어야 하고, 객체의 닷 오퍼레이터를 붙여 메서드를 호출한다. 객체 없이 호출이 가능한 이유는 isRegexEmail 클래스가 static으로 정의되었기 때문이다.
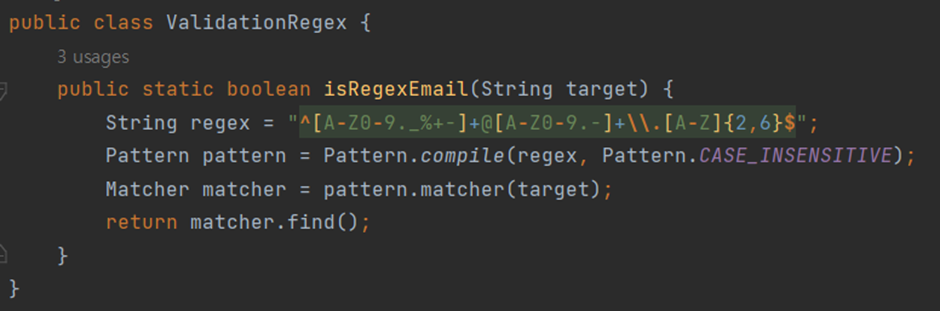
위 코드를 해석하자면 아래와 같다.
① target, regex
- String 타입의 target은 검사할 이메일을 의미한다.
- String 타입의 regex는 이메일의 정규표현식 패턴을 문자열로 저장하고 있다.
- 참고로 regex는 regular expression이라는 뜻이다.
② Pattern 객체
- Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE)은 정규표현식 패턴을 컴파일하여 Pattern 객체를 생성한다.
- Pattern.CASE_INSENSITIVE 플래그를 사용하여 대소문자를 무시하도록 설정한다.
③ Matcher 객체
- Matcher matcher = pattern.matcher(target)은 주어진 이메일 주소(target)와 패턴을 비교하는 Matcher 객체를 생성한다.
④ return matcher.find()
- Matcher 객체의 find() 메서드를 호출하여 주어진 이메일 주소에서 패턴과 일치하는 부분을 찾는다.
- 일치하는 부분을 찾으면 true를 반환하고, 일치하는 부분을 찾지 못하면 false를 반환한다.
⑤ ^[A-Z0-9._%+-]+
- 이메일 주소의 로컬 파트(local part)를 나타내며, 대문자(A-Z), 숫자(0-9), 특수 문자(._%+-)로 이루어진 문자열이다.
⑥ @
- 이메일 주소의 도메인 구분 기호이다.
⑦ [A-Z0-9.-]+
- 이메일 주소의 도메인 파트(domain part)를 나타내며, 대문자(A-Z), 숫자(0-9), 특수 문자(-.)로 이루어진 문자열이다.
⑧ \.
- 이메일 주소의 도메인 파트와 최상위 도메인(top-level domain) 사이의 점(.)을 나타낸다.
⑨ [A-Z]{2,6}
- 이메일 주소의 최상위 도메인을 나타내며, 대문자(A-Z)로 이루어진 2~6글자의 문자열입니다.
대충 이런 의미인데, 이것을 정확히 알 필요는 없고, 필요할 때마다 이 형태를 그대로 유지하여 사용하면 된다. 그리고 위에서 설명한 바 있듯 이러한 상황에서는 POST_USERS_INVALID_EMAIL이라는 생성자가 호출되어 이에 해당하는 isSuccess와 code, 메시지가 클라이언트에게 전송될 것이다.
참고로 컴파일러가 제네릭스를 추정 가능한 경우 위와 같이 생략할 수도 있다. 컴파일러가 제네릭스를 추정 가능하다는 것은 곧 이전에 사용된 제네릭스를 그대로 유지한다는 의미이다.
