데이터베이스
- 데이터베이스를 사용하는 이유
- 데이터베이스 이전에는 파일 시스템 이용 -> 데이터 종속성, 중복성, 무결성의 문제
- 파일 시스템은 데이터를 파일 단위로 저장하고 독립적 애플리케이션과 연동되어 데이터 처리
- 데이터 독립성 : 데이터베이스의 물리적 크기의 변화에도 응용프로그램을 수정할 필요가 없고 데이터베이스의 논리적 구조로 여러 응용프로그램의 논리적 요구를 만족시킬 수 있다
- 데이터 무결성 : 잘못된 데이터가 발생하는 경우 방지
- 유효성 검사를 통해 무결성 구현
- 데이터 보안성 : 인가된 데이터베이스와 자원에 접근
- 계정 관리, 접근 권한 설정
- 데이터 일관성 : 연관된 구조를 논리적인 구조로 관리하는 데이터베이스 -> 어떤 하나의 데이터만 변경했을 경우 발생할 수 있는 데이터의 불일치성 배제
- 작업 중 일부 데이터만 변경되어 나머지 데이터와 일치하지 않는 경우 방지
- 데이터 중복 최소화 : 데이터베이스는 데이터를 통합 관리 -> 중복성 배재 (파일 시스템의 단점)
- 데이터베이스 이전에는 파일 시스템 이용 -> 데이터 종속성, 중복성, 무결성의 문제
- 데이터베이스 성능
📍 디스크 I/O를 어떻게 줄이느냐- 💡 디스크 I/O : 디스크 드라이브의 플래터(원판)을 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 후 다음 데이터를 읽는 것
- 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한번에 기록하느냐에 따라 결정
- 따라서 순차 I/O 가 랜덤 I/O 보다 빠름
- 하지만 대부분 랜덤 I/O 작업이기 때문에 랜덤 I/O 줄어야 함
- 데이터베이스 쿼리 튜닝
인덱스
- 인덱스?
- 인덱스의 자료구조
- primary index VS secondary index
- composite index
- 인덱스의 성능과 고려해야할 사항
정규화
- 정규화?
- 관계형 데이터베이스에서 중복 최소화를 위해 데이터를 구조화하는 작업
- 정규형(조건을 만족하는 스키마의 형태)을 만족하도록 릴레이션 분해
- 💡 나쁜 릴레이션이란?
- 정규형에 따른 함수의 종속성을 만족 시키지 못하는 릴레이션
- 함수적 종속성 : 정규화 과정에서 고려해야하는 속성들 간의 관련성
- X의 값이 Y의 값을 유일하게 결정하면 X는 Y를 함수적으로 결정한다고 함
- 일반적으로 릴레이션에 함수적 종속성이 하나 존재하도록 정규화해 분해- 완전 함수 종속 (Fully Functional Dependency) : 속성 집합 Y가 속성 집합 X에 함수적으로 종속되어 있지만 속성 집합 X의 전체가 아닌 일부분에는 종속되지 않음
- ex. 고객아이디 -> 고객이름 / [고객아이디, 이벤트 번호] -> 당첨여부
당첨여부가 [고객아이디, 이벤트 번호]에 종속되어 있는데 일부분이 아닌 속성 집합 전체에 종속되어 있음 : 완전 함수 종속
- 부분 함수 종속 (Partial Functional Dependency) : 속성 집합 Y가 속성 집합 X의 전체가 아닌 일부분에도 함수적으로 종속됨, 결정자가 여러 개의 속성들로 구성되어 있어야 한다
- ex. 고객아이디 -> 고객이름 / [고객아이디, 이벤트 번호] -> 고객이름
고객이름이 [고객아이디, 이벤트 번호]에 종속되어 있는데 [고객아이디, 이벤트 번호]의 일부분인 고객아이디에도 종속 : 부분 함수 종속
- 정규화가 왜 필요한지?
- 데이터 중복 -> 이상 현상 (같은 데이터를 한 릴레이션에서는 변경, 다른 릴레이션에서는 그대로 -> 어떤 것이 정확한 데이터인지 혼동)
- 관련 있는 속성들로만 릴레이션 구성해야함 -> 정규화를 통해
- 📌 이상 현상
- 삽입 이상 : 새 데이터를 삽입하기 위해 불필요한 데이터도 함께 삽입하는 문제
- 갱신 이상 : 중복 튜플 중 일부만 변경하여 데이터가 불일치하게 되는 모순의 문제
- 삭제 이상 : 튜플을 삭제하면 꼭 필요한 데이터까지 함께 삭제되는 데이터 손실의 문제
- 정규화 종류?
- 각각 정규형은 1) 무손실 조인 2) 함수적 종속성을 보장해야한다
- 💡 무손실 조인 : 자연조인하여 데이터 손실 없이 원래 릴레이션으로 복원
- 💡 비부가적 조인 : 조인한 결과에 원래 릴레이션에 없는 데이터가 존재하지 않음
- 정규화의 목표 : 관련이 없는 함수 종속성은 별개의 릴레이션으로 표현하는 것
- 종류 : 정규형 종류
- 정규화의 장단점
- 장점
- 이상 현상에 따른 문제 해결
- 데이터베이스에 데이터 추가 시 그 구조를 변경하지 않아도 (일부만 변경해도) 된다
- 현실 세계의 개념과 관계를 더 효과적으로 표현하는 데이터베이스를 만들 수 있다
- 단점
- 릴레이션 간의 연산이 많아진다. (조인 연산) -> 응답시간 느려짐
- but 이상현상 제거를 통해 중복 속성을 제거하므로써 데이터 용량이 최소화되는 효과도 있음 따라서 경우에 따라 빨라질수도 느려질수도
- 조인이 많은 경우에 성능저하가 일어나면 반정규화(비정규화) 적용
- 릴레이션 간의 연산이 많아진다. (조인 연산) -> 응답시간 느려짐
- 반정규화 (비정규화)
- 정규화된 엔티티, 속성, 관계를 중복 통합, 분리등을 수행하는 데이터모델링 기법
- 시스템 성능 향상, 개발과 운영의 단순화
- 디스크 I/O양이 많아 성능 저하, 테이블간 경로가 멀어 조인으로 인한 성능 저하, 칼럼 계산 시 성능 저하로 인해
- 자주 사용하는 테이블에 엑세스하는 프로세스 수가 많을 때, 항상 일정한 범위만 조회하는 경우
- 대량의 데이터 / 범위를 자주 처리하는 경우
- 지나치게 조인을 많이 해야할 때
- 과도한 반정규화 시 무결성 깨질 가능성, 응답시간 늦어짐
트랜잭션
-
트랜잭션?
- 하나의 작업을 수행하기 위해 필요한 데이터베이스의 연산들을 모아놓은 것
- 데이터베이스에서 논리적인 작업의 단위
- 논리적인 작업 셋을 완벽하게 처리하거나 처리하지 못했을 때 원 상태로 복구해서 작업의 일부만 적용되는 현상을 방지
-
트랜잭션의 상태
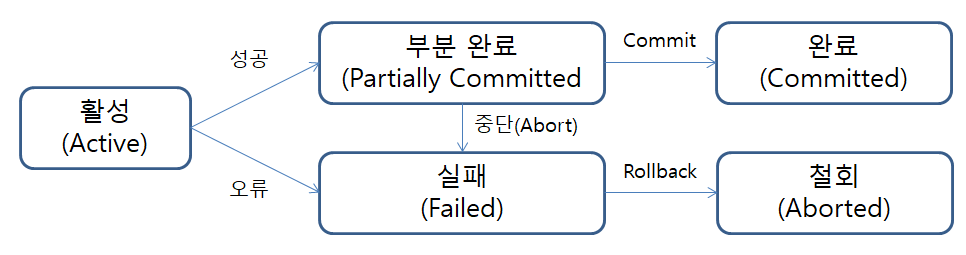
1. 활동 상태
- 트랜잭션이 수행을 시작하여 현재 수행 중인 상태
2. 부분 완료 상태
- 트랜잭션의 마지막 연산이 실행된 직후의 상태
- 모든 연산을 처리한 상태
- 연산은 끝나고 아직 수행한 최종 결과를 데이터베이스에 반영하지 않은 상태
3. 완료 상태
- 트랜잭션이 성공적으로 완료되어 commit 연산을 실행한 상태
- 완료 상태가 되면 최종 결과를 데이터베이스에 반영하고 데이터베이스가 새로운 일관된 상태가 된다
- 그리고 트랜잭션 종료
4. 실패 상태
- 장애가 잘생하여 트랜잭션의 수행이 중단된 상태
- 더는 정상적으로 수행을 계속할 수 없을 때
5. 철회 상태
- 트랜잭션 수행이 실패하여 rollback 연산을 실행한 상태
- 지금까지 실행한 연산 모두 취소하고 트랜잭션이 수행되기 전의 데이터베이스 상태로 되돌림
- 수행됐던 트랜잭션은 다시 수행되거나 폐기-
트랜잭션의 특성 : ACID
- 원자성 (Atomicity)
- 트랜잭션을 구성하는 연산들이 모두 정상적으로 실행되거나 하나도 실행되지 않아야한다. (all or nothing)
- 장애로 인해 작업을 완료하지 못했다면 지금까지 실행한 연산 모두 처리 취소 후 작업 전 상태로 되돌림 (일부만 처리 X)
- 일관성 (Consistency)
- 트랜잭션이 성공적으로 수행된 후에도 데이터베이스가 일관성 있는 상태를 유지해야 함
- 트랜잭션 수행 중 일시적으로 일관되지 않을 수도 있지만 완료 후에는 일관된 상태 유지
- 격리성 (Isolation)
- 트랜잭션 수행 중 완료될 때까지 트랜잭션이 생성한 중간 연산 결과에 다른 트랜잭션들이 접근할 수 없음
- 일반적으로 여러 트랜잭션 동시 수행, 각 트랜잭션은 독립 수행, 트랜잭션들의 중간 연산 결과에 서로 접근 안됨
- 지속성 (Durability)
- 트랜잭션이 성공적으로 완료된 후 데이터베이스에 반영한 수행 결과는 어떠한 경우에도 손실되지 않고 영구적이어야 함
- 장애가 발생하더라도 작업 결과는 데이터베이스에 그대로 남아있어야
- 원자성 (Atomicity)
-
lock : 병행 수행되는 트랜잭션들이 동일한 데이터에 동시에 접근하지 못하도록 lock과 unlock이라는 두 개의 연산을 사용하여 제어하는 것
- 트랜잭션은 데이터 정합성 보장, 락은 동시성 제어
- 공용 lock : read O, write X / 다른 트랜잭션도 같은 데이터에 대해서 공용 lock을 동시에 할 수 있다 (여러 트랜잭션이 사용권을 함께 가짐)
- 전용 lock : read O, write O / 해당 데이터에 대해 다른 트랜잭션이 공용이든 전용이든 lock 못함 (전용 lock한 트랜잭션만 독점권 가짐)
-
트랜잭션 사용 시 주의할 점
- 최소의 코드에만 적용 (범위 최소화)
- 교착상태가 발생할 수 있기 때문에
교착 상태
- 교착상태?
- 교착 상태의 예시
- 교착 상태의 빈도를 낮추는 방법
NoSQL
- NoSQL
- CAP 이론
- 일관성
- 가용성
- 네트워크 분할 허용성
- 저장방식에 따른 분류
- key-value model
- document model
- column model
- RDBMS VS NoSQL
쿼리 속도 및 효율 향상법
로우 레벨 지식
힌트
클러스터링 VS 리플리케이션
데이터베이스 튜닝
출처
https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/Database
https://kjsu0209.github.io/Tech-Interview/database/db
https://sohyunwriter.tistory.com/62
https://mangkyu.tistory.com/93

^^~