요즘 로보틱스에서 가장 핫한 주제는 뭐니뭐니해도 VLA다.
2024 CVPR, 2025 CoRL, ICRA에도 VLA 가 속속들이 등장하고 있다.
그렇다면 우리도 VLA가 뭔지 간단하게라도 알아보자!
VLA?
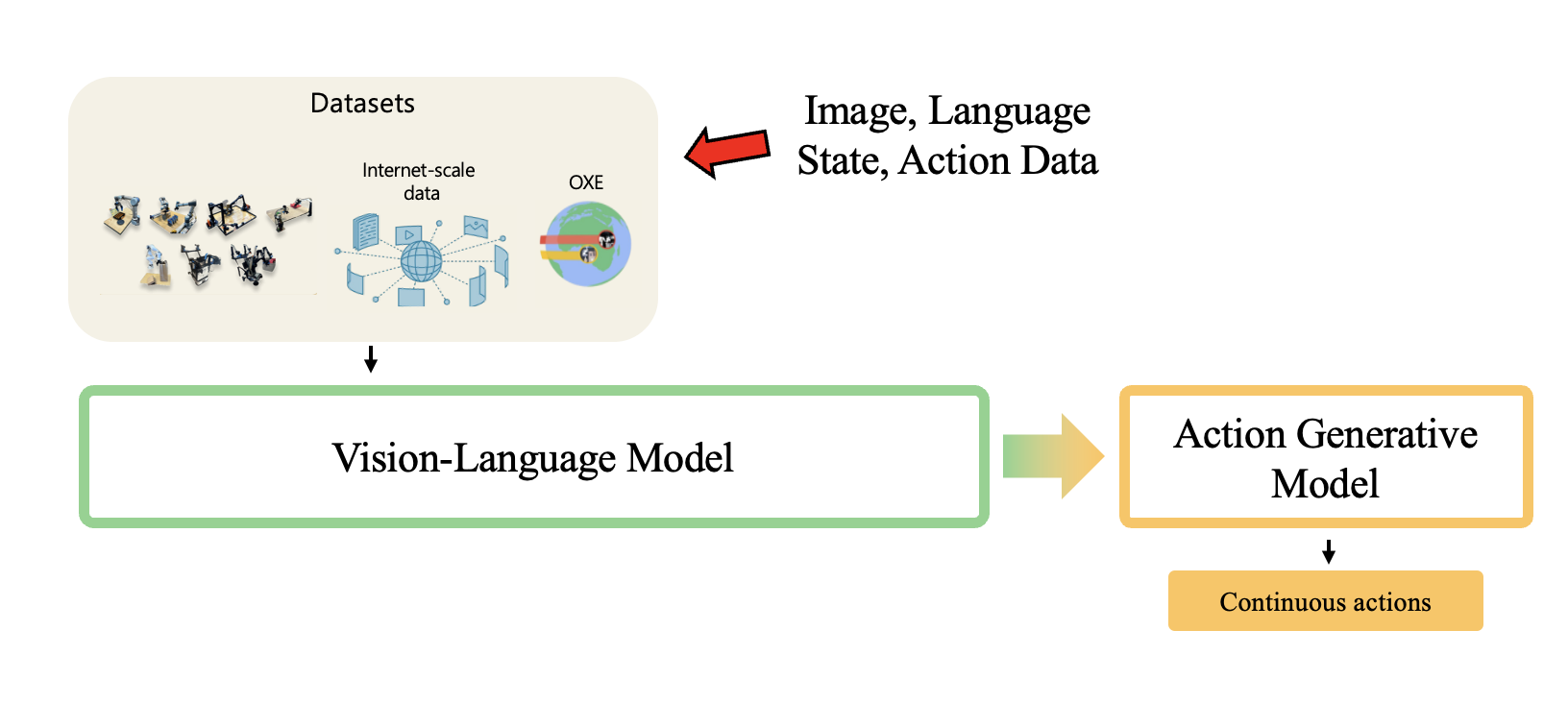
Vision-Language-Action model의 준말인 VLA는 보통 로봇 Manipulation이나, Locomotion에 많이 쓰인다.
여러장의 Image와 그에 맞는 Language 지시사항, 그리고 로봇 State와 Action까지 총 4가지 정보로 Large Foundation model을 학습하는 것이다.
위 설명한 학습과정은 대부분의 모델에서 설명하는 Pre-training 과정으로, LLM에서와 같이 큰 모델을 방대한 양의 데이터로 Pre-training(사전학습) 하는것이다.
Pre-training
주로 이 때 방대한 양의 데이터는 Internet-scale의 데이터로, DROID나 OXE dataset 혹은 더 큰 직접만든 데이터셋들을 사용한다.
Post-training
Supervised Fine-Tuning (SFT)라고도 부르며, Pre-training 이후 각 환경에 맞게 사용자들이 Pre-trained model을 통해 추가로 학습하는 과정을 일컺는다.
많은 논문들이 이 Post-training 과정에서 action을 어떻게 최적화 하는가에 대한 방법론을 제시하는 중이다.(나도)
Baseline
VLA에는 크게 두 가지 action 예측 방법이 있다. (확정은 아님 action을 최적화하는 기법은 각양각색)
- Flow matching
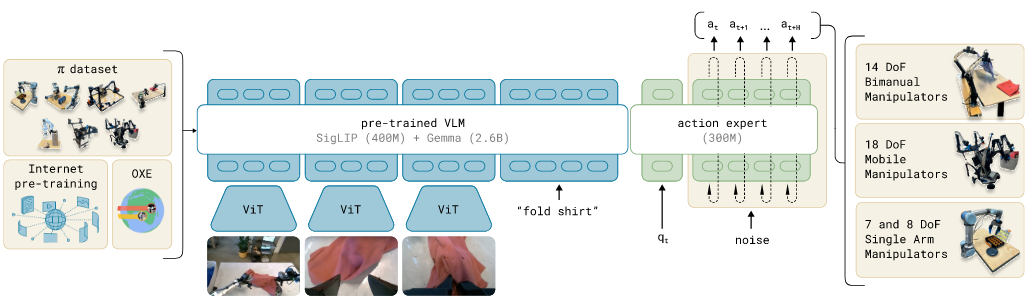
위 그림은 Stanford의 Chelsea Finn 교수를 포함한 여러 교수들이 다같이 만든 Physical Intelligence라는 회사에서 만든 라는 모델이다.
이는 VLA의 가장 큰 이슈를 모은 모델로, SigLIP vision encoder + Transformer 기반 LLM인 Gemma를 합친 PaliGemma 모델을 VLM으로 사용한다.
또한 VLM을 통해 나온 token을 기반으로 Flow matching이라는 생성 모델을 통해 action을 만들어, 빠른 추론속도(Action 생성)를 보인다.
또한 빠른 추론속도를 위해 attention 시에 사용하는 key와 value를 캐싱했다는 특징도 있다.
- Auto Regressive Predict
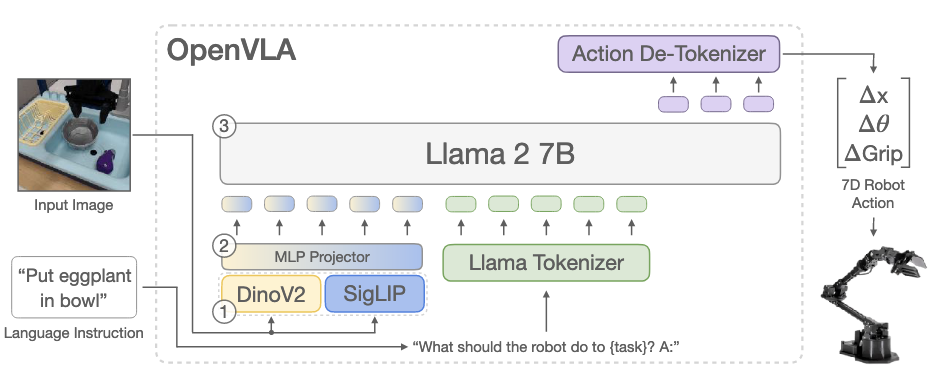
위 그림 역시 Chelsea Finn 교수 연구실에서 만든 OpenVLA라는 모델로, Auto Regressive 한 방식으로 action을 예측한다. 이는 action을 discrete action으로 다루며, LLM의 tokenizer를 이용하여 continuous action을 discrete token화 하고, 이를 통해 다음 액션 chunk(여러 개의 action)를 예측한다.
이
이는 따로 action 생성 모델을 두는 것이 아닌, VLM내에서 예측한 action token을 그대로 detokenizing하여 action을 만든다.
마무리
VLA은 현재 진행형이며, 일주일에도 3-4개의 새로운 모델들이 나오고 있다. 나도 빨리 이 열차에 탑승해야 하는데..
