Logstash

로그를 수집하고 가공해주는 파이프라인 단계를 간편하게 구현해줌
특징
- 플러그인 기반
- 다양한 형태의 데이터 처리 지원
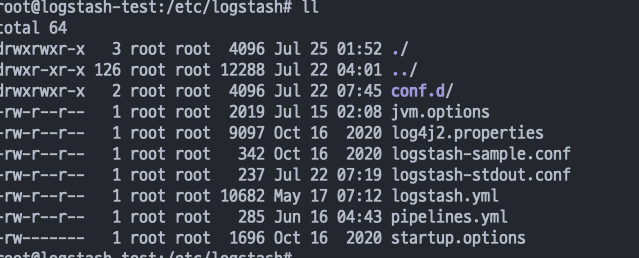
- Input → Filter → Output 단계로 파이프라인 처리
- 내장된 메모리와 파일 기반의 큐를 사용하여 처리 속도와 안정성 높음
설치 및 구성
Docker를 이용해 ELK를 각각 컨테이너로 올려 구성했습니다
파이프라인
# p1.config
input{
}
filter {
}
output {
}- input, filter, output 각 단계에 적절한 플러그인을 사용하여 원하는 형태로 가공하거나 내보내기 가능
- input과 output은 필수적으로 들어가야 하고 filter의 경우 필요한 경우 추가
- pipeline.id: my-pipeline_1
path.config: "/etc/path/to/p1.config"
pipeline.workers: 3
- pipeline.id: dead-letter-queue
path.config: "/etc/different/path/dead-level-queue.conf"
queue.type: persisted- 각 파이프라인의 worker 기본값은 1 (CPU 코어 1개)
- 여러개의 파이프라인을 하나의 인스턴스에서 처리할 때는 적절한 리소스 분배가 필요
queue.type→ disabled default-
Persistent Queue : 인스턴스 내장 디스크에 데이터 저장
- 로그스태시 장애 상황에서 도큐먼트 유실 최소화.
- Redis나 Kafka같은 외부 버퍼링 없이 burst 처리 가능 -
Dead Letter Queue : 실패한 이벤트들을 모아 큐에 저장
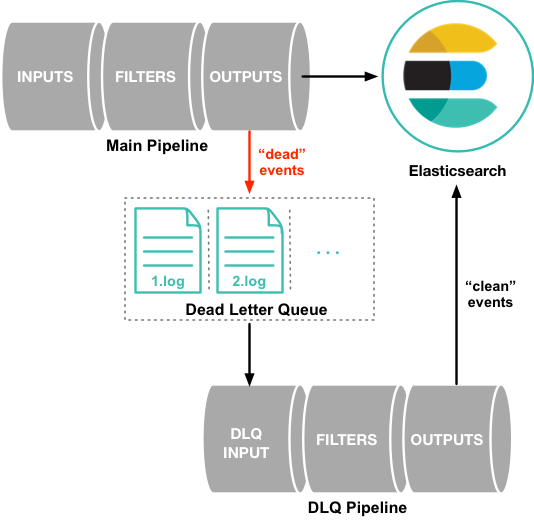
💡 The dead letter queue is currently supported only for the [Elasticsearch output](https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html). The dead letter queue is used for documents with response codes of 400 or 404, both of which indicate an event that cannot be retried.# dead-level-queue.conf input { dead_letter_queue { path => "/path/to/data/dead_letter_queue" commit_offsets => true pipeline_id => "main" } } output { stdout { codec => rubydebug { metadata => true } } }
-
입력 플러그인
- file :
tail -f처럼 파일을 스트리밍하며 읽어옴 - kafka : 카프카 토픽에서 읽어옴
- jdbc : 지정한 일정마다 쿼리를 실행해 결과 읽어옴
- beats : beats로부터 데이터 읽어옴
input {
file {
path => "/path/to/file"
start_position => "beginning"
sincedb_path => "/dev/null"
stat_interval => "1m"
}
kafka {
client_id => "kafka-logstash"
group_id => "kafka-logstash"
topics => ["topic1", "topic2", "topic3"]
codec => json
bootstrap_servers => "kafka1:9092,kafka2:9092,kafka3:9092"
}
jdbc {
jdbc_driver_library => "mysql-connector-java-5.1.36-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"
jdbc_user => "mysql"
parameters => { "favorite_artist" => "Beethoven" }
schedule => "* * * * *"
statement => "SELECT * from songs where artist = :favorite_artist"
}
beats{
port => 5044
}
}출력 플러그인
필터를 거쳐 가공된 데이터를 내보내는 단계
- elasticsearch : bulk API를 사용해 elasticsearch로 출력. 가장 많이 사용?
- file : 지정한 파일에 데이터 기록
- kafka : 카프카 토픽에 데이터 기록
- stdout : 콘솔 출력
output {
elasticsearch {
hosts => "hostname"
index => "%{[field][subfield]}-%{+YYYY.M.dd}"
user => "user_id"
password => "password"
}
file {
path => "/path/to/output/file"
codec => "json"
flush_interval => 10
}
kafka {
codec => "json"
topic_id => "topic name"
}
stdout {
codec => rubydebug
}
}필터 플러그인 ⭐️
비정형 혹은 반정형화된 데이터를 정형화 시켜 다음 스토리지에 저장하게 해주는 기능
-
grok정규 표현식을 사용해 문자열을 파싱하게 해줌 →
%{패턴: 필드명}의 형태로 특정 필드를 파싱GREEDYDATA
filter { grok { match => { "message" => "%{NUMBER:number}-%{TIMESTAMP_ISO8601:time}-%{GREEDYDATA:rest}" } } }NUMBER, SPACE, URI, IP, SYSLOGBASE, TIMESTAMP_ISO8601, DATA, GREEDYDATA
## Custom Pattern # content of pattern TEST_PATTERN [^{.*}$] #################################### filter { grok { match => { patterns_dir => ["./pattern"] "message" => "%{TEST_PATTERN:custom}" } } } -
mutate필드를 변형하는 다양한 기능 제공
https://bactoria.github.io/2020/04/12/로그스태시-mutate-filter-plugin-파헤치기/- split
- rename
- replace : 필드의 내용을 다음으로 교체
- uppercase/lowercase
- gsub :
gsub => ['field', '[pattern]', ''] - add_field/remove_field
-
dissect정규식을 사용하지 않고 구분자를 통해 새로운 필드로 추출
dessect { mapping => { "message" => "[%{timestamp}] [%{id}] %{ip}:%{port}" } }- 각 중괄호 안의 필드명으로 새로운 필드가 만들어짐
message필드의 문자열을 적절하게 파싱하여 새로운 필드로 나눠주는 것- 정규식을 쓰지 않기 때문에
grok에 비해 빠름 - 반복적인 문자열의 경우 유용하지만
grok에 비해 단순하여 복잡한 문자열의 경우 쓰기 어려움
-
datedata { match => ["timestamp", "YYYY-MM-dd HH:mm", "yyyy/MM/dd HH:mm:ss"] } -
조건문

기록하는 블로그