데이터파이프라인
1.데이터 파이프라인 구축

파이프라인 구축 연습을 위해 수집부터 Elasticsearch 적재까지의 파이프라인을 만들어보았다.로그수집 - kakfa - logstash - elasticsearch 로 이루어진 파이프라인 구성이다.3개의 오픈스택 vm을 만들고 각각 kafka, logstash,
2.데이터 파이프라인 설치 (1) - Kafka

카프카는 메세지 브로커 기능을 담당한다. 카프카가 무엇인지, 어떻게 기능하는지는 추후에 다른 글에서 다시 정리하도록 하고 여기서는 설치와 기본 설정에 대해서만 다루겠다.kafka 홈페이지에서 소스 파일을 다운로드 받으면 된다. 다만 버전 통일성을 위해 나는 동료에게 받
3.데이터 파이프라인 설치 (2) - Logstash

logstash 역시 서비스파일로 실행시켰다.홈 디렉토리에 logstash/logstash.conf를 생성한다.해당 파일에 데이터를 받아올 곳과 내보낼 곳을 설정해주는 것인데 일단은 빈칸으로 두도록 하겠다. 다음 글에서 kafka의 컨슈머로 설정하고 필터를 거친 후 e
4.데이터 파이프라인 (3) - Logstash 설정
kafka 토픽은 두 개가 있다. 각각의 프로듀서가 동일한 이름의 토픽으로 데이터를 보내고 있다. 그리고 logstashs는 컨슈머로서 데이터를 끌어온 뒤 elasticsearch로 보내준다.이때, 토픽 명에 따라서 해당 토픽 명을 필드로 추가하고 있는데 filter가
5.데이터 파이프라인 설치 - Elasticsearch
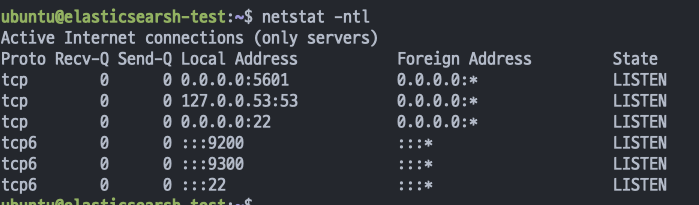
ㄹㄹ
6.데이터 파이프라인 - 로그 수집

이제 rsyslog와 collectd에서 수집한 데이터를 kafka로 보내는 설정을 해보자.먼저 rsyslog의 설정이다. /etc/rsyslog.conf에 보면 $IncludeConfig /etc/rsyslog.d/\*.conf가 있으므로 rsyslog.d/kafka
7.kafka 3 nodes Cluster install

앞서서는 전체적으로 단일노드로 구성된 데이터 파이프라인을 구성했다.하지만 각 단계는 모두 여러 노드로 구성된 클러스터 구성을 추천한다. 보통 최소 3대 이상으로 구성을 추천한다.클러스터를 구성하게되면 각 노드에 토픽이 복사되어 존재할 수 있게 된다(replication
8.Docker를 사용해 ELK 설치

도커 설치 방법은 생략하겠다WSL에서 docker desktop을 설치 해 사용했다.리눅스를 사용한다면 docker engine을 직접 설치하면 된다.엘라스틱 서치 최신 버전인 8.3.3 이미지를 pull하여 컨테이너를 띄운다.이때 single node로 실행하면 자동
9.Logstash twtitter input plugin으로 트위터 데이터 수집

로그스태시의 트위터 플러그인을 사용해 직접 트위터 데이터를 수집할 수 있었다.먼저 트위터 개발자 페이지에서 필요한 ACCESS_TOKEN과 API_KEY 등을 발급받고 입력하면 준비 끝.그리고 수집하고자 하는 키워드와 언어를 선택해서 넣어주면 자동으로 수집해준다.필터
10.Kibana에서 지도 정보 시각화 하기
키바나는 강력한 시각화 도구이다. 이번에는 지도정보 데이터를 바탕으로 시각화를 해볼 것이다.실제 프로젝트에서는 API 등을 통해 실시간으로 업데이트되는 데이터를 받아오거나 직접 수집하겠지만, 우선은 간단하게 시각화부터 해보기 위해 데이터를 파일로 받아서 엘라스틱서치에