EC2 상에서 완전분산 하둡 설치 with 도커
ec2의 인스턴스로 네임노드 1개, 세컨더리 네임노드 1개, 데이터노드 3개를 만들어 hdfs을 구성합니다.
간단한 배포와 패키징을 위해 도커, 도커 스웜,오버레이네트워크를 이용합니다.
원격 자바 API 클라이언트에서 hdfs상의 파일을 읽고 쓸 수 있도록 설정합니다.
TO DO
- ec2 기본 인스턴스 생성
- putty 원격 접속
- ec2 인스턴스 설정
- java
- ssh
- hadoop
- AMI 이미지 생성
- 모든 노드 생성
- 테스트
ec2 기본 인스턴스 생성
인스턴스 설정
- 생성

AWS - ec2 콘솔에서 인스턴스 시작을 클릭합니다.
- 이름
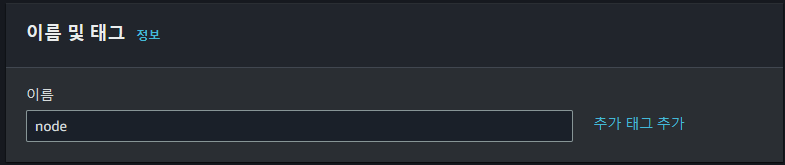
인스턴스의 이름을 설정합니다.
- OS 이미지
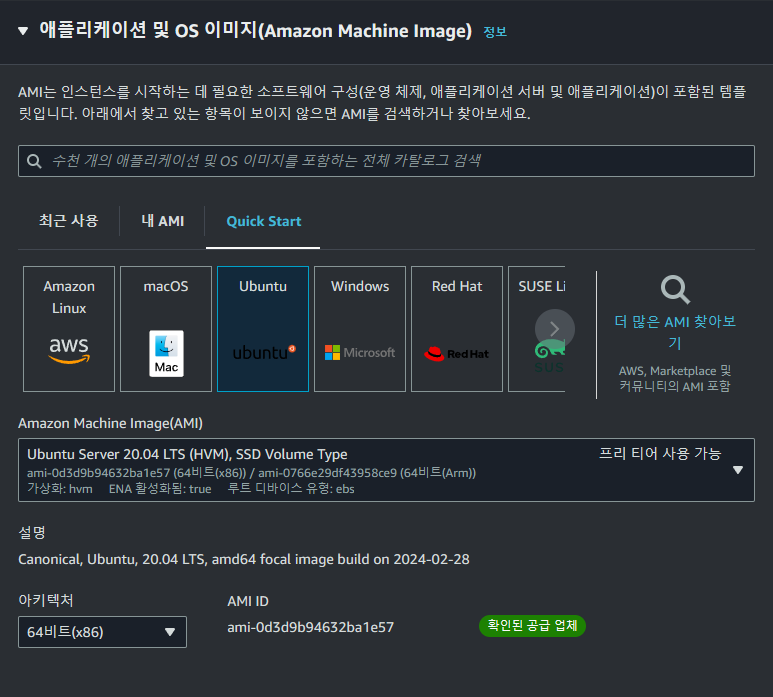
OS는 우분투 20.04 이미지를 사용합니다. 더 가벼운 이미지를 사용해도 되지만 사용의 편의를 위해 익숙한 이미지를 골랐습니다.
- 인스턴스 유형
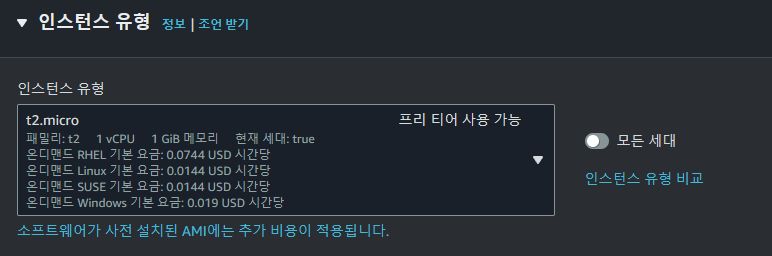
각 노드당 1~2개의 하둡 데몬을 실행할 것이고 개발 프로젝트이므로 높은 성능의 인스턴스가 필요하지 않습니다.
가장 비용이 저렴한 t2.micro 유형을 선택합니다.
- 키 페어
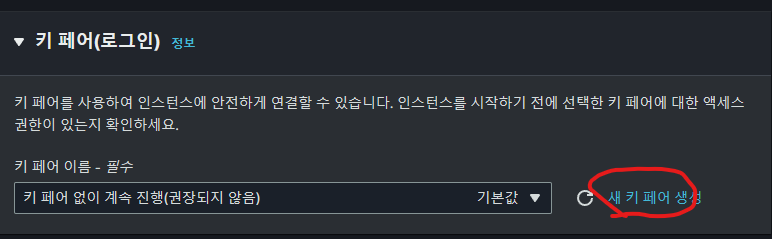
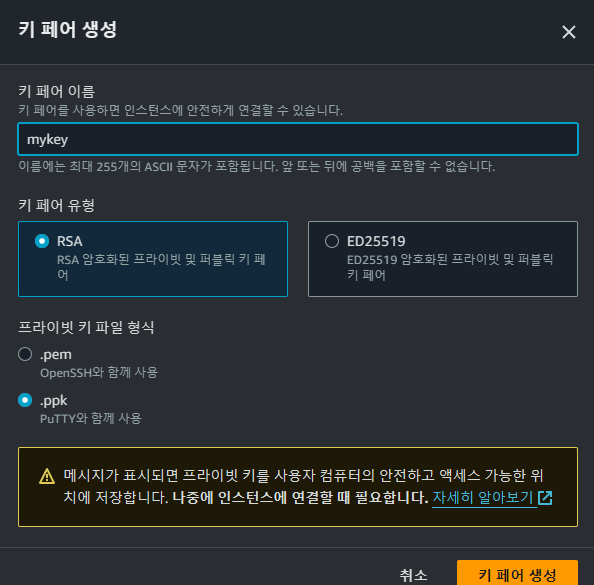
기존의 키 페어가 있다면 기존의 키 페어가 없다면 새 키 페어를 생성합니다.
이는 원격 호스트에서 ec2 인스턴스로 원격 접속하는데 사용됩니다. 현재 사용중인 환경에 따라 mac/linux → .pem 확장자 windoe → .ppk 확장자를 선택해 키페어를 생성해줍니다.
호스트의 로컬 디렉토리에 저장합니다. (ex C:/YOUR/DIRECTORY/my-key.ppk)
- 네트워크 설정
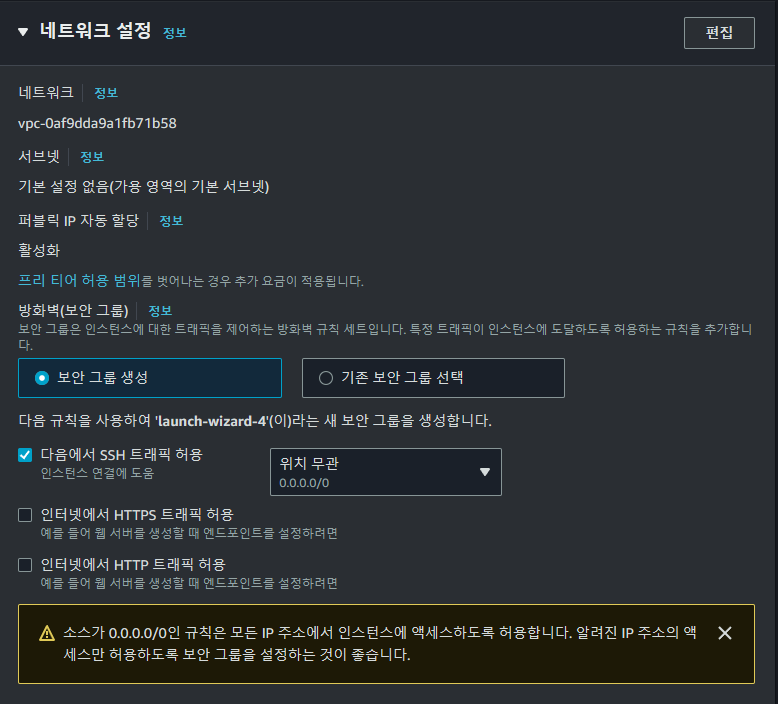
보안 그룹은 인바운드 및 아웃바운드로 사용할 포트를 설정하는 구간입니다. 개인적으로 가장 실수가 많았던 부분입니다. 개발용 프로젝트라면 모든 포트에 대해서 열어도 되지만 이번엔 사용할 포트를 정리하였습니다. 이는 후술하겠습니다.
- 인스턴스 시작
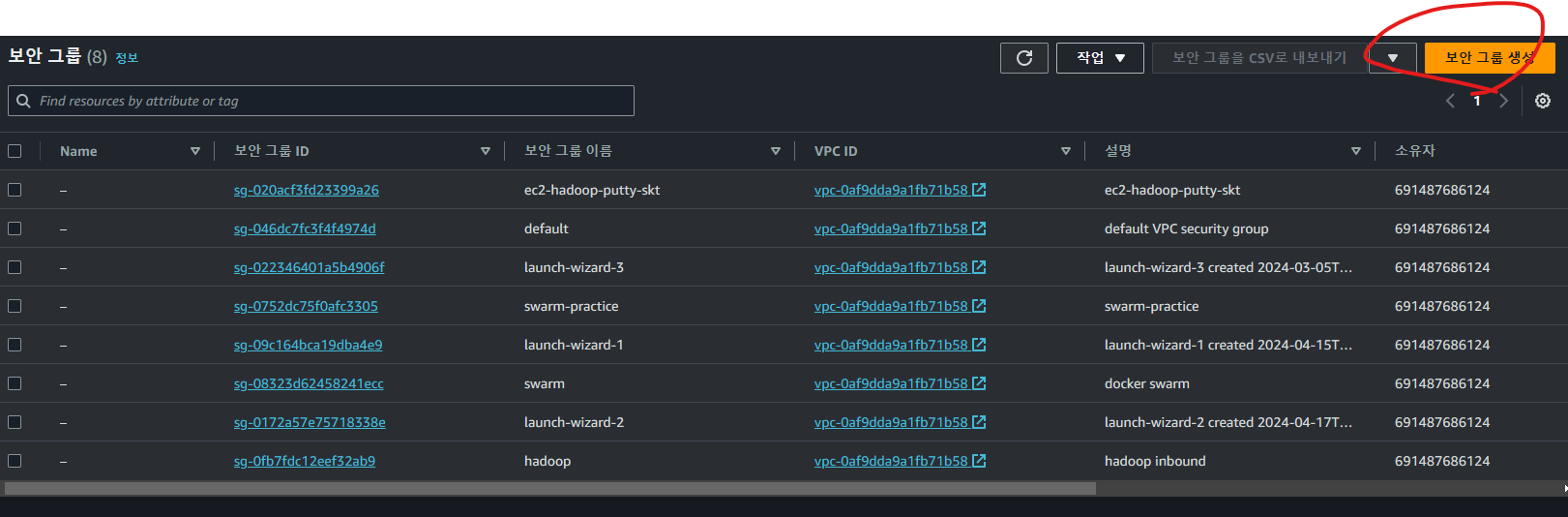
보안그룹 설정
ec2 인스턴스에 사용할 보안 그룹을 생성합니다. AWS 콘솔에서 네트워크 및 보안의 보안그룹으로 이동하고 보안그룹을 생성합니다.
SSH 연결 포트
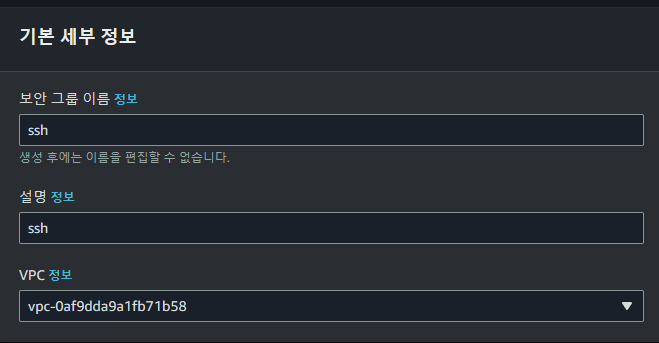
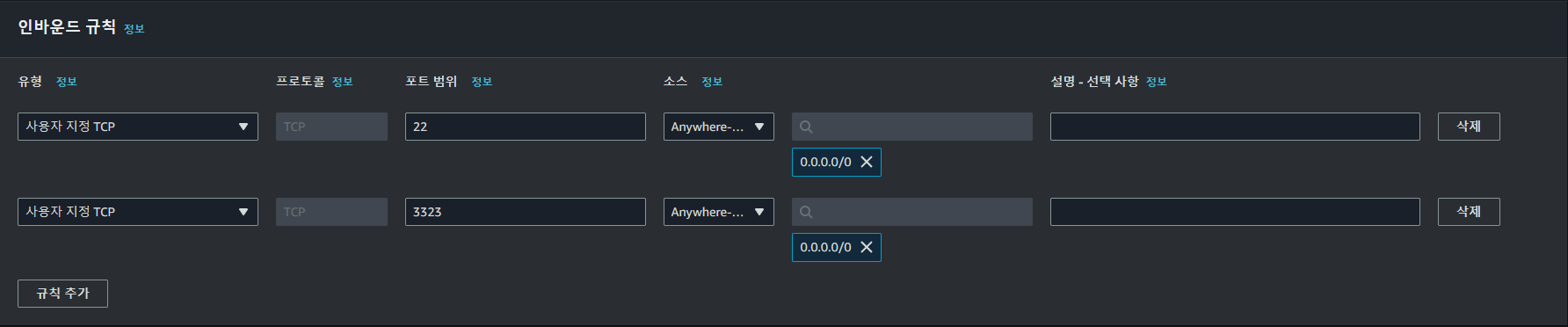
ssh위한 TCP 포트를 22, 3323번을 열었습니다. 이번 프로젝트에서 클라이언트에서 ec2 인스턴상으로의 ssh 연결은 3323번을 통해 이루어집니다. 이는 skt 공유기의 경우 22번 포트 연결을 허용하지 않는 경우가 있기 떄문입니다. 해당하지 않는다면 그대로 22번을 사용하셔도 좋습니다.
아웃바운드 규칙은 그대로 사용합니다.
하둡 포트
인바운드 규칙 TCP 네임노드 연결용 9000, 네임노드 WEB UI용 9870 을 사용합니다.
도커 스웜 포트
위와 비슷하게 인바운드 규칙을 추가해줍니다. 프로토콜 종류에 유의합니다.
putty 원격 접속
저는 윈도우 호스트이므로 putty를 이용해 원격 접솝합니다. Putty 사용법은 생략하겠습니다.

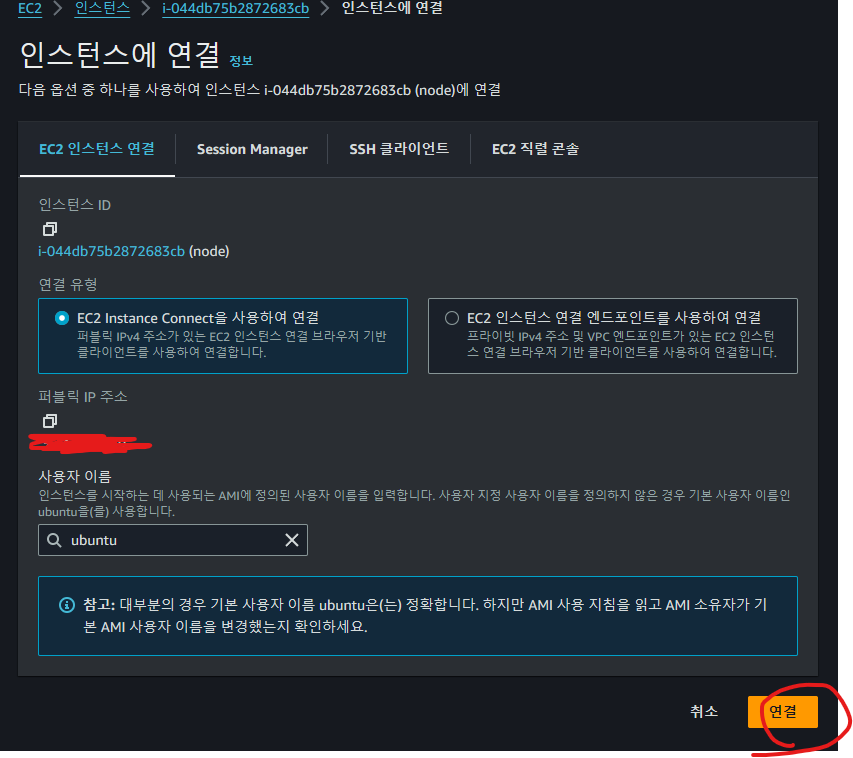
ec2 콘솔에서 ec2 인스턴스에 접속합니다.
ssh를 3323 포트를 이용할 경우에만 아래 설정을 합니다.
### Shell
sudo nano /etc/ssh/sshd_config
### FILE EDIT /etc/ssh/sshd_config
## LINE 15
Port 3323
### END file edit
### shell
sudo service ssh restart수신받는 ssh 용 포트를 3323으로 바꿔줍니다. 위의 설정이 적용하기 위해 sudo service ssh restart 해줍니다.
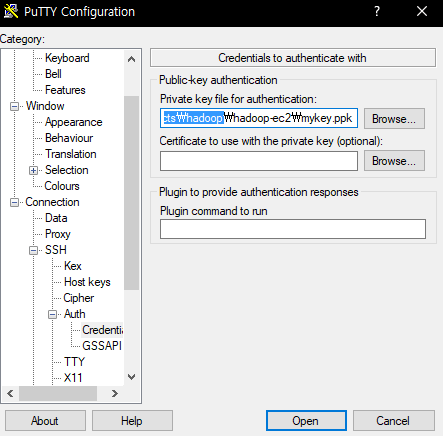
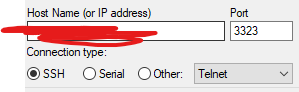

로컬 호스트에서 putty 설치 후 위에서 받았던 키를 이용해 원격 접속합니다.
ec2 인스턴스의 퍼블릭 IP와 포트번호 3323( 혹은 22)를 이용합니다. 빨간 줄이 그어진 곳에 자신의 노드의 퍼블릭 IP를 입력합니다. 퍼블릭 IP는 ec2 콘솔에서 확인할 수 있습니다.

Open → Accept → ubuntu 입력 으로 ec2 인스턴스에 접속할 수 있습니다.
3. ec2 인스턴스 설정
이제 이미지가 될 노드에 도커를 설치합니다.
3.1. 도커 설치
https://docs.docker.com/engine/install/ubuntu/
위의 공식 문서는 우분투에 도커를 설치하는 과정을 알려줍니다. 이를 따라 설치할 수 있습니다.
설명을 제외한 입력할 코드만을 나열하겠습니다.
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
# install docker
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# test docker
sudo docker run hello-world위의 과정에 문제가 없었다면 다음으로 넘어갑니다. 설치시 문제가 있다면 위의 문서를 참고해주세요.
3.2. 도커 이미지 생성 - 자바,SSH, 하둡 설치
자바이미지의 컨테이너를 실행해 ssh, 하둡을 설치후 이미지로 커밋합니다.
3.2.1. openjdk:11 이미지
openjdk11의 이미지로 컨테이너를 -it 모드로 실행합니다.
# ec2
# 도커 설치
sudo docker run --name base_container -it openjdk:11 /bin/bash
## ec2 콘솔 내의 base_container
echo $JAVA_HOME
# /usr/local/openjdk-113.2.2. ssh 설치
## ssh config
apt update
apt install openssh-server openssh-client -y
## ssh key 설정
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysssh 설치하고 암호를 생성합니다. 공개키를 authorized_keys에 추가해 ssh localhost가 가능하게 합니다.
service ssh start
ssh localhost
# yes
exit # ssh 접속 종료ssh 데몬이 실행하고 ssh localhost를 통해 설정이 제대로 되었는지 확인합니다.
## sshd_config 설정 타 호스트에서 root로 접속이 가능하게 합니다.
echo "PermitRootLogin yes" >> /etc/ssh/sshd_config
## ssh 자동 실행
echo "service ssh start" >> ~/.bashrc추가 설정을 마쳤습니다.
3.2.3. hadoop 설치
이제 도커 컨테이너에서 사용할 하둡을 설치할 것입니다. 하둡은 3.3.6 버전을 사용했습니다.
- hadoop 설치
apt install wget nano
# Y
cd ~
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
tar zxvf hadoop-3.3.6.tar.gz
rm hadoop-3.3.6.tar.gz
ln -s hadoop-3.3.6 hadoop
cd ~/hadoop
mkdir -p hdfs/namenode
mkdir -p hdfs/datanode
3.2.4. hadoop 설정
- nano ~/.bashrc
############### HADOOP-3.3.2 PATH ################
HADOOP_HOME=/root/hadoop
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootsource ~/.bashrc
하둡 디렉토리와 PATH 설정을 통해 하둡 데몬 명령어를 쉽게 사용하게 해줍니다.
- hadoop-env.sh, yarn-env.sh
echo "export JAVA_HOME=/usr/local/openjdk-11" >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh
echo "export JAVA_HOME=/usr/local/openjdk-11" >> $HADOOP_HOME/etc/hadoop/yarn-env.sh하돕 데몬에게 사용할 자바를 제시해줍니다.
- core-site.xml
nano $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode:9000</value>
</property>
</configuration>
네임노드의 Ip주소 혹은 호스트 네임과 포트번호를 설정합니다. 후술할 오버레이 네트워크에서는 컨테이너 이름으로 DNS 되므로 namenode라고 적어줍니다.
- hdfs-site.xml
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.http.address</name>
<value>namenode:9870</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>secondarynamenode:9868</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
</configuration>-
<dfs.replication>hdfs의 복제계수를 설정합니다. 권장 설정대로 데이터노드를 3개 만들 것이므로 3입니다. -
<dfs.name.dir>,<dfs.data.dir>각 노드에서 작업한 결과물, 로그, 블록등이 저장될 실제 디렉토리입니다. 앞서 설치 과정중에서 해당 디렉토리들을 만들었습니다. 하둡 설정중에 충돌이 발생한다면 이 디렉토리들을 삭제 후 재생성해주면 도움이 될 수 있습니다. -
<dfs.namenode.http.address><dfs.secondary.http.address>WebUI의 주소와 포트를 설정합니다. 앞서와 마찬가지로 오버레이 DNS를 이용하므로 호스트이름(후에 생성할 컨테이너 이름)을 적습니다. -
<dfs.namenode.rpc-bind-host>로컬 호스트에서 자바 API로 ec2 hdfs와 통신(읽기 및 저장)하고 싶으므로 모든 인터페이스에서의 허용을 설정해주었습니다. -
mapred-site.xml
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>- yarn-site.xml
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>namenode01</value>
</property>
</configuration>- workers
nano $HADOOP_HOME/etc/hadoop/workets
datanode1
datanode2
datanode3위에서와 마찬가지로 데이터노드의 IP주소 혹은 호스트 이름을 적습니다.
3.3. 이미지 커밋
exit
sudo docker commit base_container hadoop_base 설치가 끝난 위의 도커 이미지를 커밋합니다.
4. AMI 이미지 생성
하둡과 컨테이너를 위한 이미지를 생성한 ec2 인스턴스의 AMI 이미지를 만들어 줍니다.
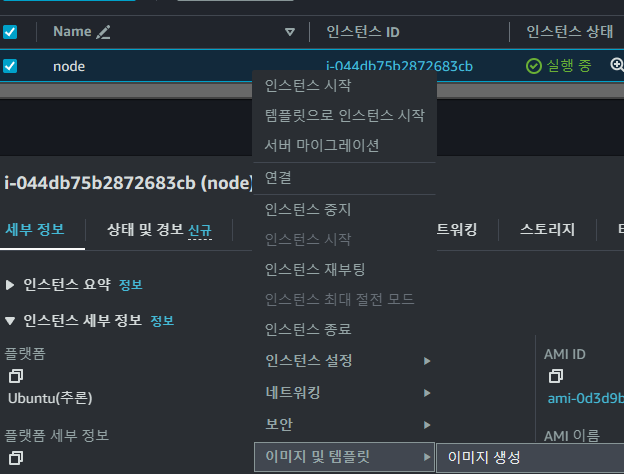
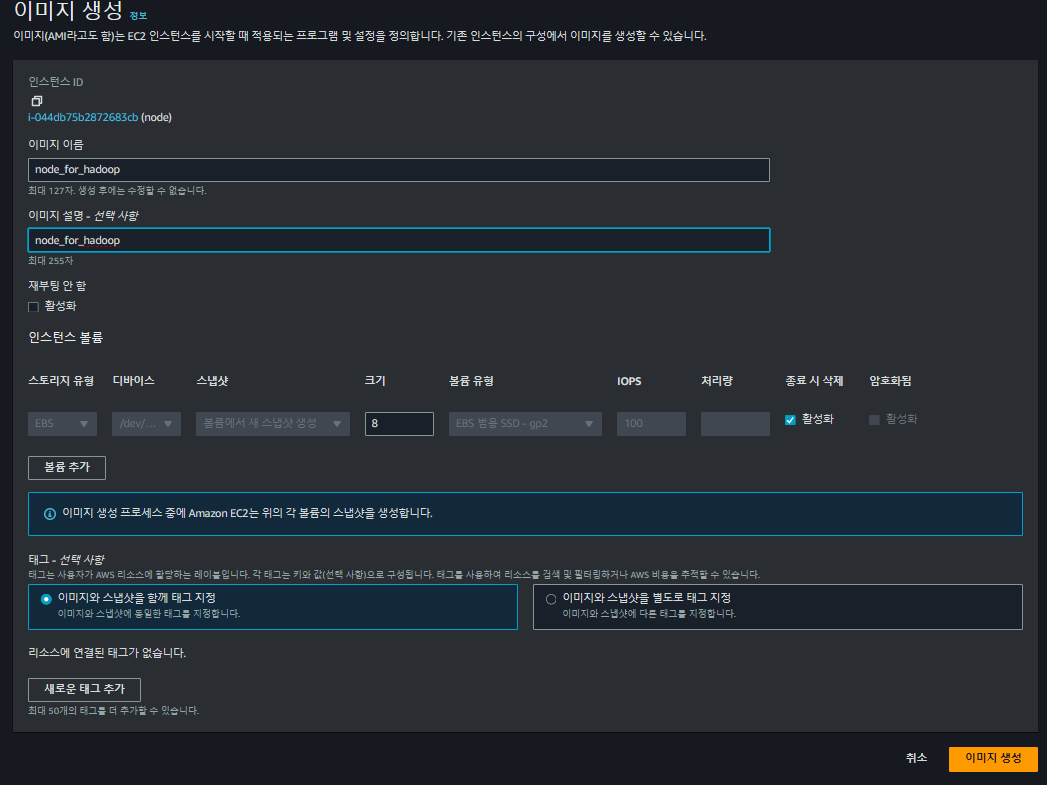
인스턴스를 우클릭해서 AMI을 생성합니다. 위의 설정이 완료된 인스턴스를 앞으로는 간단히 만들 수 있습니다.
5. 모든 노드 생성 및 설정
위의 이미지를 이용해 node 인스턴스를 4개 더 생성합니다. 보안 그룹또한 처음 만든 노드와 같이 설정합니다. 이미지 생성 요청 후 생성완료까지는 약간의 시간이 걸립니다. 완료 전에 인스턴스 생성 시 에러가 발생합니다.

각 인스터스의 이름을 용도에 맞게 수정합니다.
5.1. 도커 스웜 및 오버레이 네트워크 구축
오버레이 네트워크를 구축해 서로 다른 인스턴스, 즉 서로 다른 도커 데몬 위의 컨테이너 간의 연결을 가능하게 해줍니다. 오버레이 네트워크를 구축하기 위해 도커 스웜을 사용합니다.
오버레이 네트워크에 대한 튜토리얼은 다음 링크를 참고하시면 좋습니다.
오버레이 네트워크 , 도커 독스 공식 튜토리얼
포트 설정은 위에서 했으므로 생략합니다.
- 네임노드, 스웜 시작
sudo docker swarm init
도커 스웜의 매니저노드로 네임노드를 지정해줍니다.
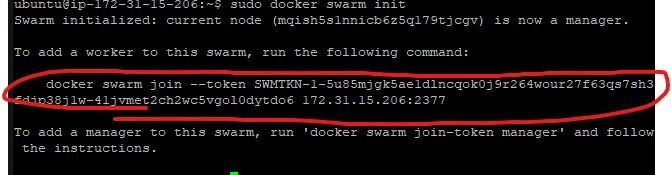
위의 빨간 원 부분을 복사하여 다른 모든 노드에서 실행해줍니다. 이 때 sudo 붙여서 사용합니다.
- 네임노드를 제외한 모든 노드, 스웜 가입
sudo docker join —token [생성된 토큰][네임노드의 private IP]:[포트번호]
sudo docker swarm join --token SWMTKN-1-01x8w62u21o7320pyp6obdm5wtdcoajouyahad3m1pj191ph83-f3i041igqcgcikz1q90nhq4gi 172.31.15.138:2377
- 네임노드, 오버레이 네트워크 생성
sudo docker network create --driver=overlay --attachable my-net
- 네임노드, 컨테이너 실행
sudo docker run -it -p 9870:9870 -p 9000:9000 --name namenode --network my-net hadoop_base bash- 네임노드를 제외한 모든 노드, 컨테이너 실행
sudo docker run -it --name datanode1 --network my-net hadoop_base bashsudo docker run -it --name datanode2 --network my-net hadoop_base bashsudo docker run -it --name datanode3 --network my-net hadoop_base bashsudo docker run -it --name secondarynamenode --network my-net hadoop_base bash5.2. SSH 연결
- 네임노드 컨테이너에서, ssh 연결 확인
ssh datanode1
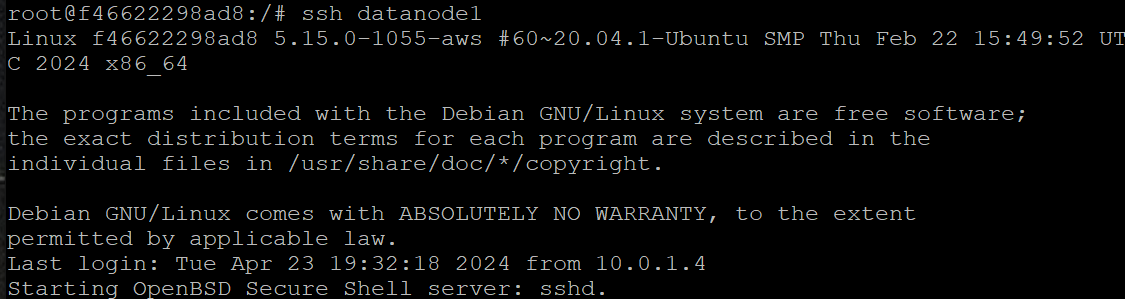
exit
하둡 데몬은 각 노드간에 연결에 ssh를 사용합니다. 위에서처럼 ssh 연결이 잘 된다면 하둡 실행으로 넘어갈 수 있습니다.
6. 하둡 실행 테스트
6.1. 데몬 실행
- 네임노드컨테이너에서, 네임노드 포맷
hadoop namenode -format
- 네임노드컨테이너에서,
start-dfs.sh 수정해주었습니다. 자세한 내용은 아래 트러블슈팅에서 확인할 수 있습니다.
echo "Starting namenodes on [${NAMENODES}]"
hadoop_uservar_su hdfs namenode "${HADOOP_HDFS_HOME}/bin/hdfs" \
# --workers
--config "${HADOOP_CONF_DIR}" \
--hostnames "${NAMENODES}" \
--daemon start \
namenode ${nameStartOpt}
HADOOP_JUMBO_RETCOUNTER=$?파일 수정후, 네임노드에서
start-dfs.sh
start-yarn.sh
실행해줍니다.

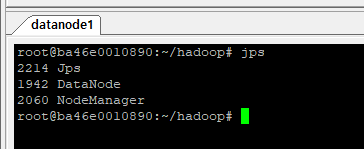
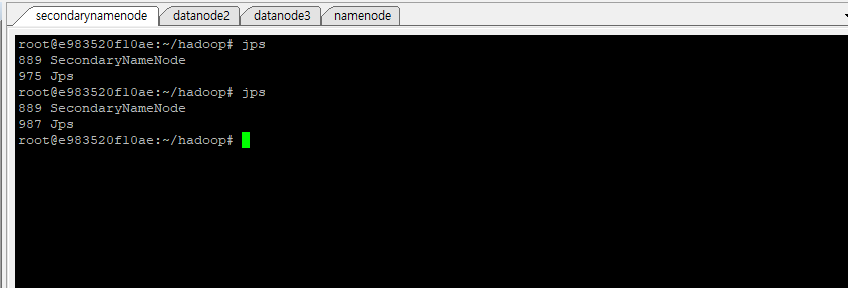
각 노드에서 위와 같이 모든 데몬들이 실행중이라면 성공입니다.
6.2. hadoopCLI
hadoop CLI 를 이용해 hdfs가 정상작동하는지 확인합니다.
- 네임노드
cd ~
echo “1, 2, 3” >> temp.txt
hadoop fs -copyFromLocal temp.txt /temp.txt
hadoop fs -ls /
hadoop fs -cat /temp.txt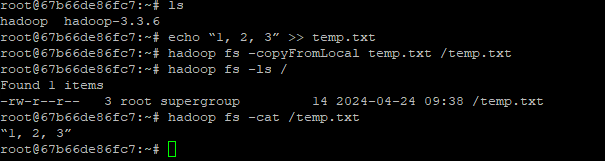
6.3. 로컬 호스트에서의 연결
로컬 호스트에서 ec2 상의 네임노드와 연결할 수 있습니다.
hadoop fs -ls hdfs://{namenode public IP:9000}/문제가 있다면 rpc 바인드, 네임노드 IP, 권한문제를 확인해 보는 것을 추천합니다.
6.4. 정지 커맨드
모든 데몬 정지: stop-all.sh
모든 “node”가 들어간 컨테이너 삭제:
sudo docker ps -a | grep 'node' | awk '{print $1}' | xargs sudo docker rm
7. 추후 추가할 부분
- 도커 볼륨: 도커 컨테이너에 데이터노드와 네임노드, 로그의 데이터는 유실되면 안되므로 실제 환경에서는 볼륨을 반드시 추가해야합니다.
- 쿠버네티스: 컨테이너 관리 도구로 셋업을 더욱 쉽게 할 수 있습니다.
- 자바 하둡 API와 연결테스트
8. 트러블슈팅
8.1. 도커 로그인
#도커 로그인
sudo docker login
아이디입력
패스워드입력
sudo docker tag hadoop_base gnswp21/hadoop-ec2:base
sudo docker push gnswp21/hadoop-ec2:base! 트러블 슈팅
sudo 안쓰고 로그인했더니 로그인 계속 안됐었음
⇒ sudo docker login 으로 해결
- tip : 이미 로그인이 되어있다면 로그인 succed만 뜬다. 또 입력하라고 안뜬다.
8.2. 컨테이너간 ssh 연결
8.3. start-dfs.sh에서 네임노드 실행
start-dfs.sh 실행시에 네임노드가 실행되지 않고 다음 에러가 발생합니다.
IOException: Could not parse line: Filesystem 1024-blocks
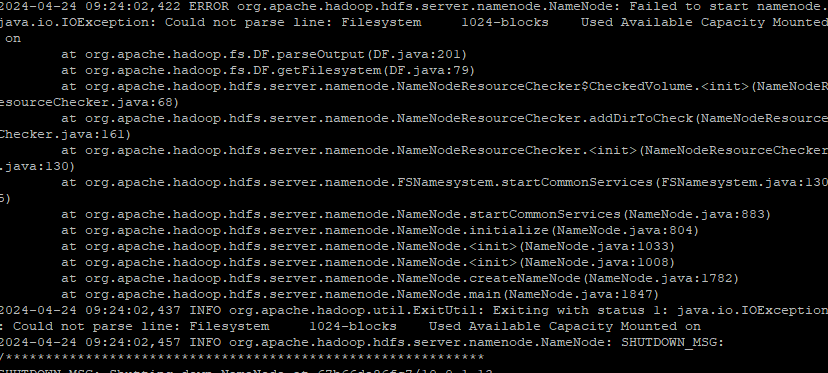
네임노드 실행시 문제가 발생한 것인데 이를 디버깅하고자 start-dfs.sh 코드를 확인하였습니다.
추가로, hdfs —daemon start namenode 실행시 네임노드가 정상 작동하는 것을 확인하였습니다. start-dfs.sh에서 어떤 로직때문에 에러가 발생하는지 확인해보았습니다.
## start-dfs.sh 중 일부
NAMENODES=$("${HADOOP_HDFS_HOME}/bin/hdfs" getconf -namenodes 2>/dev/null)
if [[ -z "${NAMENODES}" ]]; then
NAMENODES=$(hostname)
fi
echo "Starting namenodes on [${NAMENODES}]"
hadoop_uservar_su hdfs namenode "${HADOOP_HDFS_HOME}/bin/hdfs" \
--workers \
--config "${HADOOP_CONF_DIR}" \
--hostnames "${NAMENODES}" \
--daemon start \
namenode ${nameStartOpt}
HADOOP_JUMBO_RETCOUNTER=$?네임노드는 다음의 함수, hadoop_uservar_su 를 통해 실행됨을 확인했습니다. 해당 함수는 hadoop-function.sh에 정의되어있으며 hdfs 명령어를 실행할 때 유저권한과 관련된 보안 설정을 해주는 함수입니다.
해당 함수 내부에서
hdfs --worker \
--config "${HADOOP_CONF_DIR}" \
--hostnames "${NAMENODES}" \
--daemon start \
namenode ${nameStartOpt}`가 실행됩니다.
이를 제 환경에 맞게 해석하면 다음과 같습니다.
hdfs --worker \
--config "/root/hadoop/etc/hadoop" \
--hostnames "namenode" \
--daemon start \
namenode `위의 옵션 --workers, --hostnames, --config 를 하나씩 빼고 로그를 대조해보면서 어떤 옵션이 문제인지 확인하였습니다. 결과적으로, --workers 를 넣었을 때 해당 에러가 발생하는 것을 확인하였습니다.

의 공식문서 따르면 workers 파일에 적혀 있는 모든 호스트에서 이 커맨드를 가능하다면 실행합니다. workers 파일에는 데이터노드들의 호스트 이름이 적혀있습니다. 네임노드를 실행하는 커맨드에서는 필요없는 옵션같습니다.
따라서, 다음 코드에서 정상 작동합니다.
hdfs \
--config "/root/hadoop/etc/hadoop" \
--hostnames "namenode" \
--daemon start \
namenodeworker 옵션이 사용되지 않도록 start-dfs.sh을 수정하였습니다.
echo "Starting namenodes on [${NAMENODES}]"
hadoop_uservar_su hdfs namenode "${HADOOP_HDFS_HOME}/bin/hdfs" \
--config "${HADOOP_CONF_DIR}" \
--hostnames "${NAMENODES}" \
--daemon start \
namenode ${nameStartOpt}
HADOOP_JUMBO_RETCOUNTER=$?8.4. 방화벽
putty 커넥션이 자꾸 끊기는 문제가 있었는데, 아래 코드로 괜찮아졌습니다.
ufw allow 3323/tcp
service ssh restart
