
개요
다크모드를 기준으로 작성되었습니다.
aws-ec2에 실제 분산 애플리케이션을 구성하기에 앞서, 로컬 호스트 도커 컨테이너에서 개발용 분산 애플리케이션 프로젝트를 구성해보았습니다. 이 프로젝트는 단계적으로 고가용성을 지원하는 하둡 HDFS를 구성합니다.
이 글은 독자가 하둡, ssh, 도커, 도커 컴포즈에 대해 사용가능한 수준의 사전지식을 가지고 있다는 전제 하에 작성하였습니다.
프로젝트 아키텍쳐
로컬 윈도우 호스트에 도커 머신을 설치하고 최종적으로 다음의 컨테이너들을 구성합니다.
| 컨테이너 이름 | 실행되는 주요 데몬 |
|---|---|
| 네임노드1 | 네임노드, 저널노드, 주키퍼서버, ZKFC |
| 네임노드2 | 네임노드, 저널노드, 주키퍼서버, ZKFC |
| 리소스매니저 | 리소스매니저, 저널노드, 주키퍼서버 |
| 데이터노드1 | 데이터노드, 노드매니저 |
| 데이터노드2 | 데이터노드, 노드매니저 |
| 데이터노드3 | 데이터노드, 노드매니저 |
HA (고가용성)은 두개의 네임노드가 활성-대기 상태를 구성하는 것으로 원래의 단일고장점 문제를 해결한 HDFS 구성입니다. 이는 저널노드, 주키퍼서버 , ZKFC이 추가 구성되는 것으로 이루어 지며 해당 구현은 아래 내용 및 추가 글에서 다룹니다. 이에 대한 설명 및 설정 내용은 apache 공식 사이트와 하둡 완벽 가이드을 기반으로 작성되었습니다.
깃허브 및 버전 정리
깃허브: https://github.com/gnswp21/local-Distributed-ETL
- 자바 - jdk-11.0.10_linux-x64_bin
- SSH
- hadoop - 3.3.6
- zookeeper - apache-zookeeper-3.8.4.tar.gz
이 프로젝트를 학습 해보는 경우에는 git clone 이외에도 자바와 주키퍼를 apache 사이트에서 직접 다운 받아 적절한 디렉토리에 위치시켜야 합니다. 다음의 경로를 주의해주세요.
`1. java/jdk-11.0.10_linux-x64_bin.deb`
`2. ha/apache-zookeeper-3.8.4.tar.gz`
구성 - 고가용성을 지원하는 HDFS
하둡을 운용하기 위해서는 자바와 ssh 설치가 필수적입니다. 이를 먼저 설치한 후 하둡을 설치하는 이미지를 작성합니다.
자바 설치
구성
우분투 20.04에서 자바를 설치하기 위한 도커 이미지를 생성합니다.
java 디렉토리에 사용할 버전(jdk-11.0.10_linux-x64_bin.deb) 의 자바 deb 파일을 다운 받는다.
FROM ubuntu:20.04
# Copy Jav deb 파일
COPY . /root/java
ARG version=jdk-11.0.10_linux-x64_bin.deb
RUN apt update && \
apt install -y libasound2 && \
apt install nano
\
# install java
RUN sh /root/java/install-java.sh $version #!/bin/sh
yes | dpkg -i /root/java/"$1"
cd /usr/lib/jvm
jdk_version=$(ls | head -n 1)
ln -s $jdk_version jdk
cat /root/java/java-bashrc.txt >> ~/.bashrc
##################### JDK 11 PATH #########
JAVA_HOME=/usr/lib/jvm/jdk
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export JAVA_HOME
export PATH
구성 및 설치 테스트
- 이미지 생성해보기
docker build -t myjava -f java/Dockerfile-java java
- 생성된 이미지 실행 후 자바 작동 확인
docker run -it myjava bash
## myjava container bash
java -version
# 버전이 정상적으로 출력된다면 정상적인 구성
exitSSH 설치
구성
- Dockerfile-ssh
FROM myjava RUN apt install openssh-server openssh-client -y # rsa 키 형식, PEM 형식,공백입력으로 암호 생성 RUN ssh-keygen -t rsa -m PEM -P '' -f ~/.ssh/id_rsa RUN cd ~/.ssh && \ cat id_rsa.pub >> authorized_keys
rsa 키 형식, PEM 형식,공백입력으로 암호 생성합니다.
이 암호는 모든 컨테이너에서 authorized_keys 파일을 통해 공유해서 암호 없이 다른 노드로 연결 가능하게 해줍니다. 또한, 추후에 서술할 HA의 펜싱 방법으로도 사용됩니다.
구성 및 설치 테스트
- 이미지 생성해보기
docker build -t myssh -f ssh/Dockerfile-ssh ssh
- 생성된 이미지 실행 후 자바 작동 확인
docker run -it myssh bash
## myssh container bash
service ssh start
ssh localhost
# yes
# 정상적으로 ssh 접속이 되면 정상적인 구성
exit # ssh 접속 종료
exit하둡 설치 - 컨테이너 5개에서 모두 실행
고가용성 구성에 앞서 기본적인 완전분산 HDFS를 구성합니다. 우선, 5개의 컨테이너에서 분산 애플리케이션으로 작동하는 hdfs 구성을 합니다. 네임노드, 리소스매니저, 데이터노드123으로 이루어집니다.
구성
hadoop 디렉토리
FROM myssh
WORKDIR /root
# install hadoop
RUN apt -y install curl
RUN curl https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz --output hadoop-3.3.6.tar.gz
RUN tar zxvf hadoop-3.3.6.tar.gz && \
ln -s hadoop-3.3.6 hadoop
RUN mkdir -p ~/hadoop/hdfs/name && \
mkdir -p ~/hadoop/hdfs/data && \
mkdir -p ~/hadoop/hdfs/journal && \
mkdir -p ~/hadoop/logs
# copy .bashrc for ENV variables
COPY .bashrc /root/.bashrc
# copy hadoop configurations
ARG hadoophome=/root/hadoop
ARG hadoopconf=$hadoophome/etc/hadoop
COPY core-site.xml $hadoopconf/core-site.xml
COPY hdfs-site.xml $hadoopconf/hdfs-site.xml
COPY mapred-site.xml $hadoopconf/mapred-site.xml
COPY yarn-site.xml $hadoopconf/yarn-site.xml
COPY workers $hadoopconf/workers
RUN /bin/bash -c ". ~/.bashrc" # ~/.bashrc: executed by bash(1) for non-login shells.
# see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
# for examples
##################### JDK 11 PATH #########
JAVA_HOME=/usr/lib/jvm/jdk
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export JAVA_HOME
export PATH
#######HADOOP PATH######
HADOOP_HOME=~/hadoop
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# If not running interactively, don't do anything
[ -z "$PS1" ] && return
# don't put duplicate lines in the history. See bash(1) for more options
# ... or force ignoredups and ignorespace
HISTCONTROL=ignoredups:ignorespace
# append to the history file, don't overwrite it
shopt -s histappend
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
HISTSIZE=1000
HISTFILESIZE=2000
# check the window size after each command and, if necessary,
# update the values of LINES and COLUMNS.
shopt -s checkwinsize
# make less more friendly for non-text input files, see lesspipe(1)
[ -x /usr/bin/lesspipe ] && eval "$(SHELL=/bin/sh lesspipe)"
# set variable identifying the chroot you work in (used in the prompt below)
if [ -z "$debian_chroot" ] && [ -r /etc/debian_chroot ]; then
debian_chroot=$(cat /etc/debian_chroot)
fi
# set a fancy prompt (non-color, unless we know we "want" color)
case "$TERM" in
xterm-color) color_prompt=yes;;
esac
# uncomment for a colored prompt, if the terminal has the capability; turned
# off by default to not distract the user: the focus in a terminal window
# should be on the output of commands, not on the prompt
#force_color_prompt=yes
if [ -n "$force_color_prompt" ]; then
if [ -x /usr/bin/tput ] && tput setaf 1 >&/dev/null; then
# We have color support; assume it's compliant with Ecma-48
# (ISO/IEC-6429). (Lack of such support is extremely rare, and such
# a case would tend to support setf rather than setaf.)
color_prompt=yes
else
color_prompt=
fi
fi
if [ "$color_prompt" = yes ]; then
PS1='${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$ '
else
PS1='${debian_chroot:+($debian_chroot)}\u@\h:\w\$ '
fi
unset color_prompt force_color_prompt
# If this is an xterm set the title to user@host:dir
case "$TERM" in
xterm*|rxvt*)
PS1="\[\e]0;${debian_chroot:+($debian_chroot)}\u@\h: \w\a\]$PS1"
;;
*)
;;
esac
# enable color support of ls and also add handy aliases
if [ -x /usr/bin/dircolors ]; then
test -r ~/.dircolors && eval "$(dircolors -b ~/.dircolors)" || eval "$(dircolors -b)"
alias ls='ls --color=auto'
#alias dir='dir --color=auto'
#alias vdir='vdir --color=auto'
alias grep='grep --color=auto'
alias fgrep='fgrep --color=auto'
alias egrep='egrep --color=auto'
fi
# some more ls aliases
alias ll='ls -alF'
alias la='ls -A'
alias l='ls -CF'
# Alias definitions.
# You may want to put all your additions into a separate file like
# ~/.bash_aliases, instead of adding them here directly.
# See /usr/share/doc/bash-doc/examples in the bash-doc package.
if [ -f ~/.bash_aliases ]; then
. ~/.bash_aliases
fi
# enable programmable completion features (you don't need to enable
# this, if it's already enabled in /etc/bash.bashrc and /etc/profile
# sources /etc/bash.bashrc).
#if [ -f /etc/bash_completion ] && ! shopt -oq posix; then
# . /etc/bash_completion
#fi
- ssh를 통해 명령을 실행하기에 환경변수 부분을 bashrc 파일의 앞부분에 작성하였습니다.아래 트러블슈팅( ssh 명령시 패스 문제 -해결) 참고해주세요.
- 실행파일을 편하게 실행하기 위해 각 bin 디렉토라를 path에 추가하였습니다. 또한, 유저 생성 없이 root 유저를 사용할 것이므로
export HDFS_NAMENODE_USER=root와 같은 설정을 각각 추가해주었습니다.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode1:9000</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///root/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///root/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.http.address</name>
<value>namenode:9870</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>secondarynamenode:9868</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
</configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>resourcemanager</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- workers
datanode1 datanode2 datanode3 - docker-compose.yml
services: namenode1: image: myhadoop container_name: namenode1 volumes: - hdfs-name1:/root/hadoop/hdfs/name - hdfs-logs:/root/hadoop/logs networks: mynetwork: ports: - 9870:9870 command: ["sh", "-c", "service ssh start; tail -f /dev/null"] namenode2: image: myhadoop container_name: secondarynamenode volumes: - hdfs-name2:/root/hadoop/hdfs/name - hdfs-logs:/root/hadoop/logs networks: mynetwork: ports: - 9870:9870 command: [ "sh", "-c", "service ssh start; tail -f /dev/null" ] resourcemanager: image: myhadoop container_name: resourcemanager volumes: - hdfs-logs:/root/hadoop/logs networks: mynetwork: command: [ "sh", "-c", "service ssh start; tail -f /dev/null" ] datanode1: image: myhadoop container_name: datanode1 volumes: - hdfs-data1:/root/hadoop/hdfs/data - hdfs-logs:/root/hadoop/logs networks: mynetwork: command: ["sh", "-c", "service ssh start; tail -f /dev/null"] datanode2: image: myhadoop container_name: datanode2 volumes: - hdfs-data2:/root/hadoop/hdfs/data - hdfs-logs:/root/hadoop/logs networks: mynetwork: command: [ "sh", "-c", "service ssh start; tail -f /dev/null" ] datanode3: image: myhadoop container_name: datanode3 volumes: - hdfs-data3:/root/hadoop/hdfs/data - hdfs-logs:/root/hadoop/logs networks: mynetwork: command: [ "sh", "-c", "service ssh start; tail -f /dev/null" ] volumes: hdfs-name1: hdfs-name2: hdfs-data1: hdfs-data2: hdfs-data3: zookeeper-logs: hdfs-logs: networks: mynetwork:container_name도커 네트워크에서는 컨테이너명이 곧 호스트명이 됩니다.volumes:- 볼륨을 생성해주면 컨테이너가 삭제 후 재시작되어도 하둡 파일시스템의 데이터가 유지됩니다. 즉, 영속적인 시스템 구축이 가능합니다. 데이터 노드의 볼륨을 각각 설정해줌으로써 데이터노드의 데이터가 충돌하는
- 또한, 로그 파일을 보관할 수 있습니다
- ssh service를 컨테이너 시작시 실행합니다.
- tail -f /dev/null 을 통해 컨테이너가 도커 컴포즈 후 바로 종료되지 않게 합니다.
구성 및 설치 테스트
- 이미지 생성해보기, (주의, 프로젝트 디렉토리의 hadoop 디렉토리에서)
docker build -t myhadoop -f Dockerfile-hadoop . - 생성된 이미지 실행 후 하둡 작동
docker compose up -d docker exec -it namenode1 bash ## start all hadoop daemon hdfs namenode -format start-all.sh ## 정상적인 구성 테스트 echo "1,2,3" > temp hadoop fs -copyFromLocal temp /temp hadoop fs -cat /temp # 1,2,3 이 출력된다면 정상 hdfs fsck /temp # 파일 체크 복제 계수 3.0 확인 # 인터넷 브라우저로 localhost:9870, localhost:9868 접속 후 작동확인 exit docker compose down
하둡 실행
- HDFS 포멧 hdfs namenode -format
- 데몬 시작 중지
start-all.sh stop-all.sh
- hdfs 정상 작동 테스트
jps
고가용성 구성
하둡의 hdfs 고가용성 구성에 대한 설명은 아래 글에서 하였습니다.
구성 - 저널노드가 추가된 고가용성
위의 분산 하둡 구성에서 고가용성 (이하 HA)를 제공하는 구성으로 재설정해줍니다.
- hdfs-site.xml
# 추가 <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>namenode1:9000</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>namenode2:9000</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>namenode1:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>namenode2:9870</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://namenode1:8485;namenode2:8485;resourcemanager:8485/mycluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/root/hadoop/hdfs/journal</value> </property>nameservices: 2개 이상의 네임노드로 이루어진 네이노드 클러서트의 이름 (사용자가 짓는)dfs.ha.namenodes.mycluster네임노드의 수에 맞게끔 ID를 작성한다. (nn1, nn2 역시 사용자가 짓는)dfs.namenode.rpc-address.mycluster.nn1위에서 nn1으로 작명한 네임노드1의 호스트와 네임노드 포트 번호 설정dfs.namenode.http-address.mycluster.nn1위에서 nn1으로 작명한 네임노드1의 네임노드 웹 UI 포트번호 설정dfs.namenode.shared.edits.dirHA를 구성하는 저널노드의 호스트와 포트번호. 처음과 끝 형식에 주의dfs.client.failover.proxy.provider.mycluster데이터 노드 (dfs client)가 어느 네임노드가 활성상태인지 확인하는 방법 설정dfs.ha.fencing.methods액티브 네임노드가 문제가 생겨 장애극복 조치 하기전에 문제가 생긴 네임노드를 완전히 격리시키는 방법 설정dfs.ha.fencing.ssh.private-key-files위에서 펜싱 메소드로 sshfence 방법을 선택했다면 ssh private key 파일을 지정. 이 때, pem 형식의 키여야 하고 각 네임노드에는 fuser 명령어가 설치되어 있어야 한다. 아래 트러블 슈팅(HA를 구성했는데…) 참고dfs.journalnode.edits.dir저널 노드의 데이터가 작성될 디렉토리
- core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property>fs.defaultFS위에서 설정한 mycluseter가 기본 FS가 된다.
구성 및 설치 테스트
- 이미지 생성
docker build -t myhahadoop -f ha/Dockerfile-ha ha - 테스트 다음 섹션에서 주키퍼 마저 설치 후, 한꺼번에 테스트 진행합니다. 주키퍼 없이 저널노드로만 구성된 HA 실행은 위의 HA 하둡 고가용성 을 참고해주세요.
주키퍼를 이용한 자동 장애 조치 (fail over)
주키퍼와 하둡의 주키퍼 컨트롤러 데몬인 ZKFC에 대한 설명은 위의 글들에서 하였습니다. 주키퍼에 대한 설명과 주키퍼가 어떻게 빠른 장애극복을 하는지에 대한 설명이 있습니다.
또한,위의 튜토리얼에 주키퍼 클러스터(복제모드) 설정 방법이 있습니다. 이 설정 방법대로 주키퍼 클러스터를 구성했다는 전제하에 아래 내용을 진행합니다.
ZooKeeper 배포 구성
주키퍼 데몬은 3개 또는 5개의 노드에서 실행되도록 구성합니다. 이 프로젝트에서는 3개입니다.
자체 리소스 적으므로 네임노드, 스탠바이네임노드, Yarn Resourcemanager 노드를 추천합니다. (공식 문서 기준)
주키퍼 클러스터 구성 완료 후 아래의 설정 추가
- hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>- core-site.xml
<property>
<name>ha.zookeeper.quorum</name>
<value>namenode1:2181,namenode2:2181,resourcemanager:2181</value>
</property>- ~/.bashrc
export HDFS_ZKFC_USER=root주키퍼 포함된 고가용성 구성 및 실행
- 첫 HA HDFS 구성시
- 주키퍼 데몬 실행. 네임1, 네임2, 리소스매니저에서
zkServer.sh start - 네임1, 네임2, 리소스매니저에서 데몬으로 저널노드 데몬 켜주기 * 3
hdfs --daemon start journalnode - 네임노드 1에서 네임노드 포맷, 네임 노드 실행
hdfs namenode -format,hdfs --daemon start namenode - 네임노드 2에서 부트스랩후 네임 노드 실행
hdfs namenode -bootstrapStandby,hdfs --daemon start namenode - NameNode 호스트 중 하나에서
hdfs zkfc -formatZK start-dfs.sh
- 주키퍼 데몬 실행. 네임1, 네임2, 리소스매니저에서
위의 실행을
→ cluster-init.sh 에 명령을 모아두었습니다.
#!/bin/sh
ssh namenode1 "zkServer.sh start && hdfs --daemon start journalnode"
ssh namenode2 "zkServer.sh start && hdfs --daemon start journalnode"
ssh resourcemanager "zkServer.sh start && hdfs --daemon start journalnode"
ssh namenode1 "hdfs namenode -format && hdfs --daemon start namenode"
ssh namenode2 "hdfs namenode -bootstrapStandby && hdfs --daemon start namenode"
ssh namenode1 "hdfs zkfc -formatZK"
ssh namenode1 start-all.sh
- 이미 구성된 시스템을 재시작시 ( 컨테이너 삭제 후 재시작) → cluster-restart.sh
#!/bin/sh ssh namenode1 "zkServer.sh start" ssh namenode2 "zkServer.sh start" ssh resourcemanager "zkServer.sh start" ssh namenode1 start-all.sh
위의 구성을 잘 진행하였다면 HA를 지원하는 HDFS 구성을 위해 모둔 준비를 마쳤습니다.
그외
namenodes
- 클러스터 구성에 필요한 명령어를 컨테이너에 복사합니다
- 주키퍼 서버에 필요한 id를 작성합니다
resourcemanager
- 주키퍼 서버에 필요한 id를 작성합니다
docker-compose.yml
- 코드
services: namenode1: image: namenode1 container_name: namenode1 volumes: - hdfs-name1:/root/hadoop/hdfs/name - hdfs-logs:/root/hadoop/logs - hdfs-journal1:/root/hadoop/hdfs/journal - zookeeper1:/var/lib/zookeeper - zookeeper-logs:/root/zookeeper/logs networks: mynetwork: ports: - 9870:9870 command: ["sh", "-c", "service ssh start; tail -f /dev/null"] namenode2: image: namenode2 container_name: namenode2 volumes: - hdfs-name2:/root/hadoop/hdfs/name - hdfs-logs:/root/hadoop/logs - hdfs-journal2:/root/hadoop/hdfs/journal - zookeeper2:/var/lib/zookeeper - zookeeper-logs:/root/zookeeper/logs networks: mynetwork: ports: - 9871:9870 command: ["sh", "-c", "service ssh start; tail -f /dev/null"] resourcemanager: image: resourcemanager container_name: resourcemanager volumes: - hdfs-logs:/root/hadoop/logs - hdfs-journal3:/root/hadoop/hdfs/journal - zookeeper3:/var/lib/zookeeper - zookeeper-logs:/root/zookeeper/logs networks: mynetwork: command: [ "sh", "-c", "service ssh start; tail -f /dev/null" ] datanode1: image: myhahadoop container_name: datanode1 volumes: - hdfs-data1:/root/hadoop/hdfs/data - hdfs-logs:/root/hadoop/logs networks: mynetwork: command: ["sh", "-c", "service ssh start; tail -f /dev/null"] datanode2: image: myhahadoop container_name: datanode2 volumes: - hdfs-data2:/root/hadoop/hdfs/data - hdfs-logs:/root/hadoop/logs networks: mynetwork: command: [ "sh", "-c", "service ssh start; tail -f /dev/null" ] datanode3: image: myhahadoop container_name: datanode3 volumes: - hdfs-data3:/root/hadoop/hdfs/data - hdfs-logs:/root/hadoop/logs networks: mynetwork: command: [ "sh", "-c", "service ssh start; tail -f /dev/null" ] volumes: hdfs-name1: hdfs-name2: hdfs-data1: hdfs-data2: hdfs-data3: hdfs-journal1: hdfs-journal2: hdfs-journal3: zookeeper1: zookeeper2: zookeeper3: zookeeper-logs: hdfs-logs: networks: mynetwork:- 주키퍼를 위한 볼륨이 추가되었습니다.
- ssh service를 컨테이너 시작시 실행합니다.
- tail -f /dev/null 을 통해 컨테이너가 도커 컴포즈 후 바로 종료되지 않게 합니다.
실행
사전조건
- git clone
- 자바, 주키퍼 파일 다운
HDFS 컨테이너 첫 구성
.\start-build.cmddocker-compose up -ddocker exec -it namenode1 bashsh cluster-init.sh
HDFS 컨테이너 재생성
볼륨, 이미지가 남아있다는 전제하에 진행됩니다.
docker-compose up -ddocker exec -it namenode1 bashsh cluster-restart.sh
HA 테스트
- 활성상태인 네임노드에서 (웹 UI 상단을 통해서 확인할 수 있습니다. 혹은 zkfc)
- jps 로 네임노드의 프로세스 번호 확인 후
- kill -9 [네임노드 프로세스 번호]
- 대기상태이던 네임노드가 정상적으로 액티브 상태가 되는지 확인합니다. ( 안됐다면, zkfc 로그를 확인하세요.)
트러블 슈팅
파일 줄바꿈자 - 해결
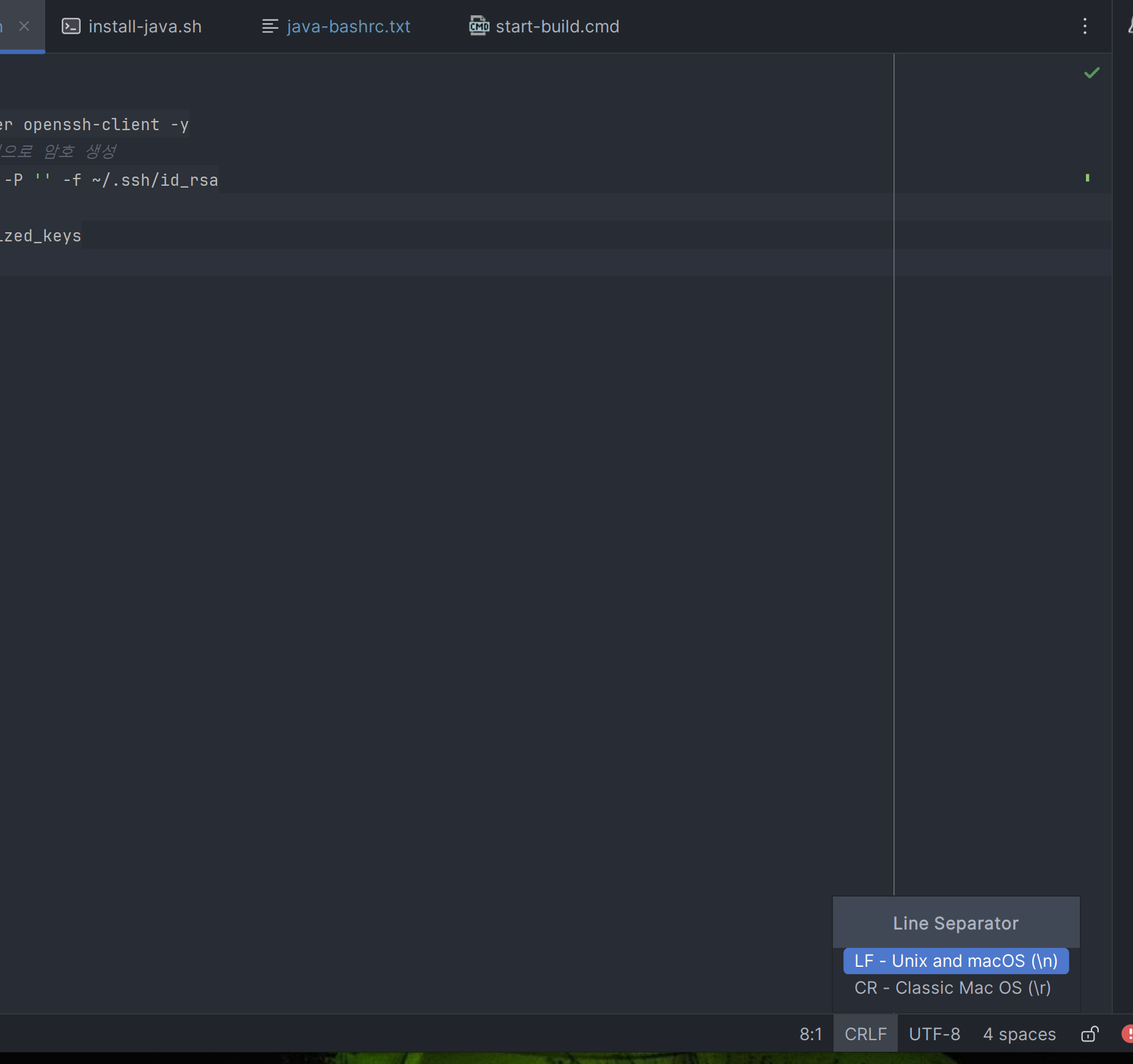
윈도우에서 리눅스 파일을 복사하는 식으로 만든다면 줄바꿈자가 호환되지 않는 문제가 발생할 수 있습니다. 인텔리제이에서 복사하는 파일의 하단 부분의 CRLF를 클릭해 LF로 전환해주면 해결됩니다.
libasound2 - 해결
를 설치해야 dpkg로 자바 설치가 됐다
도커파일 - 해결
도커파일 작성 규약들을 공부해볼 기회였다.
도커 볼륨으로 파일시스템이 유지되게 구성 - 해결
- 네임1,2와 데이터1,2,3
- 네임: /root/hdfs/name
- 데이터: /root/hdfs/data
- 저널1,2,3
- /root/hadoop/hdfs/journal
- 주키퍼1,2,3
- 하드 데이터: /var/lib/zookeeper
- 로그: /root/zookeeper/logs
- 공통
- 로그파일: /root/hadoop/logs
에 모두 볼륨을 만들어주었다.
HA를 구성했는데, 네임노드 복구가 바로 안된다. - 해결
- 환경을 재구성해보고 로그를 확인해보자
- 공식문서를 보니 zkFC 로그를 확인해보라고 한다.
- 확인해보니 펜싱 과정에서 ssh 펜싱이 실패했다. 잘못된 private key라고 한다.
- 잘못된 키라고 한다. 수동으로 ssh 연결을 해봤지만 key 자체는 정상이었다.
- chatgpt한테 로그를 읽혔다. 하둡이 사용하는 JSch는 PEM 형식의 키가 필요하다고 한다.PEM 형식과
- id_rsa 파일을 만들때 open-ssh 형식이 아닌 PEM 형식으로 만들었고 연결은 됐지만 여전히 펜싱에 실패했다. 로그를 다시 읽었고 fuser 명령에 대한 힌트를 얻었다.
- 각 네임노드에 fuser 명령어가 설치되어있어야 한다. 도커 이미지를 수정했다.
- 펜싱 성공 자동 장애극복 설정 완료!
ssh 명령시 패스 문제 -해결
bashrc에 저장된 export 등의 명령이 실행안된다
해결법
- 원문 had similar issue, but in the end I found out that ~/.bashrc was all I needed. However, in Ubuntu, I had to comment the line that stops processing ~/.bashrc :
Share Edit Following edited Jun 26, 2012 at 18:56 machineghost 34.9k3131 gold badges167167 silver badges247247 bronze badges answered Nov 13, 2010 at 17:11 tomaszbak 8,28744 gold badges4545 silver badges3737 bronze badges#If not running interactively, don't do anything [ -z "$PS1" ] && return- 13Alternatively, you can just put all of your "non-interactive" code above that line. Jun 26, 2012 at 18:56 – machineghost
- Thanks. Just adding that the file with the return statement can be found at
/etc/bash.bashrc. Aug 10, 2014 at 21:42 – adarshr
- 1Is there anyway to bypass this code in the server without changing it? Jul 30, 2016 at 22:55 – Yoni
- 2I spent so much time trying to understand why my script didn't work. Who thought it was a good idea to put these lines in the .bashrc ??? May 31, 2018 at 9:56 – Sharcoux
- 13Alternatively, you can just put all of your "non-interactive" code above that line. Jun 26, 2012 at 18:56 – machineghost
.bashrc 파일에서 인턱레티브 모드가 아니면 끄라는 구문 전에 필요한 환경변수 세팅해주면 된다.
# ~/.bashrc: executed by bash(1) for non-login shells.
# see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
# for examples
##################### JDK 11 PATH #########
JAVA_HOME=/usr/lib/jvm/jdk
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export JAVA_HOME
export PATH
#######HADOOP PATH######
HADOOP_HOME=~/hadoop
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
#export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# If not running interactively, don't do anything
[ -z "$PS1" ] && return명령 예시 : ssh datanode1 hdfs --daemon start journalnode
해결
리소스매니저가 자꾸 실행안되고 rootexport 계정을 찾는 문제 -해결
- hadoop-env.sh 파일을 보니 리소스 매니저 유저 부분에서 줄바꿈이 안되어서 자바홈 부분과 겹쳐 사용되었다.
- 이를 도커파일에서부터 수정해주었다. 해결!
