1. Hash Join의 등장 배경
MySQL에서는 오랜 기간 조인 방식으로 NL 조인만 지원되어져 왔다.
물론 NL 조인에서 드리븐 테이블로의 Random Access를 줄이는 BKA Join을 사용하거나, join의 대상을 작은 block으로 나누어 block 하나씩 join 하는 BNL 방식이 도중에 도입되었으나, 이는 여전히 hash join이 도입되기 전에 nested loop join을 활용한 기능 개선이였다.
2. 해시 조인이란?
해시 조인은 해시 테이블을 사용하여 두 입력간에 일치하는 행을 찾는 조인을 실행하는 방식이다.
특히 입력 중 하나가 메모리에 들어갈 수 있는 경우 대용량의 처리에서는 일반적으로 NL 조인보다 효율적이다.
2-1. 샘플 예제 쿼리
SELECT given_name, country_name
FROM persons JOIN contries
ON persons.country_id = countries.contry_id;2-2.빌드 단계와 프로브 단계
해시조인의 알고리즘 설명에서는 일반적으로 해시 조인을 두 단계로 나누게 된다.
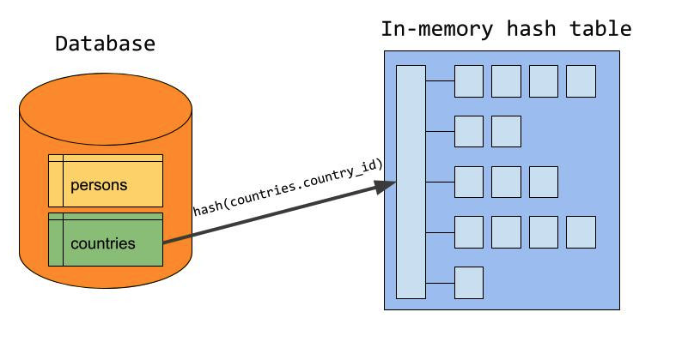
The Build Phase
빌드 단계에서는 서버는 조인 속성을 해시 테이블 키로 사용하여 입력 중 하나의 행이 저장되는 인 메모리 해시 테이블을 빌드한다.
이 입력을 빌드 입력이라고 하며 이상적으로는 MySQL 서버는 두 입력 중(두 테이블 중) 더 작은 것을 빌드 입력으로 선택한다.(행 수가 아니라 바이트로 측정됨)
필요한 모든 행이 해시 테이블에 저장되면 빌드 단계가 완료된다. (조인 컬럼과 SELECT 절에서 필요로 하는 컬럼도 함께 저장)
countries 테이블이 빌드 입력으로 지정되었다고 가정해보자. 이후 'countries.country_id'이 빌드 Input에 속한 조인 조건이며 해시 테이블의 키로서 이용되게 한다.
The Probe Phase
프로브 단계 동안 서버는 프로브 입력(이 예제에서는 persons 테이블)에서 행 읽기를 시작한다.
각 행에 대해 서버는 persons_country_id의 값을 조회 키로 사용하여 행과 일치하는 해시 테이블을 조사한다. 각 일치에 대해 결합 된 행이 클라이언트로 전송된다.
결국 서버는 두 입력간에 일치하는 행을 찾기 위해 일정한 시간 조회를 사용하여 각 입력을 한번씩만 스캔했다.
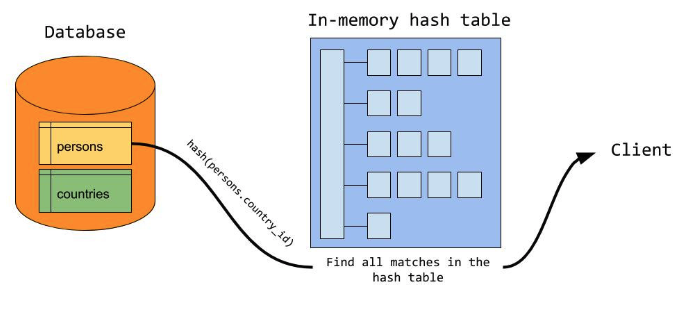
위의 상황은 MySQL서버가 전체 빌드 입력을 메모리에 저장할 수 있다는 점을 감안할 때 매우 잘 작동한다. 그러나 빌드 입력이 사용한 메모리보다 크면 디스크에 기록하게 된다.
특징
-
조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하지 않을 경우에도 사용할 수 있는 기법이다.
-
메모리 사용량이 큰 대용량 테이블 조인 시 메모리 외에 임시영역(PGA 메모리)까지 사용하여 저장할 수 있어 유리하다.
-
해시 함수를 이용하여 조인을 수행하기 때문에 '='(동등 비교)로 수행하는 조인에서만 사용가능하다.
-
각 테이블을 한번씩만 스캔했다는 점에서 매우 효과적이다.
❗️주의할 점
Hash Join은 조인 작업을 수행하기 위해 해시 테이블을 메모리에 생성한다.
Hash Table의 크기가 메모리에 적재할 수 있는 크기보다 더 커지면 임시 영역(디스크)에 해시 테이블을 저장한다.
그렇기 떄문에 Hash Join을 할 때는 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋다.
선행 테이블의 결과를 완전히 메모리에 저장할 수 있다면 임시 영역에 저장하는 작업이 발생하지 않기도 하고, CPU 연산을 조금 덜 수행할 수 있기 때문이다.
참고 링크
