이 글의 목적?
간단한 인덱스를 조회가 많이 되는 곳에 걸어, 성능을 간단하게나마 향상시켜본 적은 있다. 하지만 인덱스에 대해 개념적인 내용부터 정리해볼 필요가 있다고 생각이 들어서 포스팅 하게 되었다.
우아한테크코스의
10분 테크톡-매트,토르의 MYSQL 성능 최적화 영상과, Index관련 자료들을 바탕으로 공부해 보았다.
인덱스를 이용한 성능 최적화란?
데이터베이스에서의 성능 최적화는 디스크 I/O를 줄이는 것이 핵심이다. 원하는 데이터를 찾기 위해서는 디스크에서 헤드가 플래터에 담긴 데이터를 가져올 때 물리적으로 움직이는데, 이 움직임 때문에 데이터의 입출력이 느려진다. (SSD가 보편화되었다고 하더라도 여전히 느리다는 문제가 있다.)
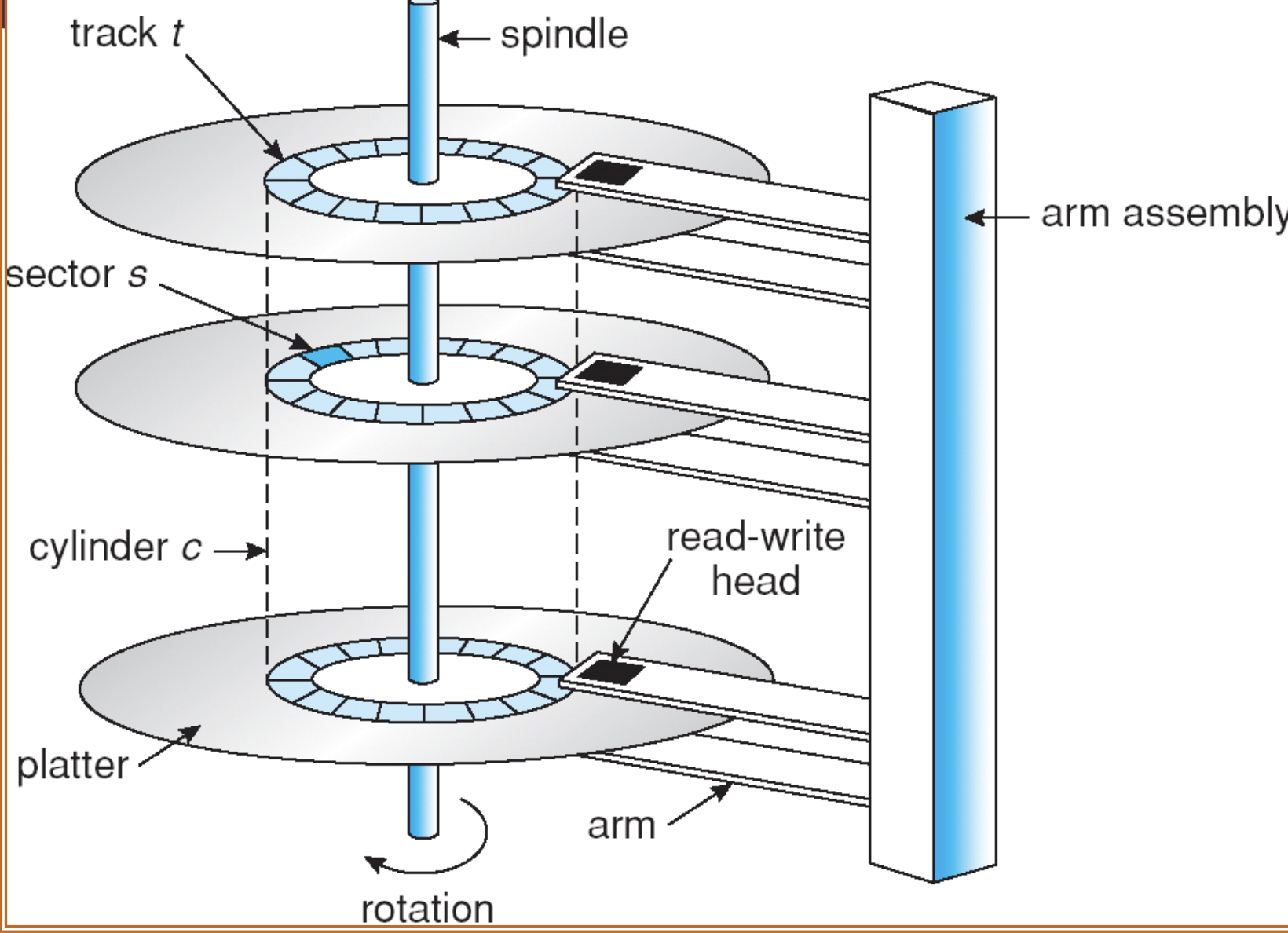
일반적인 웹 서비스에서는 수정 및 삭제보다 데이터를 조회하는 비율이 압도적으로 많기 때문에 수정 및 삭제에서 어느정도 손해를 보더라도, 조회 성능을 높이는 것을 많이 선택한다.
만약에 인덱스가 없을 경우라면, 하단의 쿼리는 데이터를 모두 읽어와 데이터베이스에서 직접 정렬을 해야겠지만, 인덱스가 적용되어 있으면, 이미 정렬되어 있기 때문에 인덱스 순서대로 파일을 읽기만 하면 되어 성능적으로 이점을 챙길 수 있다.
SELECT *
FROM crew
WHERE nickname >= '매트' AND nickname =< '토르'
ORDER BY nickname;인덱스의 종류
인덱스에는 크게 클러스터형 인덱스와 보조 인덱스가 있다.
1. 클러스터형 인덱스(Clustered Index)
클러스터형 인덱스는 기본키로 지정하면 자동 생성되며 테이블에 1개만 만들 수 있다. 기본 키로 지정된 열을 기준으로 자동 정렬된다.

이렇게 기본 키로 지정하면, 자동으로 mem_id 열에 클러스터형 인덱스가 생성된다. 그런데 기본 키는 테이블에 하나만 저장할 수 있다. 그래서 클러스터 형 인덱스는 테이블에 한 개만 만들 수 있다.
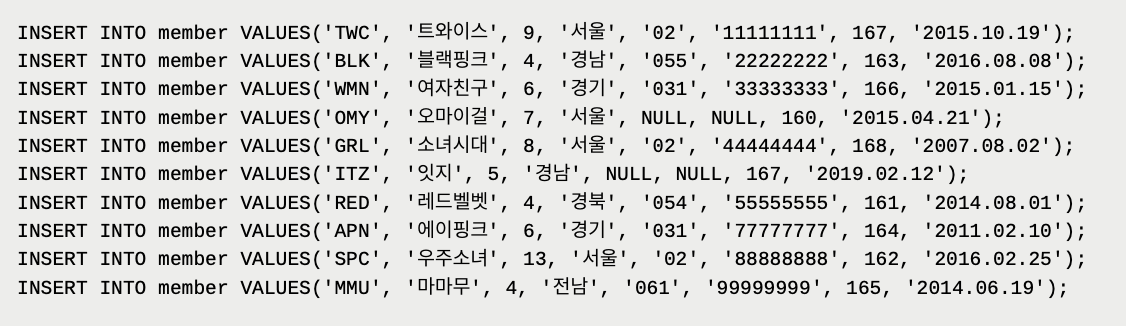
테이블을 위와 같이, member_id를 기본키로 지정해서 만들고, 데이터들을 insert하면
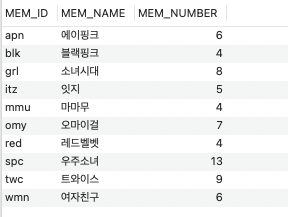
기본키로 지정된 열을 기준으로 자동 정렬됨을 확인할 수 있다.
테이블의 인덱스를 확인해보려면, show index문을 통해 인덱스 정보를 확인할 수 있다.
show index from member;
여기서 key_name 부분을 보면 PRIMARY라고 적혀 있다. 이것은 아까 우리가 기본 키로 설정해서 자동으로 생성된 인덱스라는 의미이다. 이것이 바로 클러스터형 인덱스이다.!!
그리고 index_type은 BTREE구조임을 알 수 있고, non_unique가 0이라는 것은, False 즉, 인덱스 중복이 허용되지 않는다는 뜻이고, 이는 아까 말한 클러스터형 인덱스의 특징임을 알 수 있었다.
플러스!
CREATE TABLE table2(
col1 INT PRIMARY KEY,
col2 INT UNIQUE,
col3 INT UNIQUE
);
show index FROM table2;table에 고유키가 있으면, 고유키도 인덱스가 자동으로 생성된다.
table2가 위와 같은 경우,

결과를 보면 알 수 있지만, key_name에 col2,col3라고 열 이름이 써있다. 이렇게 고유 키로 생성되는 인덱스는 보조 인덱스라고 한다. 고유 키 역시 중복을 허용하지 않기 때문에 non_unique가 0(false)로 되어 있음을 확인할 수 있다. 또 보조 인덱스도 여러 개 만들 수 있다.!!
2. 보조 인덱스(Secondary Index)
보조 인덱스는 고유 키로 지정하면 자동 생성되며 여러개를 만들 수 있지만, 자동 정렬되지는 않는다.
보조 인덱스를 책으로 비유하자면, 일반 책에는 찾아보기를 만들면 뒤에 추가되는 것이지 책 본문이 변경되는 것이 아니다.
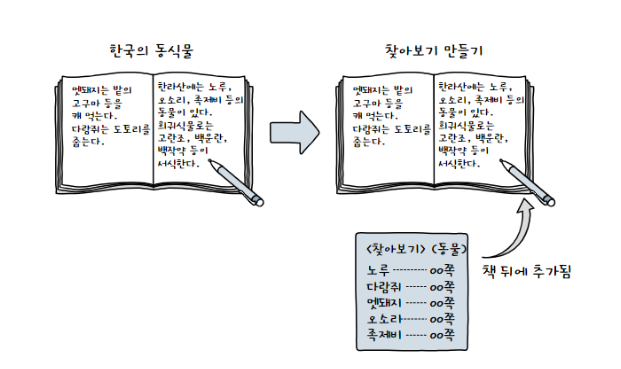
마치 보조 인덱스는 본문을 바꾸지 않고, 책 뒤에 찾아보기를 만들어, select 속도를 빠르게 하는 느낌이다.
이번에는 간단하게 테이블을 아래와 같이 만들어 보조 인덱스 실습을 해보자.
CREATE TABLE MEMBER2
(
mem_id char (8),
mem_name varchar(10),
mem_number int,
addr char(2)
);
MEMBER2 테이블을 생성하고, 4개의 데이터를 insert하면 어떻게 정렬이 될까?
PK가 없어서, cluser index가 생성이 안되고, 고유 키도 없어 보조 인덱스도 생성이 안될 것이다.
그래서 넣은 순서대로 데이터가 저장이 될 것이다.
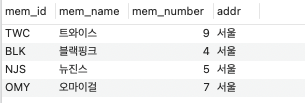

실제로 넣은 데이터 순서대로 저장이 되고, index가 아무것도 생성이 안됨을 확인할 수 있었다.
여기서 이제 mem_id를 고유키로 설정하면, 보조 인덱스가 생성될 텐데, 데이터의 내용이나 순서가 바뀔꺄?
alter table member2
add constaint
unique (mem_id);
select *from member2;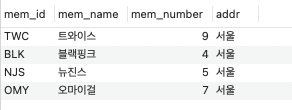
아니다. 그대로이다.
이렇게 보조 인덱스를 생성하여도, 데이터의 내용이나 순서는 변경되지 않는다.
결론: 보조 인덱스는 여러 개 만들 . 수있다. 하지만 보조 인덱스를 만들 때마다 데이터베이스의 공간을 차지하게 되므로, 전반적으로 시스템에 오히려 나쁜 영향을 끼친다.
그 외의 인덱스 종류들
1. Composite (or Multi-column) Index
- 이 인덱스는 두 개 이상의 칼럼을 기반으로 한다. 즉, 여러 칼럼의 조합을 인덱스를 구성한다.
- 주로 WHERE 절에서 여러 칼럼을 조건을 사용할 때 효과적이다.
- 예시: WHERE first_name = 'John' AND last_name ='Doe'
- Composite Index는 Cardinality가 높은(중복도가 낮은)순서대로 작성하는게 효과적이다.
2. Covering Index
-
모든 필요한 데이터를 인덱스 페이지에서 직접 가져올 수 있는 인덱스이다. 따라서 데이터베이스 페이지에 엑세스할 필요가 없어 성능이 향상된다.
-
주로 SELECT 절의 칼럼과 WHER절의 조건에 사용되는 칼럼을 포함하는 인덱스이다.
-
예시: select member_id, name, address, from member;
와 같이 select * 으로 모든 칼럼을 가져오는 것이 아니라, 자주 사용하는 칼럼들을 index에 저장해 넣고,데이터베이스 페이지의 접근을 줄이는 효과를 얻을 수 있다.
3. Full-text Index
- 텍스트 데이터 내에서 키워드 검색을 최적화 하기 위한 인덱스이다.
- 일반적인 인덱스와는 다르게, 텍스트 내의 단어를 기반으로 검색을 지원한다.
- MySQL, SQL Server, Oracle 등의 RDBMS에서 지원한다.
4. Partitional Index
- 데이터를 여러 파티션을 분할하고, 각 파티션에 대해 인덱스를 생성한다.
- 대량의 데이터를 효과적으로 관리하고, 쿼리 성능을 향상시키기 위해 데이터를 논리적인 단위로 나눈다.
- 각 파티션은 독립적으로 관리되며, 쿼리 최적화 및 데이터 관리가 각 파티션에서 수행된다.
이 외에도 다양한 종류의 인덱스가 있다.
인덱스 유형은 각각 특정한 사용 사례 및 쿼리 유형에 최적화되어 있다. 어떤 인덱스를 사용할지는, 실제 데이터와 쿼리 패턴을 기반으로 결정해야 한다.
요약

