
대본 분석 순서는 다음과 같다.
1) 두명이서 남자,여자 파트를 나눠서 맡는다
2) 각자 맡은 성별의 모든 대사 분량들을 체크한다 (글자수 체크)
3) 주연 배우들 기준으로 분량이 더 적은 배우를 맡은 사람에게 조연 배우들을 더 배치 시킨다. (남자 배우3, 여자 배우3)
우선 대본을 보면
https://fangj.github.io/friends/season/0117.html 사이트에서 스크립트를 받아와서
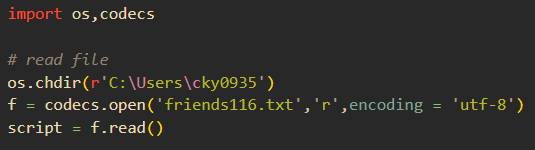
모든 대사들을 txt파일로 저장 후 파이썬에서 열어보자.
이 대본을 가져왔을 때 어떻게 한 줄 한 줄 문자열로 받아올 지 생각 해봤다.
우선, 분량을 체크할 배우들을 입력 받아서 List에 담아보기로 했다.
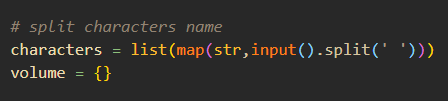
이렇게 입력한 배우들의 이름을 사용해 각 이름에 맞는 행들을 찾아서 분량을 체크해야 해봤다.

배우를 구분하기 위해서 정규식 라이브러리인 re 모듈의 findall() 함수를 사용해야 했다.
직접 입력한 배우들을 for문으로 하나씩 돌아가며 "(배우이름):" 이후의 문자열을 Lines라는 변수에 담아 사용하기로 했다.
그렇게 되면 Monica의 분량을 체크하고 싶을 때 ':' 까지 인식해서 Monica: 이후의 문자열을 문장이 끝날 때 까지 모두 읽어들이는 것이다.
또한 Lines로 들어온 문장의 길이를 구하기 위해서 (문장길이)-(배우이름길이)-3 을 해주었다.
마지막 3은 앞에 ':'와 첫 스페이스 공간과 마지막 '\n'값들을 빼준 것인데, 이렇게 해야지 배우들의 순수 대본 분량만 체크할 수 있게 된다.
그리고 이 길이를 sum에 반복하여 합한 것이 해당 배우의 전체 대본 분량인데,다시 이 것을 volume이라는 {character : sum}형식의 딕셔너리 안에 해당 배우의 이름을 키값으로 하고, 그에 맞는 value값을 대본 분량으로 저장했다.
이렇게 입력한 배우들이 모두 반복하여 분량이 체크 되는 것인데, 여기서 더 나아가 순위까지 짤 수 있는 코드를 넣어봤다.

volume에서 key값을 기준으로 내림차순 정렬을 하는 코드를 추가했다.

마지막으로 반복문을 활용하여 1. Monica[2310] 의 형태로 출력하는 코드를 넣었다.
실행
배우들 이름을 입력 받았을 때 문장들이 잘 인식이 되는지 확인 해보자.

배우 'Rosen'의 분량이 제대로 출력이 되는 것을 확인했다. 이제 모든 배우들을 입력받아 순위까지 매겨봤다.
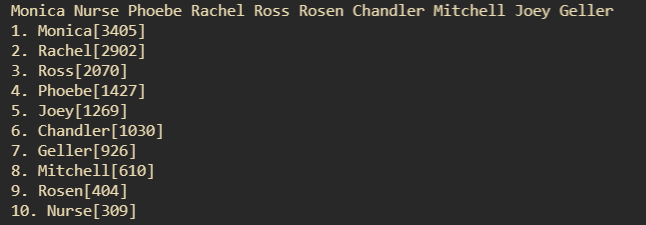
각 배우들의 이름을 스페이스바로 구분하여 모두 리스트에 담아서 분량 체크 후 최종 순위를 매긴 화면.
- 정규화 라이브러리 re 사용법 익히기
▶ re — 정규식 연산 — Python 3.10.1 문서
▶ 파이썬 정규식(Regular Expression) 사용하기 - re 라이브러리
▶파이썬/라이브러리/re - 인코덤, 생물정보 전문위키- findall() 함수의 사용법 - 문자열 구분
▶ 모든 문자열 패턴 찾기 (findall)
